什么是 goroutine
Goroutine 可以看作对 thread 加的一层抽象,它更轻量级,可以单独执行。因为有了这层抽象,Gopher 不会直接面对 thread,我们只会看到代码里满天飞的 goroutine。操作系统却相反,管你什么 goroutine,我才没空理会。我安心地执行线程就可以了,线程才是我调度的基本单位。
goroutine 和 thread 的区别
谈到 goroutine,绕不开的一个话题是:它和 thread 有什么区别?
参考资料【How Goroutines Work】告诉我们可以从三个角度区别:内存消耗、创建与销毀、切换。
- 内存占用
创建一个 goroutine 的栈内存消耗为 2 KB,实际运行过程中,如果栈空间不够用,会自动进行扩容。创建一个 thread 则需要消耗 1 MB 栈内存,而且还需要一个被称为 “a guard page” 的区域用于和其他 thread 的栈空间进行隔离。
对于一个用 Go 构建的 HTTP Server 而言,对到来的每个请求,创建一个 goroutine 用来处理是非常轻松的一件事。而如果用一个使用线程作为并发原语的语言构建的服务,例如 Java 来说,每个请求对应一个线程则太浪费资源了,很快就会出 OOM 错误(OutOfMermoryError)。
- 创建和销毀
Thread 创建和销毀都会有巨大的消耗,因为要和操作系统打交道,是内核级的,通常解决的办法就是线程池。而 goroutine 因为是由 Go runtime 负责管理的,创建和销毁的消耗非常小,是用户级。
- 切换
当 threads 切换时,需要保存各种寄存器,以便将来恢复:
16 general purpose registers, PC (Program Counter), SP (Stack Pointer), segment registers, 16 XMM registers, FP coprocessor state, 16 AVX registers, all MSRs etc.
而 goroutines 切换只需保存三个寄存器:Program Counter, Stack Pointer and BP。
一般而言,线程切换会消耗 1000-1500 纳秒,一个纳秒平均可以执行 12-18 条指令。所以由于线程切换,执行指令的条数会减少 12000-18000。
Goroutine 的切换约为 200 ns,相当于 2400-3600 条指令。
因此,goroutines 切换成本比 threads 要小得多。
M:N 模型
我们都知道,Go runtime 会负责 goroutine 的生老病死,从创建到销毁,都一手包办。Runtime 会在程序启动的时候,创建 M 个线程(CPU 执行调度的单位),之后创建的 N 个 goroutine 都会依附在这 M 个线程上执行。这就是 M:N 模型: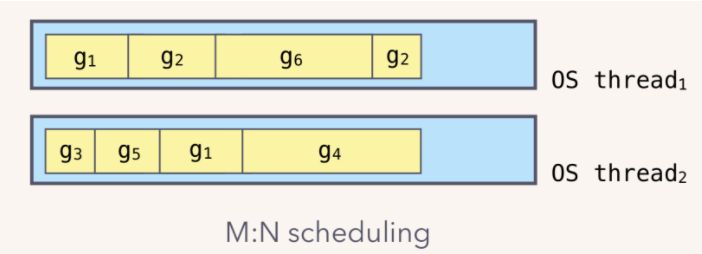
在同一时刻,一个线程上只能跑一个 goroutine。当 goroutine 发生阻塞(例如 channel 发送数据,被阻塞)时,runtime 会把当前 goroutine 调度走,让其他 goroutine 来执行。目的就是不让一个线程闲着,榨干 CPU 的每一滴油水。
什么是 sheduler
Go 程序的执行由两层组成:Go Program,Runtime,即用户程序和运行时。它们之间通过函数调用来实现内存管理、channel 通信、goroutines 创建等功能。用户程序进行的系统调用都会被 Runtime 拦截,以此来帮助它进行调度以及垃圾回收相关的工作。
一个展现了全景式的关系如下图: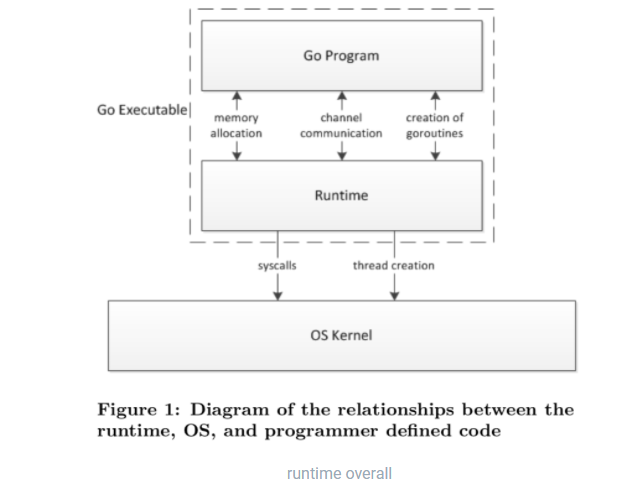
为什么要 scheduler
Go scheduler 可以说是 Go 运行时的一个最重要的部分了。Runtime 维护所有的 goroutines,并通过 scheduler 来进行调度。Goroutines 和 threads 是独立的,但是 goroutines 要依赖 threads 才能执行。
Go 程序执行的高效和 scheduler 的调度是分不开的。
scheduler 底层原理
实际上在操作系统看来,所有的程序都是在执行多线程。将 goroutines 调度到线程上执行,仅仅是 runtime 层面的一个概念,在操作系统之上的层面。
有三个基础的结构体来实现 goroutines 的调度。g,m,p。
g 代表一个 goroutine,它包含:表示 goroutine 栈的一些字段,指示当前 goroutine 的状态,指示当前运行到的指令地址,也就是 PC 值。
m 表示内核线程,包含正在运行的 goroutine 等字段。
p 代表一个虚拟的 Processor,它维护一个处于 Runnable 状态的 g 队列,m 需要获得 p 才能运行 g。
当然还有一个核心的结构体:sched,它总览全局。
Runtime 起始时会启动一些 G:垃圾回收的 G,执行调度的 G,运行用户代码的 G;并且会创建一个 M 用来开始 G 的运行。随着时间的推移,更多的 G 会被创建出来,更多的 M 也会被创建出来。
当然,在 Go 的早期版本,并没有 p 这个结构体,m 必须从一个全局的队列里获取要运行的 g,因此需要获取一个全局的锁,当并发量大的时候,锁就成了瓶颈。后来在大神 Dmitry Vyokov 的实现里,加上了 p 结构体。每个 p 自己维护一个处于 Runnable 状态的 g 的队列,解决了原来的全局锁问题。
Go scheduler 的目标:
Go scheduler 的核心思想是:
- reuse threads;
- 限制同时运行(不包含阻塞)的线程数为 N,N 等于 CPU 的核心数目;
- 线程私有的 runqueues,并且可以从其他线程 stealing goroutine 来运行,线程阻塞后,可以将 runqueues 传递给其他线程。
为什么需要 P 这个组件,直接把 runqueues 放到 M 不行吗?
当一个线程阻塞的时候,将和它绑定的 P 上的 goroutines 转移到其他线程。
Go scheduler 会启动一个后台线程 sysmon,用来检测长时间(超过 10 ms)运行的 goroutine,将其调度到 global runqueues。这是一个全局的 runqueue,优先级比较低,以示惩罚。
scheduler 历史
参考:https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine/#65-%E8%B0%83%E5%BA%A6%E5%99%A8
单线程调度器
0.x 版本调度器只包含表示 Goroutine 的 G 和表示线程的 M 两种结构,全局也只有一个线程。
多线程调度器
Go 语言在 1.0 版本正式发布时就支持了多线程的调度器,与上一个版本几乎不可用的调度器相比,Go 语言团队在这一阶段实现了从不可用到可用的跨越。我们可以在 [pkg/runtime/proc.c](https://github.com/golang/go/blob/go1.0.1/src/pkg/runtime/proc.c) 文件中找到 1.0.1 版本的调度器,多线程版本的调度函数 [runtime.schedule](https://draveness.me/golang/tree/runtime.schedule) 包含 70 多行代码,我们在这里保留了该函数的核心逻辑:
static void schedule(G *gp) {schedlock();if(gp != nil) {gp->m = nil;uint32 v = runtime·xadd(&runtime·sched.atomic, -1<<mcpuShift);if(atomic_mcpu(v) > maxgomaxprocs)runtime·throw("negative mcpu in scheduler");switch(gp->status){case Grunning:gp->status = Grunnable;gput(gp);break;case ...:}} else {...}gp = nextgandunlock();gp->status = Grunning;m->curg = gp;gp->m = m;runtime·gogo(&gp->sched, 0);}
整体的逻辑与单线程调度器没有太多区别,因为我们的程序中可能同时存在多个活跃线程,所以多线程调度器引入了 GOMAXPROCS 变量帮助我们灵活控制程序中的最大处理器数,即活跃线程数。
多线程调度器的主要问题是调度时的锁竞争会严重浪费资源,Scalable Go Scheduler Design Doc 中对调度器做的性能测试发现 14% 的时间都花费在 [runtime.futex](https://github.com/golang/go/blob/2fffba7fe19690e038314d17a117d6b87979c89f/src/pkg/runtime/os_linux.h#L9) 上3,该调度器有以下问题需要解决:
- 调度器和锁是全局资源,所有的调度状态都是中心化存储的,锁竞争问严重;
- 线程需要经常互相传递可运行的 Goroutine,引入了大量的延迟;
- 每个线程都需要处理内存缓存,导致大量的内存占用并影响数据局部性(Data locality);
- 系统调用频繁阻塞和解除阻塞正在运行的线程,增加了额外开销;
任务窃取调度器
2012 年 Google 的工程师 Dmitry Vyukov 在 Scalable Go Scheduler Design Doc 中指出了现有多线程调度器的问题并在多线程调度器上提出了两个改进的手段:
- 在当前的 G-M 模型中引入了处理器 P,增加中间层;
- 在处理器 P 的基础上实现基于工作窃取的调度器;
基于任务窃取的 Go 语言调度器使用了沿用至今的 G-M-P 模型,我们能在 runtime: improved scheduler 提交中找到任务窃取调度器刚被实现时的源代码,调度器的 [runtime.schedule](https://draveness.me/golang/tree/runtime.schedule) 函数在这个版本的调度器中反而更简单了:
static void schedule(void) {G *gp;top:if(runtime·gcwaiting) {gcstopm();goto top;}gp = runqget(m->p);if(gp == nil)gp = findrunnable();...execute(gp);}
- 如果当前运行时在等待垃圾回收,调用
[runtime.gcstopm](https://github.com/golang/go/blob/779c45a50700bda0f6ec98429720802e6c1624e8/src/pkg/runtime/proc.c#L907)函数; - 调用
[runtime.runqget](https://github.com/golang/go/blob/779c45a50700bda0f6ec98429720802e6c1624e8/src/pkg/runtime/proc.c#L2075)和[runtime.findrunnable](https://draveness.me/golang/tree/runtime.findrunnable)从本地或者全局的运行队列中获取待执行的 Goroutine; - 调用
[runtime.execute](https://draveness.me/golang/tree/runtime.execute)函数在当前线程 M 上运行 Goroutine;
当前处理器本地的运行队列中不包含 Goroutine 时,调用 [findrunnable](https://github.com/golang/go/blob/779c45a50700bda0f6ec98429720802e6c1624e8/src/pkg/runtime/proc.c#L956) 函数会触发工作窃取,从其它的处理器的队列中随机获取一些 Goroutine。
运行时 G-M-P 模型中引入的处理器 P 是线程和 Goroutine 的中间层,我们从它的结构体中就能看到处理器与 M 和 G 的关系:
struct P {Lock;uint32 status;P* link;uint32 tick;M* m;MCache* mcache;G** runq;int32 runqhead;int32 runqtail;int32 runqsize;G* gfree;int32 gfreecnt;};
抢占式调度器
对 Go 语言并发模型的修改提升了调度器的性能,但是 1.1 版本中的调度器仍然不支持抢占式调度,程序只能依靠 Goroutine 主动让出 CPU 资源才能触发调度。Go 语言的调度器在 1.2 版本4中引入基于协作的抢占式调度解决下面的问题5:
- 某些 Goroutine 可以长时间占用线程,造成其它 Goroutine 的饥饿;
- 垃圾回收需要暂停整个程序(Stop-the-world,STW),最长可能需要几分钟的时间6,导致整个程序无法工作;
1.2 版本的抢占式调度虽然能够缓解这个问题,但是它实现的抢占式调度是基于协作的,在之后很长的一段时间里 Go 语言的调度器都有一些无法被抢占的边缘情况,例如:for 循环或者垃圾回收长时间占用线程,这些问题中的一部分直到 1.14 才被基于信号的抢占式调度解决。
基于协作的抢占式调度
我们可以在 [pkg/runtime/proc.c](https://github.com/golang/go/blob/go1.2/src/pkg/runtime/proc.c) 文件中找到引入基于协作的抢占式调度后的调度器。Go 语言会在分段栈的机制上实现抢占调度,利用编译器在分段栈上插入的函数,所有 Goroutine 在函数调用时都有机会进入运行时检查是否需要执行抢占。Go 团队通过以下的多个提交实现该特性:
- runtime: add stackguard0 to G
- 为 Goroutine 引入
stackguard0字段,该字段被设置成 stackPreempt 意味着当前 Goroutine 发出了抢占请求;
- 为 Goroutine 引入
- runtime: introduce preemption function (not used for now)
- 引入抢占函数
[runtime.preemptone](https://draveness.me/golang/tree/runtime.preemptone)和[runtime.preemptall](https://draveness.me/golang/tree/runtime.preemptall),这两个函数会改变 Goroutine 的stackguard0字段发出抢占请求; - 定义抢占请求 stackPreempt;
- 引入抢占函数
- runtime: preempt goroutines for GC
- 在
[runtime.stoptheworld](https://github.com/golang/go/blob/1e112cd59f560129f4dca5e9af7c3cbc445850b6/src/pkg/runtime/proc.c#L356)中调用[runtime.preemptall](https://draveness.me/golang/tree/runtime.preemptall)设置所有处理器上正在运行的 Goroutine 的stackguard0为 stackPreempt ; - 在
[runtime.newstack](https://draveness.me/golang/tree/runtime.newstack)函数中增加抢占的代码,当stackguard0等于 stackPreempt 时触发调度器抢占让出线程;
- 在
- runtime: preempt long-running goroutines
- 在系统监控中,如果一个 Goroutine 的运行时间超过 10ms,就会调用
[runtime.retake](https://draveness.me/golang/tree/runtime.retake)和[runtime.preemptone](https://draveness.me/golang/tree/runtime.preemptone);
- 在系统监控中,如果一个 Goroutine 的运行时间超过 10ms,就会调用
- runtime: more reliable preemption
- 修复 Goroutine 因为周期性执行非阻塞的 CGO 或者系统调用不会被抢占的问题;
上面的多个提交实现了抢占式调度,但是还缺少最关键的一个环节 — 编译器如何在函数调用前插入函数,我们能在非常古老的提交 runtime: stack growth adjustments, cleanup 中找到编译器插入函数的出行,最新版本的 Go 语言会通过 [cmd/internal/obj/x86.stacksplit](https://draveness.me/golang/tree/cmd/internal/obj/x86.stacksplit) 插入 [runtime.morestack](https://draveness.me/golang/tree/runtime.morestack) 函数,该函数可能会调用 [runtime.newstack](https://draveness.me/golang/tree/runtime.newstack) 触发抢占。从上面的多个提交中,我们能归纳出基于协作的抢占式调度的工作原理:
- 编译器会在调用函数前插入
[runtime.morestack](https://draveness.me/golang/tree/runtime.morestack); - Go 语言运行时会在垃圾回收暂停程序、系统监控发现 Goroutine 运行超过 10ms 时发出抢占请求
StackPreempt; - 当发生函数调用时,可能会执行编译器插入的
[runtime.morestack](https://draveness.me/golang/tree/runtime.morestack)函数,它调用的[runtime.newstack](https://draveness.me/golang/tree/runtime.newstack)会检查 Goroutine 的stackguard0字段是否为StackPreempt; - 如果
stackguard0是StackPreempt,就会触发抢占让出当前线程;
这种实现方式虽然增加了运行时的复杂度,但是实现相对简单,也没有带来过多的额外开销,总体来看还是比较成功的实现,也在 Go 语言中使用了 10 几个版本。因为这里的抢占是通过编译器插入函数实现的,还是需要函数调用作为入口才能触发抢占,所以这是一种协作式的抢占式调度。
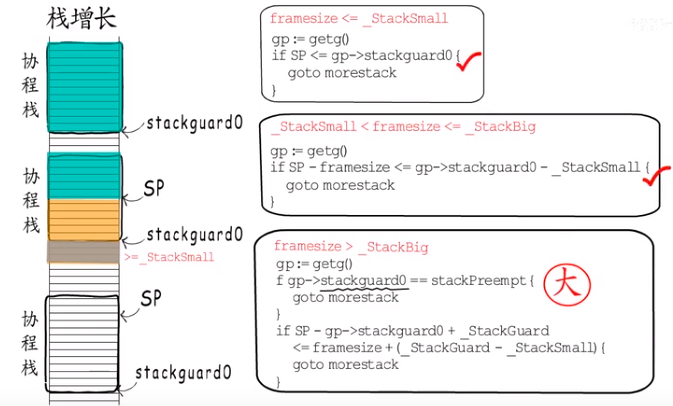
当需要抢占时将stackguard0 设置stackPreempt,当判断stackguard0==stackPreempt就会触发一次调度
基于信号的抢占式调度
转自:https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-goroutine/#%E6%8A%A2%E5%8D%A0%E5%BC%8F%E8%B0%83%E5%BA%A6%E5%99%A8
golang在之前的版本中已经实现了抢占调度,不管是陷入到大量计算还是系统调用,大多可被sysmon扫描到并进行抢占。但有些场景是无法抢占成功的。比如轮询计算 for { i++ } 等,这类操作没有函数调用,没有栈增长,无法进行morestack -> newstack,所以无法检测stackguard0 = stackpreempt。
go team已经意识到抢占是个问题,所以在1.14中加入了基于信号的协程调度抢占。原理是这样的,首先注册绑定 SIGURG 信号及处理方法runtime.doSigPreempt,sysmon会间隔性检测超时的p,然后发送信号,m收到信号后休眠执行的goroutine并且进行重新调度。
Go 语言在 1.14 版本中实现了非协作的抢占式调度,在实现的过程中我们重构已有的逻辑并为 Goroutine 增加新的状态和字段来支持抢占。Go 团队通过下面的一系列提交实现了这一功能,我们可以按时间顺序分析相关提交理解它的工作原理:
- runtime: add general suspendG/resumeG
- 挂起 Goroutine 的过程是在垃圾回收的栈扫描时完成的,我们通过runtime.suspendG和runtime.resumeG两个函数重构栈扫描这一过程;
- 调用runtime.suspendG时会将处于运行状态的 Goroutine 的preemptStop标记成true;
- 调用runtime.preemptPark可以挂起当前 Goroutine、将其状态更新成_Gpreempted并触发调度器的重新调度,该函数能够交出线程控制权;
- runtime: asynchronous preemption function for x86
- 在 x86 架构上增加异步抢占的函数runtime.asyncPreempt和runtime.asyncPreempt2;
- runtime: use signals to preempt Gs for suspendG
- 支持通过向线程发送信号的方式暂停运行的 Goroutine;
- 在runtime.sighandler函数中注册SIGURG信号的处理函数runtime.doSigPreempt;
- 实现runtime.preemptM,它可以通过SIGURG信号向线程发送抢占请求;
- runtime: implement async scheduler preemption
- 修改runtime.preemptone函数的实现,加入异步抢占的逻辑;
我们可以梳理一下上述代码实现的抢占式调度过程:
- 程序启动时,在runtime.sighandler中注册SIGURG信号的处理函数runtime.doSigPreempt;
- 在触发垃圾回收的栈扫描时会调用runtime.suspendG挂起 Goroutine,该函数会执行下面的逻辑:
- 将_Grunning状态的 Goroutine 标记成可以被抢占,即将preemptStop设置成true;
- 调用runtime.preemptM触发抢占;
- 系统监控sysmon检测运行超过10ms,调用runtime.preemptM触发抢占;(德莱文大佬说抢占式调度也只会在垃圾回收扫描任务时触发,可能与他文章看的go版本有关,我的版本go1.16)
- runtime.preemptM会调用runtime.signalM向线程发送信号SIGURG;
- 操作系统会中断正在运行的线程并执行预先注册的信号处理函数runtime.doSigPreempt;
- runtime.doSigPreempt函数会处理抢占信号,获取当前的 SP 和 PC 寄存器并调用runtime.sigctxt.pushCall;
- runtime.sigctxt.pushCall会修改寄存器并在程序回到用户态时执行runtime.asyncPreempt;
- 汇编指令runtime.asyncPreempt会调用运行时函数runtime.asyncPreempt2;
- runtime.asyncPreempt2会调用runtime.preemptPark;
- runtime.preemptPark会修改当前 Goroutine 的状态到_Gpreempted并调用runtime.schedule让当前函数陷入休眠并让出线程,调度器会选择其它的 Goroutine 继续执行;
基于信号的抢占式调度实现原理
转自:http://xiaorui.cc/archives/6535
对比测试:
// xiaorui.ccpackage mainimport ("runtime")func main() {runtime.GOMAXPROCS(1)go func() {panic("already call")}()for {}}
上面的测试思路是先针对GOMAXPROCS的p配置为1,这样就可以规避并发而影响抢占的测试,然后go关键字会把当前传递的函数封装协程结构,扔到runq队列里等待runtime调度,由于是异步执行,所以就执行到for死循环无法退出。go1.14是可以执行到panic,而1.13版本一直挂在死循环上。
源码分析:
怎么注册的sigurg信号?
go在启动时把所有的信号都注册了一遍,包括可靠的信号。
// xiaorui.ccconst sigPreempt = _SIGURGfunc initsig(preinit bool) {for i := uint32(0); i < _NSIG; i++ {fwdSig[i] = getsig(i),,,setsig(i, funcPC(sighandler)) // 注册信号对应的回调方法}}func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {,,,if sig == sigPreempt { // 如果是抢占信号// Might be a preemption signal.doSigPreempt(gp, c)},,,}// 执行抢占func doSigPreempt(gp *g, ctxt *sigctxt) {if wantAsyncPreempt(gp) && isAsyncSafePoint(gp, ctxt.sigpc(), ctxt.sigsp(), ctxt.siglr()) {// Inject a call to asyncPreempt.ctxt.pushCall(funcPC(asyncPreempt)) // 执行抢占的关键方法}// Acknowledge the preemption.atomic.Xadd(&gp.m.preemptGen, 1)}
由谁去发起检测抢占?
go1.14之前的版本是是由sysmon检测抢占,到了go1.14当然也是由sysmon操作。runtime在启动时会创建一个线程来执行sysmon,为什么要独立执行? sysmon是golang的runtime系统检测器,sysmon可进行forcegc、netpoll、retake等操作。拿抢占功能来说,如sysmon放到pmg调度模型里,每个p上面的goroutine恰好阻塞了,那么还怎么执行抢占?
runtime/proc.go
// xiaorui.cc
func main() {
g := getg()
,,,
if GOARCH != "wasm" {
systemstack(func() {
newm(sysmon, nil)
})
}
,,,
}
func schedule() {
,,,
execute(gp, inheritTime)
}
func execute(gp *g, inheritTime bool) {
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
,,,
}
func sysmon(){
,,,
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
,,,
}
// 记录每次检查的信息
type sysmontick struct {
schedtick uint32
schedwhen int64
syscalltick uint32
syscallwhen int64
}
const forcePreemptNS = 10 * 1000 * 1000 // 抢占的时间阈值 10ms
func retake(now int64) uint32 {
n := 0
lock(&allpLock)
for i := 0; i < len(allp); i++ {
_p_ := allp[i]
if _p_ == nil {
continue
}
pd := &_p_.sysmontick
s := _p_.status
if s == _Prunning || s == _Psyscall {
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now // 记录当前检测时间
// 上次时间加10ms小于当前时间,那么说明超过,需进行抢占。
} else if pd.schedwhen+forcePreemptNS <= now {
preemptone(_p_)
}
}
// 下面省略掉慢系统调用的抢占描述。
if s == _Psyscall {
// 原子更为p状态为空闲状态
if atomic.Cas(&_p_.status, s, _Pidle) {
,,,
handoffp(_p_) // 强制卸载P
}
,,,
}
func preemptone(_p_ *p) bool {
mp := _p_.m.ptr()
,,,
gp.preempt = true
,,,
gp.stackguard0 = stackPreempt
// Request an async preemption of this P.
if preemptMSupported && debug.asyncpreemptoff == 0 {
_p_.preempt = true
preemptM(mp) // 这里会给M发送信号
}
return true
}
_Psyscall与_Prunning抢占的区别
_Prunning抢占是让m重新执行一次调度
_Psyscall抢占是让m放弃p
发送SIGURG信号?
signal_unix.go
// xiaorui.cc
// 给m发送sigurg信号
func preemptM(mp *m) {
if !pushCallSupported {
// This architecture doesn't support ctxt.pushCall
// yet, so doSigPreempt won't work.
return
}
if GOOS == "darwin" && (GOARCH == "arm" || GOARCH == "arm64") && !iscgo {
return
}
signalM(mp, sigPreempt)
}
收到sigurg信号后如何处理 ?
preemptPark方法会解绑mg的关系,封存当前协程,继而重新调度runtime.schedule()获取可执行的协程,至于被抢占的协程后面会去重启。
goschedImpl操作就简单的多,把当前协程的状态从_Grunning正在执行改成 _Grunnable可执行,使用globrunqput方法把抢占的协程放到全局队列里,根据pmg的协程调度设计,globalrunq要后于本地runq被调度。
runtime/preempt.go
//go:generate go run mkpreempt.go
// asyncPreempt saves all user registers and calls asyncPreempt2.
//
// When stack scanning encounters an asyncPreempt frame, it scans that
// frame and its parent frame conservatively.
func asyncPreempt()
//go:nosplit
func asyncPreempt2() {
gp := getg()
gp.asyncSafePoint = true
if gp.preemptStop {
mcall(preemptPark)
} else {
mcall(gopreempt_m)
}
gp.asyncSafePoint = false
}
runtime/proc.go
// xiaorui.cc
// preemptPark parks gp and puts it in _Gpreempted.
//
//go:systemstack
func preemptPark(gp *g) {
,,,
status := readgstatus(gp)
if status&^_Gscan != _Grunning {
dumpgstatus(gp)
throw("bad g status")
}
,,,
schedule()
}
func goschedImpl(gp *g) {
status := readgstatus(gp)
,,,
casgstatus(gp, _Grunning, _Grunnable)
dropg()
lock(&sched.lock)
globrunqput(gp)
unlock(&sched.lock)
schedule()
}
抢占是否影响性能 ?
抢占分为_Prunning和Psyscall,Psyscall抢占通常是由于阻塞性系统调用引起的,比如磁盘io、cgo。Prunning抢占通常是由于一些类似死循环的计算逻辑引起的。
过度的发送信号来中断m进行抢占多少会影响性能的,主要是软中断和上下文切换。在平常的业务逻辑下,很难发生协程阻塞调度的问题。
信号的原理?
我们对一个进程发送信号后,内核把信号挂载到目标进程的信号 pending 队列上去,然后进行触发软中断设置目标进程为running状态。当进程被唤醒或者调度后获取CPU后,才会从内核态转到用户态时检测是否有signal等待处理,等进程处理完后会把相应的信号从链表中去掉。
通过kill -l拿到当前系统支持的信号列表,1-31为不可靠信号,也是非实时信号,信号有可能会丢失,比如发送多次相同的信号,进程只能收到一次。
// xiaorui.cc
// Print a list of signal names. These are found in /usr/include/linux/signal.h
kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS
在Linux中的posix线程模型中,线程拥有独立的进程号,可以通过getpid()得到线程的进程号,而线程号保存在pthread_t的值中。而主线程的进程号就是整个进程的进程号,因此向主进程发送信号只会将信号发送到主线程中去。如果主线程设置了信号屏蔽,则信号会投递到一个可以处理的线程中去。
注册的信号处理函数都是线程共享的,一个信号只对应一个处理函数,且最后一次为准。子线程也可更改信号处理函数,且随时都可改。
多线程下发送及接收信号的问题?
默认情况下只有主线程才可处理signal,就算指定子线程发送signal,也是主线程接收处理信号。
那么Golang如何做到给指定子线程发signal且处理的?如何指定给某个线程发送signal? 在glibc下可以使用pthread_kill来给线程发signal,它底层调用的是SYS_tgkill系统调用。
// xiaorui.cc
#include "pthread_impl.h"
int pthread_kill(pthread_t t, int sig)
{
int r;
__lock(t->killlock);
r = t->dead ? ESRCH : -__syscall(SYS_tgkill, t->pid, t->tid, sig);
__unlock(t->killlock);
return r;
}
在go runtime/sys_linux_amd64.s里找到了SYS_tgkill的汇编实现。os_linux.go中signalM调用的就是tgkill的实现。
// xiaorui.cc
func tgkill(tgid, tid, sig int)
// signalM sends a signal to mp.
func signalM(mp *m, sig int) {
tgkill(getpid(), int(mp.procid), sig)
}

若有收获,就点个赞吧
0 人点赞

{kind=link}