很多现代的编程语言中都有defer关键字,Go 语言的defer会在当前函数返回前执行传入的函数,它会经常被用于关闭文件描述符、关闭数据库连接以及解锁资源。这一节会深入 Go 语言的源代码介绍defer关键字的实现原理,相信读者读完这一节会对defer的数据结构、实现以及调用过程有着更清晰的理解。
作为一个编程语言中的关键字,defer的实现一定是由编译器和运行时共同完成的,不过在深入源码分析它的实现之前我们还是需要了解defer关键字的常见使用场景以及使用时的注意事项。
使用defer的最常见场景是在函数调用结束后完成一些收尾工作,例如在defer中回滚数据库的事务:
func createPost(db *gorm.DB) error {tx := db.Begin()defer tx.Rollback()if err := tx.Create(&Post{Author: "Draveness"}).Error; err != nil {return err}return tx.Commit().Error}
在使用数据库事务时,我们可以使用上面的代码在创建事务后就立刻调用Rollback保证事务一定会回滚。哪怕事务真的执行成功了,那么调用tx.Commit()之后再执行tx.Rollback()也不会影响已经提交的事务。
现象
我们在 Go 语言中使用defer时会遇到两个常见问题,这里会介绍具体的场景并分析这两个现象背后的设计原理:
- defer关键字的调用时机以及多次调用defer时执行顺序是如何确定的;
- defer关键字使用传值的方式传递参数时会进行预计算,导致不符合预期的结果;
作用域
向defer关键字传入的函数会在函数返回之前运行。假设我们在for循环中多次调用defer关键字:
func main() {for i := 0; i < 5; i++ {defer fmt.Println(i)}}$ go run main.go43210
运行上述代码会倒序执行传入defer关键字的所有表达式,因为最后一次调用defer时传入了fmt.Println(4),所以这段代码会优先打印 4。我们可以通过下面这个简单例子强化对defer执行时机的理解:
func main() {{defer fmt.Println("defer runs")fmt.Println("block ends")}fmt.Println("main ends")}$ go run main.goblock endsmain endsdefer runs
从上述代码的输出我们会发现,defer传入的函数不是在退出代码块的作用域时执行的,它只会在当前函数和方法返回之前被调用。
预计算参数
Go 语言中所有的函数调用都是传值的,虽然defer是关键字,但是也继承了这个特性。假设我们想要计算main函数运行的时间,可能会写出以下的代码:
func main() {startedAt := time.Now()defer fmt.Println(time.Since(startedAt))time.Sleep(time.Second)}$ go run main.go0s
然而上述代码的运行结果并不符合我们的预期,这个现象背后的原因是什么呢?经过分析,我们会发现调用defer关键字会立刻拷贝函数中引用的外部参数,所以time.Since(startedAt)的结果不是在main函数退出之前计算的,而是在defer关键字调用时计算的,最终导致上述代码输出 0s。
想要解决这个问题的方法非常简单,我们只需要向defer关键字传入匿名函数:
func main() {startedAt := time.Now()defer func() { fmt.Println(time.Since(startedAt)) }()time.Sleep(time.Second)}$ go run main.go1s
虽然调用defer关键字时也使用值传递,但是因为拷贝的是函数指针,所以time.Since(startedAt)会在main函数返回前调用并打印出符合预期的结果。
预计算参数-变种
第一次看到这题,我迟疑了下,居然不太确定输出的结果
注意结构体方法的调用,如:s.Add(1), 此时 s 就是Add 方法的参数
package mainimport "fmt"type Slice []intfunc NewSlice() Slice {return make(Slice, 0)}func (s *Slice) Add(elem int) *Slice {*s = append(*s, elem)fmt.Print(elem)return s}func main() {s := NewSlice()defer s.Add(1).Add(2).Add(3).Add(5)s.Add(4)}// output12345
数据结构
在介绍defer函数的执行过程与实现原理之前,我们首先来了解一下defer关键字在 Go 语言源代码中对应的数据结构:
type _defer struct {siz int32started boolopenDefer boolsp uintptrpc uintptrfn *funcval_panic *_paniclink *_defer}
runtime._defer结构体是延迟调用链表上的一个元素,所有的结构体都会通过link字段串联成链表。
我们简单介绍一下runtime._defer结构体中的几个字段:
- siz是参数和结果的内存大小;
- sp和pc分别代表栈指针和调用方的程序计数器;
- fn是defer关键字中传入的函数;
- _panic是触发延迟调用的结构体,可能为空;
- openDefer表示当前defer是否经过开放编码的优化;
除了上述的这些字段之外,runtime._defer中还包含一些垃圾回收机制使用的字段,这里为了减少理解的成本就都省去了。
执行机制
中间代码生成阶段的cmd/compile/internal/gc.state.stmt会负责处理程序中的defer,该函数会根据条件的不同,使用三种不同的机制处理该关键字:
func (s *state) stmt(n *Node) {...switch n.Op {case ODEFER:if s.hasOpenDefers {s.openDeferRecord(n.Left) // 开放编码} else {d := callDefer // 堆分配if n.Esc == EscNever {d = callDeferStack // 栈分配}s.callResult(n.Left, d)}}}
堆分配、栈分配和开放编码是处理defer关键字的三种方法,早期的 Go 语言会在堆上分配runtime._defer结构体,不过该实现的性能较差,Go 语言在 1.13 中引入栈上分配的结构体,减少了 30% 的额外开销1,并在 1.14 中引入了基于开放编码的defer,使得该关键字的额外开销可以忽略不计2,我们在一节中会分别介绍三种不同类型defer的设计与实现原理。
堆上分配
根据cmd/compile/internal/gc.state.stmt方法对defer的处理我们可以看出,堆上分配的runtime._defer结构体是默认的兜底方案,当该方案被启用时,编译器会调用cmd/compile/internal/gc.state.callResult和cmd/compile/internal/gc.state.call,这表示defer在编译器看来也是函数调用。
cmd/compile/internal/gc.state.call会负责为所有函数和方法调用生成中间代码,它的工作包括以下内容:
- 获取需要执行的函数名、闭包指针、代码指针和函数调用的接收方;
- 获取栈地址并将函数或者方法的参数写入栈中;
- 使用cmd/compile/internal/gc.state.newValue1A以及相关函数生成函数调用的中间代码;
- 如果当前调用的函数是defer,那么会单独生成相关的结束代码块;
- 获取函数的返回值地址并结束当前调用;
从上述代码中我们能看到,defer关键字在运行期间会调用runtime.deferproc,这个函数接收了参数的大小和闭包所在的地址两个参数。func (s *state) call(n *Node, k callKind, returnResultAddr bool) *ssa.Value {...var call *ssa.Valueif k == callDeferStack {// 在栈上初始化 defer 结构体...} else {...switch {case k == callDefer:aux := ssa.StaticAuxCall(deferproc, ACArgs, ACResults)call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, aux, s.mem())...}call.AuxInt = stksize}s.vars[&memVar] = call...}
编译器不仅将defer关键字都转换成runtime.deferproc函数,它还会通过以下三个步骤为所有调用defer的函数末尾插入runtime.deferreturn的函数调用:
- cmd/compile/internal/gc.walkstmt在遇到ODEFER节点时会执行Curfn.Func.SetHasDefer(true)设置当前函数的hasdefer属性;
- cmd/compile/internal/gc.buildssa会执行s.hasdefer = fn.Func.HasDefer()更新state的hasdefer;
- cmd/compile/internal/gc.state.exit会根据state的hasdefer在函数返回之前插入runtime.deferreturn的函数调用;
当运行时将runtime._defer分配到堆上时,Go 语言的编译器不仅将defer转换成了runtime.deferproc,还在所有调用defer的函数结尾插入了runtime.deferreturn。上述两个运行时函数是defer关键字运行时机制的入口,它们分别承担了不同的工作:func (s *state) exit() *ssa.Block {if s.hasdefer {...s.rtcall(Deferreturn, true, nil)}...}
- runtime.deferproc负责创建新的延迟调用;
- runtime.deferreturn负责在函数调用结束时执行所有的延迟调用;
我们以上述两个函数为入口介绍defer关键字在运行时的执行过程与工作原理。
创建延迟调用
runtime.deferproc会为defer创建一个新的runtime._defer结构体、设置它的函数指针fn、程序计数器pc和栈指针sp并将相关的参数拷贝到相邻的内存空间中:
func deferproc(siz int32, fn *funcval) {sp := getcallersp()argp := uintptr(unsafe.Pointer(&fn)) + unsafe.Sizeof(fn)callerpc := getcallerpc()d := newdefer(siz)if d._panic != nil {throw("deferproc: d.panic != nil after newdefer")}d.fn = fnd.pc = callerpcd.sp = spswitch siz {case 0:case sys.PtrSize:*(*uintptr)(deferArgs(d)) = *(*uintptr)(unsafe.Pointer(argp))default:memmove(deferArgs(d), unsafe.Pointer(argp), uintptr(siz))}return0()}
最后调用的runtime.return0是唯一一个不会触发延迟调用的函数,它可以避免递归runtime.deferreturn的递归调用。
runtime.deferproc中runtime.newdefer的作用是想尽办法获得runtime._defer结构体,这里包含三种路径:
- 从调度器的延迟调用缓存池sched.deferpool中取出结构体并将该结构体追加到当前 Goroutine 的缓存池中;
- 从 Goroutine 的延迟调用缓存池pp.deferpool中取出结构体;
- 通过runtime.mallocgc在堆上创建一个新的结构体;
无论使用哪种方式,只要获取到runtime._defer结构体,它都会被追加到所在 Goroutine_defer链表的最前面。func newdefer(siz int32) *_defer {var d *_defersc := deferclass(uintptr(siz))gp := getg()if sc < uintptr(len(p{}.deferpool)) {pp := gp.m.p.ptr()if len(pp.deferpool[sc]) == 0 && sched.deferpool[sc] != nil {for len(pp.deferpool[sc]) < cap(pp.deferpool[sc])/2 && sched.deferpool[sc] != nil {d := sched.deferpool[sc]sched.deferpool[sc] = d.linkpp.deferpool[sc] = append(pp.deferpool[sc], d)}}if n := len(pp.deferpool[sc]); n > 0 {d = pp.deferpool[sc][n-1]pp.deferpool[sc][n-1] = nilpp.deferpool[sc] = pp.deferpool[sc][:n-1]}}if d == nil {total := roundupsize(totaldefersize(uintptr(siz)))d = (*_defer)(mallocgc(total, deferType, true))}d.siz = sizd.link = gp._defergp._defer = dreturn d}
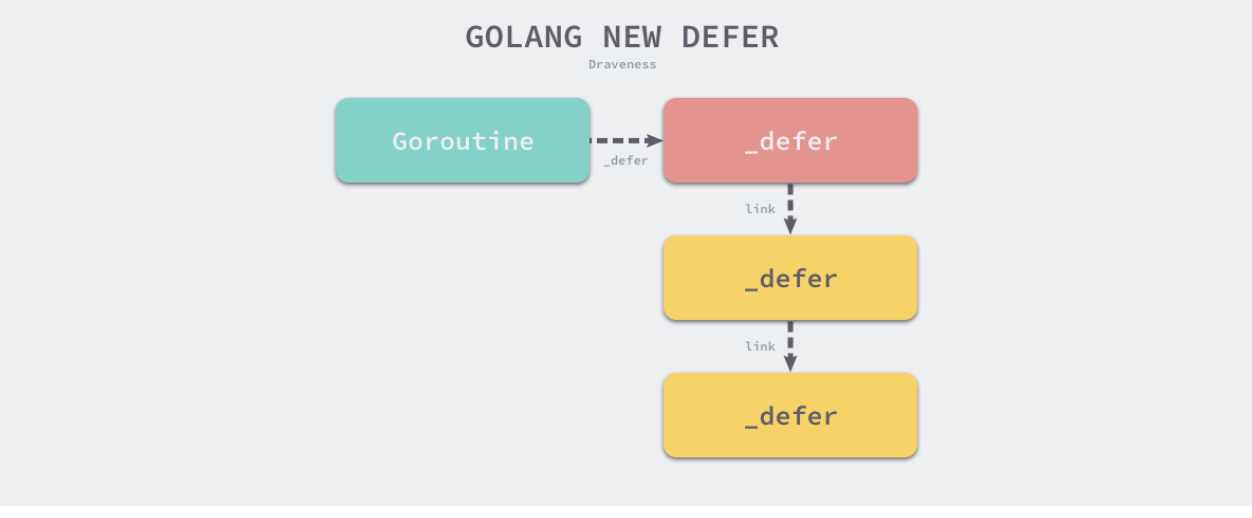
defer关键字的插入顺序是从后向前的,而defer关键字执行是从前向后的,这也是为什么后调用的defer会优先执行。
执行延迟调用
runtime.deferreturn会从 Goroutine 的_defer链表中取出最前面的runtime._defer并调用runtime.jmpdefer传入需要执行的函数和参数:
func deferreturn(arg0 uintptr) {gp := getg()d := gp._deferif d == nil {return}sp := getcallersp()...switch d.siz {case 0:case sys.PtrSize:*(*uintptr)(unsafe.Pointer(&arg0)) = *(*uintptr)(deferArgs(d))default:memmove(unsafe.Pointer(&arg0), deferArgs(d), uintptr(d.siz))}fn := d.fngp._defer = d.linkfreedefer(d)jmpdefer(fn, uintptr(unsafe.Pointer(&arg0)))}
freedefer会将d结构体放回pp.deferpool,以供下次使用
runtime/panic.go
// Free the given defer.// The defer cannot be used after this call.//// This must not grow the stack because there may be a frame without a// stack map when this is called.////go:nosplitfunc freedefer(d *_defer) {...// These lines used to be simply `*d = _defer{}` but that// started causing a nosplit stack overflow via typedmemmove.d.siz = 0d.started = falsed.openDefer = falsed.sp = 0d.pc = 0d.framepc = 0d.varp = 0d.fd = nil// d._panic and d.fn must be nil already.// If not, we would have called freedeferpanic or freedeferfn above,// both of which throw.d.link = nilpp.deferpool[sc] = append(pp.deferpool[sc], d)}
runtime.jmpdefer是一个用汇编语言实现的运行时函数,它的主要工作是跳转到defer所在的代码段并在执行结束之后跳转回runtime.deferreturn。
TEXT runtime·jmpdefer(SB), NOSPLIT, $0-8MOVL fv+0(FP), DX // fnMOVL argp+4(FP), BX // caller spLEAL -4(BX), SP // caller sp after CALL#ifdef GOBUILDMODE_sharedSUBL $16, (SP) // return to CALL again#elseSUBL $5, (SP) // return to CALL again#endifMOVL 0(DX), BXJMP BX // but first run the deferred function
runtime.deferreturn会多次判断当前 Goroutine 的_defer链表中是否有未执行的结构体,该函数只有在所有延迟函数都执行后才会返回。
栈上分配
在默认情况下,我们可以看到 Go 语言中runtime._defer结构体都会在堆上分配,如果我们能够将部分结构体分配到栈上就可以节约内存分配带来的额外开销。
Go 语言团队在 1.13 中对defer关键字进行了优化,当该关键字在函数体中最多执行一次时,编译期间的cmd/compile/internal/gc.state.call会将结构体分配到栈上并调用runtime.deferprocStack:
func (s *state) call(n *Node, k callKind) *ssa.Value {...var call *ssa.Valueif k == callDeferStack {// 在栈上创建 _defer 结构体t := deferstruct(stksize)...ACArgs = append(ACArgs, ssa.Param{Type: types.Types[TUINTPTR], Offset: int32(Ctxt.FixedFrameSize())})aux := ssa.StaticAuxCall(deferprocStack, ACArgs, ACResults) // 调用 deferprocStackarg0 := s.constOffPtrSP(types.Types[TUINTPTR], Ctxt.FixedFrameSize())s.store(types.Types[TUINTPTR], arg0, addr)call = s.newValue1A(ssa.OpStaticCall, types.TypeMem, aux, s.mem())call.AuxInt = stksize} else {...}s.vars[&memVar] = call...}
因为在编译期间我们已经创建了runtime._defer结构体,所以在运行期间runtime.deferprocStack只需要设置一些未在编译期间初始化的字段,就可以将栈上的runtime._defer追加到函数的链表上:
func deferprocStack(d *_defer) {gp := getg()d.started = falsed.heap = false // 栈上分配的 _deferd.openDefer = falsed.sp = getcallersp()d.pc = getcallerpc()d.framepc = 0d.varp = 0*(*uintptr)(unsafe.Pointer(&d._panic)) = 0*(*uintptr)(unsafe.Pointer(&d.fd)) = 0*(*uintptr)(unsafe.Pointer(&d.link)) = uintptr(unsafe.Pointer(gp._defer))*(*uintptr)(unsafe.Pointer(&gp._defer)) = uintptr(unsafe.Pointer(d))return0()}
除了分配位置的不同,栈上分配和堆上分配的runtime._defer并没有本质的不同,而该方法可以适用于绝大多数的场景,与堆上分配的runtime._defer相比,该方法可以将defer关键字的额外开销降低 ~30%。
开放编码
Go 语言在 1.14 中通过开放编码(Open Coded)实现defer关键字,该设计使用代码内联优化defer关键的额外开销并引入函数数据funcdata管理panic的调用3,该优化可以将defer的调用开销从 1.13 版本的 ~35ns 降低至 ~6ns 左右:
With normal (stack-allocated) defers only: 35.4 ns/opWith open-coded defers: 5.6 ns/opCost of function call alone (remove defer keyword): 4.4 ns/op
然而开放编码作为一种优化defer关键字的方法,它不是在所有的场景下都会开启的,开放编码只会在满足以下的条件时启用:
- 函数的defer数量少于或者等于 8 个;
- 函数的defer关键字不能在循环中执行;
- 函数的return语句与defer语句的乘积小于或者等于 15 个;
初看上述几个条件可能会觉得不明所以,但是当我们深入理解基于开放编码的优化就可以明白上述限制背后的原因,除了上述几个条件之外,也有其他的条件会限制开放编码的使用,不过这些都是不太重要的细节,我们在这里也不会深究。
启用优化
Go 语言会在编译期间就确定是否启用开放编码,在编译器生成中间代码之前,我们会使用cmd/compile/internal/gc.walkstmt修改已经生成的抽象语法树,设置函数体上的OpenCodedDeferDisallowed属性:
const maxOpenDefers = 8func walkstmt(n *Node) *Node {switch n.Op {case ODEFER:Curfn.Func.SetHasDefer(true)Curfn.Func.numDefers++if Curfn.Func.numDefers > maxOpenDefers {Curfn.Func.SetOpenCodedDeferDisallowed(true)}if n.Esc != EscNever {Curfn.Func.SetOpenCodedDeferDisallowed(true)}fallthrough...}}
就像我们上面提到的,如果函数中defer关键字的数量多于 8 个或者defer关键字处于for循环中,那么我们在这里都会禁用开放编码优化,使用上两节提到的方法处理defer。
在 SSA 中间代码生成阶段的cmd/compile/internal/gc.buildssa中,我们也能够看到启用开放编码优化的其他条件,也就是返回语句的数量与defer数量的乘积需要小于 15:
中间代码生成的这两个步骤会决定当前函数是否应该使用开放编码优化defer关键字,一旦确定使用开放编码,就会在编译期间初始化延迟比特和延迟记录。
延迟记录
延迟比特和延迟记录是使用开放编码实现defer的两个最重要结构,一旦决定使用开放编码,cmd/compile/internal/gc.buildssa会在编译期间在栈上初始化大小为 8 个比特的deferBits变量:
func buildssa(fn *Node, worker int) *ssa.Func {...if s.hasOpenDefers {deferBitsTemp := tempAt(src.NoXPos, s.curfn, types.Types[TUINT8]) // 初始化延迟比特s.deferBitsTemp = deferBitsTempstartDeferBits := s.entryNewValue0(ssa.OpConst8, types.Types[TUINT8])s.vars[&deferBitsVar] = startDeferBitss.deferBitsAddr = s.addr(deferBitsTemp)s.store(types.Types[TUINT8], s.deferBitsAddr, startDeferBits)s.vars[&memVar] = s.newValue1Apos(ssa.OpVarLive, types.TypeMem, deferBitsTemp, s.mem(), false)}}
延迟比特中的每一个比特位都表示该位对应的defer关键字是否需要被执行,如下图所示,其中 8 个比特的倒数第二个比特在函数返回前被设置成了 1,那么该比特位对应的函数会在函数返回前执行:
延迟比特
因为不是函数中所有的defer语句都会在函数返回前执行,如下所示的代码只会在if语句的条件为真时,其中的defer语句才会在结尾被执行
deferBits := 0 // 初始化 deferBits_f1, _a1 := f1, a1 // 保存函数以及参数deferBits |= 1 << 0 // 将 deferBits 最后一位置位 1if condition {_f2, _a2 := f2, a2 // 保存函数以及参数deferBits |= 1 << 1 // 将 deferBits 倒数第二位置位 1}exit:if deferBits & 1 << 1 != 0 {deferBits &^= 1 << 1_f2(a2)}if deferBits & 1 << 0 != 0 {deferBits &^= 1 << 0_f1(a1)}
延迟比特的作用就是标记哪些defer关键字在函数中被执行,这样在函数返回时可以根据对应deferBits的内容确定执行的函数,而正是因为deferBits的大小仅为 8 比特,所以该优化的启用条件为函数中的defer关键字少于 8 个。
上述伪代码展示了开放编码的实现原理,但是仍然缺少了一些细节,例如:传入defer关键字的函数和参数都会存储在如下所示的cmd/compile/internal/gc.openDeferInfo结构体中:
type openDeferInfo struct {n *Nodeclosure *ssa.ValueclosureNode *Nodercvr *ssa.ValuercvrNode *NodeargVals []*ssa.ValueargNodes []*Node}
当编译器在调用cmd/compile/internal/gc.buildssa构建中间代码时会通过cmd/compile/internal/gc.state.openDeferRecord方法在栈上构建结构体,该结构体的closure中存储着调用的函数,rcvr中存储着方法的接收者,而最后的argVals中存储了函数的参数。
很多defer语句都可以在编译期间判断是否被执行,如果函数中的defer语句都会在编译期间确定,中间代码生成阶段就会直接调用cmd/compile/internal/gc.state.openDeferExit在函数返回前生成判断deferBits的代码,也就是上述伪代码中的后半部分。
不过当程序遇到运行时才能判断的条件语句时,我们仍然需要由运行时的runtime.deferreturn决定是否执行defer关键字:
该函数为开放编码做了特殊的优化,运行时会调用runtime.runOpenDeferFrame执行活跃的开放编码延迟函数,该函数会执行以下的工作:
- 从runtime._defer结构体中读取deferBits、函数defer数量等信息;
- 在循环中依次读取函数的地址和参数信息并通过deferBits判断该函数是否需要被执行;
调用runtime.reflectcallSave调用需要执行的defer函数;
func runOpenDeferFrame(gp *g, d *_defer) bool {fd := d.fd...deferBitsOffset, fd := readvarintUnsafe(fd)nDefers, fd := readvarintUnsafe(fd)deferBits := *(*uint8)(unsafe.Pointer(d.varp - uintptr(deferBitsOffset)))for i := int(nDefers) - 1; i >= 0; i-- {var argWidth, closureOffset, nArgs uint32 // 读取函数的地址和参数信息argWidth, fd = readvarintUnsafe(fd)closureOffset, fd = readvarintUnsafe(fd)nArgs, fd = readvarintUnsafe(fd)if deferBits&(1<<i) == 0 {...continue}closure := *(**funcval)(unsafe.Pointer(d.varp - uintptr(closureOffset)))d.fn = closure...deferBits = deferBits &^ (1 << i)*(*uint8)(unsafe.Pointer(d.varp - uintptr(deferBitsOffset))) = deferBitsp := d._panicreflectcallSave(p, unsafe.Pointer(closure), deferArgs, argWidth)if p != nil && p.aborted {break}d.fn = nilmemclrNoHeapPointers(deferArgs, uintptr(argWidth))...}return done}
Go 语言的编译器为了支持开放编码在中间代码生成阶段做出了很多修改,我们在这里虽然省略了很多细节,但是也可以很好地展示defer关键字的实现原理。
小结
defer关键字的实现主要依靠编译器和运行时的协作,我们总结一下本节提到的三种机制:
- 堆上分配 · 1.1 ~ 1.12
- 编译期将defer关键字转换成runtime.deferproc并在调用defer关键字的函数返回之前插入runtime.deferreturn;
- 运行时调用runtime.deferproc会将一个新的runtime._defer结构体追加到当前 Goroutine 的链表头;
- 运行时调用runtime.deferreturn会从 Goroutine 的链表中取出runtime._defer结构并依次执行;
- 栈上分配 · 1.13
- 当该关键字在函数体中最多执行一次时,编译期间的cmd/compile/internal/gc.state.call会将结构体分配到栈上并调用runtime.deferprocStack;
- 开放编码 · 1.14 ~ 现在
- 编译期间判断defer关键字、return语句的个数确定是否开启开放编码优化;
- 通过deferBits和cmd/compile/internal/gc.openDeferInfo存储defer关键字的相关信息;
- 如果defer关键字的执行可以在编译期间确定,会在函数返回前直接插入相应的代码,否则会由运行时的runtime.deferreturn处理;
转自:https://draveness.me/golang/docs/part2-foundation/ch05-keyword/golang-defer

若有收获,就点个赞吧
0 人点赞
