上一节我们通过分析main goroutine的创建详细讨论了goroutine的创建及初始化流程,这一节我们接着来分析调度器如何把main goroutine调度到CPU上去运行。本节需要重点关注的问题有:
- 如何保存g0的调度信息?
- schedule函数有什么重要作用?
- gogo函数如何完成从g0到main goroutine的切换?
接着前一节继续分析代码,从newproc返回到rt0go,继续往下执行mstart。
_runtime/proc.go : 1153
func mstart() {_g_ := getg() //_g_ = g0//对于启动过程来说,g0的stack.lo早已完成初始化,所以onStack = falseosStack := _g_.stack.lo == 0if osStack {// Initialize stack bounds from system stack.// Cgo may have left stack size in stack.hi.// minit may update the stack bounds.size := _g_.stack.hiif size == 0 {size = 8192 * sys.StackGuardMultiplier}_g_.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))_g_.stack.lo = _g_.stack.hi - size + 1024}// Initialize stack guards so that we can start calling// both Go and C functions with stack growth prologues._g_.stackguard0 = _g_.stack.lo + _StackGuard_g_.stackguard1 = _g_.stackguard0mstart1()// Exit this thread.if GOOS == "windows" || GOOS == "solaris" || GOOS == "plan9" || GOOS == "darwin" || GOOS == "aix" {// Window, Solaris, Darwin, AIX and Plan 9 always system-allocate// the stack, but put it in _g_.stack before mstart,// so the logic above hasn't set osStack yet.osStack = true}mexit(osStack)}
mstart函数本身没啥说的,它继续调用mstart1函数。
runtime/proc.go : 1184
func mstart1() {_g_ := getg() //启动过程时 _g_ = m0的g0if _g_ != _g_.m.g0 {throw("bad runtime·mstart")}// Record the caller for use as the top of stack in mcall and// for terminating the thread.// We're never coming back to mstart1 after we call schedule,// so other calls can reuse the current frame.//getcallerpc()获取mstart1执行完的返回地址//getcallersp()获取调用mstart1时的栈顶地址save(getcallerpc(), getcallersp())asminit() //在AMD64 Linux平台中,这个函数什么也没做,是个空函数minit() //与信号相关的初始化,目前不需要关心// Install signal handlers; after minit so that minit can// prepare the thread to be able to handle the signals.if _g_.m == &m0 { //启动时_g_.m是m0,所以会执行下面的mstartm0函数mstartm0() //也是信号相关的初始化,现在我们不关注}if fn := _g_.m.mstartfn; fn != nil { //初始化过程中fn == nilfn()}if _g_.m != &m0 {// m0已经绑定了allp[0],不是m0的话还没有p,所以需要获取一个pacquirep(_g_.m.nextp.ptr())_g_.m.nextp = 0}//schedule函数永远不会返回schedule()}
mstart1首先调用save函数来保存g0的调度信息,save这一行代码非常重要,是我们理解调度循环的关键点之一。这里首先需要注意的是代码中的getcallerpc()返回的是mstart调用mstart1时被call指令压栈的返回地址,getcallersp()函数返回的是调用mstart1函数之前mstart函数的栈顶地址,其次需要看看save函数到底做了哪些重要工作。
runtime/proc.go : 2733
// save updates getg().sched to refer to pc and sp so that a following// gogo will restore pc and sp.//// save must not have write barriers because invoking a write barrier// can clobber getg().sched.////go:nosplit//go:nowritebarrierrecfunc save(pc, sp uintptr) {_g_ := getg()_g_.sched.pc = pc //再次运行时的指令地址_g_.sched.sp = sp //再次运行时到栈顶_g_.sched.lr = 0_g_.sched.ret = 0_g_.sched.g = guintptr(unsafe.Pointer(_g_))// We need to ensure ctxt is zero, but can't have a write// barrier here. However, it should always already be zero.// Assert that.if _g_.sched.ctxt != nil {badctxt()}}
可以看到,save函数保存了调度相关的所有信息,包括最为重要的当前正在运行的g的下一条指令的地址和栈顶地址,不管是对g0还是其它goroutine来说这些信息在调度过程中都是必不可少的,我们会在后面的调度分析中看到调度器是如何利用这些信息来完成调度的。代码执行完save函数之后g0的状态如下图所示: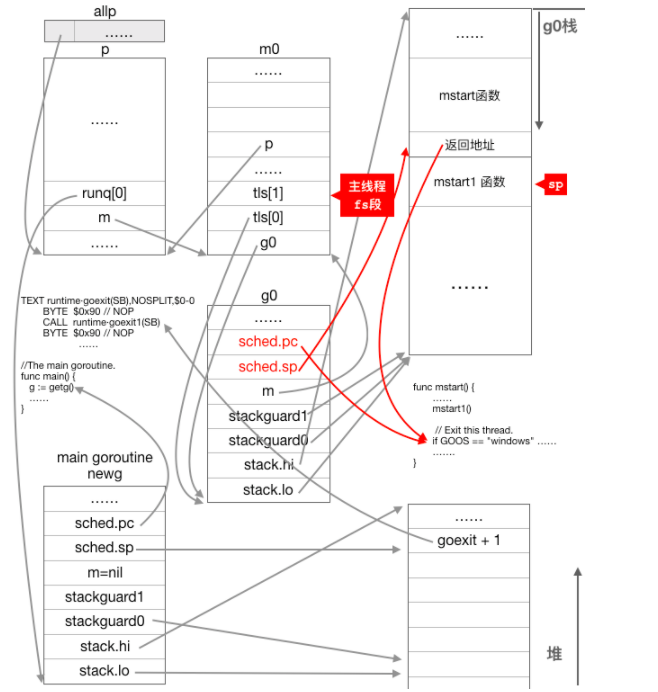
从上图可以看出,g0.sched.sp指向了mstart1函数执行完成后的返回地址,该地址保存在了mstart函数的栈帧之中;g0.sched.pc指向的是mstart函数中调用mstart1函数之后的 if 语句。
为什么g0已经执行到mstart1这个函数了而且还会继续调用其它函数,但g0的调度信息中的pc和sp却要设置在mstart函数中?难道下次切换到g0时要从mstart函数中的 if 语句继续执行?可是从mstart函数可以看到,if语句之后就要退出线程了!这看起来很奇怪,不过随着分析的进行,我们会看到这里为什么要这么做。
继续分析代码,save函数执行完成后,返回到mstart1继续其它跟m相关的一些初始化,完成这些初始化后则调用调度系统的核心函数schedule()完成goroutine的调度,之所以说它是核心,原因在于每次调度goroutine都是从schedule函数开始的。
runtime/proc.go : 2469
// One round of scheduler: find a runnable goroutine and execute it.// Never returns.func schedule() {_g_ := getg() //_g_ = 每个工作线程m对应的g0,初始化时是m0的g0//......var gp *g//......if gp == nil {// Check the global runnable queue once in a while to ensure fairness.// Otherwise two goroutines can completely occupy the local runqueue// by constantly respawning each other.//为了保证调度的公平性,每进行61次调度就需要优先从全局运行队列中获取goroutine,//因为如果只调度本地队列中的g,那么全局运行队列中的goroutine将得不到运行if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {lock(&sched.lock) //所有工作线程都能访问全局运行队列,所以需要加锁gp = globrunqget(_g_.m.p.ptr(), 1) //从全局运行队列中获取1个goroutineunlock(&sched.lock)}}if gp == nil {//从与m关联的p的本地运行队列中获取goroutinegp, inheritTime = runqget(_g_.m.p.ptr())if gp != nil && _g_.m.spinning {throw("schedule: spinning with local work")}}if gp == nil {//如果从本地运行队列和全局运行队列都没有找到需要运行的goroutine,//则调用findrunnable函数从其它工作线程的运行队列中偷取,如果偷取不到,则当前工作线程进入睡眠,//直到获取到需要运行的goroutine之后findrunnable函数才会返回。gp, inheritTime = findrunnable() // blocks until work is available}//跟启动无关的代码.....//当前运行的是runtime的代码,函数调用栈使用的是g0的栈空间//调用execte切换到gp的代码和栈空间去运行execute(gp, inheritTime)}
schedule函数通过调用globrunqget()和runqget()函数分别从全局运行队列和当前工作线程的本地运行队列中选取下一个需要运行的goroutine,如果这两个队列都没有需要运行的goroutine则通过findrunnalbe()函数从其它p的运行队列中盗取goroutine,一旦找到下一个需要运行的goroutine,则调用excute函数从g0切换到该goroutine去运行。对于我们这个场景来说,前面的启动流程已经创建好第一个goroutine并放入了当前工作线程的本地运行队列,所以这里会通过runqget把目前唯一的一个goroutine取出来,runqget()和findrunnable()这三个函数的实现流程,现在我们先来分析execute函数是如何把从运行队列中找出来的goroutine调度到CPU上运行的。
runtime/proc.go : 2136
// Schedules gp to run on the current M.
// If inheritTime is true, gp inherits the remaining time in the
// current time slice. Otherwise, it starts a new time slice.
// Never returns.
//
// Write barriers are allowed because this is called immediately after
// acquiring a P in several places.
//
//go:yeswritebarrierrec
func execute(gp *g, inheritTime bool) {
_g_ := getg() //g0
//设置待运行g的状态为_Grunning
casgstatus(gp, _Grunnable, _Grunning)
//......
//把g和m关联起来
_g_.m.curg = gp
gp.m = _g_.m
//......
//gogo完成从g0到gp真正的切换
gogo(&gp.sched)
}
execute函数的第一个参数gp即是需要调度起来运行的goroutine,这里首先把gp的状态从_Grunnable修改为_Grunning,然后把gp和m关联起来,这样通过m就可以找到当前工作线程正在执行哪个goroutine,反之亦然。
完成gp运行前的准备工作之后,execute调用gogo函数完成从g0到gp的的切换:CPU执行权的转让以及栈的切换。
gogo函数也是通过汇编语言编写的,这里之所以需要使用汇编,是因为goroutine的调度涉及不同执行流之间的切换,前面我们在讨论操作系统切换线程时已经看到过,执行流的切换从本质上来说就是CPU寄存器以及函数调用栈的切换,然而不管是go还是c这种高级语言都无法精确控制CPU寄存器的修改,因而高级语言在这里也就无能为力了,只能依靠汇编指令来达成目的。
runtime/asm_amd64.s : 251
# func gogo(buf *gobuf)
# restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $16-8
#buf = &gp.sched
MOVQ buf+0(FP), BX # BX = buf
#gobuf->g --> dx register
MOVQ gobuf_g(BX), DX # DX = gp.sched.g
#下面这行代码没有实质作用,检查gp.sched.g是否是nil,如果是nil进程会crash死掉
MOVQ 0(DX), CX # make sure g != nil
get_tls(CX)
#把要运行的g的指针放入线程本地存储,这样后面的代码就可以通过线程本地存储
#获取到当前正在执行的goroutine的g结构体对象,从而找到与之关联的m和p
MOVQ DX, g(CX)
#把CPU的SP寄存器设置为sched.sp,完成了栈的切换
MOVQ gobuf_sp(BX), SP # restore SP
#下面三条同样是恢复调度上下文到CPU相关寄存器
MOVQ gobuf_ret(BX), AX
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
#清空sched的值,因为我们已把相关值放入CPU对应的寄存器了,不再需要,这样做可以少gc的工作量
MOVQ $0, gobuf_sp(BX) # clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
#把sched.pc值放入BX寄存器
MOVQ gobuf_pc(BX), BX
#JMP把BX寄存器的包含的地址值放入CPU的IP寄存器,于是,CPU跳转到该地址继续执行指令,
JMP BX
gogo函数的这段汇编代码短小而强悍,虽然笔者已经在代码中做了详细的注释,但为了完全搞清楚它的工作原理,我们有必要再对这些指令进行逐条分析:
execute函数在调用gogo时把gp的sched成员的地址作为实参(型参buf)传递了过来,该参数位于FP寄存器所指的位置,所以第1条指令
MOVQ buf+0(FP), BX # &gp.sched --> BX
把buf的值也就是gp.sched的地址放在了BX寄存器之中,这样便于后面的指令依靠BX寄存器来存取gp.sched的成员。sched成员保存了调度相关的信息,上一节我们已经看到,main goroutine创建时已经把这些信息设置好了。
第2条指令
MOVQ gobuf_g(BX), DX # gp.sched.g --> DX
把gp.sched.g读取到DX寄存器,注意这条指令的源操作数是间接寻址,如果读者对间接寻址不熟悉的话可以参考预备知识汇编语言部分。
第3条指令
MOVQ 0(DX), CX # make sure g != nil
的作用在于检查gp.sched.g是否为nil,如果为nil指针的话,这条指令会导致程序死掉,有读者可能会有疑问,为什么要让它死掉啊,原因在于这个gp.sched.g是由go runtime代码负责设置的,按道理说不可能为nil,如果为nil,一定是程序逻辑写得有问题,所以需要把这个bug暴露出来,而不是把它隐藏起来。
第4条和第5条指令
get_tls(CX)
把DX值也就是需要运行的goroutine的指针写入线程本地存储之中
#运行这条指令之前,线程本地存储存放的是g0的地址
MOVQ DX, g(CX)
把DX寄存器的值也就是gp.sched.g(这是一个指向g的指针)写入线程本地存储之中,这样后面的代码就可以通过线程本地存储获取到当前正在执行的goroutine的g结构体对象,从而找到与之关联的m和p。
第6条指令
MOVQ gobuf_sp(BX), SP # restore SP
设置CPU的栈顶寄存器SP为gp.sched.sp,这条指令完成了栈的切换,从g0的栈切换到了gp的栈。
第7~13条指令
#下面三条同样是恢复调度上下文到CPU相关寄存器
MOVQ gobuf_ret(BX), AX #系统调用的返回值放入AX寄存器
MOVQ gobuf_ctxt(BX), DX
MOVQ gobuf_bp(BX), BP
#清空gp.sched中不再需要的值,因为我们已把相关值放入CPU对应的寄存器了,不再需要,这样做可以少gc的工作量
MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
一是根据gp.sched其它字段设置CPU相关寄存器,可以看到这里恢复了CPU的栈基地址寄存器BP,二是把gp.sched中已经不需要的成员设置为0,这样可以减少gc的工作量。
第14条指令
MOVQ gobuf_pc(BX), BX
把gp.sched.pc的值读取到BX寄存器,这个pc值是gp这个goroutine马上需要执行的第一条指令的地址,对于我们这个场景来说它现在就是runtime.main函数的第一条指令,现在这条指令的地址就放在BX寄存器里面。最后一条指令
JMP BX
这里的JMP BX指令把BX寄存器里面的指令地址放入CPU的rip寄存器,于是,CPU就会跳转到该地址继续执行属于gp这个goroutine的代码,这样就完成了goroutine的切换。
总结一下这15条指令,其实就只做了两件事:
- 把gp.sched的成员恢复到CPU的寄存器完成状态以及栈的切换;
- 跳转到gp.sched.pc所指的指令地址(runtime.main)处执行。
现在已经从g0切换到了gp这个goroutine,对于我们这个场景来说,gp还是第一次被调度起来运行,它的入口函数是runtime.main,所以接下来CPU就开始执行runtime.main函数: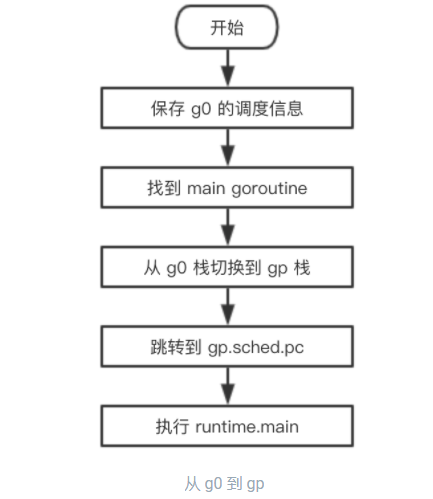

若有收获,就点个赞吧
0 人点赞
