原文:
https://blog.csdn.net/fengshenyun/article/details/100582679
https://github.com/qcrao/Go-Questions/tree/master/map
Golang的map是用哈希表实现的,在实现性能上非常优秀,这里会主要对map创建、插入、查询、删除以及删除全部的源码做详解,刻意避开了扩容以及迭代相关的代码,后续会用一个新的文章去讲述。Golang好几个版本都对map源码进行了重构,整体逻辑变化不大,但实现细节上有很大优化,下面介绍是1.12.5版本的源码。
维基百科里这样定义 map:
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type composed of a collection of (key, value) pairs, such that each possible key appears at most once in the collection.
简单说明一下:在计算机科学里,被称为相关数组、map、符号表或者字典,是由一组 <key, value> 对组成的抽象数据结构,,并且同一个 key 只会出现一次。
有两个关键点:map 是由 key-value 对组成的;key 只会出现一次。
和 map 相关的操作主要是:
- 增加一个 k-v 对 —— Add or insert;
- 删除一个 k-v 对 —— Remove or delete;
- 修改某个 k 对应的 v —— Reassign;
- 查询某个 k 对应的 v —— Lookup;
简单说就是最基本的 增删查改。
map 的设计也被称为 “The dictionary problem”,它的任务是设计一种数据结构用来维护一个集合的数据,并且可以同时对集合进行增删查改的操作。最主要的数据结构有两种:哈希查找表(Hash table)、搜索树(Search tree)。
哈希查找表用一个哈希函数将 key 分配到不同的桶(bucket,也就是数组的不同 index)。这样,开销主要在哈希函数的计算以及数组的常数访问时间。在很多场景下,哈希查找表的性能很高。
哈希查找表一般会存在“碰撞”的问题,就是说不同的 key 被哈希到了同一个 bucket。一般有两种应对方法:链表法和开放地址法。链表法将一个 bucket 实现成一个链表,落在同一个 bucket 中的 key 都会插入这个链表。开放地址法则是碰撞发生后,通过一定的规律,在数组的后面挑选“空位”,用来放置新的 key。
搜索树法一般采用自平衡搜索树,包括:AVL 树,红黑树。面试时经常会被问到,甚至被要求手写红黑树代码,很多时候,面试官自己都写不上来,非常过分。
自平衡搜索树法的最差搜索效率是 O(logN),而哈希查找表最差是 O(N)。当然,哈希查找表的平均查找效率是 O(1),如果哈希函数设计的很好,最坏的情况基本不会出现。还有一点,遍历自平衡搜索树,返回的 key 序列,一般会按照从小到大的顺序;而哈希查找表则是乱序的。
1、名词解释
对哈希桶、桶链、桶、溢出桶做一下区分,方便后面阅读。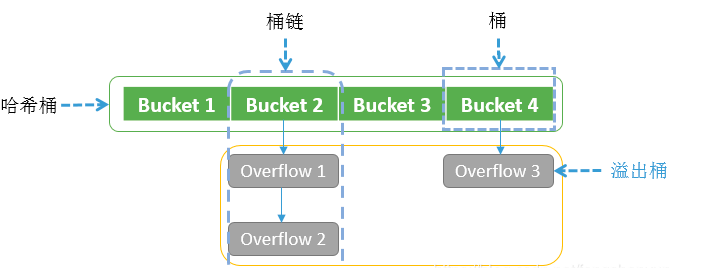
哈希桶
指整个哈希数组,数组内每个元素是一个桶。
桶链
哈希桶的一个桶以及该桶下挂着的所有溢出桶。
桶(bucket)
一个bmap结构,与溢出桶的区别在于它是哈希桶数组上的一个元素。
溢出桶(overflow bucket)
一个bmap结构,与桶区别是,它不是哈希桶数组的元素,而是挂在哈希桶数组上或挂在其它溢出桶上。
负载因子(overFactor)
表示平均每个哈希桶的元素个数(注意是哈希桶,不包括溢出桶)。如当前map中总共有20个元素,哈希桶长度为4,则负载因子为5。负载因子主要是来判断当前map是否需要扩容。
新、旧哈希桶
新、旧哈希桶的概念只存在于map扩容阶段,在哈希桶扩容时,会申请一个新的哈希桶,原来的哈希桶变成了旧哈希桶,然后会分步将旧哈希桶的元素迁移到新桶上,当旧哈希桶所有元素都迁移完成时,旧哈希桶会被释放掉。
2、整体设计
2.1 文件组成
map的源代码都在src/runtime目录下,主要由4个文件组成:
- map.go
- map_fast32.go
- map_fast64.go
- map_faststr.go
主体实现都在map.go文件中,其它三个文件分别对特点类型的key做了优化。如下:
- map_fast32.go,针对key类型为int32\uint32做了优化
- map_fast64.go,针对key类型为int\int64\uint64\pointer做了优化
map_faststr.go,针对key类型为string做了优化
2.2 优化功能
插入
删除 (不包括删除全部)
查询 (不包括迭代遍历)
扩容迁移2.3 优化具体内容
1 查询上的优化 (插入、删除、查询都会用到查询)
当只有一个哈希桶时,不计算hash值,直接遍历查找整个桶。
当多于一个哈希桶时fast32\64,省略了tophash的比较,在比较时直接比较key的值;
- string,省略了tophash的比较,多了一个字符串长度的比较,且在比较具体key时,直接通过内置的memequal。
2 内存管理上的优化
3. 数据结构
3.1 hmap
map实现的底层结构是hmap,每声明一个map就有一个hmap结构体与之对应,具体如下: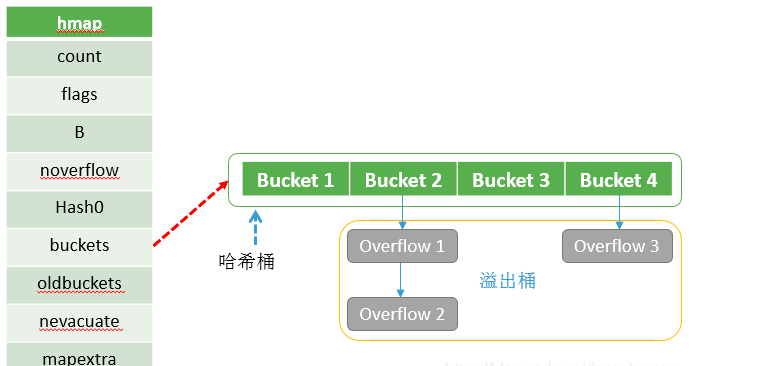
@(src/runtime/map.go)
在源码中,表示 map 的结构体是 hmap,它是 hashmap 的“缩写”:
// A header for a Go map.type hmap struct {// 元素个数,调用 len(map) 时,直接返回此值count intflags uint8// buckets 的对数 log_2B uint8// overflow 的 bucket 近似数noverflow uint16// 计算 key 的哈希的时候会传入哈希函数hash0 uint32// 指向 buckets 数组,大小为 2^B// 如果元素个数为0,就为 nilbuckets unsafe.Pointer// 扩容的时候,buckets 长度会是 oldbuckets 的两倍oldbuckets unsafe.Pointer// 指示扩容进度,小于此地址的 buckets 迁移完成nevacuate uintptrextra *mapextra // optional fields}
3.2 bmap
bmap(bucket map),描述一个桶,即可以是哈希桶也可以是溢出桶。但下面的结构体只含有一个tophash,用于桶内快速查找,并没有存K/V的地方。从下面定义里面两个Followed定义可以看出,其实bmap只给出了部分字段的描述,后面还有一块存K/V的内存,以及一个指向溢出桶的指针。之所以不给出全部描述,是因为K/V的内存块大小会随着K/V的类型不断变化,无法固定写死,在使用时也只能通过指针偏移的方式去取用。
buckets 是一个指针,最终它指向的是一个结构体:
type bmap struct {tophash [bucketCnt]uint8}
但这只是表面(src/runtime/hashmap.go)的结构,编译期间会给它加料,动态地创建一个新的结构:
type bmap struct {topbits [8]uint8keys [8]keytypevalues [8]valuetypepad uintptroverflow uintptr}
bmap 就是我们常说的“桶”,桶里面会最多装 8 个 key,这些 key 之所以会落入同一个桶,是因为它们经过哈希计算后,哈希结果是“一类”的。在桶内,又会根据 key 计算出来的 hash 值的高 8 位来决定 key 到底落入桶内的哪个位置(一个桶内最多有8个位置)。
来一个整体的图:
当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的情况下,会把 bmap 标记为不含指针,这样可以避免 gc 时扫描整个 hmap。但是,我们看 bmap 其实有一个 overflow 的字段,是指针类型的,破坏了 bmap 不含指针的设想,这时会把 overflow 移动到 extra 字段来。
type mapextra struct {// overflow[0] contains overflow buckets for hmap.buckets.// overflow[1] contains overflow buckets for hmap.oldbuckets.overflow [2]*[]*bmap// nextOverflow 包含空闲的 overflow bucket,这是预分配的 bucketnextOverflow *bmap}
bmap 是存放 k-v 的地方,我们把视角拉近,仔细看 bmap 的内部组成。
上图就是 bucket 的内存模型,HOB Hash 指的就是 top hash。 注意到 key 和 value 是各自放在一起的,并不是 key/value/key/value/... 这样的形式。源码里说明这样的好处是在某些情况下可以省略掉 padding 字段,节省内存空间。
例如,有这样一个类型的 map: map[int64]int8
如果按照 key/value/key/value/... 这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式 key/key/.../value/value/...,则只需要在最后添加 padding。
每个 bucket 设计成最多只能放 8 个 key-value 对,如果有第 9 个 key-value 落入当前的 bucket,那就需要再构建一个 bucket ,通过 overflow 指针连接起来。
const(...bucketCntBits = 3bucketCnt = 1 << bucketCntBits...)
4 源码解析
4.1. map创建
4.1.1 语法
不带参数make(map[keyType]valueType)带参数make(map[keyType]valueType, size)
4.1.2 源码分析
整体思路
- 创建hmap,并初始化。
- 获取一个随机种子,保证同一个key在不同map的hash值不一样(安全考量)。
- 计算初始桶大小。
- 如果初始桶大小不为0, 则创建桶,有必要还要创建溢出桶结构。
通过汇编语言可以看到,实际上底层调用的是 makemap 函数,主要做的工作就是初始化 hmap 结构体的各种字段,例如计算 B 的大小,设置哈希种子 hash0 等等。
@(src/runtime/map.go:305)
func makemap(t *maptype, hint int, h *hmap) *hmap {...// 1. initialize Hmapif h == nil {h = new(hmap)}// 2. initialize hash randh.hash0 = fastrand()// 3. calcate bucket sizeB := uint8(0)for overLoadFactor(hint, B) {B++}h.B = B// 4. allocate initial hash table// if B == 0, the buckets field is allocated lazily later (in mapassign)// If hint is large zeroing this memory could take a while.if h.B != 0 {var nextOverflow *bmaph.buckets, nextOverflow = makeBucketArray(t, h.B, nil)if nextOverflow != nil {h.extra = new(mapextra)h.extra.nextOverflow = nextOverflow}}return h}
4.1.3 哈希桶初始大小
在创建map时,当没有指定size大小或size为0时,不会创建哈希桶,会在插入元素时创建,避免只申请不使用导致的效率和内存浪费。当size不为0时,会根据size大小计算出哈希桶的大小,具体计算算法如下:
源码
@(src/runtime/map.go)
func overLoadFactor(count int, B uint8) bool {return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)}
写了个小demo来探测size对bucket长度的影响,大致是这样:
(1) size <9,bucketLen = 1 (2^0) B=0
(2) size < 14,bucketLen = 2 (2^1) B=1
(3) size < 27,bucketLen = 4 (2^2) B=2
(4) size < 53,bucketLen = 8 (2^3) B=3
(5) size < 104,bucketLen = 16 (2^4) B=4
…
从这些数据反推overLoadFactor方法的函义:
第二行与第一行size之差A=5,bucket长度差为1,A/B=5。
第三行与第二行size之差A=13,bucket长度差B=2,A/B=6.5。
第四行与第三行size之差A=26,bucket长度差B=4,A/B=6.5。
第五行与第四行size之差A=51,bucket长度差B=8,A/B=6.375。
…
结论:
1 哈希桶的大小是2的整数次幂
2 哈希桶大小 = size / 6.5
验证demo
@(demo源码)
package mainimport "fmt"func bucketShift(b uint8) uintptr {return uintptr(1) << b}func overLoadFactor(count int, B uint8) bool {return count > 8 && uintptr(count) > 13*(bucketShift(B)/2)}func bucketLen(hint int) uint8 {B := uint8(0)for overLoadFactor(hint, B) {B++}return B}func main() {for i := 0; i < 100; i++ {fmt.Println(i, bucketLen(i))}}
4.1.4 map作为参数传递
Go 语言中的函数传参都是值传递,在函数内部,参数会被 copy 到本地。*hmap指针 copy 完之后,仍然指向同一个 map,因此函数内部对 map 的操作会影响实参,一定要和slice区分开
4.2 map查找
4.2.1 语法
第一种用法,只返回value值,当key在map中没有找到时,返回value对应类型的默认值。
m := make(map[string]int)print(m["1"]) -- 结果为: 0 (返回int对应的默认值)
第二种用法,返回value值以及key是否存在标志
m := make(map[string]int)
val, ok := m["1"]print(val, ok) -- 结果为:0, false
- 第三种用法,返回key和value,只用于range迭代场景
m := make(map[string]int)for k, v := range m {}
4.2.2 源码分析
三种方法的对处理查找逻辑的源码差不多,差别只是在于返回值,只需分析一个方法的源码即可。
整体思路
- 校验map是否正在写,如果是,则直接报”concurrent map read and map write”错误
- 计算key哈希值,并根据哈希值计算出key所在桶链位置
- 计算tophash值,便于快速查找
- 遍历桶链上的每一个桶,并依次遍历桶内的元素
- 先比较tophash,如果tophash不一致,再比较下一个,如果tophash一致,再比较key值是否相等
- 如果key值相等,计算出value的地址,并取出value值,并直接返回
- 如果key值不相等,则继续比较下一个元素,如果所有元素都不匹配,则直接返回value类型的默认值
源码
@(src/runtime/map.go)
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {...// 判断是否正在写,如果是直接报错if h.flags&hashWriting != 0 {throw("concurrent map read and map write")}// 计算key哈希值alg := t.key.alghash := alg.hash(key, uintptr(h.hash0))// 计算桶链首地址m := bucketMask(h.B)b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))// 计算tophash值top := tophash(hash)bucketloop:// 遍历桶链每个桶for ; b != nil; b = b.overflow(t) {// 遍历桶的元素,bucketCnt固定为8for i := uintptr(0); i < bucketCnt; i++ {// 如果tophash不相等,continueif b.tophash[i] != top {if b.tophash[i] == emptyRest {break bucketloop}continue}// tophash相等// 获取当前位置对应的key值k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))if t.indirectkey() {k = *((*unsafe.Pointer)(k))}// 如果与key匹配,表明找到了,直接返回value值if alg.equal(key, k) {v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))if t.indirectvalue() {v = *((*unsafe.Pointer)(v))}return v}}}// 一直没有找到,返回value类型的默认值return unsafe.Pointer(&zeroVal[0])}
4.3 map插入(更新)
map的添加和更新是通过一个方法实现的,在往map里面插入一个K/V时,如果key已经存在,就直接覆盖更新;如果key不存在,就插入map。
4.3.1 语法
m[key] = value
4.3.2 源码分析
整体思路
- 1 校验map是否正在写,如果是,则直接报”concurrent map writes”错误
- 2 设置写标志
- 3 计算key的哈希值
- 4 如果哈希桶是空的,则创建哈希桶,桶大小为1
- 5 计算桶链首地址(用于遍历该桶及该桶得溢出桶)和tophash
- 6 找到桶链下的所有桶的元素,看key是否已经存在,如果存在,直接把value写入对应位置,跳到步骤10
- 7 在查找过程中,会记录下桶里面第一个空元素的位置
- 8 如果没有空位置,则需要申请一个溢出桶,并把该溢出桶挂在该桶链下
- 9 把K/V插入到空闲位置
- 10 map元素总个数加1
- 11 清除写标志
源码
@(src/runtime/map.go:576)
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {...// 如果正在写,则直接报错if h.flags&hashWriting != 0 {throw("concurrent map writes")}// 计算插入key的hash值alg := t.key.alghash := alg.hash(key, uintptr(h.hash0))// 设置写标记h.flags ^= hashWriting// 如果当前哈希桶为空,则新建一个大小为1的哈希桶if h.buckets == nil {h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)}again:// 计算桶链的位置以及tophashbucket := hash & bucketMask(h.B)...b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))top := tophash(hash)// 用于记录第一个空闲k/V的位置var inserti *uint8var insertk unsafe.Pointervar val unsafe.Pointerbucketloop:// 遍历桶链的每个桶for {// 遍历桶内元素for i := uintptr(0); i < bucketCnt; i++ {// tophash不相等,继续判断下一个元素if b.tophash[i] != top {// 记录第一个空闲K/V位置if isEmpty(b.tophash[i]) && inserti == nil {inserti = &b.tophash[i]insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))}if b.tophash[i] == emptyRest {break bucketloop}continue}// tophash相等// 获取当前位置对应的key值k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))if t.indirectkey() {k = *((*unsafe.Pointer)(k))}// 如果不相等,继续比较下一个if !alg.equal(key, k) {continue}// 更新keyif t.needkeyupdate() {typedmemmove(t.key, k, key)}// 更新valueval = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))goto done}// 计算下一个桶的地址ovf := b.overflow(t)// 如果桶链下的元素全部遍历完了,则退出遍历if ovf == nil {break}b = ovf}// 没有匹配到key, 即刚插入的K/V是新增// 如果没有找到空闲位置,则新申请一个新溢出桶,并把新溢出桶挂到桶链上// 将inserti,insertk指向空闲K/V位置if inserti == nil {// all current buckets are full, allocate a new one.newb := h.newoverflow(t, b)inserti = &newb.tophash[0]insertk = add(unsafe.Pointer(newb), dataOffset)val = add(insertk, bucketCnt*uintptr(t.keysize))}// 插入keyif t.indirectkey() {kmem := newobject(t.key)*(*unsafe.Pointer)(insertk) = kmeminsertk = kmem}// 插入valueif t.indirectvalue() {vmem := newobject(t.elem)*(*unsafe.Pointer)(val) = vmem}typedmemmove(t.key, insertk, key)*inserti = top// map元素加1h.count++done:// 现次判断是否有并发写if h.flags&hashWriting == 0 {throw("concurrent map writes")}// 清空写标记h.flags &^= hashWritingif t.indirectvalue() {val = *((*unsafe.Pointer)(val))}return val}
4.4 map删除
4.4.1 语法
delete(map, key)
4.4.2 源码分析
整体思路
- 1 校验map是否正在写,如果是,则直接报”concurrent map writes”错误
- 2 设置写标志
- 3 计算key的哈希值
- 4 计算桶链首地址(用于遍历该桶及该桶得溢出桶)和tophash
- 5 找到桶链下的所有桶的元素,如果找到key,处理指针相关(这块后面详解)
- 6 设置该位置的tophash值,这个逻辑比较复杂,详细会在tophash详解里面介绍
- 7 map总元素个数减1
- 8 清除写标志
源码
@(src/runtime/map.go:691)
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {...// 如果正在写,则直接报错if h.flags&hashWriting != 0 {throw("concurrent map writes")}// 计算插入key的hash值alg := t.key.alghash := alg.hash(key, uintptr(h.hash0))// 设置写标记h.flags ^= hashWriting// 计算桶链的位置以及tophashbucket := hash & bucketMask(h.B)...b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))bOrig := btop := tophash(hash)search:// 遍历桶链每个桶for ; b != nil; b = b.overflow(t) {// 遍历桶的每个元素for i := uintptr(0); i < bucketCnt; i++ {// tophash不相等,继续判断下一个元素if b.tophash[i] != top {if b.tophash[i] == emptyRest {break search}continue}// tophash相等// 获取当前位置对应的key值k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))k2 := kif t.indirectkey() {k2 = *((*unsafe.Pointer)(k2))}// 如果不相等,继续比较下一个if !alg.equal(key, k2) {continue}// 如果是指针或含有指针,处理指针if t.indirectkey() {*(*unsafe.Pointer)(k) = nil} else if t.key.kind&kindNoPointers == 0 {memclrHasPointers(k, t.key.size)}// 计算出value位置,处理指针v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))if t.indirectvalue() {*(*unsafe.Pointer)(v) = nil} else if t.elem.kind&kindNoPointers == 0 {memclrHasPointers(v, t.elem.size)} else {memclrNoHeapPointers(v, t.elem.size)}// 重新计算该位置tophash的值b.tophash[i] = emptyOne...notLast:// map总元素个数减1h.count--break search}}// 清空写标记if h.flags&hashWriting == 0 {throw("concurrent map writes")}h.flags &^= hashWriting}
4.5 map删除所有
4.5.1 用法
通过Go的内部函数mapclear方法删除。这个函数并没有显示的调用方法,当你使用for循环遍历删除所有元素时,Go的编译器会优化成Go内部函数mapclear。
for k := range m {delete(m, k)}
4.5.2 demo分析
package mainfunc main() {m := make(map[byte]int)m[1] = 1m[2] = 2for k := range m {delete(m, k)}}
把上述源代码直接编译成汇编(默认是有编译器优化的):
go tool compile -S map_clear.go
可以看到编译器把源码9行的for循环直接优化成了mapclear去删除所有元素。
4.5.3 源码分析
这部分代码涉及到内存管理和GC,只能看懂个大概,后续再补充。
整体思路
- 清空统计数据,如元素个数、溢出数等。
- 重新申请一个新的extra,原有的extra交给GC。
- 释放桶内存块。
源码
@(src/runtime/map.go:981)
func mapclear(t *maptype, h *hmap) {...// 把oldbuckets置nil,如果有oldbuckets就让GC处理h.oldbuckets = nil// 初始化溢出数、元素个数h.nevacuate = 0h.noverflow = 0h.count = 0// 重新申请一个新的extra,旧的交给GC回收if h.extra != nil {*h.extra = mapextra{}}// 清空bucket_, nextOverflow := makeBucketArray(t, h.B, h.buckets)...}
5.哈希函数
map 的一个关键点在于,哈希函数的选择。在程序启动时,会检测 cpu 是否支持 aes,如果支持,则使用 aes hash,否则使用 memhash。这是在函数 alginit() 中完成,位于路径:src/runtime/alg.go 下。
hash 函数,有加密型和非加密型。 加密型的一般用于加密数据、数字摘要等,典型代表就是 md5、sha1、sha256、aes256 这种; 非加密型的一般就是查找。在 map 的应用场景中,用的是查找。 选择 hash 函数主要考察的是两点:性能、碰撞概率。
之前我们讲过,表示类型的结构体:
type _type struct {size uintptrptrdata uintptr // size of memory prefix holding all pointershash uint32tflag tflagalign uint8fieldalign uint8kind uint8alg *typeAlggcdata *bytestr nameOffptrToThis typeOff}
其中 alg 字段就和哈希相关,它是指向如下结构体的指针:
// src/runtime/alg.go
type typeAlg struct {// (ptr to object, seed) -> hashhash func(unsafe.Pointer, uintptr) uintptr// (ptr to object A, ptr to object B) -> ==?equal func(unsafe.Pointer, unsafe.Pointer) bool}
typeAlg 包含两个函数,hash 函数计算类型的哈希值,而 equal 函数则计算两个类型是否“哈希相等”。
对于 string 类型,它的 hash、equal 函数如下:
func strhash(a unsafe.Pointer, h uintptr) uintptr {x := (*stringStruct)(a)return memhash(x.str, h, uintptr(x.len))}func strequal(p, q unsafe.Pointer) bool {return *(*string)(p) == *(*string)(q)}
根据 key 的类型,_type 结构体的 alg 字段会被设置对应类型的 hash 和 equal 函数。
6.key是如何定位
key 经过哈希计算后得到哈希值,共 64 个 bit 位(64位机,32位机就不讨论了,现在主流都是64位机),计算它到底要落在哪个桶时,只会用到最后 B 个 bit 位。还记得前面提到过的 B 吗?如果 B = 5,那么桶的数量,也就是 buckets 数组的长度是 2^5 = 32。
例如,现在有一个 key 经过哈希函数计算后,得到的哈希结果是:
10010111 | 000011110110110010001111001010100010010110010101010 │ 01010
用最后的 5 个 bit 位(根据B值决定),也就是 01010,值为 10,也就是 10 号桶。这个操作实际上就是取余操作,但是取余开销太大,所以代码实现上用的位操作代替。
再用哈希值的高 8 位,找到此 key 在 bucket 中的位置,这是在寻找已有的 key。最开始桶内还没有 key,新加入的 key 会找到第一个空位,放入。
buckets 编号就是桶编号,当两个不同的 key 落在同一个桶中,也就是发生了哈希冲突。冲突的解决手段是用链表法:在 bucket 中,从前往后找到第一个空位。这样,在查找某个 key 时,先找到对应的桶,再去遍历 bucket 中的 key。
这里参考曹大 github 博客里的一张图,原图是 ascii 图,geek 味十足,可以从参考资料找到曹大的博客,推荐大家去看看。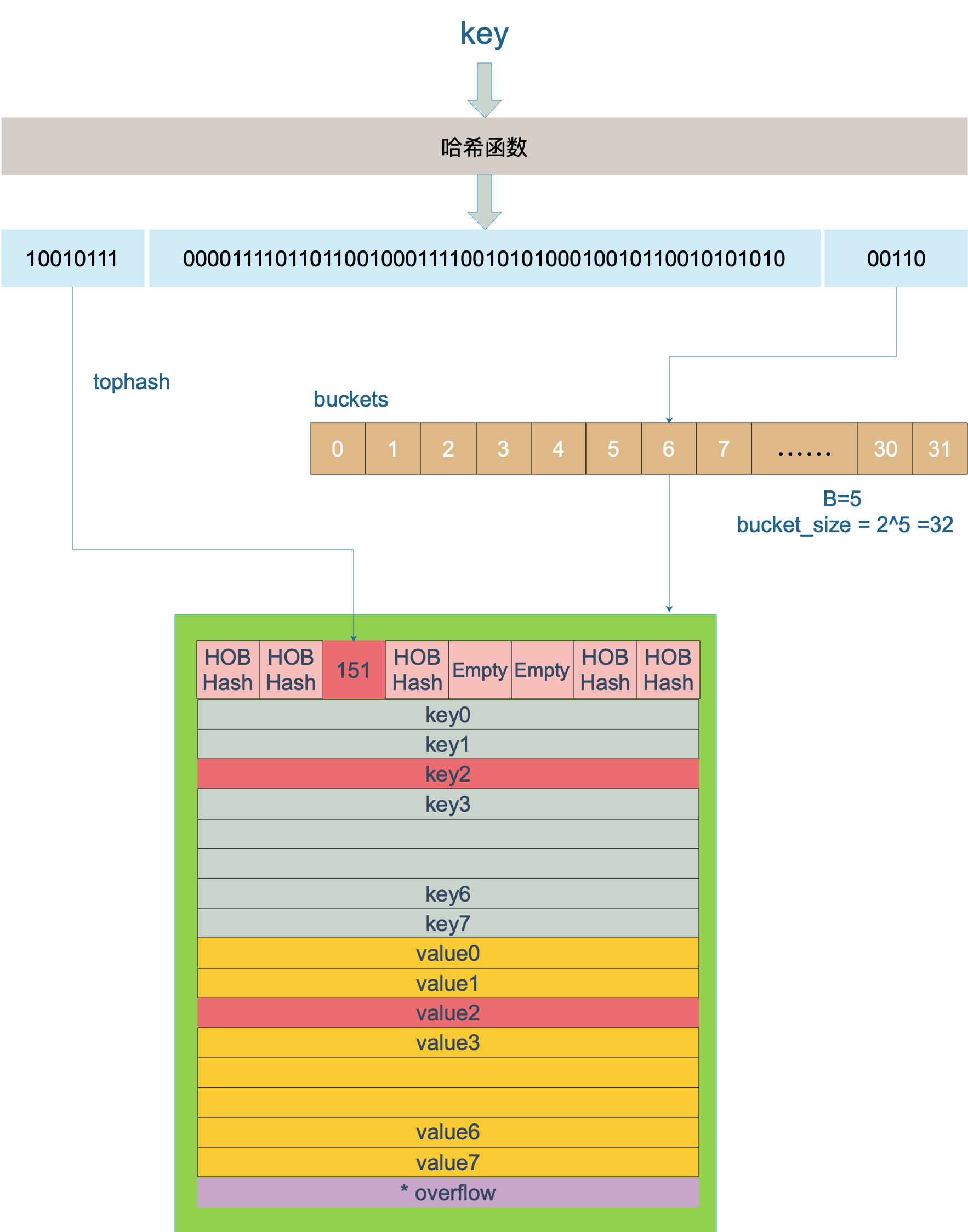
上图中,假定 B = 5,所以 bucket 总数就是 2^5 = 32。首先计算出待查找 key 的哈希,使用低 5 位 00110,找到对应的 6 号 bucket,使用高 8 位 10010111,对应十进制 151,在 6 号 bucket 中寻找 tophash 值(HOB hash)为 151 的 key,找到了 2 号槽位,这样整个查找过程就结束了。
如果在 bucket 中没找到,并且 overflow 不为空,还要继续去 overflow bucket 中寻找,直到找到或是所有的 key 槽位都找遍了,包括所有的 overflow bucket。
我们来看下源码吧,哈哈!通过汇编语言可以看到,查找某个 key 的底层函数是 mapacess 系列函数,函数的作用类似,区别在下一节会讲到。这里我们直接看 mapacess1 函数:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {// ……// 如果 h 什么都没有,返回零值if h == nil || h.count == 0 {return unsafe.Pointer(&zeroVal[0])}// 写和读冲突if h.flags&hashWriting != 0 {throw("concurrent map read and map write")}// 不同类型 key 使用的 hash 算法在编译期确定alg := t.key.alg// 计算哈希值,并且加入 hash0 引入随机性hash := alg.hash(key, uintptr(h.hash0))// 比如 B=5,那 m 就是31,二进制是全 1// 求 bucket num 时,将 hash 与 m 相与,// 达到 bucket num 由 hash 的低 8 位决定的效果m := uintptr(1)<<h.B - 1// b 就是 bucket 的地址b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))// oldbuckets 不为 nil,说明发生了扩容if c := h.oldbuckets; c != nil {// 如果不是同 size 扩容(看后面扩容的内容)// 对应条件 1 的解决方案if !h.sameSizeGrow() {// 新 bucket 数量是老的 2 倍m >>= 1}// 求出 key 在老的 map 中的 bucket 位置oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))// 如果 oldb 没有搬迁到新的 bucket// 那就在老的 bucket 中寻找if !evacuated(oldb) {b = oldb}}// 计算出高 8 位的 hash// 相当于右移 56 位,只取高8位top := uint8(hash >> (sys.PtrSize*8 - 8))// 增加一个 minTopHashif top < minTopHash {top += minTopHash}for {// 遍历 8 个 bucketfor i := uintptr(0); i < bucketCnt; i++ {// tophash 不匹配,继续if b.tophash[i] != top {continue}// tophash 匹配,定位到 key 的位置k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))// key 是指针if t.indirectkey {// 解引用k = *((*unsafe.Pointer)(k))}// 如果 key 相等if alg.equal(key, k) {// 定位到 value 的位置v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))// value 解引用if t.indirectvalue {v = *((*unsafe.Pointer)(v))}return v}}// bucket 找完(还没找到),继续到 overflow bucket 里找b = b.overflow(t)// overflow bucket 也找完了,说明没有目标 key// 返回零值if b == nil {return unsafe.Pointer(&zeroVal[0])}}}
函数返回 h[key] 的指针,如果 h 中没有此 key,那就会返回一个 value相应类型的零值,不会返回 nil。
代码整体比较直接,没什么难懂的地方。跟着上面的注释一步步理解就好了。
这里,说一下定位 key 和 value 的方法以及整个循环的写法。
// key 定位公式k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))// value 定位公式v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
b 是 bmap 的地址,这里 bmap 还是源码里定义的结构体,只包含一个 tophash 数组,经编译器扩充之后的结构体才包含 key,value,overflow 这些字段。dataOffset 是 key 相对于 bmap 起始地址的偏移:
dataOffset = unsafe.Offsetof(struct {b bmapv int64}{}.v)
因此 bucket 里 key 的起始地址就是 unsafe.Pointer(b)+dataOffset。第 i 个 key 的地址就要在此基础上跨过 i 个 key 的大小;而我们又知道,value 的地址是在所有 key 之后,因此第 i 个 value 的地址还需要加上所有 key 的偏移。理解了这些,上面 key 和 value 的定位公式就很好理解了。
再说整个大循环的写法,最外层是一个无限循环,通过
b = b.overflow(t)
遍历所有的 bucket,这相当于是一个 bucket 链表。
当定位到一个具体的 bucket 时,里层循环就是遍历这个 bucket 里所有的 cell,或者说所有的槽位,也就是 bucketCnt=8 个槽位。整个循环过程: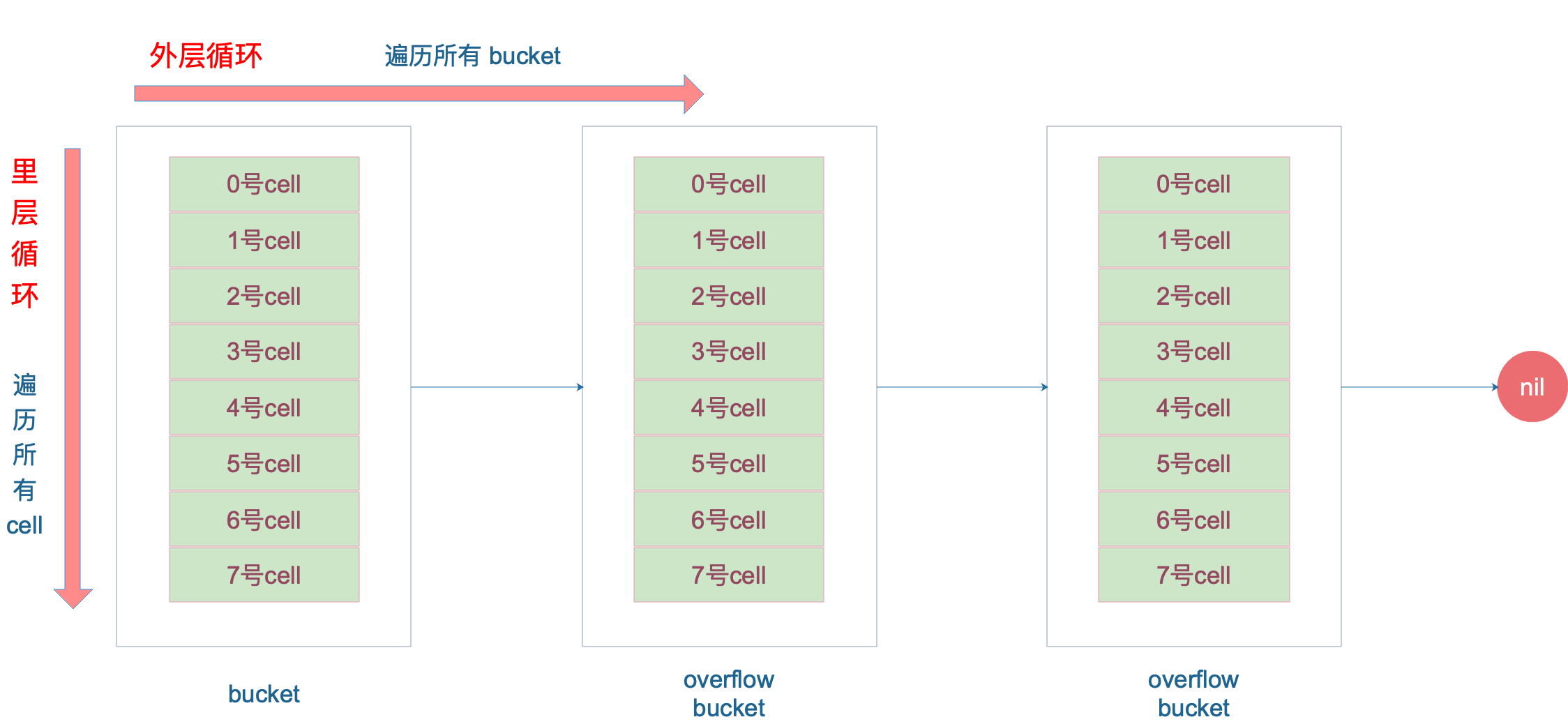
再说一下 minTopHash,当一个 cell 的 tophash 值小于 minTopHash 时,标志这个 cell 的迁移状态。因为这个状态值是放在 tophash 数组里,为了和正常的哈希值区分开,会给 key 计算出来的哈希值一个增量:minTopHash。这样就能区分正常的 top hash 值和表示状态的哈希值。
下面的这几种状态就表征了 bucket 的情况:
// 空的 cell,也是初始时 bucket 的状态empty = 0// 空的 cell,表示 cell 已经被迁移到新的 bucketevacuatedEmpty = 1// key,value 已经搬迁完毕,但是 key 都在新 bucket 前半部分,// 后面扩容部分会再讲到。evacuatedX = 2// 同上,key 在后半部分evacuatedY = 3// tophash 的最小正常值minTopHash = 4
源码里判断这个 bucket 是否已经搬迁完毕,用到的函数:
func evacuated(b *bmap) bool {h := b.tophash[0]return h > empty && h < minTopHash}
只取了 tophash 数组的第一个值,判断它是否在 0-4 之间。对比上面的常量,当 top hash 是 evacuatedEmpty、evacuatedX、evacuatedY 这三个值之一,说明此 bucket 中的 key 全部被搬迁到了新 bucket。
7.key为什么是无序的
map 在扩容后,会发生 key 的搬迁,原来落在同一个 bucket 中的 key,搬迁后,有些 key 就要远走高飞了(bucket 序号加上了 2^B)。而遍历的过程,就是按顺序遍历 bucket,同时按顺序遍历 bucket 中的 key。搬迁后,key 的位置发生了重大的变化,有些 key 飞上高枝,有些 key 则原地不动。这样,遍历 map 的结果就不可能按原来的顺序了。
当然,如果我就一个 hard code 的 map,我也不会向 map 进行插入删除的操作,按理说每次遍历这样的 map 都会返回一个固定顺序的 key/value 序列吧。的确是这样,但是 Go 杜绝了这种做法,因为这样会给新手程序员带来误解,以为这是一定会发生的事情,在某些情况下,可能会酿成大错。
当然,Go 做得更绝,当我们在遍历 map 时,并不是固定地从 0 号 bucket 开始遍历,每次都是从一个随机值序号的 bucket 开始遍历,并且是从这个 bucket 的一个随机序号的 cell 开始遍历。这样,即使你是一个写死的 map,仅仅只是遍历它,也不太可能会返回一个固定序列的 key/value 对了。
8.map是如何扩容的
使用哈希表的目的就是要快速查找到目标 key,然而,随着向 map 中添加的 key 越来越多,key 发生碰撞的概率也越来越大。bucket 中的 8 个 cell 会被逐渐塞满,查找、插入、删除 key 的效率也会越来越低。最理想的情况是一个 bucket 只装一个 key,这样,就能达到 O(1) 的效率,但这样空间消耗太大,用空间换时间的代价太高。
Go 语言采用一个 bucket 里装载 8 个 key,定位到某个 bucket 后,还需要再定位到具体的 key,这实际上又用了时间换空间。
当然,这样做,要有一个度,不然所有的 key 都落在了同一个 bucket 里,直接退化成了链表,各种操作的效率直接降为 O(n),是不行的。
因此,需要有一个指标来衡量前面描述的情况,这就是装载因子。Go 源码里这样定义 装载因子:
loadFactor := count / (2^B)
count 就是 map 的元素个数,2^B 表示 bucket 数量。
再来说触发 map 扩容的时机:在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容:
- 装载因子超过阈值,源码里定义的阈值是 6.5。
- overflow 的 bucket 数量过多:当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B;当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。
通过汇编语言可以找到赋值操作对应源码中的函数是 mapassign,对应扩容条件的源码如下:
@// src/runtime/hashmap.go/mapassign
// 触发扩容时机
if !h.growing() && (overLoadFactor(int64(h.count), h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
}
// 装载因子超过 6.5
func overLoadFactor(count int64, B uint8) bool {
return count >= bucketCnt && float32(count) >= loadFactor*float32((uint64(1)<<B))
}
// overflow buckets 太多
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B < 16 {
return noverflow >= uint16(1)<<B
}
return noverflow >= 1<<15
}
解释一下:
- 第 1 点:我们知道,每个 bucket 有 8 个空位,在没有溢出,且所有的桶都装满了的情况下,装载因子算出来的结果是 8。因此当装载因子超过 6.5 时,表明很多 bucket 都快要装满了,查找效率和插入效率都变低了。在这个时候进行扩容是有必要的。
- 第 2 点:是对第 1 点的补充。就是说在装载因子比较小的情况下,这时候 map 的查找和插入效率也很低,而第 1 点识别不出来这种情况。表面现象就是计算装载因子的分子比较小,即 map 里元素总数少,但是 bucket 数量多(真实分配的 bucket 数量多,包括大量的 overflow bucket)。
不难想像造成这种情况的原因:不停地插入、删除元素。先插入很多元素,导致创建了很多 bucket,但是装载因子达不到第 1 点的临界值,未触发扩容来缓解这种情况。之后,删除元素降低元素总数量,再插入很多元素,导致创建很多的 overflow bucket,但就是不会触犯第 1 点的规定,你能拿我怎么办?overflow bucket 数量太多,导致 key 会很分散,查找插入效率低得吓人,因此出台第 2 点规定。这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难。
对于命中条件 1,2 的限制,都会发生扩容。但是扩容的策略并不相同,毕竟两种条件应对的场景不同。
对于条件 1,元素太多,而 bucket 数量太少,很简单:将 B 加 1,bucket 最大数量(2^B)直接变成原来 bucket 数量的 2 倍。于是,就有新老 bucket 了。注意,这时候元素都在老 bucket 里,还没迁移到新的 bucket 来。而且,新 bucket 只是最大数量变为原来最大数量(2^B)的 2 倍(2^B * 2)。
对于条件 2,其实元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满。解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升。
对于条件 2 的解决方案,曹大的博客里还提出了一个极端的情况:如果插入 map 的 key 哈希都一样,就会落到同一个 bucket 里,超过 8 个就会产生 overflow bucket,结果也会造成 overflow bucket 数过多。移动元素其实解决不了问题,因为这时整个哈希表已经退化成了一个链表,操作效率变成了 O(n)。
再来看一下扩容具体是怎么做的。由于 map 扩容需要将原有的 key/value 重新搬迁到新的内存地址,如果有大量的 key/value 需要搬迁,会非常影响性能。因此 Go map 的扩容采取了一种称为“渐进式”地方式,原有的 key 并不会一次性搬迁完毕,每次最多只会搬迁 2 个 bucket。
上面说的 hashGrow() 函数实际上并没有真正地“搬迁”,它只是分配好了新的 buckets,并将老的 buckets 挂到了 oldbuckets 字段上。真正搬迁 buckets 的动作在 growWork() 函数中,而调用 growWork() 函数的动作是在 mapassign 和 mapdelete 函数中。也就是插入或修改、删除 key 的时候,都会尝试进行搬迁 buckets 的工作。 先检查 oldbuckets 是否搬迁完毕,具体来说就是检查 oldbuckets 是否为 nil。
我们先看 hashGrow() 函数所做的工作,再来看具体的搬迁 buckets 是如何进行的。
func hashGrow(t *maptype, h *hmap) {
// B+1 相当于是原来 2 倍的空间
bigger := uint8(1)
// 对应条件 2
if !overLoadFactor(int64(h.count), h.B) {
// 进行等量的内存扩容,所以 B 不变
bigger = 0
h.flags |= sameSizeGrow
}
// 将老 buckets 挂到 buckets 上
oldbuckets := h.buckets
// 申请新的 buckets 空间
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger)
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// 提交 grow 的动作
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// 搬迁进度为 0
h.nevacuate = 0
// overflow buckets 数为 0
h.noverflow = 0
// ……
}
主要是申请到了新的 buckets 空间,把相关的标志位都进行了处理:例如标志 nevacuate 被置为 0, 表示当前搬迁进度为 0。
值得一说的是对 h.flags 的处理:
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
这里得先说下运算符:&^。这叫按位置 0运算符。例如:
x = 01010011
y = 01010100
z = x &^ y = 00000011
如果 y bit 位为 1,那么结果 z 对应 bit 位就为 0,否则 z 对应 bit 位就和 x 对应 bit 位的值相同。
所以上面那段对 flags 一顿操作的代码的意思是:先把 h.flags 中 iterator 和 oldIterator 对应位清 0,然后如果发现 iterator 位为 1,那就把它转接到 oldIterator 位,使得 oldIterator 标志位变成 1。潜台词就是:buckets 现在挂到了 oldBuckets 名下了,对应的标志位也转接过去吧。
几个标志位如下:
// 可能有迭代器使用 buckets
iterator = 1
// 可能有迭代器使用 oldbuckets
oldIterator = 2
// 有协程正在向 map 中写入 key
hashWriting = 4
// 等量扩容(对应条件 2)
sameSizeGrow = 8
再来看看真正执行搬迁工作的 growWork() 函数。
func growWork(t *maptype, h *hmap, bucket uintptr) {
// 确认搬迁老的 bucket 对应正在使用的 bucket
evacuate(t, h, bucket&h.oldbucketmask())
// 再搬迁一个 bucket,以加快搬迁进程
if h.growing() {
evacuate(t, h, h.nevacuate)
}
}
h.growing() 函数非常简单:
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
如果 oldbuckets 不为空,说明还没有搬迁完毕,还得继续搬。bucket&h.oldbucketmask() 这行代码,如源码注释里说的,是为了确认搬迁的 bucket 是我们正在使用的 bucket。oldbucketmask() 函数返回扩容前的 map 的 bucketmask。
所谓的 bucketmask,作用就是将 key 计算出来的哈希值与 bucketmask 相与,得到的结果就是 key 应该落入的桶。比如 B = 5,那么 bucketmask 的低 5 位是 11111,其余位是 0,hash 值与其相与的意思是,只有 hash 值的低 5 位决策 key 到底落入哪个 bucket。
接下来,我们集中所有的精力在搬迁的关键函数 evacuate。源码贴在下面,不要紧张,我会加上大面积的注释,通过注释绝对是能看懂的。之后,我会再对搬迁过程作详细说明。
源码如下:
func evacuate(t *maptype, h *hmap, oldbucket uintptr) {
// 定位老的 bucket 地址
b := (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 结果是 2^B,如 B = 5,结果为32
newbit := h.noldbuckets()
// key 的哈希函数
alg := t.key.alg
// 如果 b 没有被搬迁过
if !evacuated(b) {
var (
// 表示bucket 移动的目标地址
x, y *bmap
// 指向 x,y 中的 key/val
xi, yi int
// 指向 x,y 中的 key
xk, yk unsafe.Pointer
// 指向 x,y 中的 value
xv, yv unsafe.Pointer
)
// 默认是等 size 扩容,前后 bucket 序号不变
// 使用 x 来进行搬迁
x = (*bmap)(add(h.buckets, oldbucket*uintptr(t.bucketsize)))
xi = 0
xk = add(unsafe.Pointer(x), dataOffset)
xv = add(xk, bucketCnt*uintptr(t.keysize))、
// 如果不是等 size 扩容,前后 bucket 序号有变
// 使用 y 来进行搬迁
if !h.sameSizeGrow() {
// y 代表的 bucket 序号增加了 2^B
y = (*bmap)(add(h.buckets, (oldbucket+newbit)*uintptr(t.bucketsize)))
yi = 0
yk = add(unsafe.Pointer(y), dataOffset)
yv = add(yk, bucketCnt*uintptr(t.keysize))
}
// 遍历所有的 bucket,包括 overflow buckets
// b 是老的 bucket 地址
for ; b != nil; b = b.overflow(t) {
k := add(unsafe.Pointer(b), dataOffset)
v := add(k, bucketCnt*uintptr(t.keysize))
// 遍历 bucket 中的所有 cell
for i := 0; i < bucketCnt; i, k, v = i+1, add(k, uintptr(t.keysize)), add(v, uintptr(t.valuesize)) {
// 当前 cell 的 top hash 值
top := b.tophash[i]
// 如果 cell 为空,即没有 key
if top == empty {
// 那就标志它被"搬迁"过
b.tophash[i] = evacuatedEmpty
// 继续下个 cell
continue
}
// 正常不会出现这种情况
// 未被搬迁的 cell 只可能是 empty 或是
// 正常的 top hash(大于 minTopHash)
if top < minTopHash {
throw("bad map state")
}
k2 := k
// 如果 key 是指针,则解引用
if t.indirectkey {
k2 = *((*unsafe.Pointer)(k2))
}
// 默认使用 X,等量扩容
useX := true
// 如果不是等量扩容
if !h.sameSizeGrow() {
// 计算 hash 值,和 key 第一次写入时一样
hash := alg.hash(k2, uintptr(h.hash0))
// 如果有协程正在遍历 map
if h.flags&iterator != 0 {
// 如果出现 相同的 key 值,算出来的 hash 值不同
if !t.reflexivekey && !alg.equal(k2, k2) {
// 只有在 float 变量的 NaN() 情况下会出现
if top&1 != 0 {
// 第 B 位置 1
hash |= newbit
} else {
// 第 B 位置 0
hash &^= newbit
}
// 取高 8 位作为 top hash 值
top = uint8(hash >> (sys.PtrSize*8 - 8))
if top < minTopHash {
top += minTopHash
}
}
}
// 取决于新哈希值的 oldB+1 位是 0 还是 1
// 详细看后面的文章
useX = hash&newbit == 0
}
// 如果 key 搬到 X 部分
if useX {
// 标志老的 cell 的 top hash 值,表示搬移到 X 部分
b.tophash[i] = evacuatedX
// 如果 xi 等于 8,说明要溢出了
if xi == bucketCnt {
// 新建一个 bucket
newx := h.newoverflow(t, x)
x = newx
// xi 从 0 开始计数
xi = 0
// xk 表示 key 要移动到的位置
xk = add(unsafe.Pointer(x), dataOffset)
// xv 表示 value 要移动到的位置
xv = add(xk, bucketCnt*uintptr(t.keysize))
}
// 设置 top hash 值
x.tophash[xi] = top
// key 是指针
if t.indirectkey {
// 将原 key(是指针)复制到新位置
*(*unsafe.Pointer)(xk) = k2 // copy pointer
} else {
// 将原 key(是值)复制到新位置
typedmemmove(t.key, xk, k) // copy value
}
// value 是指针,操作同 key
if t.indirectvalue {
*(*unsafe.Pointer)(xv) = *(*unsafe.Pointer)(v)
} else {
typedmemmove(t.elem, xv, v)
}
// 定位到下一个 cell
xi++
xk = add(xk, uintptr(t.keysize))
xv = add(xv, uintptr(t.valuesize))
} else { // key 搬到 Y 部分,操作同 X 部分
// ……
// 省略了这部分,操作和 X 部分相同
}
}
}
// 如果没有协程在使用老的 buckets,就把老 buckets 清除掉,帮助gc
if h.flags&oldIterator == 0 {
b = (*bmap)(add(h.oldbuckets, oldbucket*uintptr(t.bucketsize)))
// 只清除bucket 的 key,value 部分,保留 top hash 部分,指示搬迁状态
if t.bucket.kind&kindNoPointers == 0 {
memclrHasPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
} else {
memclrNoHeapPointers(add(unsafe.Pointer(b), dataOffset), uintptr(t.bucketsize)-dataOffset)
}
}
}
// 更新搬迁进度
// 如果此次搬迁的 bucket 等于当前进度
if oldbucket == h.nevacuate {
// 进度加 1
h.nevacuate = oldbucket + 1
// Experiments suggest that 1024 is overkill by at least an order of magnitude.
// Put it in there as a safeguard anyway, to ensure O(1) behavior.
// 尝试往后看 1024 个 bucket
stop := h.nevacuate + 1024
if stop > newbit {
stop = newbit
}
// 寻找没有搬迁的 bucket
for h.nevacuate != stop && bucketEvacuated(t, h, h.nevacuate) {
h.nevacuate++
}
// 现在 h.nevacuate 之前的 bucket 都被搬迁完毕
// 所有的 buckets 搬迁完毕
if h.nevacuate == newbit {
// 清除老的 buckets
h.oldbuckets = nil
// 清除老的 overflow bucket
// 回忆一下:[0] 表示当前 overflow bucket
// [1] 表示 old overflow bucket
if h.extra != nil {
h.extra.overflow[1] = nil
}
// 清除正在扩容的标志位
h.flags &^= sameSizeGrow
}
}
}
evacuate 函数的代码注释非常清晰,对着代码和注释是很容易看懂整个的搬迁过程的,耐心点。
搬迁的目的就是将老的 buckets 搬迁到新的 buckets。而通过前面的说明我们知道,应对条件 1,新的 buckets 数量是之前的一倍,应对条件 2,新的 buckets 数量和之前相等。
对于条件 1,从老的 buckets 搬迁到新的 buckets,由于 bucktes 数量不变,因此可以按序号来搬,比如原来在 0 号 bucktes,到新的地方后,仍然放在 0 号 buckets。
对于条件 2,就没这么简单了。要重新计算 key 的哈希,才能决定它到底落在哪个 bucket。例如,原来 B = 5,计算出 key 的哈希后,只用看它的低 5 位,就能决定它落在哪个 bucket。扩容后,B 变成了 6,因此需要多看一位,它的低 6 位决定 key 落在哪个 bucket。这称为 rehash。
因此,某个 key 在搬迁前后 bucket 序号可能和原来相等,也可能是相比原来加上 2^B(原来的 B 值),取决于 hash 值 第 6 bit 位是 0 还是 1。
再明确一个问题:如果扩容后,B 增加了 1,意味着 buckets 总数是原来的 2 倍,原来 1 号的桶“裂变”到两个桶。
例如,原始 B = 2,1号 bucket 中有 2 个 key 的哈希值低 3 位分别为:010,110。由于原来 B = 2,所以低 2 位 10 决定它们落在 2 号桶,现在 B 变成 3,所以 010、110 分别落入 2、6 号桶。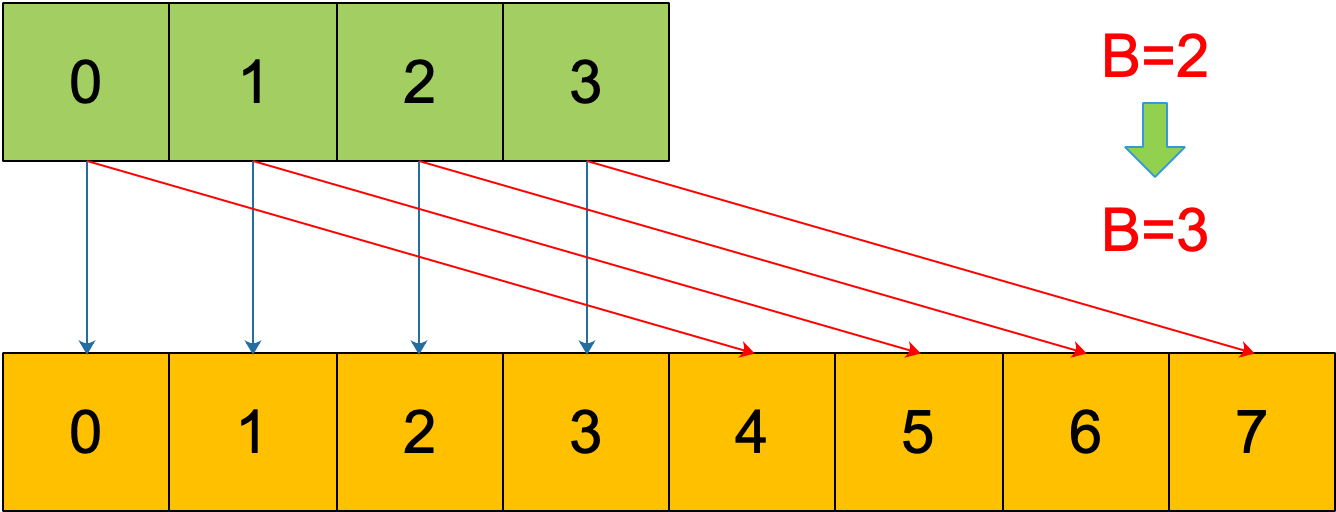
理解了这个,后面讲 map 迭代的时候会用到。
再来讲搬迁函数中的几个关键点:
evacuate 函数每次只完成一个 bucket 的搬迁工作,因此要遍历完此 bucket 的所有的 cell,将有值的 cell copy 到新的地方。bucket 还会链接 overflow bucket,它们同样需要搬迁。因此会有 2 层循环,外层遍历 bucket 和 overflow bucket,内层遍历 bucket 的所有 cell。这样的循环在 map 的源码里到处都是,要理解透了。
源码里提到 X, Y part,其实就是我们说的如果是扩容到原来的 2 倍,桶的数量是原来的 2 倍,前一半桶被称为 X part,后一半桶被称为 Y part。一个 bucket 中的 key 可能会分裂落到 2 个桶,一个位于 X part,一个位于 Y part。所以在搬迁一个 cell 之前,需要知道这个 cell 中的 key 是落到哪个 Part。很简单,重新计算 cell 中 key 的 hash,并向前“多看”一位,决定落入哪个 Part,这个前面也说得很详细了。
有一个特殊情况是:有一种 key,每次对它计算 hash,得到的结果都不一样。这个 key 就是 math.NaN() 的结果,它的含义是 not a number,类型是 float64。当它作为 map 的 key,在搬迁的时候,会遇到一个问题:再次计算它的哈希值和它当初插入 map 时的计算出来的哈希值不一样!
你可能想到了,这样带来的一个后果是,这个 key 是永远不会被 Get 操作获取的!当我使用 m[math.NaN()] 语句的时候,是查不出来结果的。这个 key 只有在遍历整个 map 的时候,才有机会现身。所以,可以向一个 map 插入任意数量的 math.NaN() 作为 key。
当搬迁碰到 math.NaN() 的 key 时,只通过 tophash 的最低位决定分配到 X part 还是 Y part(如果扩容后是原来 buckets 数量的 2 倍)。如果 tophash 的最低位是 0 ,分配到 X part;如果是 1 ,则分配到 Y part。
这是通过 tophash 值与新算出来的哈希值进行运算得到的:
if top&1 != 0 {
// top hash 最低位为 1
// 新算出来的 hash 值的 B 位置 1
hash |= newbit
} else {
// 新算出来的 hash 值的 B 位置 0
hash &^= newbit
}
// hash 值的 B 位为 0,则搬迁到 x part
// 当 B = 5时,newbit = 32,二进制低 6 位为 10 0000
useX = hash&newbit == 0
其实这样的 key 我随便搬迁到哪个 bucket 都行,当然,还是要搬迁到上面裂变那张图中的两个 bucket 中去。但这样做是有好处的,在后面讲 map 迭代的时候会再详细解释,暂时知道是这样分配的就行。
确定了要搬迁到的目标 bucket 后,搬迁操作就比较好进行了。将源 key/value 值 copy 到目的地相应的位置。
设置 key 在原始 buckets 的 tophash 为 evacuatedX 或是 evacuatedY,表示已经搬迁到了新 map 的 x part 或是 y part。新 map 的 tophash 则正常取 key 哈希值的高 8 位。
下面通过图来宏观地看一下扩容前后的变化。
扩容前,B = 2,共有 4 个 buckets,lowbits 表示 hash 值的低位。假设我们不关注其他 buckets 情况,专注在 2 号 bucket。并且假设 overflow 太多,触发了等量扩容(对应于前面的条件 2)。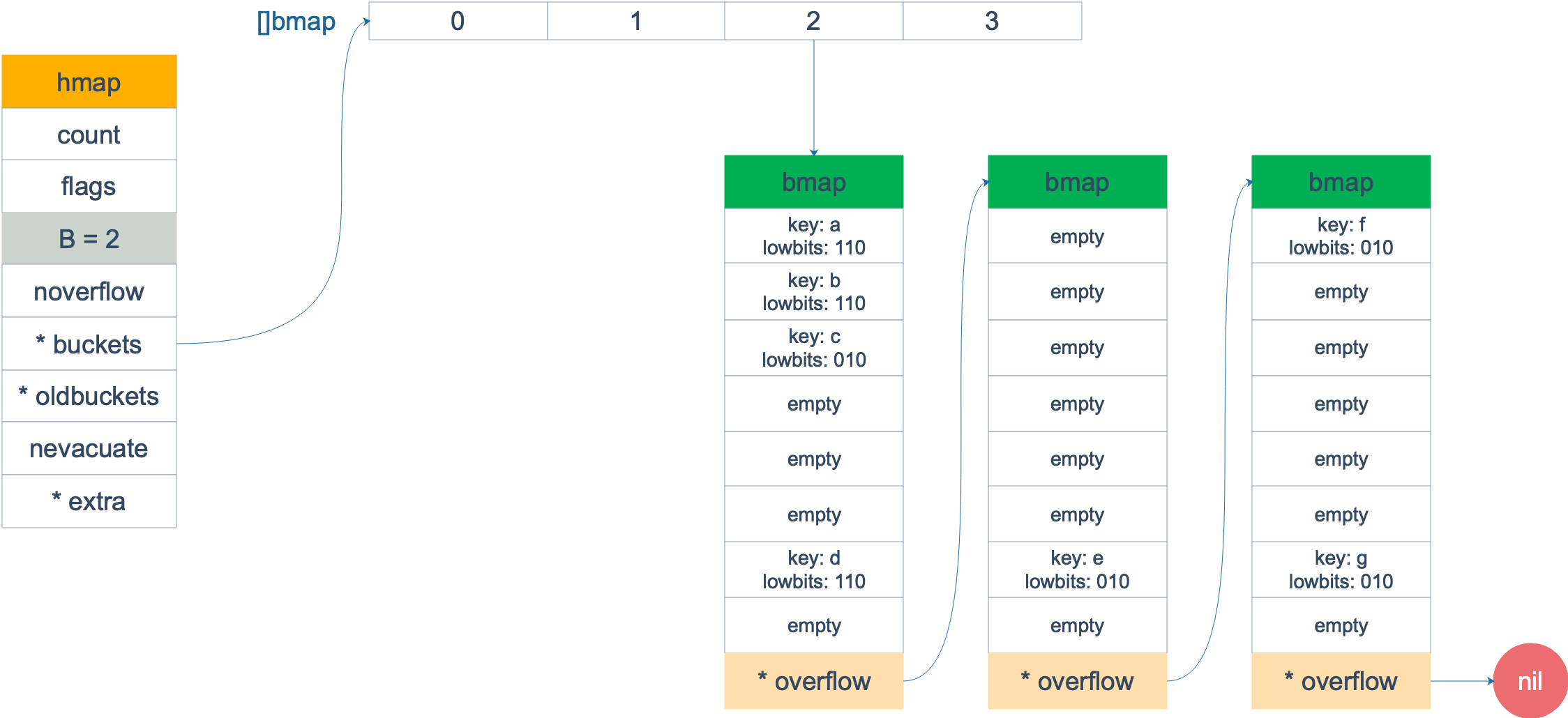
扩容完成后,overflow bucket 消失了,key 都集中到了一个 bucket,更为紧凑了,提高了查找的效率。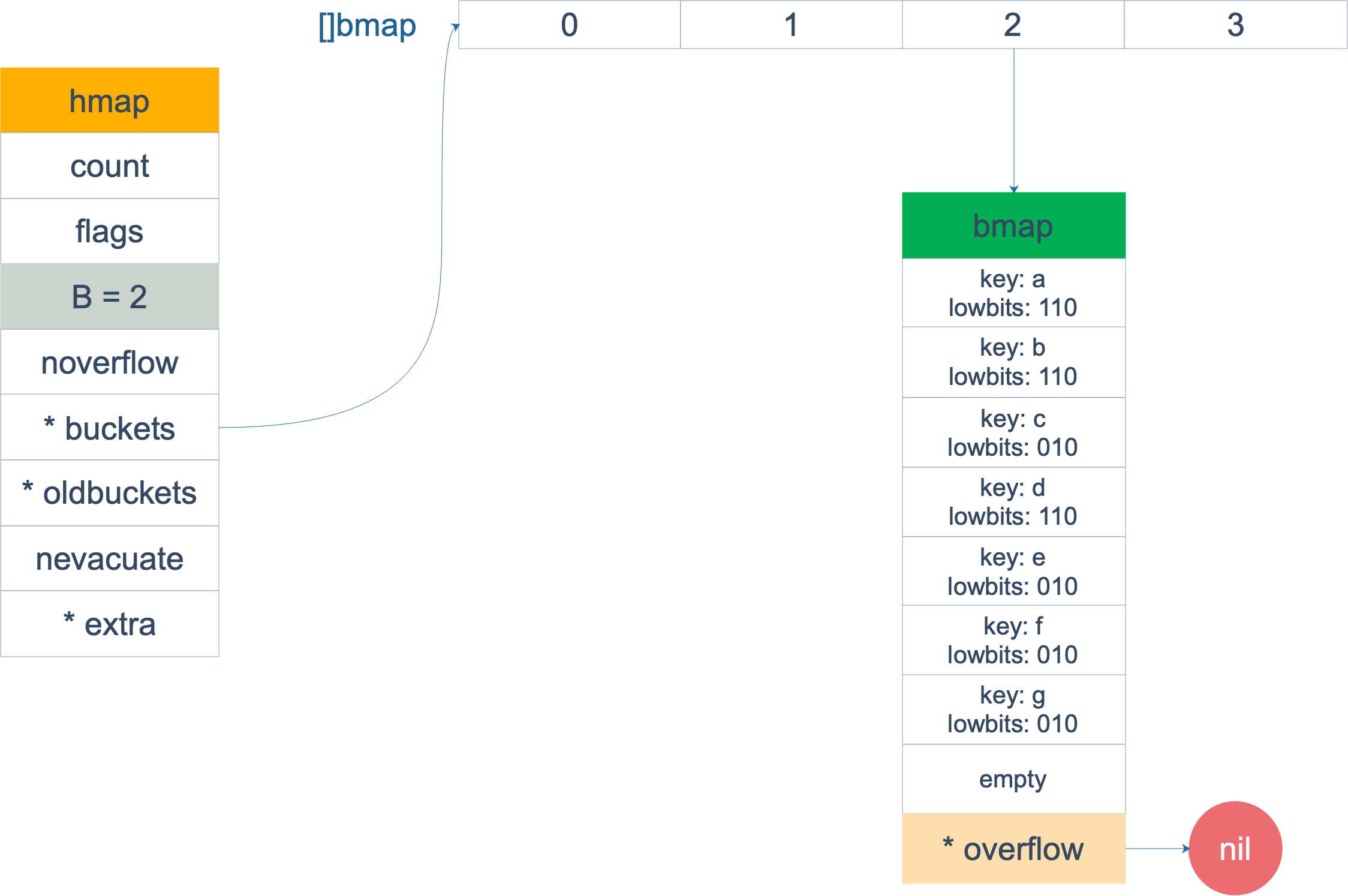
假设触发了 2 倍的扩容,那么扩容完成后,老 buckets 中的 key 分裂到了 2 个 新的 bucket。一个在 x part,一个在 y 的 part。依据是 hash 的 lowbits。新 map 中 0-3 称为 x part,4-7 称为 y part。
注意,上面的两张图忽略了其他 buckets 的搬迁情况,表示所有的 bucket 都搬迁完毕后的情形。实际上,我们知道,搬迁是一个“渐进”的过程,并不会一下子就全部搬迁完毕。所以在搬迁过程中,oldbuckets 指针还会指向原来老的 []bmap,并且已经搬迁完毕的 key 的 tophash 值会是一个状态值,表示 key 的搬迁去向。

若有收获,就点个赞吧
0 人点赞
