结构体tag快速补全
- 填写相关信息
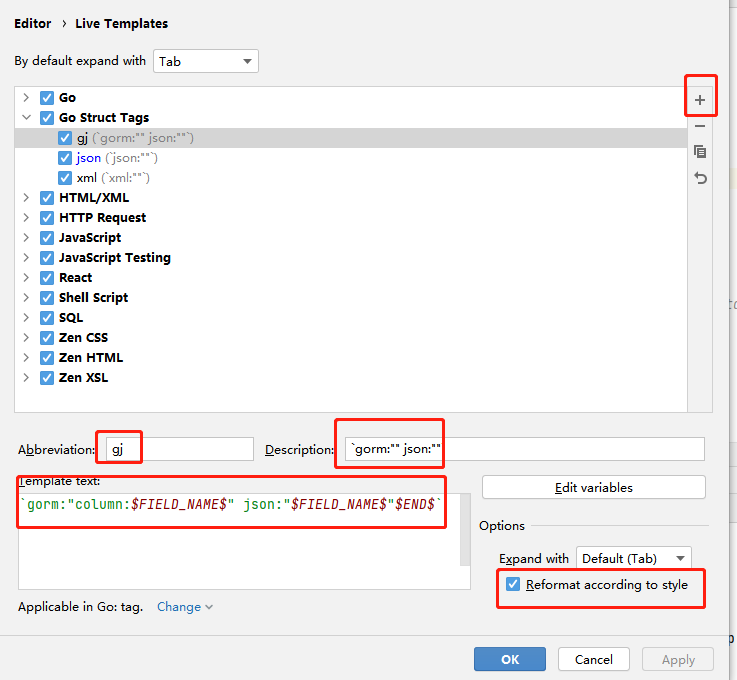
- 编辑你定义的变量
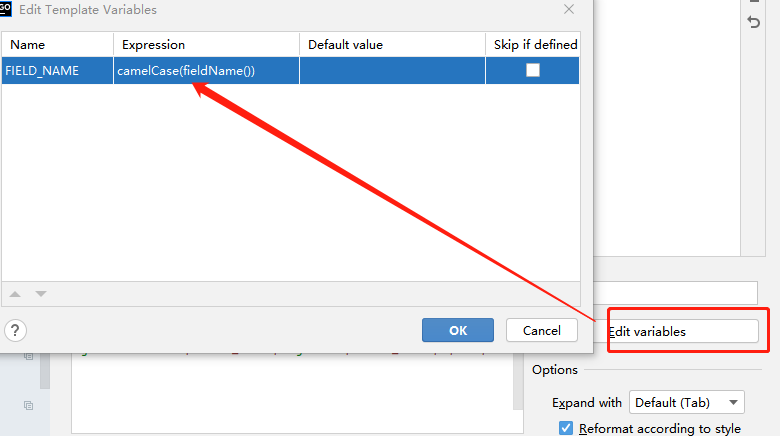
camelCase(fieldName()) 即为变量明的驼峰命名
- 最后一步
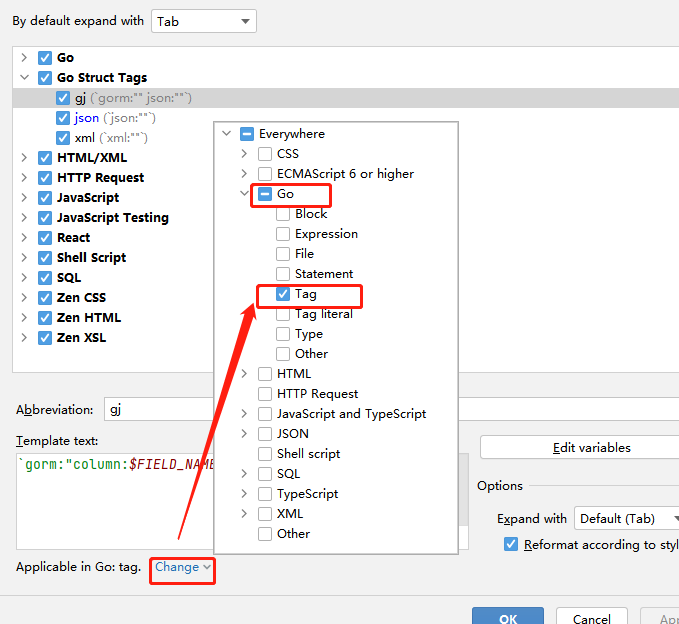
ps : json默认在Go 与 Go Struct Tags里都有,我们因删除Go里面的json
另外,json默认的是snakeCase(fieldName()) 即为变量明的蛇形命名,我们改一下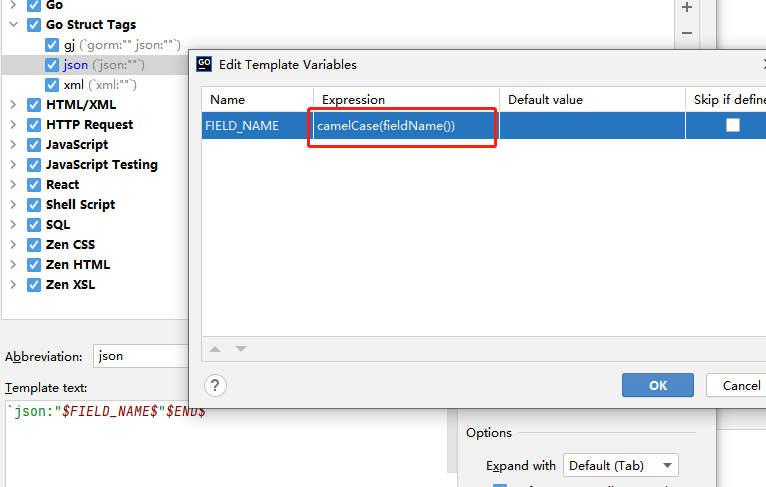
使用技巧:ALT + SHIFT + 鼠标左键添加多个光标,先给一个空格,然后输入json 按下tab键
type P struct {NameA string `json:"nameA"`NameB string `json:"nameB"`NameC string `json:"nameC"`NameD string `json:"nameD"`}
注释
设置
/*** @Author jiangwei* @MethodName: //TODO* @Description //TODO* @Param //TODO* @return //TODO* @Date $time$ $date$**/
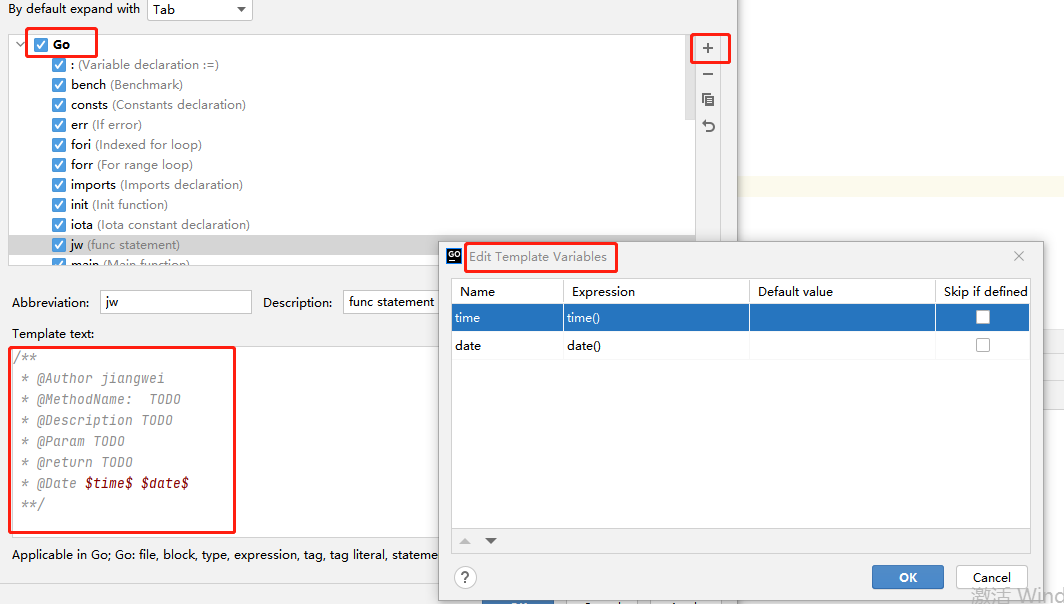
配置区域,直接全选Go
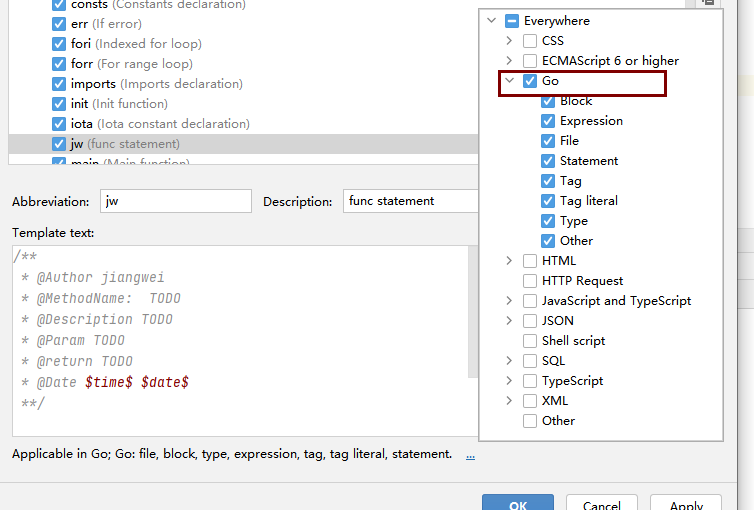
- 使用,jw + tab 或 jw + enter
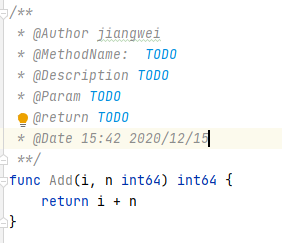
设置模板内容
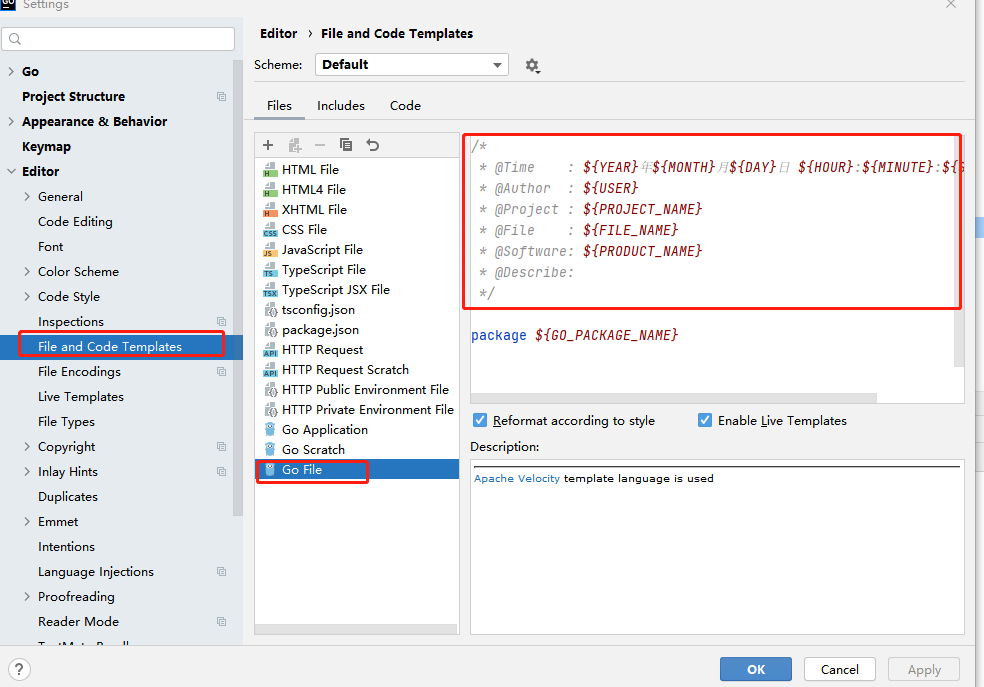
找到 Go File 添加如下内容 即可,注意最后又一个空行
/** @Time : ${YEAR}年${MONTH}月${DAY}日 ${HOUR}:${MINUTE}:${SECOND}* @Author : ${USER}* @Project : ${PROJECT_NAME}* @File : ${FILE_NAME}* @Software: ${PRODUCT_NAME}* @Describe:*/
代码测试
goland能够很方便的生成测试文件
举例:
tools.go
package testingfunc Add(n int) int {res := 0for i := 1; i <= n; i++ {res += 1}return res}
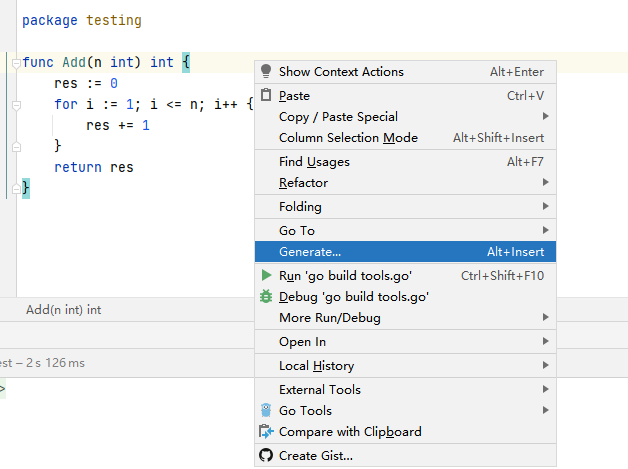
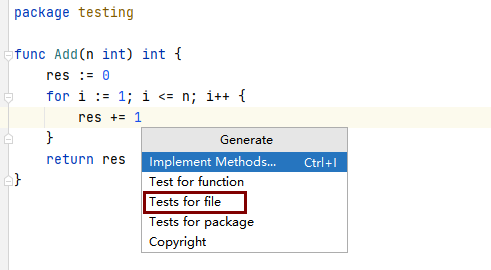
会在同目录下生成xxx_test.go文件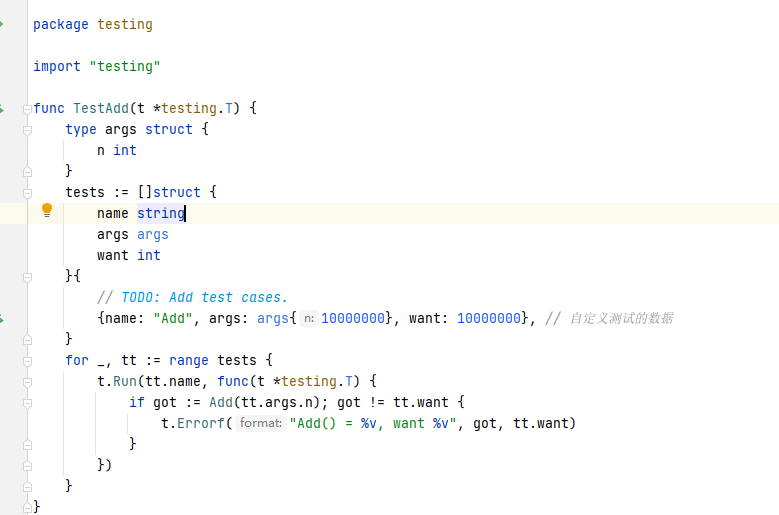
缺点是无法做基准测试,只能自己在该文件中实现了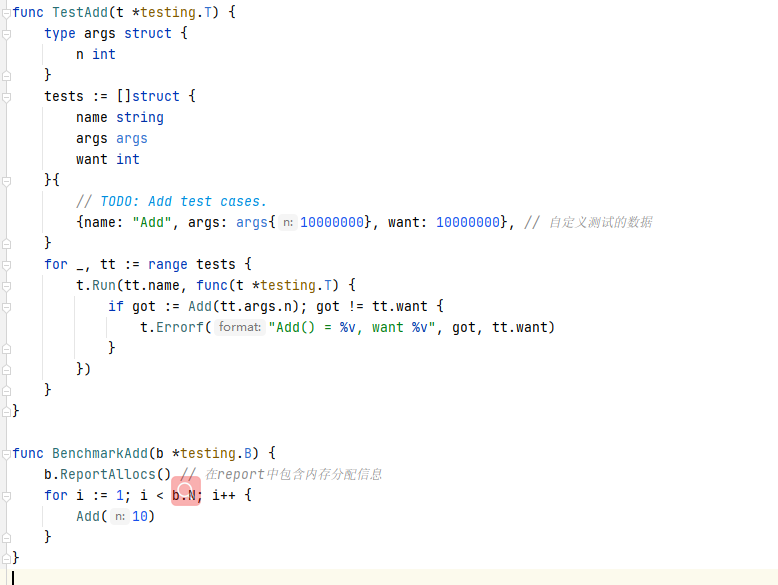
代码检查
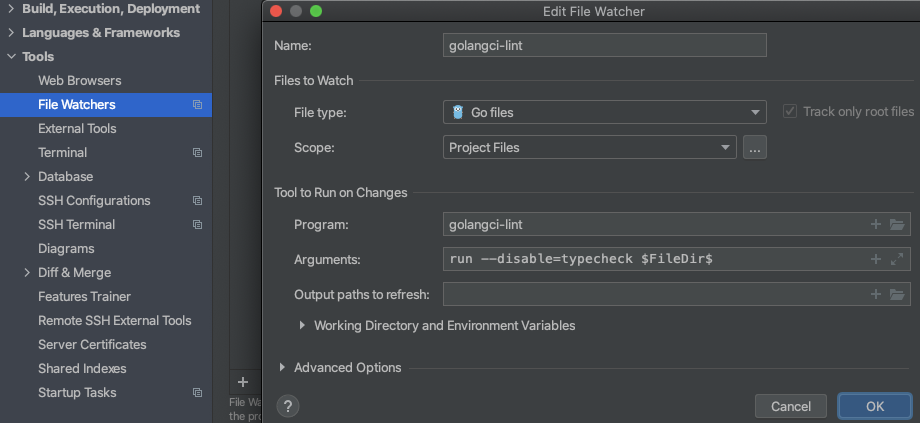
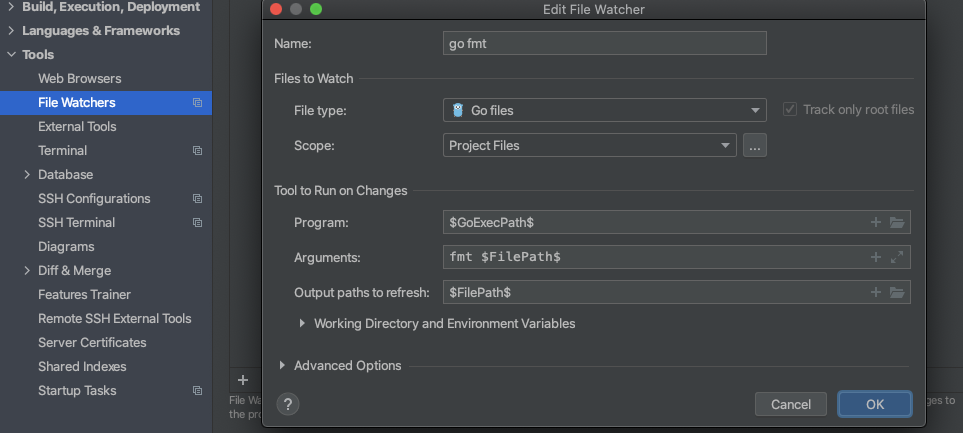
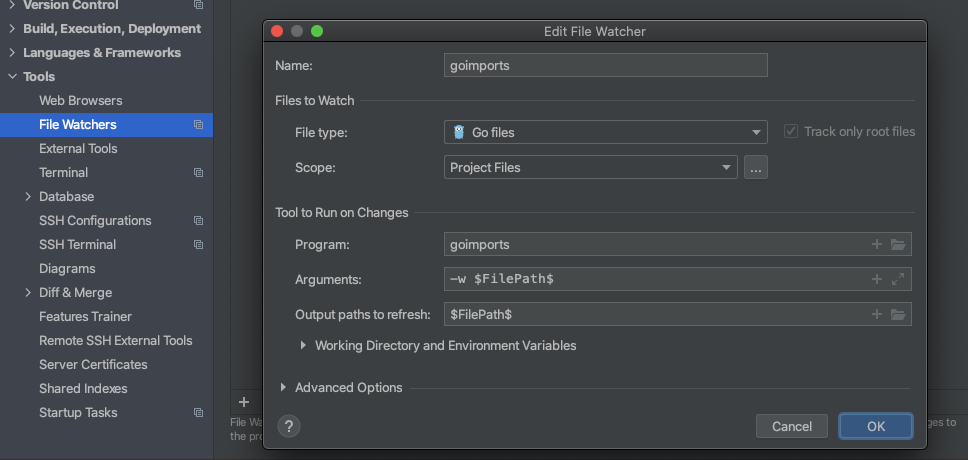
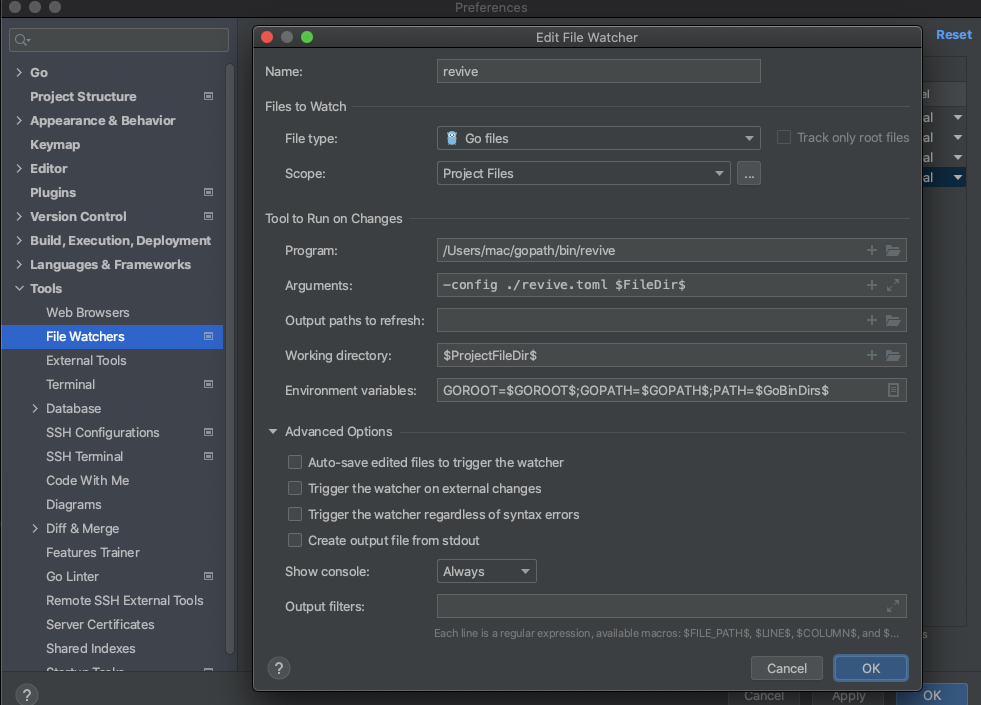
revive配置
# https://github.com/mgechev/revive/ignoreGeneratedHeader = falseseverity = "warning"confidence = 0.8errorCode = 1warningCode = 1# 入参个数限制[rule.argument-limit]arguments =[4]# 检查常见的sync/atomic包不正确用法[rule.atomic]# 裸返回[rule.bare-return]# 禁用的字符(不检查注释)[rule.banned-characters]arguments =["Ω","Σ","σ"]# 空白导入[rule.blank-imports]# 逻辑表达式中使用布尔文字 ( true, false) 可能会降低代码的可读性# 此规则建议从逻辑表达式中删除布尔文字。[rule.bool-literal-in-expr]# 显式调用垃圾收集器是非常可疑的,除了在基准测试中的特定用途。[rule.call-to-gc]# 认知复杂性[rule.cognitive-complexity]arguments =[7]# struct名称仅因大小写而异的方法或字段可能会造成混淆[rule.confusing-naming]# 返回多个相同类型的无命名值的函数或方法可能会导致错误[rule.confusing-results]# 规则会发现计算结果始终为相同值的逻辑表达式[rule.constant-logical-expr]# 按照惯例,context.Context应该是函数的第一个参数[rule.context-as-argument]# 基本类型不应用作context.WithValue[rule.context-keys-type]# 圈复杂度是代码复杂度的度量。强制每个函数的最大复杂度有助于保持代码的可读性和可维护性。[rule.cyclomatic]arguments =[3]# 这条规则警告使用defer语句时的一些常见错误# call-chain 即使foo()()形式的延迟调用链是有效的,它也无助于理解代码# loop 延迟内部循环可能会引起误解# method-call 如果方法没有指针接收器,延迟对方法的调用可能会导致微妙的错误# recover 在延迟函数外调用recover没有效果# return 从延迟函数中返回值是没有作用的[rule.defer]arguments=[["call-chain","loop"]]# 导入 with.使程序更难理解,因为不清楚名称是属于当前包还是导入包。[rule.dot-imports]# 可能会无意中两次导入同一个包。此规则查找导入两次或多次的包。[rule.duplicated-imports]# 在 GO 中,尽量减少嵌套语句是惯用的做法[rule.early-return]# 空块使代码可读性降低,并且可能是错误或未完成重构的征兆。[rule.empty-block]# 有时gofmt不足以强制执行代码库的通用格式;[rule.empty-lines]# 按照惯例,为了可读性,类型变量error必须以前缀命名err。[rule.error-naming]# 按照惯例,为了可读性,错误应该在函数返回值列表的最后。[rule.error-return]# 按照惯例,为了更好的可读性,错误消息不应大写或以标点符号或换行符结尾[rule.error-strings]# 可以通过更换得到一个简单的程序errors.New(fmt.Sprintf())用fmt.Errorf()[rule.errorf]# 导出的函数和方法应该有注释。这会警告未记录的导出函数和方法。# checkPrivateReceivers启用检查私有类型的公共方法[rule.exported]arguments =["checkPrivateReceivers","disableStutteringCheck"]# 项目中的所有源文件强制实施通用标头[rule.file-header]arguments =["This is the text that must appear at the top of source files."]# 返回过多结果的函数可能难以理解/使用。[rule.function-result-limit]arguments =[3]# 函数太长(有很多语句和/或行)可能难以理解# 检查超过 10 条语句的函数,不会检查函数的行数[rule.function-length]arguments =[10,0]# 通常,名称以Get为前缀的函数应该返回一个值。[rule.get-return]# if-then-else在两个分支中具有相同实现的条件是错误的。[rule.identical-branches]# 检查错误是否为nil到返回错误或 nil 是多余的[rule.if-return]# 发现了像i += 1,i -= 1并建议将它们改为i++、i--[rule.increment-decrement]# 为了提高代码的可读性,建议尽量减少缩进。该规则突出显示了可以从代码中消除的冗余else 块。[rule.indent-error-flow]# 导入列入黑名单的包时发出警告[imports-blacklist]arguments =["crypto/md5", "crypto/sha1"]# 当代码行超过配置的最大值时发出警告。[rule.line-length-limit]arguments =[80]# 声明过多公共结构的包可能难以理解/使用,并且可能是不良设计的征兆。[rule.max-public-structs]arguments =[3]# 修改接收器值的方法可能会出现不希望的行为。修改也可能是错误的根源,# 因为实际值接收器可能是调用站点使用的值的副本。当方法修改其接收器时,此规则会发出警告。[rule.modifies-parameter]# 声明包含其他内联结构定义的结构的包对于其他开发人员来说可能难以理解/阅读。[rule.nested-structs]# 最短路径[rule.optimize-operands-order]# 包应该有注释。此规则对未记录的包以及当包注释与package关键字分离时发出警告。[rule.package-comments]# 此规则建议使用更短的方式来编写不使用第二个值的范围[rule.range]# 循环中的范围变量在每次迭代时都被重用;因此,在循环中创建的 goroutine 将指向范围变量从上范围。# 这样,goroutine 就可以使用带有不需要的值的变量。# 当在闭包中使用范围值(或索引)时,此规则会发出警告[rule.range-val-in-closure]# 循环中的范围变量在每次迭代中都被重用。当分配变量的地址、将地址传递给 append()# 或在映射中使用它时,此规则会发出警告。[rule.range-val-address]# 按照惯例,方法中的接收者名称应该反映他们的身份。例如,如果接收器的类型为Parts,p就是它的适当名称。# 与其他语言相反,将接收者命名为this或并不习惯self。[rule.receiver-naming]# 常量名如false, true, nil,函数名如append,make和基本类型名如bool;# 因此可以重新定义。即使可能,重新定义这些内置名称也会导致很难检测到的错误。[rule.redefines-builtin-id]# 显式类型转换string(i),其中i是整数类型,可能不符合开发人员的预期(例如string(42)不是"42")[rule.string-of-int]# 在编译时不检查结构标记。# 此规则检查并警告是否在常见结构标记类型中发现错误,例如:asn1、default、json、protobuf、xml、yaml[rule.struct-tag]# 为了提高代码的可读性,建议尽量减少缩进。该规则突出显示了可以从代码中消除的冗余else 块[rule.superfluous-else]# 当时间类型使用==和!=进行相等性检查时,发出警告,建议使用time.time.Equal[rule.time-equal]# 当使用"Secs", "Mins", ... 等后缀为time.Duration进行命名时,可能产生误导[rule.time-naming]# 当不遵循变量或包命名约定时,此规则会发出警告。# 此规则接受两个字符串切片,一个白名单和一个初始值黑名单。[rule.var-naming]arguments = [["ID"], ["VM"]]# 该规则建议简化变量声明[rule.var-declaration]# 无条件递归调用会产生无限递归,从而导致程序堆栈溢出。此规则检测并警告无条件(直接)递归调用。[rule.unconditional-recursion]# 此规则警告错误命名的未导出符号,即名称以大写字母开头的未导出符号。[rule.unexported-naming]# 当导出的函数或方法返回未导出类型的值时,此规则会发出警告。[rule.unexported-return]# 当函数返回的错误未在调用方明确处理时,此规则会发出警告。[rule.unhandled-error]arguments =["fmt.Printf", "myFunction"]# 此规则建议删除breakcase 块末尾的 a等冗余语句,以提高代码的可读性。[rule.unnecessary-stmt]# 此规则发现并建议删除无法访问的代码。[rule.unreachable-code]# 此规则警告未使用的参数。带有未使用参数的函数或方法可能是未完成重构或错误的征兆。[rule.unused-parameter]# 此规则警告未使用的方法接收器。带有未使用接收器的方法可能是未完成重构或错误的征兆。[rule.unused-receiver]# sync.WaitGroup不能做值传递[rule.waitgroup-by-value]
推荐配置
ignoreGeneratedHeader = falseseverity = "warning"confidence = 0.8errorCode = 0warningCode = 0[rule.blank-imports][rule.context-as-argument][rule.context-keys-type][rule.dot-imports][rule.error-return][rule.error-strings][rule.error-naming][rule.exported][rule.if-return][rule.increment-decrement][rule.var-naming][rule.var-declaration][rule.package-comments][rule.range][rule.receiver-naming][rule.time-naming][rule.unexported-return][rule.indent-error-flow][rule.errorf][rule.empty-block][rule.superfluous-else][rule.unused-parameter][rule.unreachable-code][rule.redefines-builtin-id]
在配置文件中加了规则,也可以在代码中取消
例如:对xxx函数不做cyclomatic检测
// revive:disable:cyclomaticfunc xxx() {}
�

若有收获,就点个赞吧
0 人点赞
