DataCon2020-加密恶意流量检测 - 清华大学HawkEye战队
1:概述
由于加密流量荷载不可观测且流量数据体量较大,我们通过采用机器学习技术结合领域知识,对加密恶意流量和正常流量的行为特征进行深入挖掘,实现对恶意流量的自动化检测。
我们所采用的检测方法的总体结构是让多个分别利用不同的异构特征训练而成的分类器进行多数投票(Majority Voting)的方式来获取最终的判定结果。由于我们所采用的多种特征是异构数据,且具有不同的组织特点,我们并没有直接采用将这些特征统一编码并输入到集成学习分类器中的常规方式,而是针对各个特征的特点分别构建对应的分类器,并利用他们的分类结果进行投票,最终取得多数票的分类结果被定为最终的分类结果。
参与投票的多个模型中部分使用了多维特征综合分析,另一部分使用经过分析后黑白样本区分较大的、置信度较高的单维特征对多维特征中的潜在的过拟合和判断错误进行消解。
同时,我们考虑到了数据包级、流级、主机级多维度的行为建模,将不同层次的数据进行聚合分析,提升对于黑白样本建模的准确度。
图1展示了我们方案的整体流程。下面我们将分别介绍我们所采用的特征及对应的分类器、投票机制、实现和性能以及展望和总结。
2:特征选取与子分类器
下面我们将详细介绍六个参与投票的子模型中的每一个模型所采用的特征及对应的分类器,以及设计的动机和意义。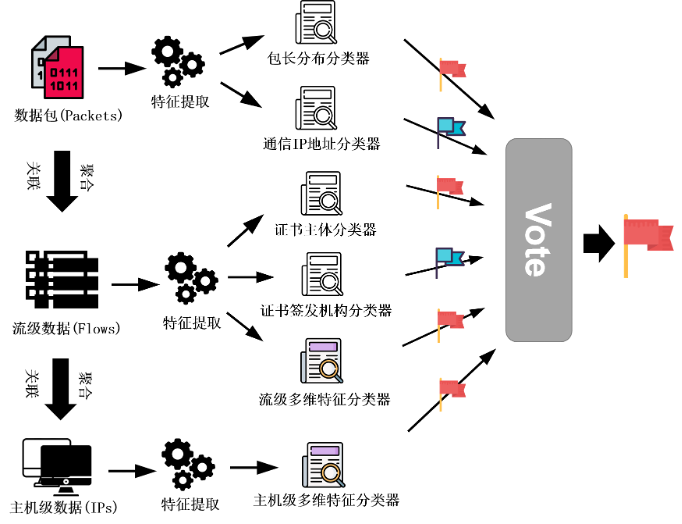
图1:加密恶意流量检测整体流程图
2.1 包长分布特征
2.1.1动机
不同的软件在通信数据的体量上具有不同的特点,我们认为功能或实现相似的软件会具有相同的数据包体量分布特点,正如视频软件的下行流量通常远大于上行流量,而恶意键盘记录器的上行流量总是远大于下行流量一样。
再如图2展示的正常通信(如搜索浏览网页)和恶意软件在包长上的区别,浏览网页通常是客户端向服务端发送少量数据包(搜索请求)然后服务端回复大量的响应包(通常是大段的MTU长度的包),但是恶意软件进行数据窃取和回传时,在行为模式上体现为客户端向服务器端发送发量的数据包,而服务器端只有少量的控制命令。
由于流量的体量特征并不会因为数据的加密而变得不可见或被歪曲,因此适用于对加密流量的检测。
然而,仅利用上行流量的下行流量的数据包数量比值与字节数量比值这两个数值特征过于笼统,并无法充分表征软件在通信流量上的体量特点。于是我们采用了将每个报文所具有的长度和方向均作为一维独立的特征进行编码的方式。我们推测软件与服务端之间通信的一些控制信息的报文的长度总是相似的,且这些频繁的具有相同目的的通信报文的长度会是高频的,且这种长度特征是直接由软件的功能和实现决定的,具有较好的平稳性和区分度。
图2:恶意/正常通信中数据包长度的区别
2.1.2 编码方式与分类器
我们将每一个可能的报文长度和方向的二元组视为包长分布特征中的一个独立的维度。由于以太网最小帧长为64字节,而互联网的最大传输单元通常是1500字节,报文的方向只有收发两个方向,我们的包长分布特征是一个维数约3000的概率分布。
对该特征的提取,我们采用以频率估计概率的方式,统计每个流量样本中的各个长度和方向的报文的数量,并除以报文总数得到其概率分布。
由于包长分布的特征本质上是一个离散概率分布,最直接的分类器应该是基于度量的分类算法,通过度量分布之间的相似性大小来判断其类别所属。我们采用了Hellinger距离的度量方式与kNN分类算法,Hellinger距离是在概率分布空间对欧氏距离的模拟。由于kNN算法并不需要训练过程,而在分类过程中需要计算待分类的样例与已有样本集中的每个样例的相似性度量结果,因此其运行效率十分低下,于是我们也考虑了采用随机森林的分类器来利用这一特征的方式。
2.1.3 测试与分析
仅采用包长分布这一特征与kNN分类器的方法在初赛中取得了68.7分的成绩,说明该方法具有一定的检测能力。在复赛中,我们曾采用该分类器不参与投票的方法,结果触发了高检出奖励,但是整体得分依然不够高,在我们加入了基于这一特征的分类器的投票后,得分更高,但是不再触发高检出奖励,可见这一方法具有良好的降低误报的效果。最终,基于对测试性能的考虑,我们采用了随机森林分类器来处理这一特征,并利用其结果参与到最终的投票中。
考虑到包含恶意流量的样本中也含有与正常服务通信的流量,而与正常服务之间的通信流量可能会掩盖恶意流量在包长分布上的特征。我们尝试使用流级的包长分布特征来进行分类。
然而,我们无法将标注为‘black’的样本中的所有的流都视为恶意流量,因此我们仅将其中只包含一条流的样本中的流级包长分布特征作为标注为恶意流量的特征,这在所有的标注为‘black’的样本中共有一千多条流,而在标注为‘white’的样本中仅有不到500条流,双方并不均衡,如果把标注为‘white’的样本中的包含多条流的流量均选入流级特征的训练集,又会造成一种相反的不均衡。
采用流级的包长分布特征时,我们将不包含任何分类为恶意流量的流的流量样本判断为正常样本,否则视为恶意样本,这种处理方法的结果并不理想,因此我们并没有采用。
2.2 证书主体与签发者黑白名单特征
2.2.1 动机
我们认为决定一个软件是否是恶意软件不仅仅取决于其通信内容,也取决于其通信的对象,而通信内容由于加密无法作为可辨识的特征,因此我们着重考虑了客户端流量样本中的通信对象。
在TLS建立连接的过程中,服务端发来的证书中的叶子证书的Subject字段表明了客户端的直接通信对象,而Issuer字段则表明了该证书的直属签发机构。
Subject字段里的commonname通常是一个域名,我们认为这将是一个很重要的标识信息,因为恶意软件与恶意域名关联的可能性较大。
图3中展示了恶意和正常证书中主体和签发者的情况,可以看出黑白样本有明显区别并都存在着访问频次较高的项:
图3:恶意/正常证书中主体和签发者
2.2.2 编码方式与分类器
我们对训练集中的每个流量样本统计了其中的叶子证书所涉及到的不同Subject和Issuer的数量,并记录每个流量样本与他们通信的频数。
我们采用了词袋模型中的bagging方法来编码这一特征,即将每个单独的Subject和Issuer视作一个独立的单词,一个流量样本视作由这些样本组成的句子,然后将词频编码为特征向量。
最后我们采用朴素贝叶斯分类器这一基于先验概率的算法对测试集中的样本进行分类,由于朴素贝叶斯分类器属于非参数算法,其本质在于发现特征与分类结果之间的因果关系,因此可以视为一种黑白名单的方法。
如果一个测试样本中所有的证书Subject或Issuer都不曾在训练集中出现过,我们直接将其判定为恶意样本,因为在训练集中包含了绝大多数流行域名,这是正常流量中大概率会出现的通信对象。
通过对证书中Subject的频数分析,我们发现在训练集中,正常样本访问‘google.com’,‘microsoft.com’的频率高于恶意样本,而恶意样本中访问‘qq.com’和‘baidu.com’的频率高于正常样本,这些域名都是明显的良性域名,然而在朴素贝叶斯分类器中,‘google.com’和‘microsoft.com’将对判定为正常样本贡献更多的证据,而‘qq.com’和‘baidu.com’将对判定为恶意样本贡献更多的证据。
基于对此的质疑,我们尝试过去掉频数统计而改用二值编码的方式以及去掉一些对流行域名的编码的方式,发现效果都没有采用bagging处理方式的效果好。
此外,我们还尝试了仅使用二级域名与域名字符随机性的方法,都没有较明显的效果提升。
2.3 通信IP地址黑白名单特征
2.3.1 动机
除了证书中的Subject和Issuer信息外,服务端IP地址是另一个表示软件通信对象的标识符。有少数流量样本中出现了缺少证书的情况,且我们认为同一地区遭受同类恶意软件感染很可能会造成他们对相同的IP地址的访问,因此我们将流量样本中的远程IP地址的访问情况也作为一个判断是否包含恶意流量的依据。
2.3.2 编码方式与分类器
与证书主体和签发者黑白名单特征类似的是,我们采用了朴素贝叶斯分类器作为远程通信IP地址黑白名单的处理算法。不同的是,我们并没有记录每个IP地址的通信频次,而是用二值0和1表示是否与某个特定IP地址进行了通信。因为我们认为对于恶意软件的服务端IP地址,即使仅仅一次通信,也能够将其视为来自恶意软件的恶意流量。
2.4 流级荷载无关特征提取
2.4.1 动机
上述四个子模型结合领域知识和对加密恶意流量特征提出了不同的单维特征提取和分类方法,除此而外,为了进一步提升检测效果,避免由于领域知识的不足和片面性导致恶意流量一些无法根据上述的特征检出,我们还提出了比较通用的多维特征,即通过尽可能多的对协议头部和流量行为特征进行抽取和建模,构建多维模型,并利用机器学习算法对于多维数据强大的学习能力,对黑白流量进行分类。
2.4.2 编码方式与分类器
我们首先考虑流级特征,由于TCP连接可以由流的四元组确定,所以恶意通信一般是指流级别的,分析每条流的黑或白是十分合理的。我们综合考虑了已有相关工作[1–3],以及对TCP、TLS/SSL协议进行深入分析,共提取了超过1000维与荷载无关的流级特征,包含如下几部分:
元数据(Metadata)
即单条流的基本统计数据,包含持续时间(duration)、总的流入(inbound)/流出(outbound)的字节数、数据包个数;
窗口序列统计特征
我们对出/入流量分别维护了包时间间隔和包长度的窗口,每个窗口提取统计特征,包含平均值、标准差、最大值、最小值;除此而外,我们发现仅仅关注一整个窗口的特征粒度不够细化,为了更加精细化的对流量行为进行捕获和建模,我们关注窗口中的每个数据包,并使用马尔科夫转移矩阵的方式捕获相邻包之间的关系。
以构建包长窗口的马尔科夫矩阵为例,我们首先将包长均匀分成15个桶(bin),然后建立15×15的矩阵,每个元素表示从行转移到列所代表的的桶,最后对矩阵进行行的归一化处理,将其转化为概率形式;
TLS/SSL握手包特征
首先我们发现本赛题中客户端和服务器端都出现了多种不同的协议类型,而黑和白训练集中客户端和服务器不同版本的分布是不同的,因此协议版本可以作为一个特征,我们将客户端和服务器端使用的TLS版本进行独热(one-hot)编码;同时我们关注到Hello包中GMTUnixTime字段在黑/白训练集中的分布也有所不同,因此我们将客户端和服务器端的GMTUnixTime的是否存在、是否使用随机时间编码为0/1的特征;此外,由于恶意软件和恶意服务器使用的加密套件和列表很有可能与正常的加密流量有所区别,我们将客户端与服务器端的加密套件(列表)和扩展列表进行独热编码,即将所有可能的加密套件和扩展列出展成一维0向量,当前流使用的套件和扩展对应的位置赋值为1;
TLS/SSL证书特征
服务器端证书对于区分正常和恶意流量有着重要的作用,如恶意通信的证书多采用自签名的方式。因此我们对服务器端证书进行了特征挖掘,主要选用如下的0/1特征:是否自签名、是否过期、版本号、证书有效期、公钥长度;
同时,我们考虑到之前模型发现有些证书主体域名单一使用无法区分黑/白的情况,因此也嵌入到多维特征中,使用独热编码对训练集常用证书主体域名进行独热编码。
我们最终采用了随机森林模型对高维数据进行分类,主要是由于其对于高维数据有较好的处理能力,同时基于树的方法可以直接对特征重要性进行评分,这对于后续挑选重要特征、降低特征维度、删除冗余特征十分方便,同时我们对树高进行了限制防止特征过于细化导致过拟合。
2.5 主机级荷载无关特征聚合
2.5.1 动机
上一小节中分析流级特征来对分析目标进行判定是十分合理的,但是却面临着挑战和问题。
首先,本赛题的标记数据为单个pcap报文,对于白样本,我们可以简单认为其所有流都是白的,但是对于黑样本的流标记问题存在一定问题,由于被感染的主机也可能会进行正常通信,而且恶意软件也可能出现正常行为,比如访问谷歌判断网络连通性,所以黑样本的流标记变得十分困难。
同时,单独的看每条流可能漏掉了流之间的关联行为即主机级别的行为,比如恶意软件在发出正常的访问谷歌流量后可能就要开始进行恶意传输。再比如,有少量正常流也会出现自签名,如果我们单独看流,可能就会误判,但是如果我们基于主机提取特征发现同一IP下有多条流都是自签名,则我们就会有很大的信心认为这是恶意的。
因此,我们将上一小节中流级别的特征进行聚合,并以流为基本单位提取主机级别特征。
2.5.2 编码方式与分类器
主机级特征聚合部分主要考虑了如下的特征:首先是选取了部分流级特征进行聚合,包含总包个数,每条流的平均包个数,时间间隔、包长的均值,以及上一个小节中证书部分的相关特征,即自签名流数量,过期流数量,有效期过长(比如100年)的流数量及其均值。
除了对上一小节中的特征进行聚合,我们还对不同流的连接状态进行统计,我们发现恶意ip的TLS半连接和无连接与正常ip的分布不同,因此我们统计不同tls连接状态的流数目,以及出现Alert的流数目。分类器依然使用随机森林模型,主要是其使用了可解释性较强的决策树的集成学习模式,测试发现有较好的效果。
3 投票机制
我们总共有6个分类器进行直接投票,并没有根据每个分类器的判定概率进行投票。在我们尝试的过程中,如果有奇数个分类器,那么对于二分类问题不会出现平局的情况。在我们最终的方案中,由于有偶数个分类器,可能会出现平均的情况,这时我们增加了基于流特征的分
类器的权重,因为其在单独测试中取得了最佳的成绩,即如果出现各有三个分类器分别认为某测试样本是正常样本和恶意样本时,我们采用基于流特征的分类器的结果作为最终结果。
4 实现与性能
4.1 特征提取
为了优化性能,我们直接实现了从原始报文数据中的流量特征提取,没有依赖tshark等第三方工具与第三方库,即我们直接将pcap文件作为二进制流读取并依据协议解析每个字段,因此我们的特征提取效率是很高的。
在测试环境中,我们从原始流量数据中提取特征到输出最终的检测结果的总用时在136秒左右,相比于使用tshark进行特征相关字段的提取,快了近几十倍。
4.2 机器学习模型
我们的分类器机器学习算法采用了Pythonsklearn库的实现。在本地测评时使用了2:1划分训练集和测试集。采用的机器学习模型基本使用了默认参数,其中随机森林增加弱分类器数目到200。
我们在复赛阶段取得的最高得分是82.34,还有两次得分出发了高检出奖励(检出率>95%)。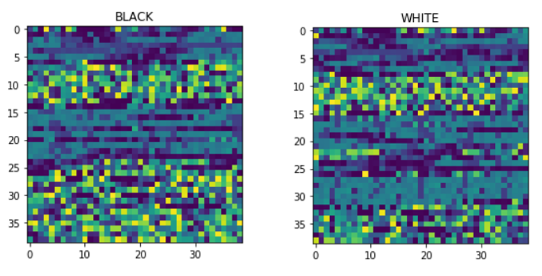
图4:恶意/正常证书内容转化为像素的纹理区别
5 展望和总结
除了上述介绍的使用统计和机器学习方法外,我们团队还尝试使用其他方法,如深度学习技术进行自动特征学习来减轻人为特征提取的高开销和片面性,我们对一些想法进行了简单实现,比如使用将证书内容转换为RGB像素值输入到CNN中,基于图像纹理对黑白样本的证书进行区分,如图4所示。
同时,上述分析的流之前关联性的分析使用RNN也非常合适,以及对于不同的ip和流之间的连接关系建立图结构使用GNN进行节点分类也十分具有前景,但因为复赛时间非常有限,同时虚拟环境没有gpu支持,本次比赛最终没有使用深度学习的方法,相关方法值得后续研究。
总的来讲,本次比赛我们通过对加密流量进行深入分析和特征挖掘,对TLS/SSL协议进行分析学习,通过多模型投票、单维/多维特征结合、以及包级/流级/主机级多层级行为聚合分析,有效的提升了检测效果。
同时,本次比赛锻炼了我们使用机器学习方法去解决实际安全问题的能力,本次比赛引入性能因素也让我们有机会对原始报文进行解析,深入了解协议原理,是一次难得的学习经历。
参考文献
[1]KORCZYŃSKIM,DUDAA.Markovchainfingerprintingtoclassifyencryptedtraffic[C]//IEEEINFOCOM2014-IEEEConferenceonComputerCommunications.[S.l.]:IEEE,2014:781-789.
[2]ANDERSONB,MCGREWD.Machinelearningforencryptedmalwaretrafficclassification:accountingfornoisylabelsandnon-stationarity[C]//Proceedingsofthe23rdACMSIGKDDInternationalConferenceonknowledgediscoveryanddatamining.[S.l.:s.n.],2017:1723-1732.
[3]ANDERSONB,PAULS,MCGREWD.Decipheringmalware’suseoftls(withoutdecryption)[J].JournalofComputer
VirologyandHackingTechniques,2018,14(3):195-211.

若有收获,就点个赞吧
0 人点赞
