内部数据结构
@(src/runtime/slice.go)
slice 仅有三个字段,其中array 是保存数据的部分,len 字段为长度,cap 为容量。
type slice struct {array unsafe.Pointer // 数据部分len int // 长度cap int // 容量}
创建
创建一个slice,其实就是分配内存。cap, len 的设置在汇编中完成。

下面的代码主要是做了容量大小的判断,以及内存的分配。
@(src/runtime/slice.go)
func makeslice(et *_type, len, cap int) unsafe.Pointer {// 获取需要申请的内存大小mem, overflow := math.MulUintptr(et.size, uintptr(cap))if overflow || mem > maxAlloc || len < 0 || len > cap {mem, overflow := math.MulUintptr(et.size, uintptr(len))if overflow || mem > maxAlloc || len < 0 {panicmakeslicelen()}panicmakeslicecap()}// 分配内存// 小对象从当前P 的cache中空闲数据中分配// 大的对象 (size > 32KB) 直接从heap中分配// runtime/malloc.goreturn mallocgc(mem, et, true)}
append
对于不需要内存扩容的slice,直接数据拷贝即可。
注意:append是在现有的长度上追加
func main() {a := make([]int,10,100)a = append(a,1)fmt.Println(a) // [0 0 0 0 0 0 0 0 0 0 1]}
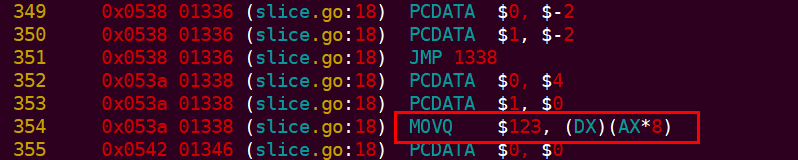
上面的DX 存放的就是array 指针,AX 是数据的偏移. 将 123 存入数组。
而对于容量不够的情况,就需要对slice 进行扩容。这也是slice 比较关心的地方。 (因为对于大slice,grow slice会影响到内存的分配和执行的效率)
@(src/runtime/slice.go)
func growslice(et *_type, old slice, cap int) slice {// 静态分析, 内存扫描// ...if cap < old.cap {panic(errorString("growslice: cap out of range"))}// 如果存储的类型空间为0, 比如说 []struct{}, 数据为空,长度不为空if et.size == 0 {return slice{unsafe.Pointer(&zerobase), old.len, cap}}newcap := old.capdoublecap := newcap + newcapif cap > doublecap {// 如果新容量大于原有容量的两倍,则直接按照新增容量大小申请newcap = cap} else {if old.len < 1024 {// 如果原有长度小于1024,那新容量是老容量的2倍newcap = doublecap} else {// 按照原有容量的1/4 增加,直到满足新容量的需要for 0 < newcap && newcap < cap {newcap += newcap / 4}// 通过校验newcap 大于0检查容量是否溢出。if newcap <= 0 {newcap = cap}}}var overflow boolvar lenmem, newlenmem, capmem uintptr// 为了加速计算(少用除法,乘法)// 对于不同的slice元素大小,选择不同的计算方法// 获取需要申请的内存大小。switch {case et.size == 1:lenmem = uintptr(old.len)newlenmem = uintptr(cap)capmem = roundupsize(uintptr(newcap))overflow = uintptr(newcap) > maxAllocnewcap = int(capmem)case et.size == sys.PtrSize:lenmem = uintptr(old.len) * sys.PtrSizenewlenmem = uintptr(cap) * sys.PtrSizecapmem = roundupsize(uintptr(newcap) * sys.PtrSize)overflow = uintptr(newcap) > maxAlloc/sys.PtrSizenewcap = int(capmem / sys.PtrSize)case isPowerOfTwo(et.size):// 二的倍数,用位移运算var shift uintptrif sys.PtrSize == 8 {// Mask shift for better code generation.shift = uintptr(sys.Ctz64(uint64(et.size))) & 63} else {shift = uintptr(sys.Ctz32(uint32(et.size))) & 31}lenmem = uintptr(old.len) << shiftnewlenmem = uintptr(cap) << shiftcapmem = roundupsize(uintptr(newcap) << shift)overflow = uintptr(newcap) > (maxAlloc >> shift)newcap = int(capmem >> shift)default:// 其他用除法lenmem = uintptr(old.len) * et.sizenewlenmem = uintptr(cap) * et.sizecapmem, overflow = math.MulUintptr(et.size, uintptr(newcap))capmem = roundupsize(capmem)newcap = int(capmem / et.size)}// 判断是否会溢出if overflow || capmem > maxAlloc {panic(errorString("growslice: cap out of range"))}// 内存分配var p unsafe.Pointerif et.kind&kindNoPointers != 0 {p = mallocgc(capmem, nil, false)// 清空不需要数据拷贝的部分内存memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)} else {// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.p = mallocgc(capmem, et, true)if writeBarrier.enabled { // gc 相关// Only shade the pointers in old.array since we know the destination slice p// only contains nil pointers because it has been cleared during alloc.bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)}}// 数据拷贝memmove(p, old.array, lenmem)return slice{p, old.len, newcap}}
切片拷贝 (copy)
切片的浅拷贝
直接切就是浅拷贝
func main() {a := make([]int,10,100)a1 := a[9:12:12]a1[0] = 100fmt.Println(a) // [0 0 0 0 0 0 0 0 0 100]}
切片的深拷贝
深拷贝也比较简单,只是做了一次内存的深拷贝。
对于使用者角度,用copy即可
func slicecopy(to, fm slice, width uintptr) int {if fm.len == 0 || to.len == 0 {return 0}n := fm.lenif to.len < n {n = to.len}// 元素大小为0,则直接返回if width == 0 {return n}// 竟态分析和内存扫描// ...size := uintptr(n) * width// 直接内存拷贝if size == 1 { // common case worth about 2x to do here*(*byte)(to.array) = *(*byte)(fm.array) // known to be a byte pointer} else {memmove(to.array, fm.array, size)}return n}// 字符串slice的拷贝func slicestringcopy(to []byte, fm string) int {if len(fm) == 0 || len(to) == 0 {return 0}n := len(fm)if len(to) < n {n = len(to)}// 竟态分析和内存扫描// ...memmove(unsafe.Pointer(&to[0]), stringStructOf(&fm).str, uintptr(n))return n}
引用类型作为参数时传递的是地址还是值?
在 Golang 中函数之间传递变量时总是以值的方式传递的,无论是 int,string,bool,array 这样的内置类型(或者说原始的类型),还是 slice,channel,map 这样的引用类型,在函数间传递变量时,都是以值的方式传递,也就是说传递的都是值的副本
感觉值传递示例:
func main() {slice := []int{1, 2, 3, 4, 5}fmt.Printf("切片:%v\n", slice)setSliceNil(slice)fmt.Printf("切片:%v\n", slice)}func setSliceNil(slice []int) {slice = nilfmt.Printf("切片:%v\n", slice)}切片:[1 2 3 4 5]切片:[]切片:[1 2 3 4 5]经过函数中对slice赋值nil并没有改变main中的slice变量的值,说明go中引用类型的传递也是值传递
感觉指针传递示例
func main() {slice := []int{1, 2, 3, 4, 5}fmt.Printf("切片:%v\n", slice)changeSlice(slice)fmt.Printf("切片:%v\n", slice)}func changeSlice(slice []int) {slice[2] = 10fmt.Printf("切片:%v\n", slice)}切片:[1 2 3 4 5]切片:[1 2 10 4 5]切片:[1 2 10 4 5]这里的结果会让人产生困惑,既然是值传递为什么main函数中的切片被修改了呢
golang所有参数传递都是值传递
为什么都是值传递,会有指针传递的效果,这个得从源码的角度来说
以切片为例:定义一个切片返回的是一个指针
type slice struct {array unsafe.Pointer // 数据部分len int // 长度cap int // 容量}func makeslice(et *_type, len, cap int) unsafe.Pointer {...}注意:1.10版本之前makeslice返回的是一个slicefunc makeslice(et *_type, len, cap int) slice {...}这个问题,让我纠结了很久,这里的makeslice实际上创建的是底层数组(也就是slice.array),注意:在reflect包也解释了,SliceHeader才是slice运行的结构type SliceHeader struct {Data uintptrLen intCap int}
我以为,map与slice传递的都是指针类型,实际上不是这样的,例如下面
type a struct {a []int64}type b struct {b []int64}func main() {a := a{make([]int64, 10, 100)}a.a[0] = 1fmt.Printf("%p\n", a.a)b := b{a.a}fmt.Printf("%p\n", b.b)b.b = append(b.b, 1, 2, 3)b.b[0] = 0fmt.Printf("%p\n", b.b)fmt.Println(b.b)fmt.Println(a.a)}0xc0000700000xc0000700000xc000070000[0 0 0 0 0 0 0 0 0 0 1 2 3][0 0 0 0 0 0 0 0 0 0]
可以看到地址没变,b.b的长度增长没影响到a.a 但a.a[0] 却受到了 b.b[0]=0的影响
或下面
func main() {slice := make([]int, 10, 20)fmt.Printf("%p\n", slice) // 0xc00008e000bbb(slice)fmt.Println(len(slice)) // 10}func bbb(slice []int) {fmt.Printf("%p\n", slice) // 0xc00008e000for v := 0; v < 10; v++ {slice = append(slice, v)}// 虽然这里的地址没变,但不会影响到main中的slice// 为什么append后地址没变,是因为main中的slice初始化时,容量给的较大// 这里我们在循环中,v改大一点,是会导致slice底层的数组重新分配一次内存fmt.Printf("%p\n", slice) // 0xc00008e000fmt.Println(len(slice)) //20}
问题来了,为什么地址是一样的,但是main中slice的长度没有改变,注意:fmt.Printf(“%p\n”, slice)这里打印的是底层数组的数组的标头地址,上面的append并没有导致扩容,所以底层的数组是没有变化的,而slice传递是值传递,会将len=10,cap=20,data=0xc00008e000传给方法bbb,bbb中的slice由于append,长度发生了变化,但这并不影响main中的slice的长度
结论:在参数传递中还是传递的slice结构体
切片与数组
数组是定长的,长度定义好之后,不能再更改。在 Go 中,数组是不常见的,因为其长度是类型的一部分,限制了它的表达能力,比如 [3]int 和 [4]int 就是不同的类型。
而切片则非常灵活,它可以动态地扩容。切片的类型和长度无关。
数组就是一片连续的内存, slice 实际上是一个结构体,包含三个字段:长度、容量、底层数组。
@runtime/slice.go
type slice struct {array unsafe.Pointer // 元素指针len int // 长度cap int // 容量}
slice 的数据结构如下:
注意,底层数组是可以被多个 slice 同时指向的,因此对一个 slice 的元素进行操作是有可能影响到其他 slice 的。
【引申1】 [3]int 和 [4]int 是同一个类型吗?
不是。因为数组的长度是类型的一部分,这是与 slice 不同的一点。
【引申2】 下面的代码输出是什么?
package mainimport "fmt"func main() {slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}s1 := slice[2:5]s2 := s1[2:6:7]s2 = append(s2, 100)s2 = append(s2, 200)s1[2] = 20fmt.Println(s1)fmt.Println(s2)fmt.Println(slice)}结果:[2 3 20][4 5 6 7 100 200][0 1 2 3 20 5 6 7 100 9]
说明:例子来自雨痕大佬《Go学习笔记》第四版,P43页。这里我会进行扩展,并会作图详细分析。
s1 从 slice 索引2(闭区间)到索引5(开区间,元素真正取到索引4),长度为3,容量默认到数组结尾,为8。 s2 从 s1 的索引2(闭区间)到索引6(开区间,元素真正取到索引5),容量到索引7(开区间,真正到索引6),为5。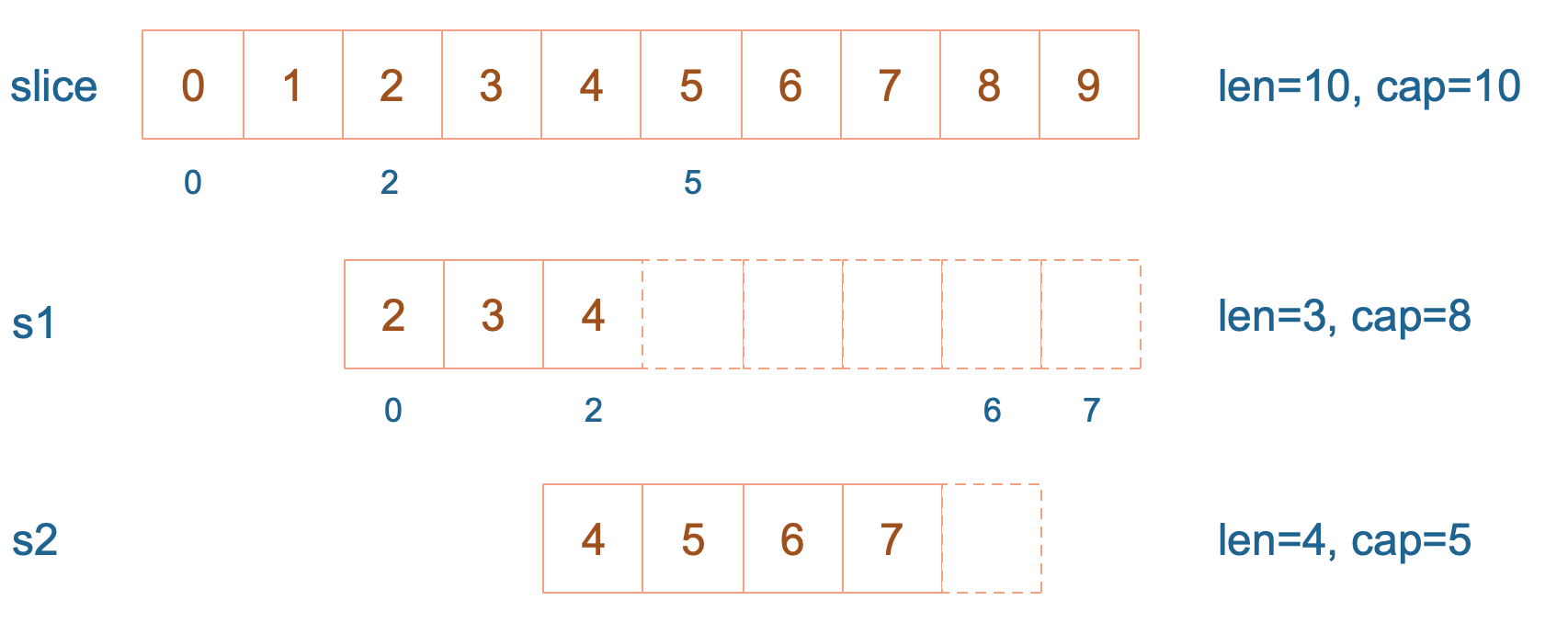
接着,向 s2 尾部追加一个元素 100:
s2 = append(s2, 100)s2 容量刚好够,直接追加。不过,这会修改原始数组对应位置的元素。这一改动,数组和 s1 都可以看得到。
再次向 s2 追加元素200:
s2 = append(s2, 100)
这时,s2 的容量不够用,该扩容了。于是,s2 另起炉灶,将原来的元素复制新的位置,扩大自己的容量。并且为了应对未来可能的 append 带来的再一次扩容,s2 会在此次扩容的时候多留一些 buffer,将新的容量将扩大为原始容量的2倍,也就是10了。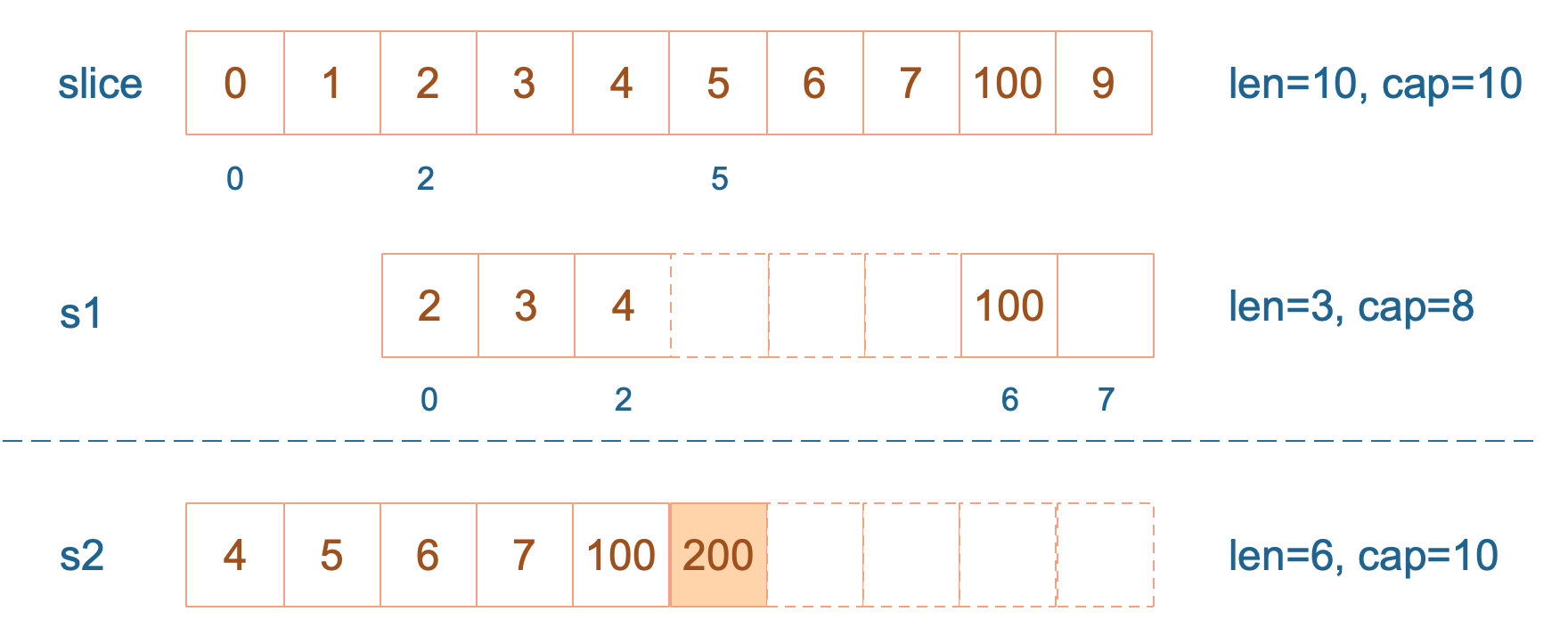
最后,修改 s1 索引为2位置的元素:
s1[2] = 20
这次只会影响原始数组相应位置的元素。它影响不到 s2 了,人家已经远走高飞了。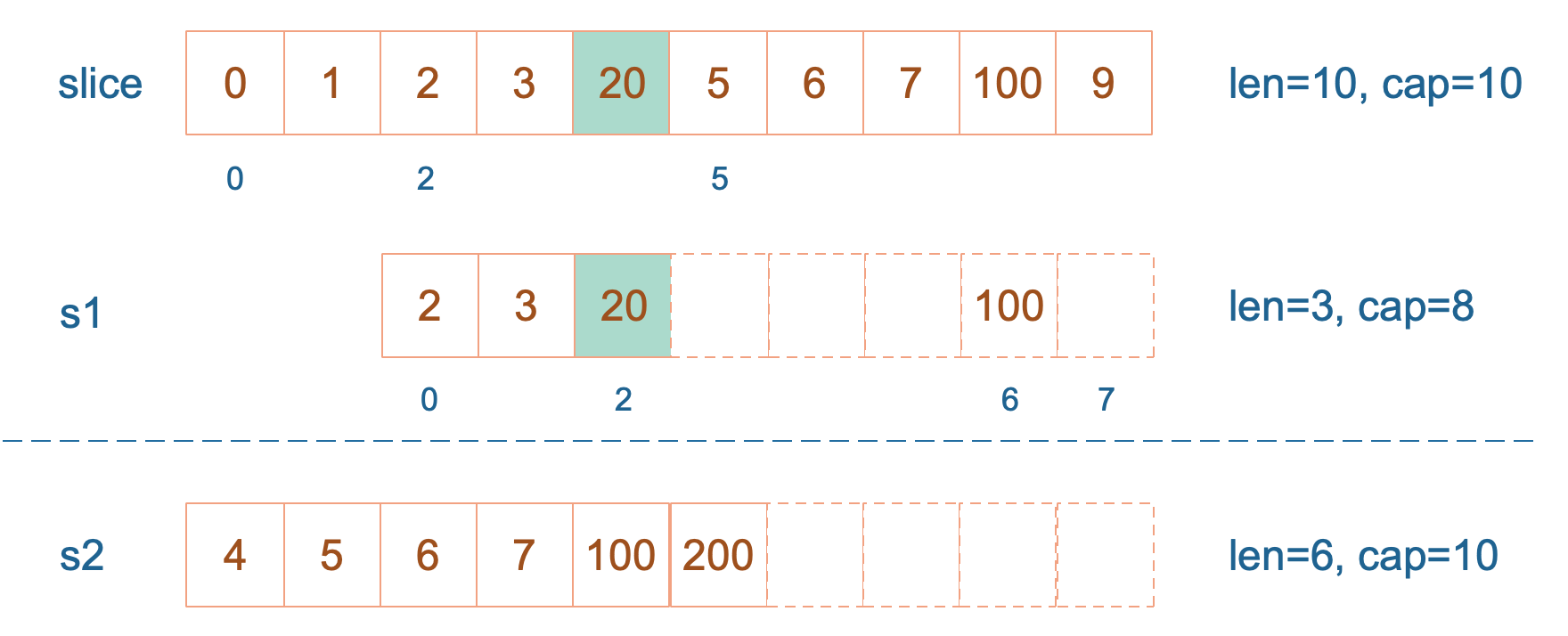
再提一点,打印 s1 的时候,只会打印出 s1 长度以内的元素。所以,只会打印出3个元素,虽然它的底层数组不止3个元素。
其他
汇编的生成方法
go tool compile -N -S slice.go > slice.S
需要了解unsafe.Pointer 的使用
- slice.go 位于 runtime/slice.go
- 上述代码使用 go1.12.5 版本
- 还有一点需要提醒, type 长度为0的对象。比如说 struct{} 类型。(所以,很多使用chan struct{} 做channel 的传递,节省内存)
package mainimport "fmt"import "unsafe"func main() {var data [100000]struct{}var data1 [100000]int// 0fmt.Println(unsafe.Sizeof(data))// 800000fmt.Println(unsafe.Sizeof(data1))}

若有收获,就点个赞吧
0 人点赞
