内存布局
在讲Golang的内存分配之前,让我们先来看看一般程序的内存分布情况:
以上是程序内存的逻辑分类情况。
我们再来看看一般程序的内存的真实(真实逻辑)图: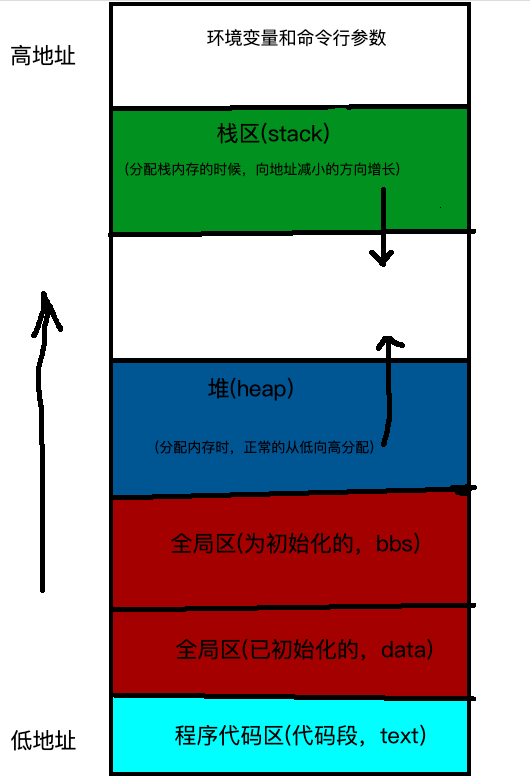
内存分配方法
编程语言的内存分配器一般包含两种分配方法,一种是线性分配器(Sequential Allocator,Bump Allocator),另一种是空闲链表分配器(Free-List Allocator),这两种分配方法有着不同的实现机制和特性
线性分配器
线性分配(Bump Allocator)是一种高效的内存分配方法,但是有较大的局限性。当我们使用线性分配器时,只需要在内存中维护一个指向内存特定位置的指针,如果用户程序向分配器申请内存,分配器只需要检查剩余的空闲内存、返回分配的内存区域并修改指针在内存中的位置,即移动下图中的指针: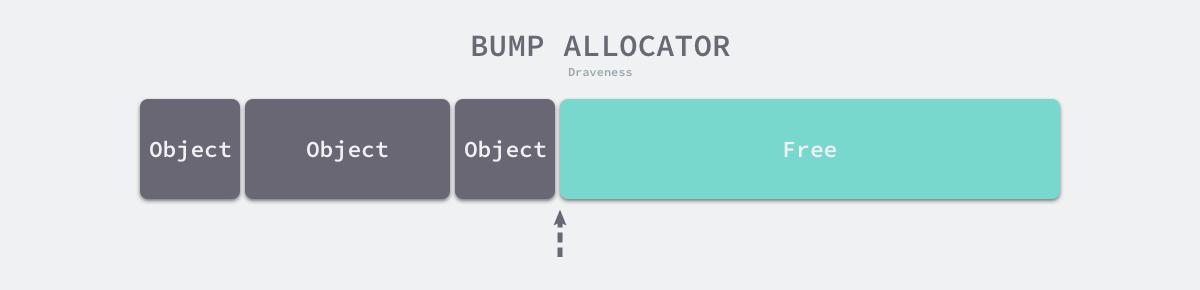
虽然线性分配器实现为它带来了较快的执行速度以及较低的实现复杂度,但是线性分配器无法在内存被释放时重用内存。如下图所示,如果已经分配的内存被回收,线性分配器无法重新利用红色的内存: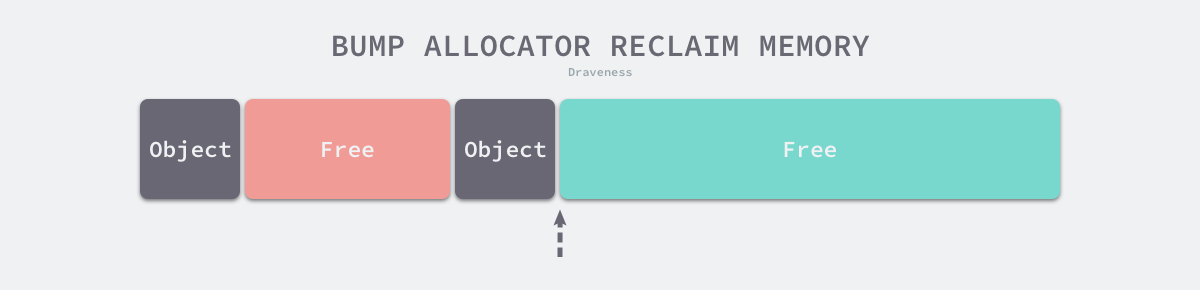
因为线性分配器具有上述特性,所以需要与合适的垃圾回收算法配合使用,例如:标记压缩(Mark-Compact)、复制回收(Copying GC)和分代回收(Generational GC)等算法,它们可以通过拷贝的方式整理存活对象的碎片,将空闲内存定期合并,这样就能利用线性分配器的效率提升内存分配器的性能了。
因为线性分配器需要与具有拷贝特性的垃圾回收算法配合,所以 C 和 C++ 等需要直接对外暴露指针的语言就无法使用该策略,我们会在下一节详细介绍常见垃圾回收算法的设计原理。
空闲链表分配器
空闲链表分配器(Free-List Allocator)可以重用已经被释放的内存,它在内部会维护一个类似链表的数据结构。当用户程序申请内存时,空闲链表分配器会依次遍历空闲的内存块,找到足够大的内存,然后申请新的资源并修改链表: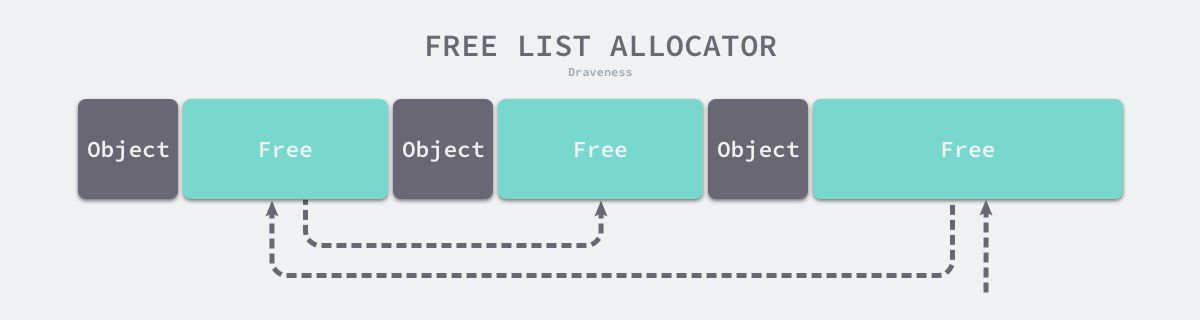
因为不同的内存块通过指针构成了链表,所以使用这种方式的分配器可以重新利用回收的资源,但是因为分配内存时需要遍历链表,所以它的时间复杂度是 𝑂(𝑛)O(n)。空闲链表分配器可以选择不同的策略在链表中的内存块中进行选择,最常见的是以下四种:
- 首次适应(First-Fit)— 从链表头开始遍历,选择第一个大小大于申请内存的内存块;
- 循环首次适应(Next-Fit)— 从上次遍历的结束位置开始遍历,选择第一个大小大于申请内存的内存块;
- 最优适应(Best-Fit)— 从链表头遍历整个链表,选择最合适的内存块;
- 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同,申请内存时先找到满足条件的链表,再从链表中选择合适的内存块;
上述四种策略的前三种就不过多介绍了,Go 语言使用的内存分配策略与第四种策略有些相似,我们通过下图了解该策略的原理: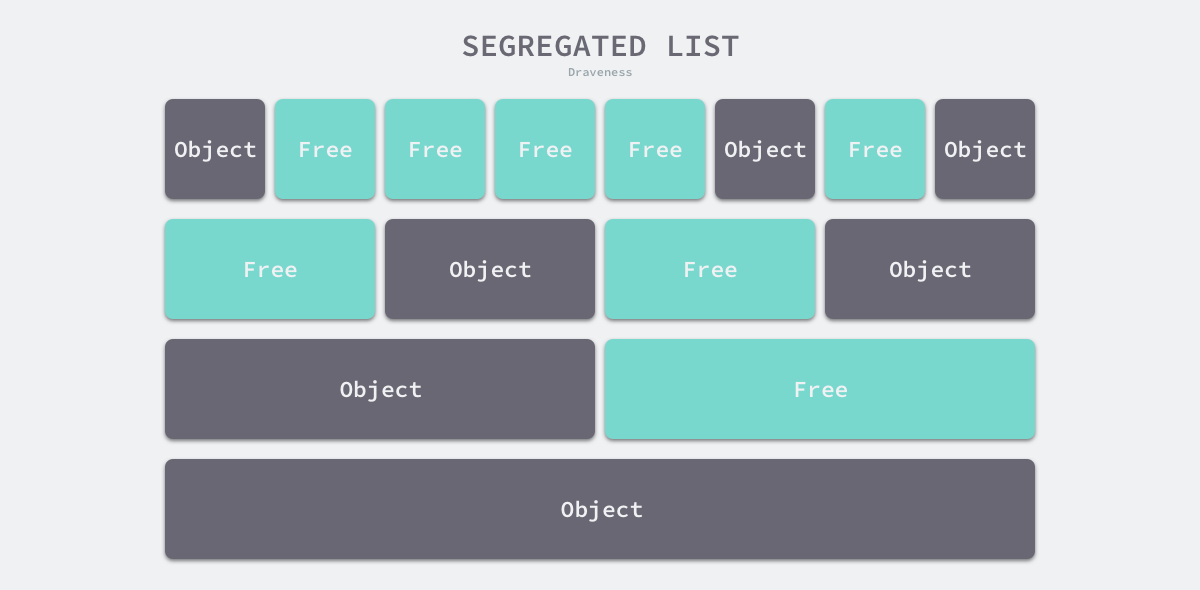
Go的内存分配核心思想
Go是内置运行时的编程语言(runtime),像这种内置运行时的编程语言通常会抛弃传统的内存分配方式,改为自己管理。这样可以完成类似预分配、内存池等操作,以避开系统调用带来的性能问题,防止每次分配内存都需要系统调用。
Go的内存分配的核心思想可以分为以下几点:
- 每次从操作系统申请一大块儿的内存,由Go来对这块儿内存做分配,减少系统调用
- 内存分配算法采用Google的
TCMalloc算法。算法比较复杂,究其原理可自行查阅。其核心思想就是把内存切分的非常的细小,分为多级管理,以降低锁的粒度。 - 回收对象内存时,并没有将其真正释放掉,只是放回预先分配的大块内存中,以便复用。只有内存闲置过多的时候,才会尝试归还部分内存给操作系统,降低整体开销
虚拟内存布局
这里会介绍 Go 语言堆区内存地址空间的设计以及演进过程,在 Go 语言 1.10 以前的版本,堆区的内存空间都是连续的;但是在 1.11 版本,Go 团队使用稀疏的堆内存空间替代了连续的内存,解决了连续内存带来的限制以及在特殊场景下可能出现的问题。
线性内存
Go 语言程序的 1.10 版本在启动时会初始化整片虚拟内存区域,如下所示的三个区域 spans、bitmap 和 arena 分别预留了 512MB、16GB 以及 512GB 的内存空间,这些内存并不是真正存在的物理内存,而是虚拟内存: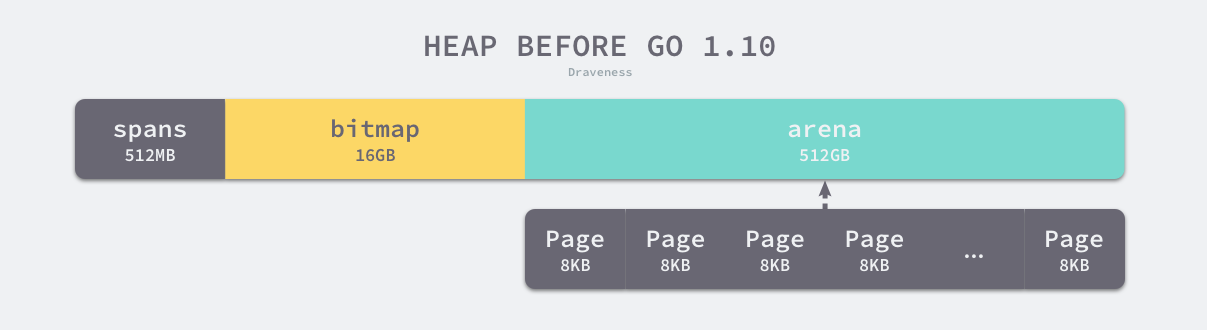
注意: 这时还只是一段虚拟的地址空间,并不会真正地分配内存三个数组组成一个高性能内存管理结构。使用arena地址向操作系统申请内存,其大小决定了可分配用户内存上限 图中span和bitmap的大小会随着heap的改变而改变
arena
就是所谓的堆区,Go动态分配的内存都是在这个区域,它把内存分割成8KB大小的页,一些页组合起来称为mspan
spans
spans区域,可以认为是用于上面所说的管理分配arena(即heap)的区域。
此区域存放了mspan的指针,mspan是啥后面会讲。
spans区域用于表示arena区中的某一页(page)属于哪个mspan。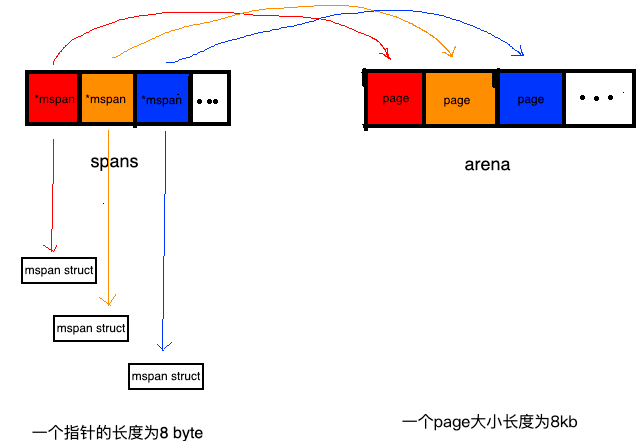
bitmap
bitmap 有好几种:Stack, data, and bss bitmaps,再就是这次要说的heap bitmaps。
在此bitmap的做作用是标记标记arena(即heap)中的对象。一是的标记对应地址中是否存在对象,另外是标记此对象是否被gc标记过。一个功能一个bit位,所以,heap bitmaps用两个bit位。
bitmap区域中的一个byte对应arena区域的四个指针大小的内存的结构如下: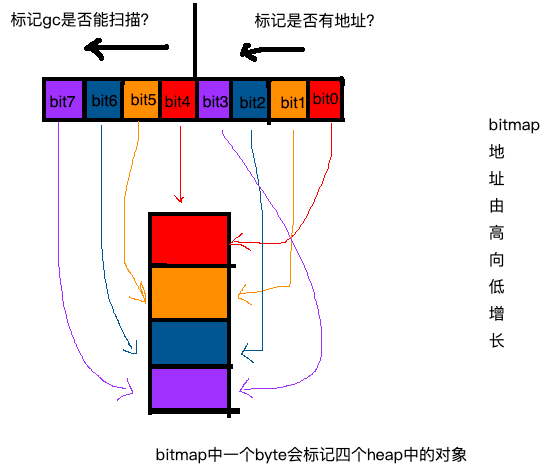
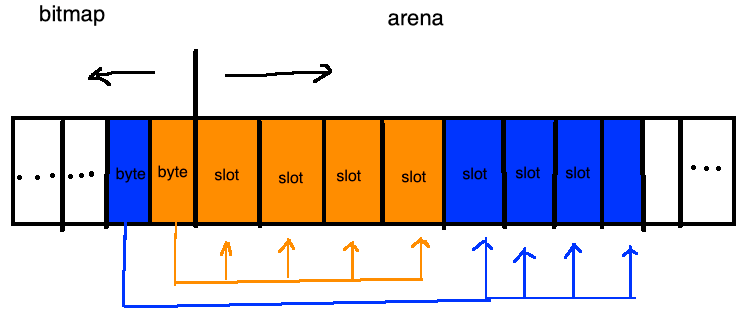
稀疏内存
稀疏内存是 Go 语言在 1.11 中提出的方案,使用稀疏的内存布局不仅能移除堆大小的上限5,还能解决 C 和 Go 混合使用时的地址空间冲突问题。不过因为基于稀疏内存的内存管理失去了内存的连续性这一假设,这也使内存管理变得更加复杂: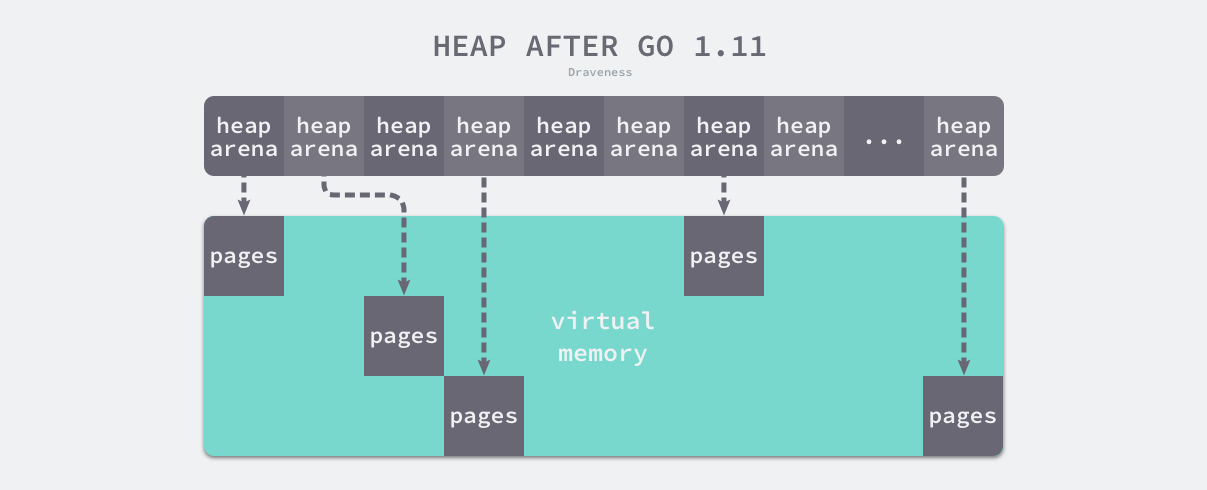
如上图所示,运行时使用二维的 runtime.heapArena 数组管理所有的内存,每个单元都会管理 64MB 的内存空间:
type heapArena struct {bitmap [heapArenaBitmapBytes]bytespans [pagesPerArena]*mspanpageInUse [pagesPerArena / 8]uint8pageMarks [pagesPerArena / 8]uint8pageSpecials [pagesPerArena / 8]uint8checkmarks *checkmarksMapzeroedBase uintptr}
该结构体中的 bitmap 和 spans 与线性内存中的 bitmap 和 spans 区域一一对应,zeroedBase 字段指向了该结构体管理的内存的基地址。上述设计将原有的连续大内存切分成稀疏的小内存,而用于管理这些内存的元信息也被切成了小块。
不同平台和架构的二维数组大小可能完全不同,如果我们的 Go 语言服务在 Linux 的 x86-64 架构上运行,二维数组的一维大小会是 1,而二维大小是 4,194,304,因为每一个指针占用 8 字节的内存空间,所以元信息的总大小为 32MB。由于每个 runtime.heapArena 都会管理 64MB 的内存,整个堆区最多可以管理 256TB 的内存,这比之前的 512GB 多好几个数量级。
Go 语言团队在 1.11 版本中通过以下几个提交将线性内存变成稀疏内存,移除了 512GB 的内存上限以及堆区内存连续性的假设:
- runtime: use sparse mappings for the heap
- runtime: fix various contiguous bitmap assumptions
- runtime: make the heap bitmap sparse
- runtime: abstract remaining mheap.spans access
- runtime: make span map sparse
- runtime: eliminate most uses of mheap.arena*
- runtime: remove non-reserved heap logic
- runtime: move comment about address space sizes to malloc.go
由于内存的管理变得更加复杂,上述改动对垃圾回收稍有影响,大约会增加 1% 的垃圾回收开销,不过这也是我们为了解决已有问题必须付出的成本。
地址空间
因为所有的内存最终都是要从操作系统中申请的,所以 Go 语言的运行时构建了操作系统的内存管理抽象层,该抽象层将运行时管理的地址空间分成以下四种状态
| 状态 | 解释 |
|---|---|
| None | 内存没有被保留或者映射,是地址空间的默认状态 |
| Reserved | 运行时持有该地址空间,但是访问该内存会导致错误 |
| Prepared | 内存被保留,一般没有对应的物理内存访问该片内存的行为是未定义的可以快速转换到 Ready 状态 |
| Ready | 可以被安全访问 |
每个不同的操作系统都会包含一组用于管理内存的特定方法,这些方法可以让内存地址空间在不同的状态之间转换,我们可以通过下图了解不同状态之间的转换过程: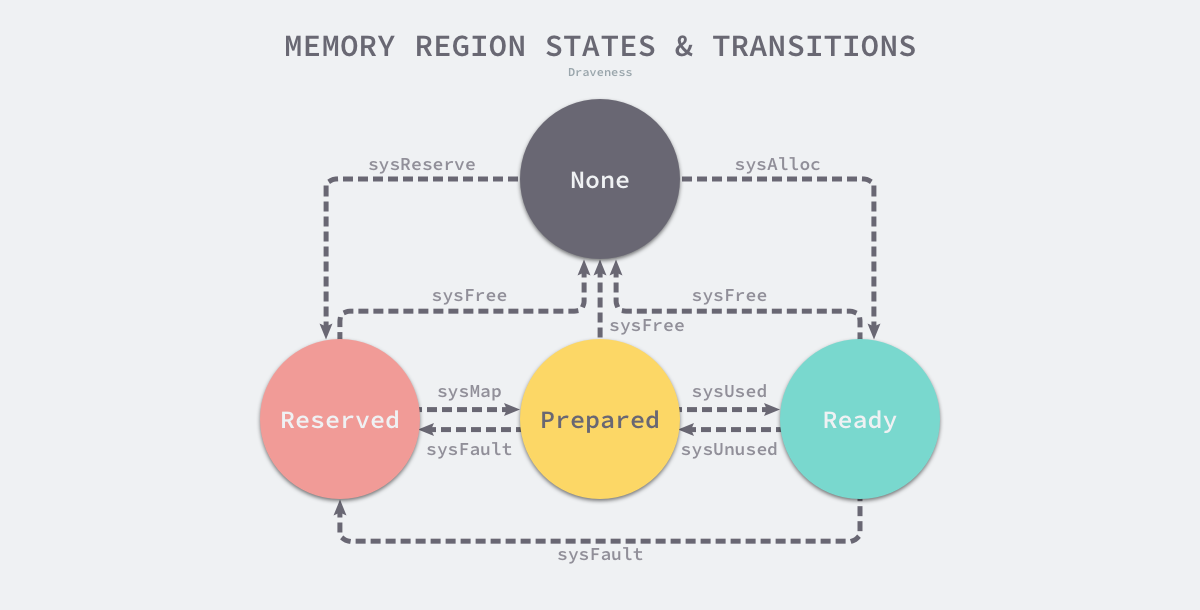
内存管理组件
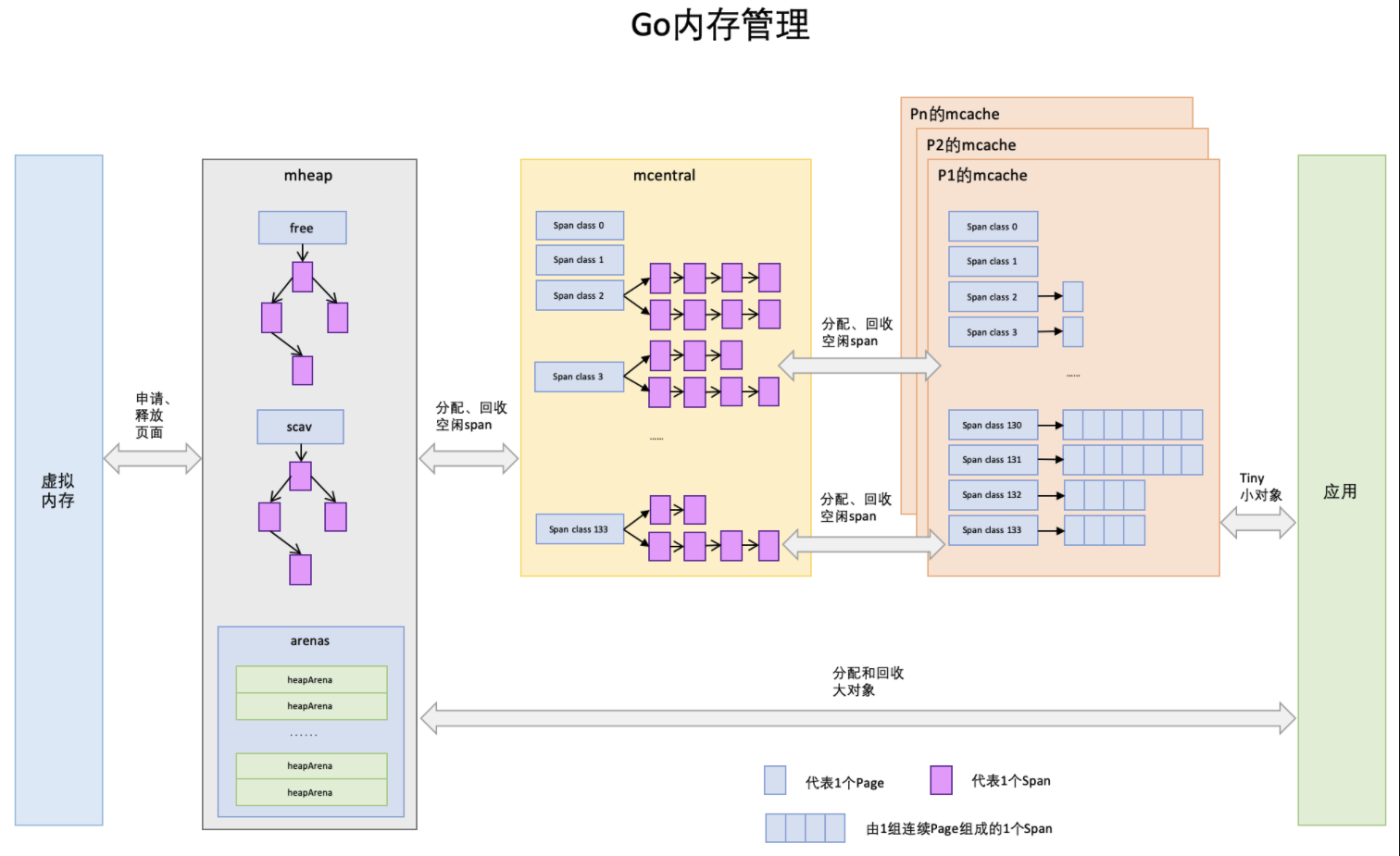
go的内存管理组件主要有:mspan、mcache、mcentral和mheap
mspan为内存管理的基础单元,直接存储数据的地方。mcache:每个运行期的goroutine都会绑定的一个mcache(具体来讲是绑定的GMP并发模型中的P,所以可以无锁分配mspan,后续还会说到),mcache会分配goroutine运行中所需要的内存空间(即mspan)。mcentral为所有mcache切分好后备的mspanmheap代表Go程序持有的所有堆空间。还会管理闲置的span,需要时向操作系统申请新内存。mspan
type mspan struct {next mspan // 双向链表中 指向下一个prev mspan // 双向链表中 指向前一个startAddr uintptr // 起始序号npages uintptr // 管理的页数manualFreeList gclinkptr // 待分配的 object 链表nelems uintptr // 块个数,表示有多少个块可供分配allocCount uint16 // 已分配块的个数...// 0 ~ _NumSizeClasses 之间的一个值,这个解释了我们的疑问。比如,sizeclass = 3,// 那么这个 mspan 被分割成 32 byte 的块。sizeclass uint8 // size class...// 通过 sizeclass 或者 npages 可以计算出来。比如 sizeclass = 3, elemsize = 32 byte// 对于大于 32Kb 的内存分配,都是分配整数页,elemsize = page_size * npageselemsize uintptr // computed from sizeclass or from npages...}
mspan可以说是go内存管理的最基本单元,但是内存的使用最终还是要落脚到“对象”上。mspan和对象是什么关系呢?
其实“对象”肯定也放到page中,毕竟page是内存存储的基本单元,
我们抛开问题不看,先看看一般情况下的对象和内存的分配是如何的:如下图
假如再分配“p4”的时候,是不是内存不足没法分配了?是不是有很多碎片?
这种一般的分配情况会出现内存碎片的情况,go是如何解决的呢?
可以归结为四个字:按需分配。go将内存块分为大小不同的67种,然后再把这67种大内存块,逐个分为小块(可以近似理解为大小不同的相当于page)称之为span(连续的page),在go语言中就是上文提及的mspan。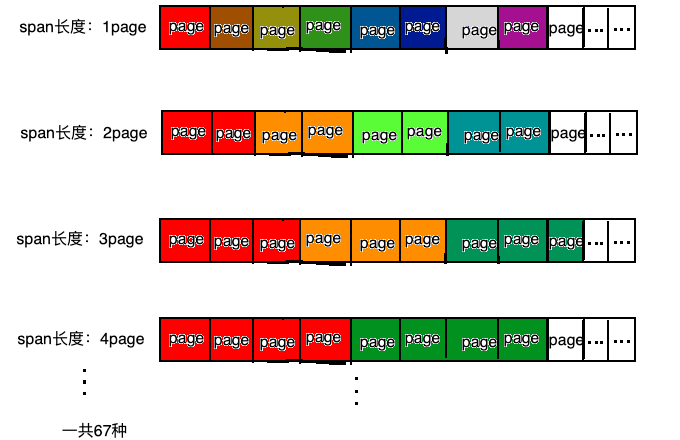
对象分配的时候,根据对象的大小选择大小相近的span,这样,碎片问题就解决了。
// class bytes/obj bytes/span objects tail waste max waste// 1 8 8192 1024 0 87.50%// 2 16 8192 512 0 43.75%// 3 32 8192 256 0 46.88%// 4 48 8192 170 32 31.52%..........................// 65 28672 57344 2 0 4.91%// 66 32768 32768 1 0 12.50%class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型bytes/obj:该class代表对象的字节数bytes/span:每个span占用堆的字节数,也即页数*页大小objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)
阅读方式如下:
以类型(class)为1的span为例,span中的元素大小是8 byte, span本身占1页也就是8K, 一共可以保存1024个对象
mcache
type mcache struct {next_sample uintptr // trigger heap sample after allocating this many byteslocal_scan uintptr // bytes of scannable heap allocatedtiny uintptr // 小对象分配器,小于 16 byte 的小对象都会通过 tiny 来分配tinyoffset uintptrlocal_tinyallocs uintptr // number of tiny allocs not counted in other stats// The rest is not accessed on every malloc.alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClassstackcache [_NumStackOrders]stackfreelist// Local allocator stats, flushed during GC.local_largefree uintptr // bytes freed for large objects (>maxsmallsize)local_nlargefree uintptr // number of frees for large objects (>maxsmallsize)local_nsmallfree [_NumSizeClasses]uintptr // number of frees for small objects (<=maxsmallsize)flushGen uint32 // 和gc相关}
我们知道每个 Gorontine 的运行都是绑定到一个 P 上面,mcache 是每个 P 的 cache。这么做的好处是分配内存时不需要加锁。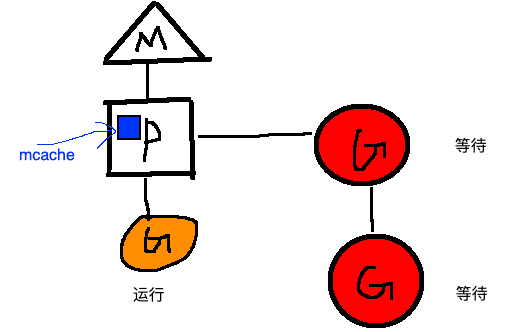
mcache中的span链表分为两组,一组是包含指针类型的对象,另一组是不包含指针类型的对象。为什么分开呢?
主要是方便GC,在进行垃圾回收的时候,对于不包含指针的对象列表无需进一步扫描是否引用其他活跃的对象
对于 <=32k的对象,将直接通过mcache分配。
在此,我觉的有必要说一下go中对象按照的大小维度的分类。
分为三类:
- tinny allocations (size < 16 bytes,no pointers)
- small allocations (16 bytes < size <= 32k)
- large allocations (size > 32k)
对于tiny allocations的分配,mcache有一个微型分配器tiny allocator来分配,分配的对象都是不包含指针的,例如一些小的字符串和不包含指针的独立的逃逸变量等。small allocations的分配,就是mcache根据对象的大小来找自身存在的大小相匹配mspan来分配。
当mcache没有可用空间时,会从mcentral的 mspans 列表获取一个新的所需大小规格的mspan
mcentral
为所有mcache提供切分好的mspan
上面说到当 mcache 不够用的时候,会从 mcentral 申请。那我们下面就来介绍一下 mcentral。
type mcentral struct {lock mutex // 因为会有多个 P 过来竞争sizeclass int32 // 也有成员 sizeclass,那么 mcentral 是不是也有 67 个呢?是的nonempty mSpanList // mspan 的双向链表,当前 mcentral 中可用的 mspan listempty mSpanList // 已经被使用的,可以认为是一种对所有 mspan 的 track}type mSpanList struct {first *mspanlast *mspan}
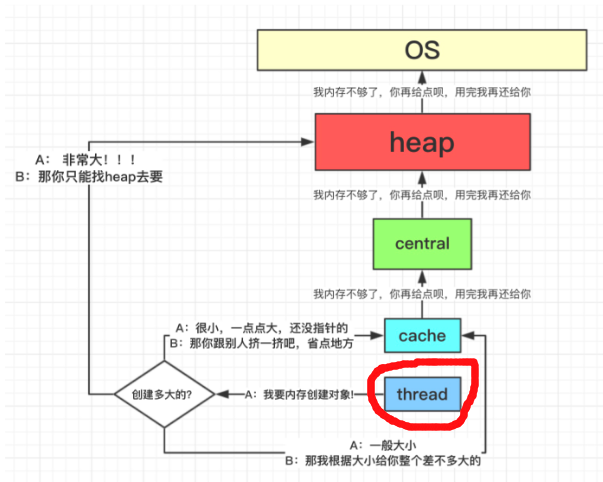
假如需要分配内存时,mcentral没有空闲的mspan列表了,此时需要向mheap去获取。
mheap
mheap可以认为是Go程序持有的整个堆空间,mheap全局唯一,可以认为是个全局变量。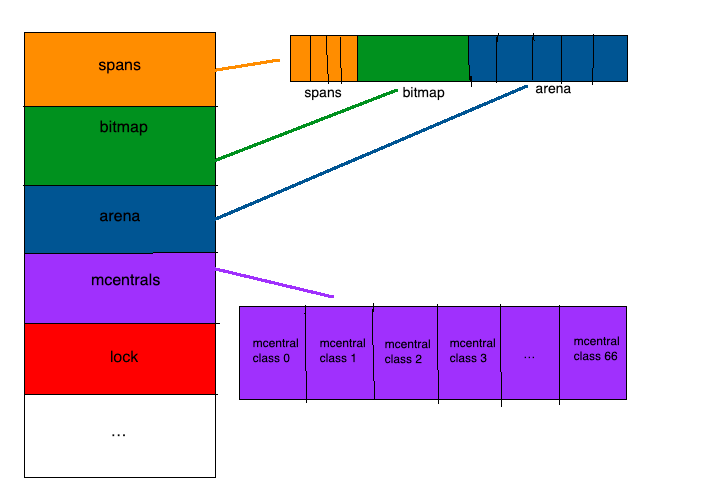
type mheap struct {lock mutexfree [_MaxMHeapList]mSpanList // free lists of given lengthfreelarge mSpanList // free lists length >= _MaxMHeapListbusy [_MaxMHeapList]mSpanList // busy lists of large objects of given lengthbusylarge mSpanList // busy lists of large objects length >= _MaxMHeapListsweepgen uint32 // sweep generation, see comment in mspansweepdone uint32 // all spans are swept// allspans is a slice of all mspans ever created. Each mspan// appears exactly once.//// The memory for allspans is manually managed and can be// reallocated and move as the heap grows.//// In general, allspans is protected by mheap_.lock, which// prevents concurrent access as well as freeing the backing// store. Accesses during STW might not hold the lock, but// must ensure that allocation cannot happen around the// access (since that may free the backing store).allspans []*mspan // all spans out there// spans is a lookup table to map virtual address page IDs to *mspan.// For allocated spans, their pages map to the span itself.// For free spans, only the lowest and highest pages map to the span itself.// Internal pages map to an arbitrary span.// For pages that have never been allocated, spans entries are nil.//// This is backed by a reserved region of the address space so// it can grow without moving. The memory up to len(spans) is// mapped. cap(spans) indicates the total reserved memory.spans []*mspan// sweepSpans contains two mspan stacks: one of swept in-use// spans, and one of unswept in-use spans. These two trade// roles on each GC cycle. Since the sweepgen increases by 2// on each cycle, this means the swept spans are in// sweepSpans[sweepgen/2%2] and the unswept spans are in// sweepSpans[1-sweepgen/2%2]. Sweeping pops spans from the// unswept stack and pushes spans that are still in-use on the// swept stack. Likewise, allocating an in-use span pushes it// on the swept stack.sweepSpans [2]gcSweepBuf_ uint32 // align uint64 fields on 32-bit for atomics// Proportional sweeppagesInUse uint64 // pages of spans in stats _MSpanInUse; R/W with mheap.lockspanBytesAlloc uint64 // bytes of spans allocated this cycle; updated atomicallypagesSwept uint64 // pages swept this cycle; updated atomicallysweepPagesPerByte float64 // proportional sweep ratio; written with lock, read without// TODO(austin): pagesInUse should be a uintptr, but the 386// compiler can't 8-byte align fields.// Malloc stats.largefree uint64 // bytes freed for large objects (>maxsmallsize)nlargefree uint64 // number of frees for large objects (>maxsmallsize)nsmallfree [_NumSizeClasses]uint64 // number of frees for small objects (<=maxsmallsize)// range of addresses we might see in the heapbitmap uintptr // Points to one byte past the end of the bitmapbitmap_mapped uintptrarena_start uintptrarena_used uintptr // always mHeap_Map{Bits,Spans} before updatingarena_end uintptrarena_reserved bool// central free lists for small size classes.// the padding makes sure that the MCentrals are// spaced CacheLineSize bytes apart, so that each MCentral.lock// gets its own cache line.central [_NumSizeClasses]struct {mcentral mcentralpad [sys.CacheLineSize]byte}spanalloc fixalloc // allocator for span*cachealloc fixalloc // allocator for mcache*specialfinalizeralloc fixalloc // allocator for specialfinalizer*specialprofilealloc fixalloc // allocator for specialprofile*speciallock mutex // lock for special record allocators.}var mheap_ mheap // 一个全局变量,会在系统初始化的时候初始化(在函数 mallocinit() 中)
初始化
在系统初始化阶段,上面介绍的几个结构会被进行初始化,我们直接看一下初始化代码:mallocinit()
func mallocinit() {......一系列检测......// Initialize the heap.mheap_.init() // 初始化全局的mheap_mcache0 = allocmcache()lockInit(&gcBitsArenas.lock, lockRankGcBitsArenas)lockInit(&proflock, lockRankProf)lockInit(&globalAlloc.mutex, lockRankGlobalAlloc)// Create initial arena growth hints.if sys.PtrSize == 8 {for i := 0x7f; i >= 0; i-- {var p uintptrswitch {case raceenabled:p = uintptr(i)<<32 | uintptrMask&(0x00c0<<32)if p >= uintptrMask&0x00e000000000 {continue}case GOARCH == "arm64" && GOOS == "ios":p = uintptr(i)<<40 | uintptrMask&(0x0013<<28)case GOARCH == "arm64":p = uintptr(i)<<40 | uintptrMask&(0x0040<<32)case GOOS == "aix":if i == 0 {// We don't use addresses directly after 0x0A00000000000000// to avoid collisions with others mmaps done by non-go programs.continue}p = uintptr(i)<<40 | uintptrMask&(0xa0<<52)default:p = uintptr(i)<<40 | uintptrMask&(0x00c0<<32)}hint := (*arenaHint)(mheap_.arenaHintAlloc.alloc())hint.addr = phint.next, mheap_.arenaHints = mheap_.arenaHints, hint}} else {// 32位机器,不用考虑}
内存分配
先说一下给对象 object 分配内存的主要流程:
- object size > 32K,则使用 mheap 直接分配。
- object size < 16 byte,使用 mcache 的小对象分配器 tiny 直接分配。 (其实 tiny 就是一个指针,暂且这么说吧。)
- object size > 16 byte && size <=32K byte 时,先使用 mcache 中对应的 size class 分配。
- 如果 mcache 对应的 size class 的 span 已经没有可用的块,则向 mcentral 请求。
- 如果 mcentral 也没有可用的块,则向 mheap 申请,并切分。
- 如果 mheap 也没有合适的 span,则向操作系统申请。 ```go package main
func foo() *int { x := 1 return &x }
func main() { x := foo() println(*x) }
根据之前介绍的逃逸分析,foo() 中的 x 会被分配到堆上。把上面代码保存为 test1.go 看一下汇编代码。```gogo build -gcflags '-l' -o test1 test1.go$ go tool objdump -s "main\.foo" test1TEXT main.foo(SB) /Users/didi/code/go/malloc_example/test2.gotest2.go:3 0x2040 65488b0c25a0080000 GS MOVQ GS:0x8a0, CXtest2.go:3 0x2049 483b6110 CMPQ 0x10(CX), SPtest2.go:3 0x204d 762a JBE 0x2079test2.go:3 0x204f 4883ec10 SUBQ $0x10, SPtest2.go:4 0x2053 488d1d66460500 LEAQ 0x54666(IP), BXtest2.go:4 0x205a 48891c24 MOVQ BX, 0(SP)test2.go:4 0x205e e82d8f0000 CALL runtime.newobject(SB)test2.go:4 0x2063 488b442408 MOVQ 0x8(SP), AXtest2.go:4 0x2068 48c70001000000 MOVQ $0x1, 0(AX)test2.go:5 0x206f 4889442418 MOVQ AX, 0x18(SP)test2.go:5 0x2074 4883c410 ADDQ $0x10, SPtest2.go:5 0x2078 c3 RETtest2.go:3 0x2079 e8a28d0400 CALL runtime.morestack_noctxt(SB)test2.go:3 0x207e ebc0 JMP main.foo(SB)
堆上内存分配调用了 runtime 包的 newobject 函数。
func newobject(typ *_type) unsafe.Pointer {return mallocgc(typ.size, typ, true)}func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {...c := gomcache()var x unsafe.Pointernoscan := typ == nil || typ.kind&kindNoPointers != 0if size <= maxSmallSize {// object size <= 32Kif noscan && size < maxTinySize {// 小于 16 byte 的小对象分配off := c.tinyoffset// Align tiny pointer for required (conservative) alignment.if size&7 == 0 {off = round(off, 8)} else if size&3 == 0 {off = round(off, 4)} else if size&1 == 0 {off = round(off, 2)}if off+size <= maxTinySize && c.tiny != 0 {// The object fits into existing tiny block.x = unsafe.Pointer(c.tiny + off)c.tinyoffset = off + sizec.local_tinyallocs++mp.mallocing = 0releasem(mp)return x}// Allocate a new maxTinySize block.span := c.alloc[tinySizeClass]v := nextFreeFast(span)if v == 0 {v, _, shouldhelpgc = c.nextFree(tinySizeClass)}x = unsafe.Pointer(v)(*[2]uint64)(x)[0] = 0(*[2]uint64)(x)[1] = 0// See if we need to replace the existing tiny block with the new one// based on amount of remaining free space.if size < c.tinyoffset || c.tiny == 0 {c.tiny = uintptr(x)c.tinyoffset = size}size = maxTinySize} else {// object size >= 16 byte && object size <= 32K bytevar sizeclass uint8if size <= smallSizeMax-8 {sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]} else {sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]}size = uintptr(class_to_size[sizeclass])span := c.alloc[sizeclass]v := nextFreeFast(span)if v == 0 {v, span, shouldhelpgc = c.nextFree(sizeclass)}x = unsafe.Pointer(v)if needzero && span.needzero != 0 {memclrNoHeapPointers(unsafe.Pointer(v), size)}}} else {//object size > 32K bytevar s *mspanshouldhelpgc = truesystemstack(func() {s = largeAlloc(size, needzero)})s.freeindex = 1s.allocCount = 1x = unsafe.Pointer(s.base())size = s.elemsize}}
整个分配过程可以根据 object size 拆解成三部分:size < 16 byte, 16 byte <= size <= 32 K byte, size > 32 K byte。
size 小于 16 byte
对于小于 16 byte 的内存块,mcache 有个专门的内存区域 tiny 用来分配,tiny 是指针,指向开始地址。
func mallocgc(...) {...off := c.tinyoffset// 地址对齐if size&7 == 0 {off = round(off, 8)} else if size&3 == 0 {off = round(off, 4)} else if size&1 == 0 {off = round(off, 2)}// 分配if off+size <= maxTinySize && c.tiny != 0 {// The object fits into existing tiny block.x = unsafe.Pointer(c.tiny + off)c.tinyoffset = off + sizec.local_tinyallocs++mp.mallocing = 0releasem(mp)return x}// tiny 不够了,为其重新分配一个 16 byte 内存块span := c.alloc[tinySizeClass]v := nextFreeFast(span)if v == 0 {v, _, shouldhelpgc = c.nextFree(tinySizeClass)}x = unsafe.Pointer(v)//将申请的内存块全置为 0(*[2]uint64)(x)[0] = 0(*[2]uint64)(x)[1] = 0// See if we need to replace the existing tiny block with the new one// based on amount of remaining free space.// 如果申请的内存块用不完,则将剩下的给 tiny,用 tinyoffset 记录分配了多少。if size < c.tinyoffset || c.tiny == 0 {c.tiny = uintptr(x)c.tinyoffset = size}size = maxTinySize}
如上所示,tinyoffset 表示 tiny 当前分配到什么地址了,之后的分配根据 tinyoffset 寻址。先根据要分配的对象大小进行地址对齐,比如 size 是 8 的倍数,tinyoffset 和 8 对齐。然后就是进行分配。如果 tiny 剩余的空间不够用,则重新申请一个 16 byte 的内存块,并分配给 object。如果有结余,则记录在 tiny 上。
size 大于 32 K byte
对于大于 32 Kb 的内存分配,直接跳过 mcache 和 mcentral,通过 mheap 分配
func mallocgc(...) {} else {var s *mspanshouldhelpgc = truesystemstack(func() {s = largeAlloc(size, needzero)})s.freeindex = 1s.allocCount = 1x = unsafe.Pointer(s.base())size = s.elemsize}...}func largeAlloc(size uintptr, needzero bool) *mspan {...npages := size >> _PageShiftif size&_PageMask != 0 {npages++}...s := mheap_.alloc(npages, 0, true, needzero)if s == nil {throw("out of memory")}s.limit = s.base() + sizeheapBitsForSpan(s.base()).initSpan(s)return s}
size 介于 16byte 和 32K
对于 size 介于 16byte ~ 32K byte 的内存分配先计算应该分配的 sizeclass,然后去 mcache 里面 alloc[sizeclass] 申请,如果 mcache.alloc[sizeclass] 不足以申请,则 mcache 向 mcentral 申请,然后再分配。mcentral 给 mcache 分配完之后会判断自己需不需要扩充,如果需要则想 mheap 申请。
func mallocgc(...) {...} else {var sizeclass uint8//计算 sizeclassif size <= smallSizeMax-8 {sizeclass = size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]} else {sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv- 1)/largeSizeDiv]}size = uintptr(class_to_size[sizeclass])span := c.alloc[sizeclass]//从对应的 span 里面分配一个 objectv := nextFreeFast(span)if v == 0 {v, span, shouldhelpgc = c.nextFree(sizeclass)}x = unsafe.Pointer(v)if needzero && span.needzero != 0 {memclrNoHeapPointers(unsafe.Pointer(v), size)}}}
allocCache 这里是用位图表示内存是否可用,1 表示可用。然后通过 span 里面的 freeindex 和 elemsize 来计算地址即可。
如果 mcache.alloc[sizeclass] 已经不够用了,则从 mcentral 申请内存到 mcache。
func (c *mcache) nextFree(sizeclass uint8) (v gclinkptr, s *mspan, shouldhelpgc bool) {s = c.alloc[sizeclass]shouldhelpgc = falsefreeIndex := s.nextFreeIndex()if freeIndex == s.nelems {// The span is full.if uintptr(s.allocCount) != s.nelems {println("runtime: s.allocCount=", s.allocCount, "s.nelems=", s.nelems)throw("s.allocCount != s.nelems && freeIndex == s.nelems")}systemstack(func() {// 这个地方 mcache 向 mcentral 申请c.refill(int32(sizeclass))})shouldhelpgc = trues = c.alloc[sizeclass]// mcache 向 mcentral 申请完之后,再次从 mcache 申请freeIndex = s.nextFreeIndex()}...}// nextFreeIndex returns the index of the next free object in s at// or after s.freeindex.// There are hardware instructions that can be used to make this// faster if profiling warrants it.// 这个函数和 nextFreeFast 有点冗余了func (s *mspan) nextFreeIndex() uintptr {...}
mcache 向 mcentral,如果 mcentral 不够,则向 mheap 申请
func (c *mcache) refill(sizeclass int32) *mspan {...// 向 mcentral 申请s = mheap_.central[sizeclass].mcentral.cacheSpan()...return s}// Allocate a span to use in an MCache.func (c *mcentral) cacheSpan() *mspan {...// Replenish central list if empty.s = c.grow()}func (c *mcentral) grow() *mspan {npages := uintptr(class_to_allocnpages[c.sizeclass])size := uintptr(class_to_size[c.sizeclass])n := (npages << _PageShift) / size//这里想 mheap 申请s := mheap_.alloc(npages, c.sizeclass, false, true)...return s}
如果 mheap 不足,则向 OS 申请。接上面的代码 mheap_.alloc()
func (h *mheap) alloc(npage uintptr, sizeclass int32, large bool, needzero bool) *mspan {...var s *mspansystemstack(func() {s = h.alloc_m(npage, sizeclass, large)})...}func (h *mheap) alloc_m(npage uintptr, sizeclass int32, large bool) *mspan {...s := h.allocSpanLocked(npage)...}func (h *mheap) allocSpanLocked(npage uintptr) *mspan {...s = h.allocLarge(npage)if s == nil {if !h.grow(npage) {return nil}s = h.allocLarge(npage)if s == nil {return nil}}...}func (h *mheap) grow(npage uintptr) bool {// Ask for a big chunk, to reduce the number of mappings// the operating system needs to track; also amortizes// the overhead of an operating system mapping.// Allocate a multiple of 64kB.npage = round(npage, (64<<10)/_PageSize)ask := npage << _PageShiftif ask < _HeapAllocChunk {ask = _HeapAllocChunk}v := h.sysAlloc(ask)...}
总体
转自:
https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-memory-allocator/

若有收获,就点个赞吧
0 人点赞
