导言
Go 基于 I/O multiplexing 和 goroutine scheduler 构建了一个简洁而高性能的原生网络模型(基于 Go 的 I/O 多路复用 netpoller ),提供了 goroutine-per-connection 这样简单的网络编程模式。在这种模式下,开发者使用的是同步的模式去编写异步的逻辑,极大地降低了开发者编写网络应用时的心智负担,且借助于 Go runtime scheduler 对 goroutines 的高效调度,这个原生网络模型不论从适用性还是性能上都足以满足绝大部分的应用场景。
然而,在工程性上能做到如此高的普适性和兼容性,最终暴露给开发者提供接口/模式如此简洁,其底层必然是基于非常复杂的封装,做了很多取舍,也有可能放弃了一些追求极致性能的设计和理念。事实上 Go netpoller 底层就是基于 epoll/kqueue/iocp 这些 I/O 多路复用技术来做封装的,最终暴露出 goroutine-per-connection 这样的极简的开发模式给使用者。
Go netpoller 在不同的操作系统,其底层使用的 I/O 多路复用技术也不一样,可以从 Go 源码目录结构和对应代码文件了解 Go 在不同平台下的网络 I/O 模式的实现。比如,在 Linux 系统下基于 epoll,freeBSD 系统下基于 kqueue,以及 Windows 系统下基于 iocp。
本文将基于 Linux 平台来解析 Go netpoller 之 I/O 多路复用的底层是如何基于 epoll 封装实现的,从源码层层推进,全面而深度地解析 Go netpoller 的设计理念和实现原理,以及 Go 是如何利用 netpoller 来构建它的原生网络模型的。
Go netpoller 核心
Go netpoller 基本原理
Go netpoller 通过在底层对 epoll/kqueue/iocp 的封装,从而实现了使用同步编程模式达到异步执行的效果。总结来说,所有的网络操作都以网络描述符 netFD 为中心实现。netFD 与底层 PollDesc 结构绑定,当在一个 netFD 上读写遇到 EAGAIN 错误时,就将当前 goroutine 存储到这个 netFD 对应的 PollDesc 中,同时调用 gopark 把当前 goroutine 给 park 住,直到这个 netFD 上再次发生读写事件,才将此 goroutine 给 ready 激活重新运行。显然,在底层通知 goroutine 再次发生读写等事件的方式就是 epoll/kqueue/iocp 等事件驱动机制。
总所周知,Go 是一门跨平台的编程语言,而不同平台针对特定的功能有不用的实现,这当然也包括了 I/O 多路复用技术,比如 Linux 里的 I/O 多路复用有 select、poll 和 epoll,而 freeBSD 或者 MacOS 里则是 kqueue,而 Windows 里则是基于异步 I/O 实现的 iocp,等等;因此,Go 为了实现底层 I/O 多路复用的跨平台,分别基于上述的这些不同平台的系统调用实现了多版本的 netpollers,具体的源码路径如下:
src/runtime/netpoll_epoll.gosrc/runtime/netpoll_kqueue.gosrc/runtime/netpoll_solaris.gosrc/runtime/netpoll_windows.gosrc/runtime/netpoll_aix.gosrc/runtime/netpoll_fake.go
数据结构
Listener
type Listener interface {Accept() (Conn, error)Close() errorAddr() Addr}
TCPListener
由tcp实现的Listener接口的结构体
type TCPListener struct {fd *netFDlc ListenConfig}
Conn
�Conn是一个通用的面向流的网络连接
type Conn interface {Read(b []byte) (n int, err error)Write(b []byte) (n int, err error)Close() errorLocalAddr() AddrRemoteAddr() AddrSetDeadline(t time.Time) errorSetReadDeadline(t time.Time) errorSetWriteDeadline(t time.Time) error}
TCPConn
由tcp实现的Conn接口的结构体
type TCPConn struct {conn}type conn struct {fd *netFD}
��netFD
网络描述符,类似于 Linux 的文件描述符的概念
type netFD struct {pfd poll.FD// immutable until Closefamily intsotype intisConnected bool // handshake completed or use of association with peernet stringladdr Addrraddr Addr}
FD
文件描述符
type FD struct {// Lock sysfd and serialize access to Read and Write methods.fdmu fdMutex// System file descriptor. Immutable until Close.Sysfd int// I/O poller.pd pollDesc// Writev cache.iovecs *[]syscall.Iovec// Semaphore signaled when file is closed.csema uint32// Non-zero if this file has been set to blocking mode.isBlocking uint32// Whether this is a streaming descriptor, as opposed to a// packet-based descriptor like a UDP socket. Immutable.IsStream bool// Whether a zero byte read indicates EOF. This is false for a// message based socket connection.ZeroReadIsEOF bool// Whether this is a file rather than a network socket.isFile bool}
�pollDesc
�pollDesc 是底层事件驱动的封装,netFD 通过它来完成各种 I/O 相关的操作,它的定义如下:
type pollDesc struct {runtimeCtx uintptr}
这里的 struct 只包含了一个指针,而通过 pollDesc 的 init 方法,我们可以找到它具体的定义是在 runtime.pollDesc 这里:
func (pd *pollDesc) init(fd *FD) error {serverInit.Do(runtime_pollServerInit)ctx, errno := runtime_pollOpen(uintptr(fd.Sysfd))if errno != 0 {if ctx != 0 {runtime_pollUnblock(ctx)runtime_pollClose(ctx)}return errnoErr(syscall.Errno(errno))}pd.runtimeCtx = ctxreturn nil}
这里的 struct 只包含了一个指针,而通过 pollDesc 的 init 方法,我们可以找到它具体的定义是在 runtime.pollDesc 这里:
// Network poller descriptor.//// No heap pointers.////go:notinheaptype pollDesc struct {link *pollDesc // in pollcache, protected by pollcache.lock// The lock protects pollOpen, pollSetDeadline, pollUnblock and deadlineimpl operations.// This fully covers seq, rt and wt variables. fd is constant throughout the PollDesc lifetime.// pollReset, pollWait, pollWaitCanceled and runtime·netpollready (IO readiness notification)// proceed w/o taking the lock. So closing, everr, rg, rd, wg and wd are manipulated// in a lock-free way by all operations.// NOTE(dvyukov): the following code uses uintptr to store *g (rg/wg),// that will blow up when GC starts moving objects.lock mutex // protects the following fieldsfd uintptrclosing booleverr bool // marks event scanning error happeneduser uint32 // user settable cookierseq uintptr // protects from stale read timersrg uintptr // pdReady, pdWait, G waiting for read or nilrt timer // read deadline timer (set if rt.f != nil)rd int64 // read deadlinewseq uintptr // protects from stale write timerswg uintptr // pdReady, pdWait, G waiting for write or nilwt timer // write deadline timerwd int64 // write deadlineself *pollDesc // storage for indirect interface. See (*pollDesc).makeArg.}
这里重点关注里面的 rg 和 wg,这里两个 uintptr “万能指针”类型,取值分别可能是 pdReady、pdWait、等待 file descriptor 就绪的 goroutine 也就是 g 数据结构以及 nil,它们是实现唤醒 goroutine 的关键。
runtime.pollDesc 包含自身类型的一个指针,用来保存下一个 runtime.pollDesc 的地址,以此来实现链表
runtime.pollCache
type pollCache struct {lock mutexfirst *pollDesc// PollDesc objects must be type-stable,// because we can get ready notification from epoll/kqueue// after the descriptor is closed/reused.// Stale notifications are detected using seq variable,// seq is incremented when deadlines are changed or descriptor is reused.}
因为 runtime.pollCache 是一个在 runtime 包里的全局变量,因此需要用一个互斥锁来避免 data race 问题,从它的名字也能看出这是一个用于缓存的数据结构,也就是用来提高性能的,具体如何实现呢?
func (c *pollCache) alloc() *pollDesc {lock(&c.lock)if c.first == nil {const pdSize = unsafe.Sizeof(pollDesc{})n := pollBlockSize / pdSizeif n == 0 {n = 1}// Must be in non-GC memory because can be referenced// only from epoll/kqueue internals.mem := persistentalloc(n*pdSize, 0, &memstats.other_sys)for i := uintptr(0); i < n; i++ {pd := (*pollDesc)(add(mem, i*pdSize))pd.link = c.firstc.first = pd}}pd := c.firstc.first = pd.linklockInit(&pd.lock, lockRankPollDesc)unlock(&c.lock)return pd}
Go runtime 会在调用 poll_runtime_pollOpen 往 epoll 实例注册 fd 之时首次调用 runtime.pollCache.alloc方法时批量初始化大小 4KB 的 runtime.pollDesc 结构体的链表,初始化过程中会调用 runtime.persistentalloc 来为这些数据结构分配不会被 GC 回收的内存,确保这些数据结构只能被 epoll和kqueue 在内核空间去引用。
再往后每次调用这个方法则会先判断链表头是否已经分配过值了,若是,则直接返回表头这个 pollDesc,这种批量初始化数据进行缓存而后每次都直接从缓存取数据的方式是一种很常见的性能优化手段,在这里这种方式可以有效地提升 netpoller 的吞吐量。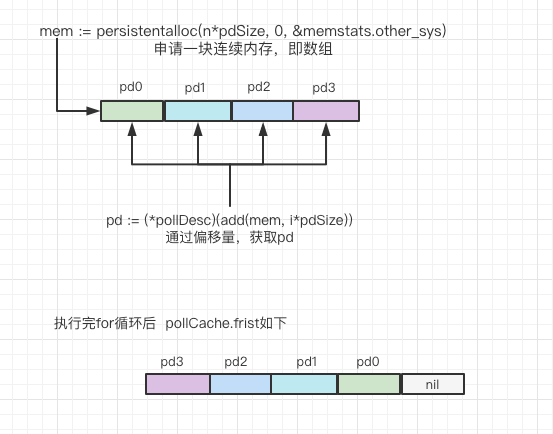
�Go runtime 会在关闭 pollDesc 之时调用 runtime.pollCache.free 释放内存:
func (c *pollCache) free(pd *pollDesc) {lock(&c.lock)pd.link = c.firstc.first = pdunlock(&c.lock)}
将要被释放的pd,加入空闲队列的头部,以供复用
实现原理
使用 Go 编写一个典型的 TCP echo server:
package mainimport ("log""net")func main() {listen, err := net.Listen("tcp", ":8888")if err != nil {log.Println("listen error: ", err)return}for {conn, err := listen.Accept()if err != nil {log.Println("accept error: ", err)break}go HandleConn(conn)}}func HandleConn(conn net.Conn) {packet := make([]byte, 1024)for {n, err := conn.Read(packet)if err != nil {log.Println("read socket error: ", err)return}_, _ = conn.Write(packet[:n])}}
net.Listen
调用 net.Listen 之后,底层会通过 Linux 的系统调用 socket 方法创建一个 fd 分配给 listener,并用以来初始化 listener 的 netFD ,接着调用 netFD 的 listenStream 方法完成对 socket 的 bind&listen 操作以及对 netFD 的初始化(主要是对 netFD 里的 pollDesc 的初始化),调用链是 runtime.runtime_pollServerInit —> runtime.poll_runtime_pollServerInit —> runtime.netpollGenericInit,主要做的事情是:
- 调用 epollcreate1 创建一个 epoll 实例 epfd,作为整个 runtime 的唯一 event-loop 使用;
- 调用 runtime.nonblockingPipe 创建一个用于和 epoll 实例通信的管道,这里为什么不用更新且更轻量的 eventfd 呢?我个人猜测是为了兼容更多以及更老的系统版本;
- 将 netpollBreakRd 通知信号量封装成 epollevent 事件结构体注册进 epoll 实例。
func (pd *pollDesc) init(fd *FD) error {// netFD.init 会调用 poll.FD.Init 并最终调用到 pollDesc.init,// 它会创建 epoll 实例并把 listener fd 加入监听队列serverInit.Do(runtime_pollServerInit)// runtime_pollOpen 内部调用了 netpollopen 来将 listener fd 注册到// epoll 实例中,另外,它会初始化一个 pollDesc 并返回ctx, errno := runtime_pollOpen(uintptr(fd.Sysfd))if errno != 0 {if ctx != 0 {runtime_pollUnblock(ctx)runtime_pollClose(ctx)}return errnoErr(syscall.Errno(errno))}// 把真正初始化完成的 pollDesc 实例赋值给当前的 pollDesc 代表自身的指针,// 后续使用直接通过该指针操作pd.runtimeCtx = ctxreturn nil}var (epfd int32 = -1 // epoll descriptor)func netpollinit() {epfd = epollcreate1(_EPOLL_CLOEXEC)if epfd < 0 {epfd = epollcreate(1024)if epfd < 0 {println("runtime: epollcreate failed with", -epfd)throw("runtime: netpollinit failed")}closeonexec(epfd)}r, w, errno := nonblockingPipe()if errno != 0 {println("runtime: pipe failed with", -errno)throw("runtime: pipe failed")}ev := epollevent{events: _EPOLLIN,}*(**uintptr)(unsafe.Pointer(&ev.data)) = &netpollBreakRderrno = epollctl(epfd, _EPOLL_CTL_ADD, r, &ev)if errno != 0 {println("runtime: epollctl failed with", -errno)throw("runtime: epollctl failed")}netpollBreakRd = uintptr(r)netpollBreakWr = uintptr(w)}
我们前面提到的 epoll 的三个基本调用,Go 在源码里实现了对那三个调用的封装:
#include <sys/epoll.h>int epoll_create(int size);int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);// Go 对上面三个调用的封装func netpollinit()func netpollopen(fd uintptr, pd *pollDesc) int32func netpoll(block bool) gList
netFD 就是通过这三个封装来对 epoll 进行创建实例、注册 fd 和等待事件操作的。
Listener.Accept()
netpoll accept socket 的工作流程如下:
- 服务端的 netFD 在 listen 时会创建 epoll 的实例,并将 listenerFD 加入 epoll 的事件队列
- netFD 在 accept 时将返回的 connFD 也加入 epoll 的事件队列
- netFD 在读写时出现 syscall.EAGAIN 错误,通过 pollDesc 的 waitRead 方法将当前的 goroutine park 住,直到 ready,从 pollDesc 的 waitRead 中返回
```go
func (l *TCPListener) Accept() (Conn, error) {
if !l.ok() {
} c, err := l.accept() if err != nil {return nil, syscall.EINVAL
} return c, nil }return nil, &OpError{Op: "accept", Net: l.fd.net, Source: nil, Addr: l.fd.laddr, Err: err}
func (ln TCPListener) accept() (TCPConn, error) { fd, err := ln.fd.accept() if err != nil { return nil, err } tc := newTCPConn(fd) if ln.lc.KeepAlive >= 0 { setKeepAlive(fd, true) ka := ln.lc.KeepAlive if ln.lc.KeepAlive == 0 { ka = defaultTCPKeepAlive } setKeepAlivePeriod(fd, ka) } return tc, nil }
func (fd netFD) accept() (netfd netFD, err error) { // 调用 poll.FD 的 Accept 方法接受新的 socket 连接,返回 socket 的 fd d, rsa, errcall, err := fd.pfd.Accept() if err != nil { if errcall != “” { err = wrapSyscallError(errcall, err) } return nil, err }
// 以 socket fd 构造一个新的 netFD,代表这个新的 socket
if netfd, err = newFD(d, fd.family, fd.sotype, fd.net); err != nil {
poll.CloseFunc(d)
return nil, err
}
// 调用 netFD 的 init 方法完成初始化(此时就是往epoll中添加socket)
if err = netfd.init(); err != nil {
netfd.Close()
return nil, err
}
lsa, _ := syscall.Getsockname(netfd.pfd.Sysfd)
netfd.setAddr(netfd.addrFunc()(lsa), netfd.addrFunc()(rsa))
return netfd, nil
}
netFD.accept 方法里会再调用 poll.FD.Accept ,最后会使用 Linux 的系统调用 accept 来完成新连接的接收,并且会把 accept 的 socket 设置成非阻塞 I/O 模式:
```go
func (fd *FD) Accept() (int, syscall.Sockaddr, string, error) {
if err := fd.readLock(); err != nil {
return -1, nil, "", err
}
defer fd.readUnlock()
if err := fd.pd.prepareRead(fd.isFile); err != nil {
return -1, nil, "", err
}
for {
s, rsa, errcall, err := accept(fd.Sysfd)
if err == nil {
return s, rsa, "", err
}
switch err {
case syscall.EINTR:
continue
case syscall.EAGAIN:
if fd.pd.pollable() {
// 这里会hang住Accept,直到有新连接过来,被netpoll复活
// 与连接过来的fd可读可写流程类似
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
case syscall.ECONNABORTED:
// This means that a socket on the listen
// queue was closed before we Accept()ed it;
// it's a silly error, so try again.
continue
}
return -1, nil, errcall, err
}
}
pollDesc.waitRead 方法主要负责检测当前这个 pollDesc 的上层 netFD 对应的 fd 是否有『期待的』I/O 事件发生,如果有就直接返回,否则就 park 住当前的 goroutine 并持续等待直至对应的 fd 上发生可读/可写或者其他『期待的』I/O 事件为止,然后它就会返回到外层的 for 循环,让 goroutine 继续执行逻辑。
poll.FD.Accept() 返回之后,会构造一个对应这个新 socket 的 netFD,然后调用 init() 方法完成初始化,这个 init 过程和前面 net.Listen() 是一样的,调用链:netFD.init() —> poll.FD.Init() —> poll.pollDesc.init()
然后把这个 socket fd 注册到 listener 的 epoll 实例的事件队列中去,等待 I/O 事件。
Conn.Read
我们先来看看 Conn.Read 方法是如何实现的,原理其实和 Listener.Accept 是一样的,具体调用链还是首先调用 conn 的 netFD.Read ,然后内部再调用 poll.FD.Read ,最后使用 Linux 的系统调用 read: syscall.Read 完成数据读取:
func (c *conn) Read(b []byte) (int, error) {
if !c.ok() {
return 0, syscall.EINVAL
}
n, err := c.fd.Read(b)
if err != nil && err != io.EOF {
err = &OpError{Op: "read", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
}
return n, err
}
func (fd *netFD) Read(p []byte) (n int, err error) {
n, err = fd.pfd.Read(p)
runtime.KeepAlive(fd)
return n, wrapSyscallError(readSyscallName, err)
}
func (fd *FD) Read(p []byte) (int, error) {
if err := fd.readLock(); err != nil {
return 0, err
}
defer fd.readUnlock()
if len(p) == 0 {
// If the caller wanted a zero byte read, return immediately
// without trying (but after acquiring the readLock).
// Otherwise syscall.Read returns 0, nil which looks like
// io.EOF.
// TODO(bradfitz): make it wait for readability? (Issue 15735)
return 0, nil
}
if err := fd.pd.prepareRead(fd.isFile); err != nil {
return 0, err
}
if fd.IsStream && len(p) > maxRW {
p = p[:maxRW]
}
for {
n, err := ignoringEINTRIO(syscall.Read, fd.Sysfd, p)
if err != nil {
n = 0
if err == syscall.EAGAIN && fd.pd.pollable() {
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
}
}
err = fd.eofError(n, err)
return n, err
}
}
Conn.Write
与read的流程一直
func (c *conn) Write(b []byte) (int, error) {
if !c.ok() {
return 0, syscall.EINVAL
}
n, err := c.fd.Write(b)
if err != nil {
err = &OpError{Op: "write", Net: c.fd.net, Source: c.fd.laddr, Addr: c.fd.raddr, Err: err}
}
return n, err
}
func (fd *netFD) Write(p []byte) (nn int, err error) {
nn, err = fd.pfd.Write(p)
runtime.KeepAlive(fd)
return nn, wrapSyscallError(writeSyscallName, err)
}
func (fd *FD) Write(p []byte) (int, error) {
if err := fd.writeLock(); err != nil {
return 0, err
}
defer fd.writeUnlock()
if err := fd.pd.prepareWrite(fd.isFile); err != nil {
return 0, err
}
var nn int
for {
max := len(p)
if fd.IsStream && max-nn > maxRW {
max = nn + maxRW
}
n, err := ignoringEINTRIO(syscall.Write, fd.Sysfd, p[nn:max])
if n > 0 {
nn += n
}
if nn == len(p) {
return nn, err
}
if err == syscall.EAGAIN && fd.pd.pollable() {
if err = fd.pd.waitWrite(fd.isFile); err == nil {
continue
}
}
if err != nil {
return nn, err
}
if n == 0 {
return nn, io.ErrUnexpectedEOF
}
}
}
pollDesc.waitRead/pollDesc.waitWrite
pollDesc.waitRead 内部调用了 poll.runtime_pollWait —> runtime.poll_runtime_pollWait 来达成无 I/O 事件时 park 住 goroutine 的目的:
// poll_runtime_pollWait, which is internal/poll.runtime_pollWait,
// waits for a descriptor to be ready for reading or writing,
// according to mode, which is 'r' or 'w'.
// This returns an error code; the codes are defined above.
//go:linkname poll_runtime_pollWait internal/poll.runtime_pollWait
func poll_runtime_pollWait(pd *pollDesc, mode int) int {
errcode := netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
// As for now only Solaris, illumos, and AIX use level-triggered IO.
if GOOS == "solaris" || GOOS == "illumos" || GOOS == "aix" {
netpollarm(pd, mode)
}
// 进入 netpollblock 并且判断是否有期待的 I/O 事件发生,
// 这里的 for 循环是为了一直等到 io ready
for !netpollblock(pd, int32(mode), false) {
errcode = netpollcheckerr(pd, int32(mode))
if errcode != pollNoError {
return errcode
}
// Can happen if timeout has fired and unblocked us,
// but before we had a chance to run, timeout has been reset.
// Pretend it has not happened and retry.
}
return pollNoError
}
// returns true if IO is ready, or false if timedout or closed
// waitio - wait only for completed IO, ignore errors
func netpollblock(pd *pollDesc, mode int32, waitio bool) bool {
// gpp 保存的是 goroutine 的数据结构 g,这里会根据 mode 的值决定是 rg 还是 wg,
// 前面提到过,rg 和 wg 是用来保存等待 I/O 就绪的 gorouine 的,后面调用 gopark 之后,
// 会把当前的 goroutine 的抽象数据结构 g 存入 gpp 这个指针,也就是 rg 或者 wg
gpp := &pd.rg
if mode == 'w' {
gpp = &pd.wg
}
// set the gpp semaphore to pdWait
// 这个 for 循环是为了等待 io ready 或者 io wait
for {
old := *gpp
// gpp == pdReady 表示此时已有期待的 I/O 事件发生,
// 可以直接返回 unblock 当前 goroutine 并执行响应的 I/O 操作
if old == pdReady {
*gpp = 0
return true
}
if old != 0 {
throw("runtime: double wait")
}
// 如果没有期待的 I/O 事件发生,则通过原子操作把 gpp 的值置为 pdWait 并退出 for 循环
if atomic.Casuintptr(gpp, 0, pdWait) {
break
}
}
// waitio 此时是 false,netpollcheckerr 方法会检查当前 pollDesc 对应的 fd 是否是正常的,
// 通常来说 netpollcheckerr(pd, mode) == 0 是成立的,所以这里会执行 gopark
// 把当前 goroutine 给 park 住,直至对应的 fd 上发生可读/可写或者其他『期待的』I/O 事件为止,
// 然后 unpark 返回,在 gopark 内部会把当前 goroutine 的抽象数据结构 g 存入
// gpp(pollDesc.rg/pollDesc.wg) 指针里,以便在后面的 netpoll 函数取出 pollDesc 之后,
// 把 g 添加到链表里返回,接着重新调度 goroutine
if waitio || netpollcheckerr(pd, mode) == 0 {
// 注册 netpollblockcommit 回调给 gopark,在 gopark 内部会执行它,保存当前 goroutine 到 gpp
gopark(netpollblockcommit, unsafe.Pointer(gpp), waitReasonIOWait, traceEvGoBlockNet, 5)
}
// be careful to not lose concurrent pdReady notification
old := atomic.Xchguintptr(gpp, 0)
if old > pdWait {
throw("runtime: corrupted polldesc")
}
return old == pdReady
}
// gopark 会停住当前的 goroutine 并且调用传递进来的回调函数 unlockf
// 从上面的源码我们可以知道这个函数是 netpollblockcommit
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem() // 获取当前goroutine的m结构
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp) // 释放m.locks--
// can't do anything that might move the G between Ms here.
// gopark 最终会调用 park_m,在这个函数内部会调用 unlockf,也就是 netpollblockcommit,
// 然后会把当前的 goroutine,也就是 g 数据结构保存到 pollDesc 的 rg 或者 wg 指针里
mcall(park_m) // 从g切到g0,然后执行调度
}
// park continuation on g0.
func park_m(gp *g) {
_g_ := getg() // 获取线程正在执行的goroutine
if trace.enabled {
traceGoPark(_g_.m.waittraceev, _g_.m.waittraceskip)
}
casgstatus(gp, _Grunning, _Gwaiting)
dropg()
if fn := _g_.m.waitunlockf; fn != nil {
// 调用 netpollblockcommit,把当前的 goroutine,
// 也就是 g 数据结构保存到 pollDesc 的 rg 或者 wg 指针里
ok := fn(gp, _g_.m.waitlock)
_g_.m.waitunlockf = nil
_g_.m.waitlock = nil
if !ok {
if trace.enabled {
traceGoUnpark(gp, 2)
}
casgstatus(gp, _Gwaiting, _Grunnable)
execute(gp, true) // Schedule it back, never returns.
}
}
schedule()
}
// 在 gopark 函数里被调用
func netpollblockcommit(gp *g, gpp unsafe.Pointer) bool {
// 通过原子操作把当前 goroutine 抽象的数据结构 g,也就是这里的参数 gp 存入 gpp 指针,
// 此时 gpp 的值是 pollDesc 的 rg 或者 wg 指针
r := atomic.Casuintptr((*uintptr)(gpp), pdWait, uintptr(unsafe.Pointer(gp)))
if r {
// Bump the count of goroutines waiting for the poller.
// The scheduler uses this to decide whether to block
// waiting for the poller if there is nothing else to do.
atomic.Xadd(&netpollWaiters, 1)
}
return r
}
pollDesc.waitWrite 的内部实现原理和 pollDesc.waitRead 是一样的,都是基于 poll.runtime_pollWait —> runtime.poll_runtime_pollWait,这里就不再赘述。
netpoll
前面已经从源码的层面分析完了 netpoll 是如何通过 park goroutine 从而达到阻塞 Accept/Read/Write 的效果,而通过调用 gopark,goroutine 会被放置在某个等待队列中,这里是放到了 epoll 的 “interest list” 里,底层数据结构是由红黑树实现的 eventpoll.rbr,此时 G 的状态由 _Grunning为_Gwaitting ,因此 G 必须被手动唤醒(通过 goready ),否则会丢失任务,应用层阻塞通常使用这种方式。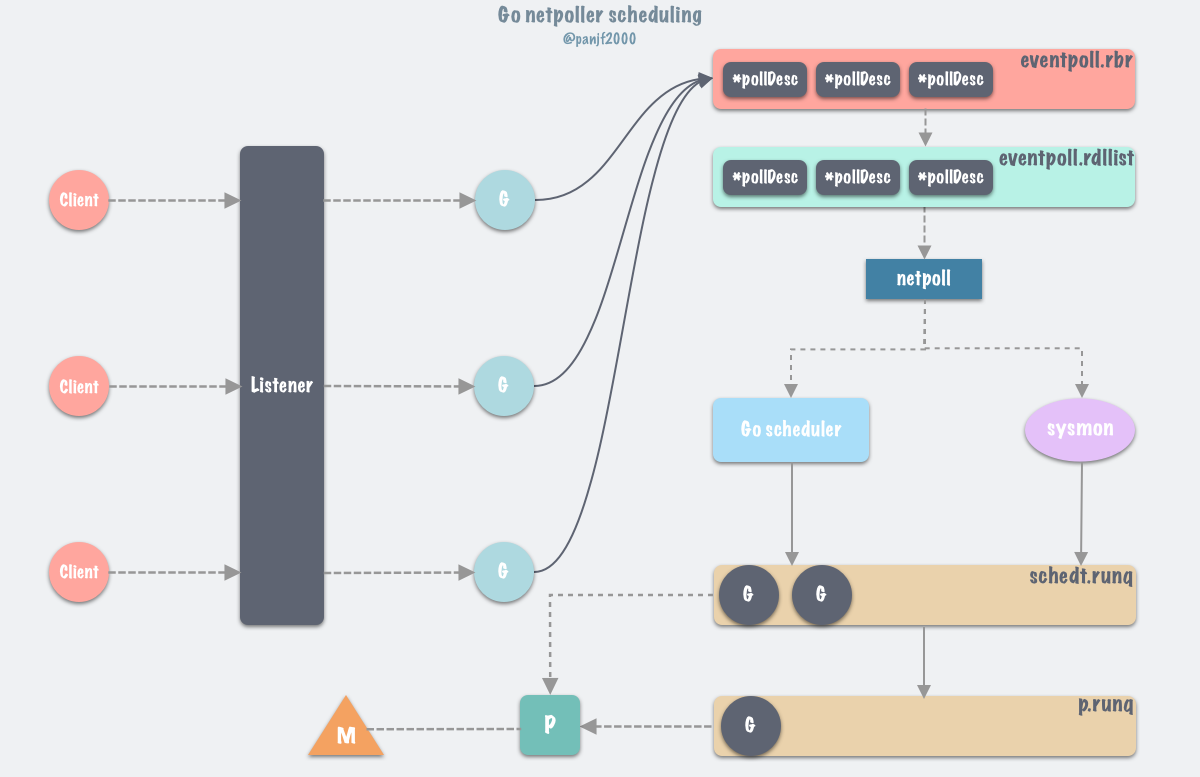
首先,client 连接 server 的时候,listener 通过 accept 调用接收新 connection,每一个新 connection 都启动一个 goroutine 处理,accept 调用会把该 connection 的 fd 连带所在的 goroutine 上下文信息封装注册到 epoll 的监听列表里去,当 goroutine 调用 conn.Read 或者 conn.Write 等需要阻塞等待的函数时,会被 gopark 给封存起来并使之休眠,让 P 去执行本地调度队列里的下一个可执行的 goroutine,往后 Go scheduler 会在循环调度的 runtime.schedule() 函数以及 sysmon 监控线程中调用 runtime.netpoll 以获取可运行的 goroutine 列表并通过调用 injectglist 把剩下的 g 放入全局调度队列或者当前 P 本地调度队列去重新执行。
那么当 I/O 事件发生之后,netpoller 是通过什么方式唤醒那些在 I/O wait 的 goroutine 的?答案是通过 runtime.netpoll。
runtime.netpoll 的核心逻辑是:
- 根据调用方的入参 delay,设置对应的调用 epollwait 的 timeout 值;
- 调用 epollwait 等待发生了可读/可写事件的 fd;
循环 epollwait 返回的事件列表,处理对应的事件类型, 组装可运行的 goroutine 链表并返回。 ```go // netpoll checks for ready network connections. // Returns list of goroutines that become runnable. // delay < 0: blocks indefinitely // delay == 0: does not block, just polls // delay > 0: block for up to that many nanoseconds func netpoll(delay int64) gList { if epfd == -1 {
return gList{}} var waitms int32 if delay < 0 {
waitms = -1} else if delay == 0 {
waitms = 0} else if delay < 1e6 {
waitms = 1} else if delay < 1e15 {
waitms = int32(delay / 1e6)} else {
// An arbitrary cap on how long to wait for a timer. // 1e9 ms == ~11.5 days. waitms = 1e9} var events [128]epollevent // 一次最多拿128个就绪事件 retry: // 就绪的 fd 读写事件 n := epollwait(epfd, &events[0], int32(len(events)), waitms) if n < 0 {
if n != -_EINTR { println("runtime: epollwait on fd", epfd, "failed with", -n) throw("runtime: netpoll failed") } // If a timed sleep was interrupted, just return to // recalculate how long we should sleep now. if waitms > 0 { return gList{} } goto retry}
// toRun 是一个 g 的链表,存储要恢复的 goroutines,最后返回给调用方 var toRun gList for i := int32(0); i < n; i++ {
ev := &events[i] if ev.events == 0 { continue } // Go scheduler 在调用 findrunnable() 寻找 goroutine 去执行的时候, // 在调用 netpoll 之时会检查当前是否有其他线程同步阻塞在 netpoll, // 若是,则调用 netpollBreak 来唤醒那个线程,避免它长时间阻塞 if *(**uintptr)(unsafe.Pointer(&ev.data)) == &netpollBreakRd { if ev.events != _EPOLLIN { println("runtime: netpoll: break fd ready for", ev.events) throw("runtime: netpoll: break fd ready for something unexpected") } if delay != 0 { // netpollBreak could be picked up by a // nonblocking poll. Only read the byte // if blocking. var tmp [16]byte read(int32(netpollBreakRd), noescape(unsafe.Pointer(&tmp[0])), int32(len(tmp))) atomic.Store(&netpollWakeSig, 0) } continue } // 判断发生的事件类型,读类型或者写类型等,然后给 mode 复制相应的值, // mode 用来决定从 pollDesc 里的 rg 还是 wg 里取出 goroutine var mode int32 if ev.events&(_EPOLLIN|_EPOLLRDHUP|_EPOLLHUP|_EPOLLERR) != 0 { mode += 'r' } if ev.events&(_EPOLLOUT|_EPOLLHUP|_EPOLLERR) != 0 { mode += 'w' } if mode != 0 { // 取出保存在 epollevent 里的 pollDesc pd := *(**pollDesc)(unsafe.Pointer(&ev.data)) pd.everr = false if ev.events == _EPOLLERR { pd.everr = true } netpollready(&toRun, pd, mode) }} return toRun }
// netpollready 调用 netpollunblock 返回就绪 fd 对应的 goroutine 的抽象数据结构 g func netpollready(toRun gList, pd pollDesc, mode int32) { var rg, wg *g if mode == ‘r’ || mode == ‘r’+’w’ { rg = netpollunblock(pd, ‘r’, true) } if mode == ‘w’ || mode == ‘r’+’w’ { wg = netpollunblock(pd, ‘w’, true) } if rg != nil { toRun.push(rg) } if wg != nil { toRun.push(wg) } }
// netpollunblock 会依据传入的 mode 决定从 pollDesc 的 rg 或者 wg 取出当时 gopark 之时存入的 // goroutine 抽象数据结构 g 并返回 func netpollunblock(pd pollDesc, mode int32, ioready bool) g { gpp := &pd.rg if mode == ‘w’ { gpp = &pd.wg }
for {
// 这个old非常关键,它就是在gopack时给rg或wg的goroutine指针
old := *gpp
if old == pdReady {
return nil
}
if old == 0 && !ioready {
// Only set pdReady for ioready. runtime_pollWait
// will check for timeout/cancel before waiting.
return nil
}
var new uintptr
if ioready {
new = pdReady
}
if atomic.Casuintptr(gpp, old, new) {
if old == pdWait {
old = 0
}
// 通过万能指针还原成 g 并返回
return (*g)(unsafe.Pointer(old))
}
}
}
Go 在多种场景下都可能会调用 netpoll 检查文件描述符状态,netpoll 里会调用 epoll_wait 从 epoll 的 eventpoll.rdllist 就绪双向链表返回,从而得到 I/O 就绪的 socket fd 列表,并根据取出最初调用 epoll_ctl 时保存的上下文信息,恢复 g。所以执行完netpoll 之后,会返回一个就绪 fd 列表对应的 goroutine 链表,接下来将就绪的 goroutine 通过调用 injectglist 加入到全局调度队列或者 P 的本地调度队列中,启动 M 绑定 P 去执行。
具体调用 netpoll 的地方,首先在 Go runtime scheduler 循环调度 goroutines 之时就有可能会调用 netpoll 获取到已就绪的 fd 对应的 goroutine 来调度执行。
首先 Go scheduler 的核心方法 runtime.schedule() 里会调用一个叫 runtime.findrunable() 的方法获取可运行的 goroutine 来执行,而在 runtime.findrunable() 方法里就调用了 runtime.netpoll 获取已就绪的 fd 列表对应的 goroutine 列表:
```go
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
...
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
...
}
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
func findrunnable() (gp *g, inheritTime bool) {
...
// poll network
if netpollinited() && (atomic.Load(&netpollWaiters) > 0 || pollUntil != 0) && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
atomic.Store64(&sched.pollUntil, uint64(pollUntil))
if _g_.m.p != 0 {
throw("findrunnable: netpoll with p")
}
if _g_.m.spinning {
throw("findrunnable: netpoll with spinning")
}
if faketime != 0 {
// When using fake time, just poll.
delta = 0
}
list := netpoll(delta) // 同步阻塞调用 netpoll,直至有可用的 goroutine
atomic.Store64(&sched.pollUntil, 0)
atomic.Store64(&sched.lastpoll, uint64(nanotime()))
if faketime != 0 && list.empty() {
// Using fake time and nothing is ready; stop M.
// When all M's stop, checkdead will call timejump.
stopm()
goto top
}
lock(&sched.lock)
_p_ = pidleget() // 查找是否有空闲的 P 可以来就绪的 goroutine
unlock(&sched.lock)
if _p_ == nil {
injectglist(&list) // 如果当前没有空闲的 P,则把就绪的 goroutine 放入全局调度队列等待被执行
} else {
// 如果当前有空闲的 P,则 pop 出一个 g,返回给调度器去执行,
// 并通过调用 injectglist 把剩下的 g 放入全局调度队列或者当前 P 本地调度队列
acquirep(_p_)
if !list.empty() {
gp := list.pop()
injectglist(&list)
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
} else if pollUntil != 0 && netpollinited() {
pollerPollUntil := int64(atomic.Load64(&sched.pollUntil))
if pollerPollUntil == 0 || pollerPollUntil > pollUntil {
netpollBreak()
}
}
stopm()
goto top
}
另外, sysmon 监控线程会在循环过程中检查距离上一次 runtime.netpoll 被调用是否超过了 10ms,若是则会去调用它拿到可运行的 goroutine 列表并通过调用 injectglist 把 g 列表放入全局调度队列或者当前 P 本地调度队列等待被执行:
func sysmon() {
...
// poll network if not polled for more than 10ms
lastpoll := int64(atomic.Load64(&sched.lastpoll))
if netpollinited() && lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
list := netpoll(0) // non-blocking - returns list of goroutines
if !list.empty() {
// Need to decrement number of idle locked M's
// (pretending that one more is running) before injectglist.
// Otherwise it can lead to the following situation:
// injectglist grabs all P's but before it starts M's to run the P's,
// another M returns from syscall, finishes running its G,
// observes that there is no work to do and no other running M's
// and reports deadlock.
incidlelocked(-1)
injectglist(&list)
incidlelocked(1)
}
}
...
}
Go runtime 在程序启动的时候会创建一个独立的 M 作为监控线程,叫 sysmon ,这个线程为系统级的 daemon 线程,无需 P 即可运行, sysmon 每 20us~10ms 运行一次。 sysmon 中以轮询的方式执行以下操作(如上面的代码所示):
- 以非阻塞的方式调用 runtime.netpoll ,从中找出能从网络 I/O 中唤醒的 g 列表,并通过调用 injectglist 把 g 列表放入全局调度队列或者当前 P 本地调度队列等待被执行,调度触发时,有可能从这个全局 runnable 调度队列获取 g。然后再循环调用 startm ,直到所有 P 都不处于 _Pidle 状态。
- 调用 retake ,抢占长时间处于 _Psyscall 状态的 P。
综上,Go 借助于 epoll/kqueue/iocp 和 runtime scheduler 等的帮助,设计出了自己的 I/O 多路复用 netpoller,成功地让 Listener.Accept / conn.Read / conn.Write 等方法从开发者的角度看来是同步模式。
转自:https://strikefreedom.top/go-netpoll-io-multiplexing-reactor

若有收获,就点个赞吧
0 人点赞
