Token是编程语言中最小的具有独立含义的词法单元。
Token不仅仅包含关键字,还包含用户自定义的标识符、运算符、分隔符和注释等。每个Token对应的词法单元有三个属性是比较重要的:首先是Token本身的值表示词法单元的类型,其次是Token在源代码中源代码文本形式,最后是Token出现的位置。
Go语言中主要有标识符、关键字、运算符和分隔符等类型等Token组成。其中标识符的语法定义如下:
identifier = letter { letter | unicode_digit } .letter = unicode_letter | "_" .
identifier表示标识符,由字母和数字组成
在标识符中有一类特殊的标识符被定义为关键字。关键字用于引导特殊的语法结构,不能将关键字作为独立的标识符()。下面是Go语言定义的25个关键字:
break default func interface selectcase defer go map structchan else goto package switchconst fallthrough if range typecontinue for import return var
除了标识符和关键字,Token还包含运算符和分隔符。下面是Go语言定义的47个符号:
+ & += &= && == != ( )- | -= |= || < <= [ ]* ^ *= ^= <- > >= { }/ << /= <<= ++ = := , ;% >> %= >>= -- ! ... . :&^ &^=
当然,除了用户自定义的标识符、25个关键字、47个运算和分隔符号,程序中还有一些面值、注释和空白符组成。要解析一个Go语言程序,第一步就是要解析这些Token。
type Token
Token被定义为一种枚举值,不同值的Token表示不同类型的词法记号
所有的Token被分为四类:特殊类型的Token、基础面值对应的Token、运算符Token和关键字。
type Token int// The list of tokens.const (......)func Lookup(ident string) Tokenfunc (tok Token) IsKeyword() boolfunc (tok Token) IsLiteral() boolfunc (tok Token) IsOperator() boolfunc (op Token) Precedence() intfunc (tok Token) String() string
type Position
Position描述任意源位置,包括文件、行和列位置。如果行号为> 0,则Position有效。
type Position struct {Filename string // filename, if anyOffset int // offset, starting at 0Line int // line number, starting at 1Column int // column number, starting at 1 (byte count)}func (pos *Position) IsValid() boolfunc (pos Position) String() string
func main() {a := token.Position{Filename: "hello.go", Line: 1, Column: 2}b := token.Position{Filename: "hello.go", Line: 1}c := token.Position{Filename: "hello.go"}d := token.Position{Line: 1, Column: 2}e := token.Position{Line: 1}f := token.Position{Column: 2}fmt.Println(a.String())fmt.Println(b.String())fmt.Println(c.String())fmt.Println(d.String())fmt.Println(e.String())fmt.Println(f.String())}hello.go:1:2hello.go:1hello.go1:21-
type Pos
Pos是FileSet的全局偏移量,反之也可以通过Pos查询对应的File,以及对应File内部的offset
type Pos intfunc (p Pos) IsValid() bool
FileSet 和 File
在定义Token之后,其实我们可以通过手工方式对源代码进行简单的词法分析了。不过如果希望以后能够复用词法分析的代码,则需要小心设计和源代码部分相关的接口。参考Go语言本身,它是由多个文件组成包,然后多个包链接为一个可执行文件,所以单个包对应的多个文件可以看作是Go语言的基本编译单元。因此go/token包还定义了FileSet和File对象,用于描述文件集和文件。
FileSet和File对象的对应关系如图所示: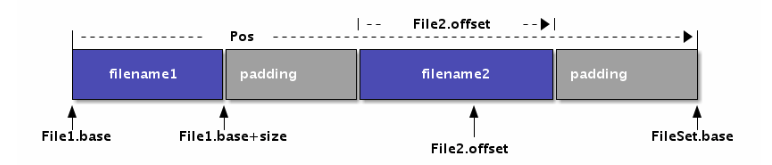
每个FileSet表示一个文件集合,底层抽象为一个一维数组,而Pos类型表示数组的下标位置。FileSet中的每个File元素对应底层数组的一个区间,不同的File之间没有交集,相邻的File之间可能存在填充空间。
而每个File主要由文件名、base和size三个信息组成。其中base对应File在FileSet中的Pos索引位置,因此base和base+size定义了File在FileSet数组中的开始和结束位置。
在每个File内部可以通过offset定位下标索引,通过offset+File.base可以将File内部的offset转换为Pos位置。因为Pos是FileSet的全局偏移量,反之也可以通过Pos查询对应的File,以及对应File内部的offset。
而词法分析的每个Token位置信息就是由Pos定义,通过Pos和对应的FileSet可以轻松查询到对应的File。然后在通过File对应的源文件和offset计算出对应的行号和列号(实现中File只是保存了每行的开始位置,并没有包含原始的源代码数据)。Pos底层是int类型,它和指针的语义类似,因此0也类似空指针被定义为NoPos,表示无效的Pos。

若有收获,就点个赞吧
0 人点赞
