全局变量
Go scheduler 在源码中的结构体为 schedt,保存调度器的状态信息、全局的可运行 G 队列等。源码如下:
// 保存调度器的信息type schedt struct {// accessed atomically. keep at top to ensure alignment on 32-bit systems.// 需以原子访问访问。// 保持在 struct 顶部,以使其在 32 位系统上可以对齐goidgen uint64lastpoll uint64lock mutex// 由空闲的工作线程组成的链表midle muintptr // idle m's waiting for work// 空闲的工作线程数量nmidle int32 // number of idle m's waiting for work// 空闲的且被 lock 的 m 计数nmidlelocked int32 // number of locked m's waiting for work// 已经创建的工作线程数量mcount int32 // number of m's that have been created// 表示最多所能创建的工作线程数量maxmcount int32 // maximum number of m's allowed (or die)// goroutine 的数量,自动更新ngsys uint32 // number of system goroutines; updated atomically// 由空闲的 p 结构体对象组成的链表pidle puintptr // idle p's// 空闲的 p 结构体对象的数量npidle uint32nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.// Global runnable queue.// 全局可运行的 G队列runqhead guintptr // 队列头runqtail guintptr // 队列尾runqsize int32 // 元素数量// Global cache of dead G's.// dead G 的全局缓存// 已退出的 goroutine 对象,缓存下来// 避免每次创建 goroutine 时都重新分配内存gflock mutexgfreeStack *ggfreeNoStack *g// 空闲 g 的数量ngfree int32// Central cache of sudog structs.// sudog 结构的集中缓存sudoglock mutexsudogcache *sudog// Central pool of available defer structs of different sizes.// 不同大小的可用的 defer struct 的集中缓存池deferlock mutexdeferpool [5]*_defergcwaiting uint32 // gc is waiting to runstopwait int32stopnote notesysmonwait uint32sysmonnote note// safepointFn should be called on each P at the next GC// safepoint if p.runSafePointFn is set.safePointFn func(*p)safePointWait int32safePointNote noteprofilehz int32 // cpu profiling rate// 上次修改 gomaxprocs 的纳秒时间procresizetime int64 // nanotime() of last change to gomaxprocstotaltime int64 // ∫gomaxprocs dt up to procresizetime}
在程序运行过程中,schedt 对象只有一份实体,它维护了调度器的所有信息。
在 proc.go 和 runtime2.go 文件中,有一些很重要全局的变量,我们先列出来:
// 所有 g 的长度allglen uintptr// 保存所有的 gallgs []*g// 保存所有的 mallm *m// 保存所有的 p,_MaxGomaxprocs = 1024allp [_MaxGomaxprocs + 1]*p// p 的最大值,默认等于 ncpugomaxprocs int32// 程序启动时,会调用 osinit 函数获得此值ncpu int32// 调度器结构体对象,记录了调度器的工作状态sched schedt// 代表进程的主线程m0 m// m0 的 g0,即 m0.g0 = &g0g0 g
在程序初始化时,这些全局变量都会被初始化为零值:指针被初始化为 nil 指针,切片被初始化为 nil 切片,int 被初始化为 0,结构体的所有成员变量按其类型被初始化为对应的零值。因此程序刚启动时 allgs,allm 和allp 都不包含任何 g,m 和 p。
不仅是 Go 程序,系统加载可执行文件大概都会经过这几个阶段:
- 从磁盘上读取可执行文件,加载到内存
- 创建进程和主线程
- 为主线程分配栈空间
- 把由用户在命令行输入的参数拷贝到主线程的栈
- 把主线程放入操作系统的运行队列等待被调度
我们从一个 Hello World 的例子来回顾一下 Go 程序初始化的过程:
package mainimport "fmt"func main() {fmt.Println("hello world")}
在项目根目录下执行:go build -gcflags “-N -l” -o hello src/main.go-gcflags "-N -l" 是为了关闭编译器优化和函数内联,防止后面在设置断点的时候找不到相对应的代码位置。
得到了可执行文件 hello,执行:
[qcrao@qcrao hello-world]$ gdb hello
进入 gdb 调试模式,执行 info files,得到可执行文件的文件头,列出了各种段:、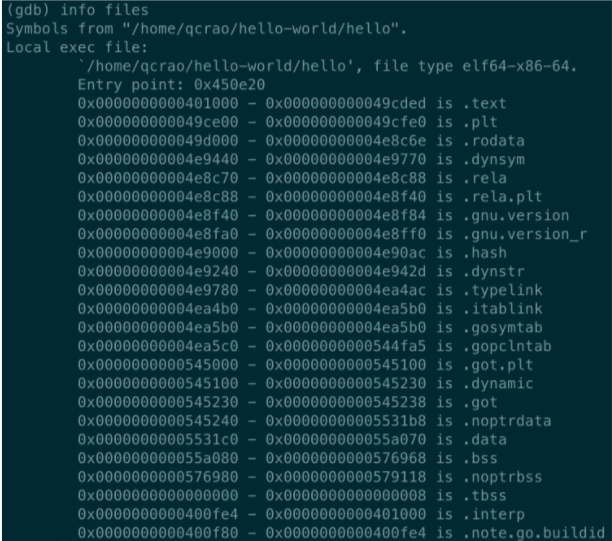
同时,我们也得到了入口地址:0x450e20。
(gdb) b *0x450e20Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.
这就是 Go 程序的入口地址,我是在 linux 上运行的,所以入口文件为 src/runtime/rt0_linux_amd64.s,runtime 目录下有各种不同名称的程序入口文件,支持各种操作系统和架构,代码为:
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8LEAQ 8(SP), SI // argvMOVQ 0(SP), DI // argcMOVQ $main(SB), AXJMP AX
主要是把 argc,argv 从内存拉到了寄存器。这里 LEAQ 是计算内存地址,然后把内存地址本身放进寄存器里,也就是把 argv 的地址放到了 SI 寄存器中。最后跳转到:
TEXT main(SB),NOSPLIT,$-8MOVQ $runtime·rt0_go(SB), AXJMP AX
继续跳转到 runtime·rt0_go(SB),完成 go 启动时所有的初始化工作。
位于 /usr/local/go/src/runtime/asm_amd64.s
初始化g0
注意:这里的g0是一个全局变量,是主线程m0的g0,也需要注意每一个m中也有一个g0,只有m0创建才需要用到一个全局变量g0,其它的m创建时直接m.g0 = xxx 即可
继续看后面的代码,下面开始初始化全局变量g0,前面我们说过,g0的主要作用是提供一个栈供runtime代码执行,因此这里主要对g0的几个与栈有关的成员进行了初始化,从这里可以看出g0的栈大约有64K,地址范围为 SP - 64*1024 + 104 ~ SP。
runtime/asm_amd64.s : 96
// create istack out of the given (operating system) stack.// _cgo_initmay update stackguard.//下面这段代码从系统线程的栈空分出一部分当作g0的栈,然后初始化g0的栈信息和stackgardMOVQ $runtime·g0(SB), DI //g0的地址放入DI寄存器LEAQ (-64*1024+104)(SP), BX//BX=SP- 64*1024 + 104MOVQ BX, g_stackguard0(DI) //g0.stackguard0 =SP- 64*1024 + 104MOVQ BX, g_stackguard1(DI) //g0.stackguard1 =SP- 64*1024 + 104MOVQ BX, (g_stack+stack_lo)(DI) //g0.stack.lo =SP- 64*1024 + 104MOVQ SP, (g_stack+stack_hi)(DI) //g0.stack.hi =SP
运行完上面这几行指令后g0与栈之间的关系如下图所示: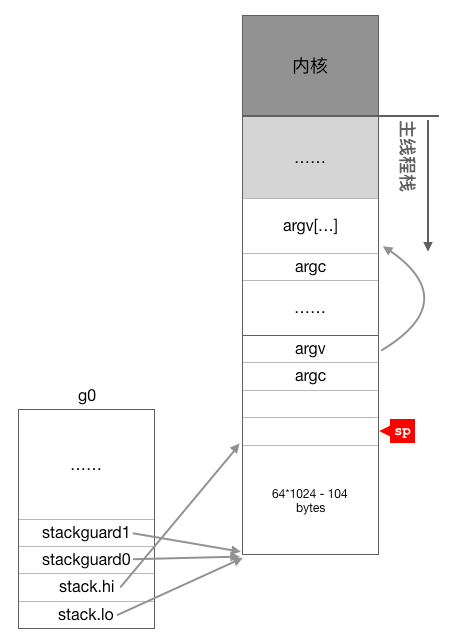
主线程与m0绑定
设置好g0栈之后,我们跳过CPU型号检查以及cgo初始化相关的代码,直接从164行继续分析。
runtime/asm_amd64.s : 164
//下面开始初始化tls(thread local storage,线程本地存储)LEAQ runtime·m0+m_tls(SB), DI//DI=&m0.tls,取m0的tls成员的地址到DI寄存器CALL runtime·settls(SB) //调用settls设置线程本地存储,settls函数的参数在DI寄存器中// store through it, to make sure it works//验证settls是否可以正常工作,如果有问题则abort退出程序get_tls(BX) //获取fs段基地址并放入BX寄存器,其实就是m0.tls[1]的地址,get_tls的代码由编译器生成MOVQ $0x123, g(BX) //把整型常量0x123拷贝到fs段基地址偏移-8的内存位置,也就是m0.tls[0] =0x123MOVQ runtime·m0+m_tls(SB), AX//AX=m0.tls[0]CMPQ AX, $0x123 //检查m0.tls[0]的值是否是通过线程本地存储存入的0x123来验证tls功能是否正常JEQ 2(PC)CALL runtime·abort(SB) //如果线程本地存储不能正常工作,退出程序
这段代码首先调用settls函数初始化主线程的线程本地存储(TLS),目的是把m0与主线程关联在一起,设置了线程本地存储之后接下来的几条指令在于验证TLS功能是否正常,如果不正常则直接abort退出程序
下面我们详细来详细看一下settls函数是如何实现线程私有全局变量的。
runtime/sys_linx_amd64.s : 606
// set tls base to DITEXT runtime·settls(SB),NOSPLIT,$32//......//DI寄存器中存放的是m.tls[0]的地址,m的tls成员是一个数组,读者如果忘记了可以回头看一下m结构体的定义//下面这一句代码把DI寄存器中的地址加8,为什么要+8呢,主要跟ELF可执行文件格式中的TLS实现的机制有关//执行下面这句指令之后DI寄存器中的存放的就是m.tls[1]的地址了ADDQ $8, DI// ELF wants to use -8(FS)//下面通过arch_prctl系统调用设置FS段基址MOVQ DI, SI//SI存放arch_prctl系统调用的第二个参数MOVQ $0x1002, DI// ARCH_SET_FS //arch_prctl的第一个参数MOVQ $SYS_arch_prctl, AX//系统调用编号SYSCALLCMPQ AX, $0xfffffffffffff001JLS 2(PC)MOVL $0xf1, 0xf1 // crash //系统调用失败直接crashRET
从代码可以看到,这里通过archprctl系统调用把m0.tls[1]的地址设置成了fs段的段基址。CPU中有个叫fs的段寄存器与之对应,而每个线程都有自己的一组CPU寄存器值,操作系统在把线程调离CPU运行时会帮我们把所有寄存器中的值保存在内存中,调度线程起来运行时又会从内存中把这些寄存器的值恢复到CPU,这样,在此之后,工作线程代码就可以通过fs寄存器来找到m.tls,读者可以参考上面初始化tls之后对tls功能验证的代码来理解这一过程。
下面继续分析rt0_go,
_runtime/asm_amd64.s : 174
ok:// set the per-goroutine and per-mach "registers"get_tls(BX) //获取fs段基址到BX寄存器LEAQ runtime·g0(SB), CX//CX=g0的地址MOVQ CX, g(BX) //把g0的地址保存在线程本地存储里面,也就是m0.tls[0]=&g0LEAQ runtime·m0(SB), AX//AX=m0的地址//把m0和g0关联起来m0->g0 =g0,g0->m =m0// save m->g0 =g0MOVQ CX, m_g0(AX) //m0.g0 =g0// save m0 to g0->mMOVQ AX, g_m(CX) //g0.m =m0
上面的代码首先把g0的地址放入主线程的线程本地存储中,然后通过m0.g0 = &g0g0.m = &m0
把m0和g0绑定在一起,这样,之后在主线程中通过get_tls可以获取到g0,通过g0的m成员又可以找到m0,于是这里就实现了m0和g0与主线程之间的关联。从这里还可以看到,保存在主线程本地存储中的值是g0的地址,也就是说工作线程的私有全局变量其实是一个指向g的指针而不是指向m的指针,目前这个指针指向g0,表示代码正运行在g0栈。此时,主线程,m0,g0以及g0的栈之间的关系如下图所示: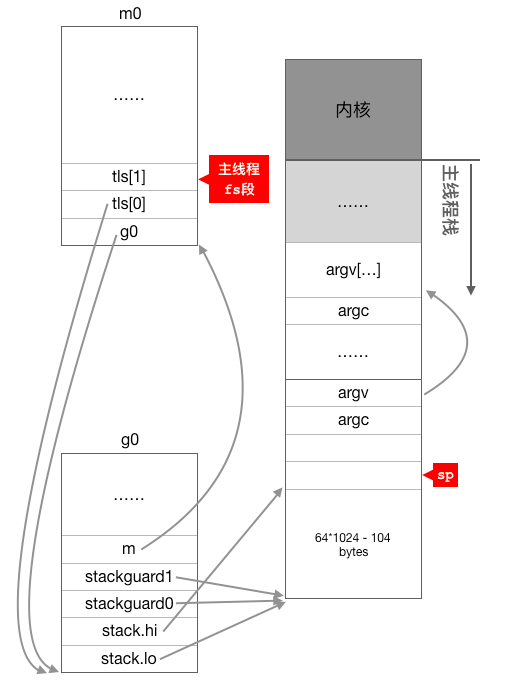
初始化m0
下面代码开始处理命令行参数,这部分我们不关心,所以跳过。命令行参数处理完成后调用osinit函数获取CPU核的数量并保存在全局变量ncpu之中,调度器初始化时需要知道当前系统有多少个CPU核。
runtime/asm_amd64.s : 189
//准备调用args函数,前面四条指令把参数放在栈上MOVL 16(SP), AX// AX = argcMOVL AX, 0(SP) // argc放在栈顶MOVQ 24(SP), AX// AX = argvMOVQ AX, 8(SP) // argv放在SP + 8的位置CALL runtime·args(SB) //处理操作系统传递过来的参数和env,不需要关心//对于linx来说,osinit唯一功能就是获取CPU的核数并放在global变量ncpu中,//调度器初始化时需要知道当前系统有多少CPU核CALL runtime·osinit(SB) //执行的结果是全局变量 ncpu = CPU核数CALL runtime·schedinit(SB) //调度系统初始化
接下来继续看调度器是如何初始化的。
runtime/proc.go : 526
func schedinit() {// raceinit must be the first call to race detector.// In particular, it must be done before mallocinit below calls racemapshadow.//getg函数在源代码中没有对应的定义,由编译器插入类似下面两行代码//get_tls(CX)//MOVQ g(CX), BX; BX存器里面现在放的是当前g结构体对象的地址_g_ := getg() // _g_ = &g0......//设置最多启动10000个操作系统线程,也是最多10000个Msched.maxmcount=10000......mcommoninit(_g_.m) //初始化m0,因为从前面的代码我们知道g0->m = &m0......sched.lastpoll = uint64(nanotime())procs := ncpu //系统中有多少核,就创建和初始化多少个p结构体对象if n, ok: = atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {procs = n//如果环境变量指定了GOMAXPROCS,则创建指定数量的p}if procresize(procs) != nil {//创建和初始化全局变量allpthrow("unknown runnable goroutine during bootstrap")}......}
前面我们已经看到,g0的地址已经被设置到了线程本地存储之中,schedinit通过getg函数(getg函数是编译器实现的,我们在源代码中是找不到其定义的)从线程本地存储中获取当前正在运行的g,这里获取出来的是g0,然后调用mcommoninit函数对m0(g0.m)进行必要的初始化,对m0初始化完成之后调用procresize初始化系统需要用到的p结构体对象,按照go语言官方的说法,p就是processor的意思,它的数量决定了最多可以有都少个goroutine同时并行运行。schedinit函数除了初始化m0和p,还设置了全局变量sched的maxmcount成员为10000,限制最多可以创建10000个操作系统线程出来工作。
这里我们需要重点关注一下mcommoninit如何初始化m0以及procresize函数如何创建和初始化p结构体对象。首先我们深入到mcommoninit函数中一探究竟。这里需要注意的是不只是初始化的时候会执行该函数,在程序运行过程中如果创建了工作线程,也会执行它,所以我们会在函数中看到加锁和检查线程数量是否已经超过最大值等相关的代码。
runtime/proc.go : 596
func mcommoninit(mp*m) {_g_ := getg() //初始化过程中_g_ = g0// g0 stack won't make sense for user (and is not necessary unwindable).if _g_ != _g_.m.g0 { //函数调用栈traceback,不需要关心callers(1, mp.createstack[:])}lock(&sched.lock)if sched.mnext + 1 < sched.mnext {throw("runtime: thread ID overflow")}mp.id = sched.mnextsched.mnext++checkmcount() //检查已创建系统线程是否超过了数量限制(10000)//random初始化mp.fastrand[0] = 1597334677*uint32(mp.id)mp.fastrand[1] = uint32(cputicks())if mp.fastrand[0]|mp.fastrand[1] ==0{mp.fastrand[1] =1}//创建用于信号处理的gsignal,只是简单的从堆上分配一个g结构体对象,然后把栈设置好就返回了mpreinit(mp)if mp.gsignal!=nil {mp.gsignal.stackguard1=mp.gsignal.stack.lo+_StackGuard}//把m挂入全局链表allm之中// Add to allm so garbage collector doesn't free g->m// when it is just in a register or thread-local storage.mp.alllink = allm// NumCgoCall() iterates over allm w/o schedlock,// so we need to publish it safely.atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))unlock(&sched.lock)// Allocate memory to hold a cgo traceback if the cgo call crashes.if iscgo || GOOS == "solaris" || GOOS == "windows" {mp.cgoCallers = new(cgoCallers)}}
从这个函数的源代码可以看出,这里并未对m0做什么关于调度相关的初始化,所以可以简单的认为这个函数只是把m0放入全局链表allm之中就返回了。
m0完成基本的初始化后,继续调用procresize创建和初始化p结构体对象,在这个函数里面会创建指定个数(根据cpu核数或环境变量确定)的p结构体对象放在全变量allp里, 并把m0和allp[0]绑定在一起,因此当这个函数执行完成之后就有m0.p = allp[0]allp[0].m = &m0
到此m0, g0, 和m需要的p完全关联在一起了。
初始化allp
下面我们来看procresize函数,考虑到初始化完成之后用户代码还可以通过 GOMAXPROCS()函数调用它重新创建和初始化p结构体对象,而在运行过程中再动态的调整p牵涉到的问题比较多,所以这个函数的处理比较复杂,但如果只考虑初始化,相对来说要简单很多,所以这里只保留了初始化时会执行的代码:
runtime/proc.go : 3902
func procresize(nprocsint32) *p {old := gomaxprocs//系统初始化时 gomaxprocs = 0......// Grow allp if necessary.if nprocs > int32(len(allp)) { //初始化时 len(allp) == 0// Synchronize with retake, which could be running// concurrently since it doesn't run on a P.lock(&allpLock)if nprocs <= int32(cap(allp)) {allp = allp[:nprocs]} else { //初始化时进入此分支,创建allp 切片nallp:=make([]*p, nprocs)// Copy everything up to allp's cap so we// never lose old allocated Ps.copy(nallp, allp[:cap(allp)])allp=nallp}unlock(&allpLock)}// initialize new P's//循环创建nprocs个p并完成基本初始化for i := int32(0); i<nprocs; i++{pp := allp[i]if pp == nil{pp=new(p)//调用内存分配器从堆上分配一个struct ppp.id=ipp.status=_Pgcstop......atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))}......}......_g_:=getg() // _g_ = g0if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {//初始化时m0->p还未初始化,所以不会执行这个分支// continue to use the current P_g_.m.p.ptr().status=_Prunning_g_.m.p.ptr().mcache.prepareForSweep()} else {//初始化时执行这个分支// release the current P and acquire allp[0]if _g_.m.p != 0 {//初始化时这里不执行_g_.m.p.ptr().m=0}_g_.m.p=0_g_.m.mcache = nilp := allp[0]p.m = 0p.status = _Pidleacquirep(p) //把p和m0关联起来,其实是这两个strct的成员相互赋值if trace.enabled {traceGoStart()}}//下面这个for 循环把所有空闲的p放入空闲链表var runnablePs *pfor i := nprocs-1; i >= 0; i-- {p := allp[i]if _g_.m.p.ptr() == p {//allp[0]跟m0关联了,所以是不能放任continue}p.status = _Pidleif runqempty(p) {//初始化时除了allp[0]其它p全部执行这个分支,放入空闲链表pidleput(p)} else {......}}......return runnablePs}
这个函数代码比较长,但并不复杂,这里总结一下这个函数的主要流程:
- 使用make([]p, nprocs)初始化全局变量allp,即allp = make([]p, nprocs)
- 循环创建并初始化nprocs个p结构体对象并依次保存在allp切片之中
- 把m0和allp[0]绑定在一起,即m0.p = allp[0], allp[0].m = m0
- 把除了allp[0]之外的所有p放入到全局变量sched的pidle空闲队列之中
procresize函数执行完后,调度器相关的初始化工作就基本结束了,这时整个调度器相关的各组成部分之间的联系如下图所示: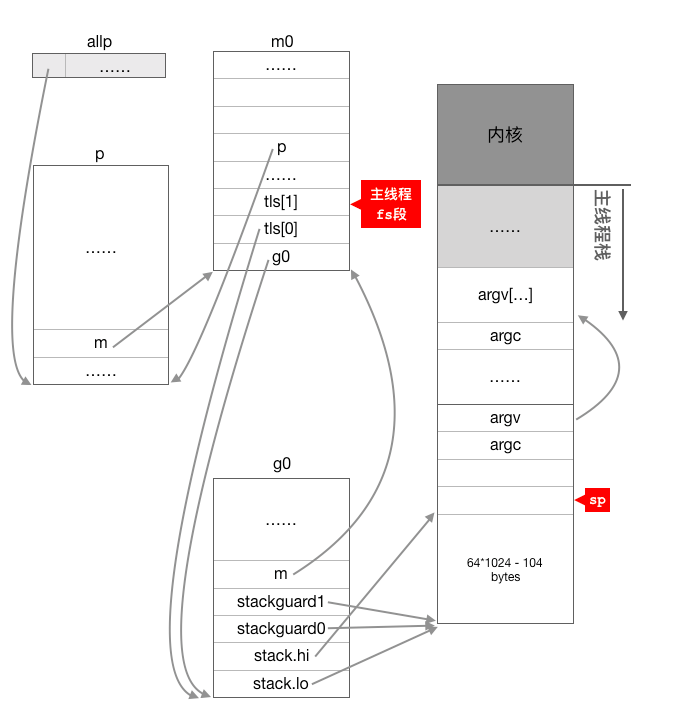

若有收获,就点个赞吧
0 人点赞
