威胁棱镜-Avenger - IoT恶意软件进化谱系研究
《IEEE IoT Newsletter - March 2021》
已有研究多针对特定IoT恶意软件展开,都忽略了每个家族的系统演化情况,导致对恶意软件发展趋势的分析不完整不是全局视野。研究需要挖掘家族之间的血缘关系,形成对恶意软件的家族归类和谱系推断的能力。
情报收集
BlackHat 的演讲(Iot malware: Comprehensive survey, analysis framework and case studies)中总结了至少 60 个 IoT 恶意软件家族,涵盖了 2012 年至 2018 年的主要家族。从这些家族名称的初始关键字列表开始。通过在 Google 上搜索初始关键词,得到了 10214 条相关结果作为初始文章库。
对于别名可以通过正则表达式捕获,这些匹配模式是通过从收集的文章中进行的大量手动分析工作总结出来的。这样总共收集到了 138 个家族别名(覆盖 72 个家族)。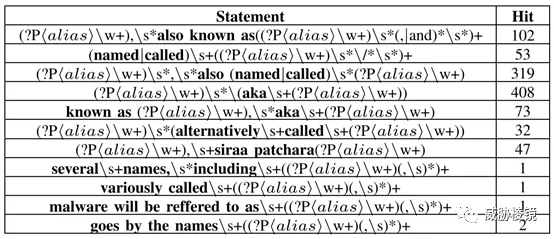
进一步使用这些家族别名和固定短语“IoT 恶意软件/僵尸网络”来搜索在线文章并抓取所有结果,包括安全报告、技术博客文章等。然后删除重复的和不相关的文章。
最后,可使用 17857 篇 IoT 恶意软件相关文章进行分析。虽然定义的别名模式可能无法涵盖所有可能的用法,但由于收集的文章数量众多,这些模式足以收集常用的别名。
特征挖掘
恶意软件特征挖掘阶段包括两个任务:恶意软件行为提取和基于提取行为的特征工程。
行为提取
首先获取每个家族的高频行为列表,用于后续的特征关联。恶意软件行为提取主要分两步提取:收集和行为加权。
使用斯坦福类型依赖解析器来分析每个句子的主要成分并提取行为。通过 WordNet 合并具有相似含义的相同词性的单词以减少单词变体。最后从 17857 篇文章中生成了 62424 个独特的行为。
收集所有行为中的动词和名词,以预测单词和家族之间的语法关系。根据 FeatureSmith(Featuresmith: Automatically engineering features for malware detection by mining the security literature)的方法定义每个单词和家族之间的相关性分数。
选择 ATT&CK 中与 Linux 相关的战术阶段,并将提取的行为映射到特定的战术阶段,以便与可提取的特征进一步关联。根据统计分析,高权重行为在相应家族的在线文章中出现更为频繁。最终得到每个家族前 5400 种行为被映射为 7 种战术阶段,如下所示。
特征工程
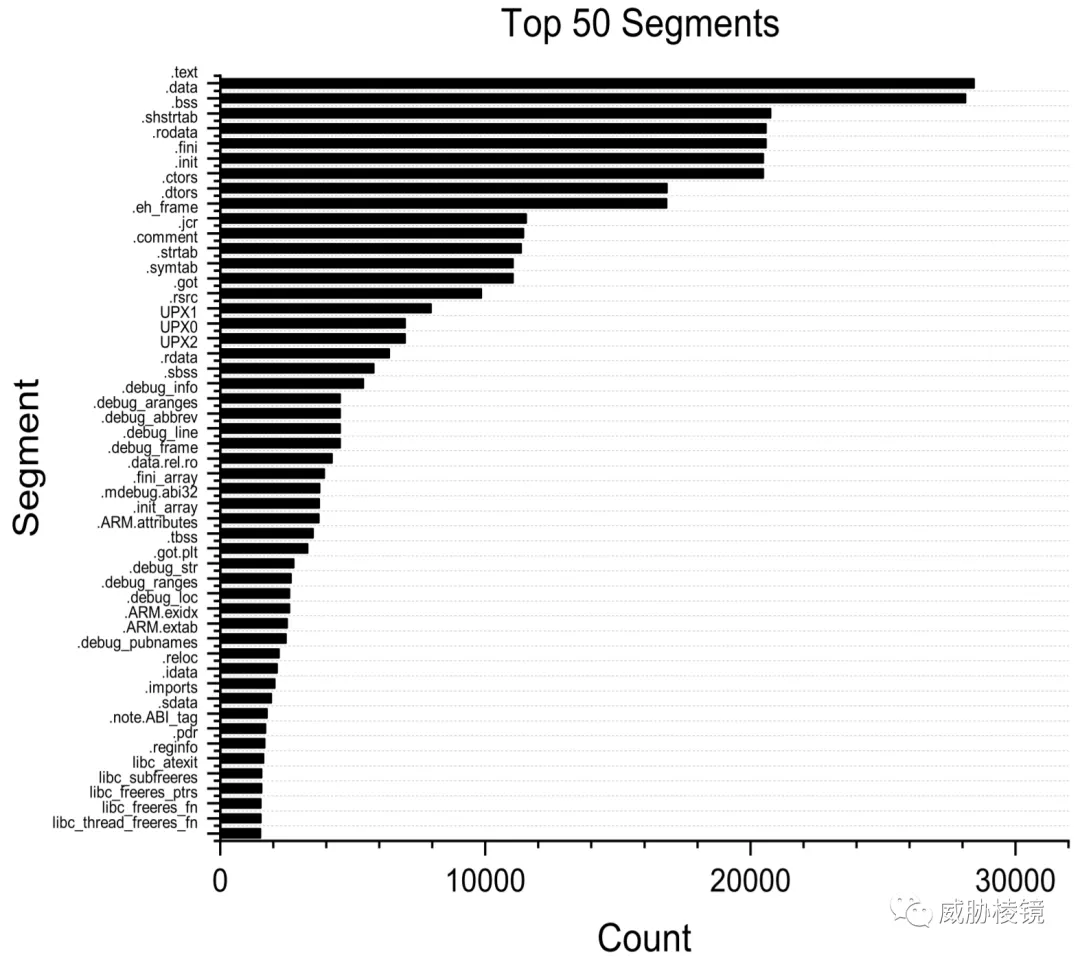
特征工程是要将 5400 个行为映射到对应的特征上。前人研究证明可执行二进制文件中的文件元信息、段、系统调用和用户命令可以反映不同家族的行为特征。本工作也利用文件元数据、系统调用和库函数作为潜在的物联网恶意软件分类特征。
用作分类特征的文件元数据包括二进制文件大小、编译期间的安全选项(例如 Canary 和 NX)、操作环境(例如 OS、架构和 MMU(内存管理单元支持))和各种编译选项。共选择了 18 个可执行二进制文件的属性作为分类特征,如下所示。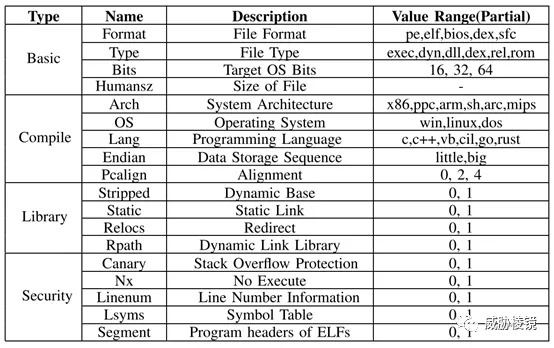
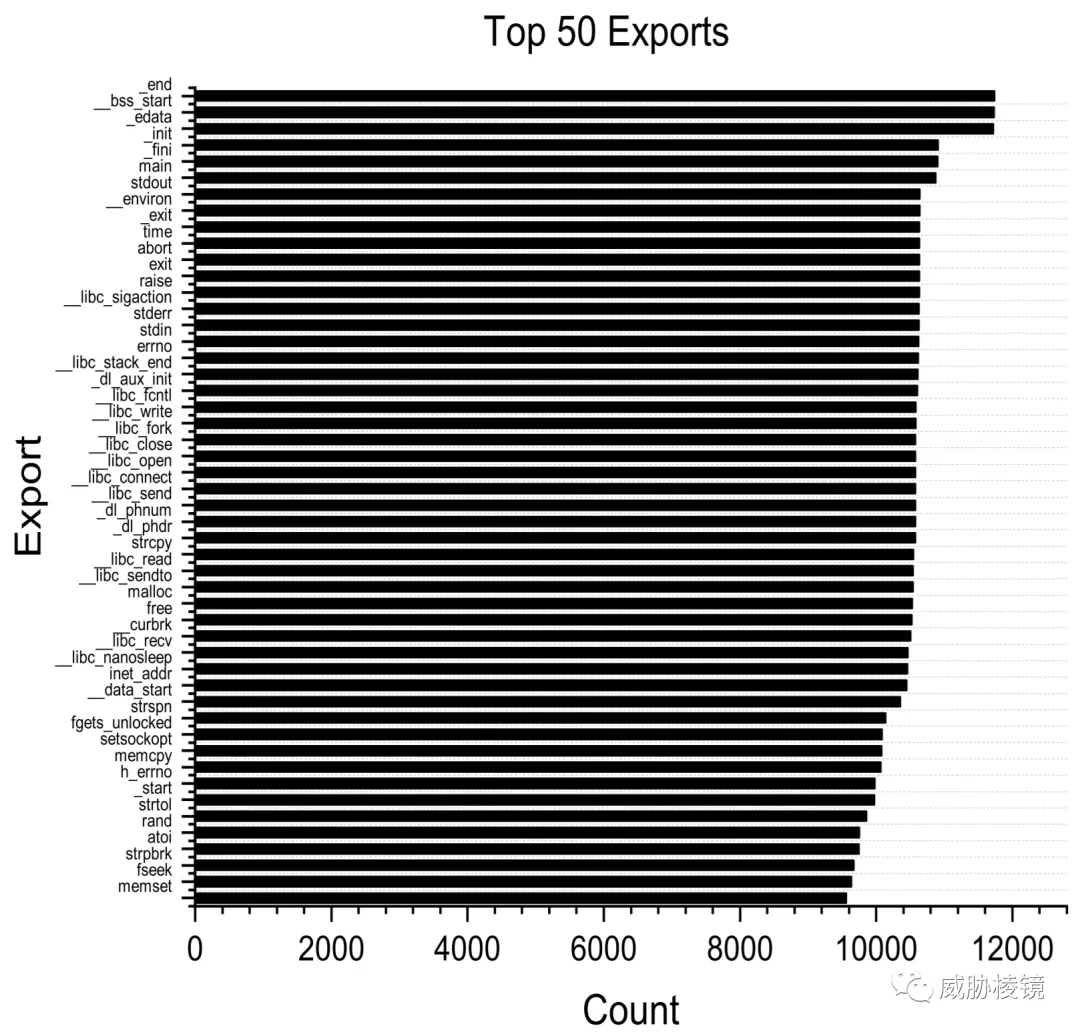
在基于 Linux 的系统下有两种操作的方式:系统调用和库函数。系统调用提供了操作系统和进程之间的接口,这是进入内核系统的唯一入口点。库函数作为应用程序编程接口用于应用程序开发。恶意行为可能与一个或多个特定的系统调用或库函数相关联。用系统调用和库函数来生成物联网恶意软件检测的潜在特征。总的来说,共有 7422 个库函数和 500 个系统调用。
要分三步将行为和特征关联起来,前五个特征如下所示: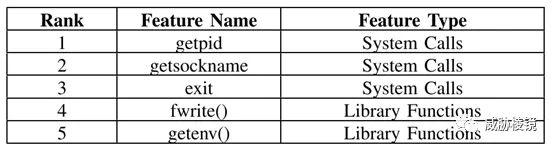
总共获得了 165 个系统调用和 1278 个库函数可用作特征,这些特征可以很容易地从可执行文件中提取出来。
家族谱系推断
与传统恶意软件相比,IoT 恶意软件家族进化速度更快,派生关系更加复杂,变种家族数量众多。
首先删除包含少于两个不同家族名称的句子,它们不太可能表达出可用的谱系相关信息。采用简单的 SVM 模型来区分出包含谱系关系表达的句子。选择 SVM 是因为在数据量较小时相比其他同类算法决策树、KNN 等具有更好的分类准确率,并且训练更加轻量级。
谱系关系表达的词汇是 “new”、“same”、“evolution”、“likely”、“common”、“offspring”、“later”、“derived”、“variant”、“beyond”、“faster”、“similar”、“merge”、“followed”、“like”、“from”、“version”、“fusion”。
提取出 9002 句与谱系关系有关的句子,使用别名库合并过滤。最后有 280 个句子可以表示恶意样本的谱系关系。
分类模型
集成学习使用多种基本学习算法(又名弱模型)来获得比任何弱模型更好的分类性能。弱模型的设计如下所示。
在准确性和效率之间进行权衡考虑后,提出四种类型的弱模型:即 Double 模型、Simple 模型、Black-White 模型和 Total 模型。对收集的 23 个家族进行了模型训练,涉及的弱模型总数为 253 个。最终的检测结果由每个模型的线性加法加权投票决定。
进行 10 折交叉验证测试,选择 f-measure 作为集成模型的投票权重(注:f-measure 是 precision 和 recall 的调和平均值)。Black-White 模型首先用于检测给定样本是良性还是恶意。之后,其他弱模型同时进行进一步检测。异构弱模型针对不同特征的识别可以提高整个集成模型的鲁棒性,每一个绕过集成模型的意图都可能影响每个弱模型的输出,从而极大地增加攻击成本。
谱系分析
恶意软件谱系分析难以验证分析结果。让基于 NLP 的谱系分析和基于样本的分析得到的结果相互印证。
基于系统调用与恶意软件行为相关。恶意软件经过变种改进后,主要的恶意特征仍然保留。这一发现表明系统调用可以检测派生谱系。此外,即使是新的变种,其恶意意图也与原始变种相似。因此,可以通过系统调用有效地识别新的变体。
将每个特征作为词向量处理,得到每个家族排名靠前的频繁向量(也可称为频繁串)。为了计算每个家族的谱系纯度,定义了七个变量。
工作准备
设计了四种收集样本的蜜罐,如下所示: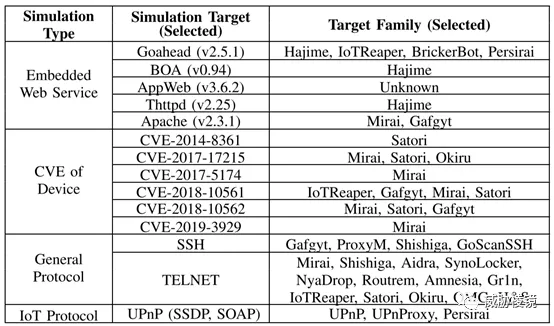
- 第一种类型的蜜罐模拟嵌入 Web 服务的设备,主要包括 Goahead、BOA、AppWeb、Thttpd、Apache 等。
- 第二种类型的蜜罐模拟流行的 CVE 存在的物联网设备。
- 第三种类型的蜜罐模拟通用协议捕获物联网恶意软件家族的 courie 蜜罐。
- 第四种类型的蜜罐模拟物联网相关协议的物联网恶意软件家族。
蜜罐覆盖 15 国家/地区的 20 个 VPN 上部署,拥有动态 IP 地址。大部分被捕获的家族是 Mirai 和 Gafgyt,另外也从其他来源补充了数据集。
家族标签由 AVClass 确定。但 VirusTotal 中的引擎并未针对 IoT 进行定制,这导致许多 IoT 恶意软件样本被标记为传统恶意软件家族。
最终的恶意软件数据集由两部分组成:第一部分包括从 Ubuntu Core 18 系统 AMD 64 位、RIOT-OS-2020.04 和 Contiki-NG-3.0 的可执行文件中收集的 16752 个良性样本,这些样本是专门为物联网设备设计的。第二部分是基于 Cowrie 蜜罐和商业交换收集到的 36 个恶意软件家族的 39004 个物联网恶意样本。如下所示: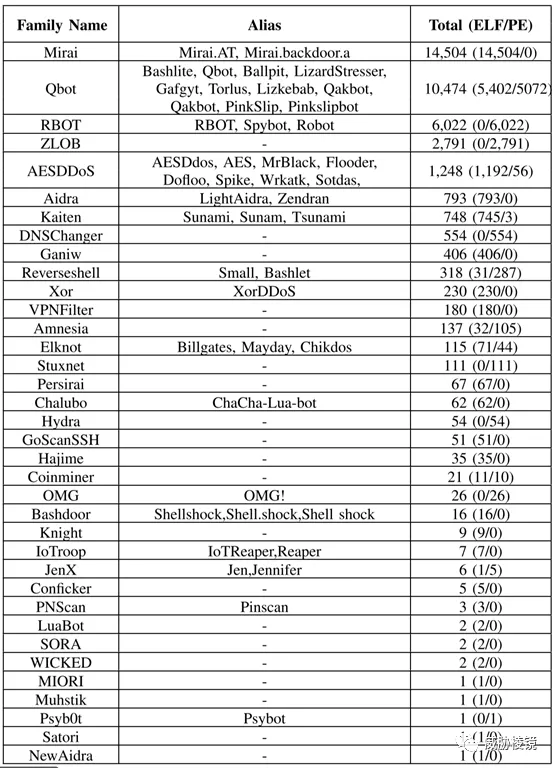
样本数据集以及其他一些内容开源在https://github.com/IoMafelt/IoMafelt。
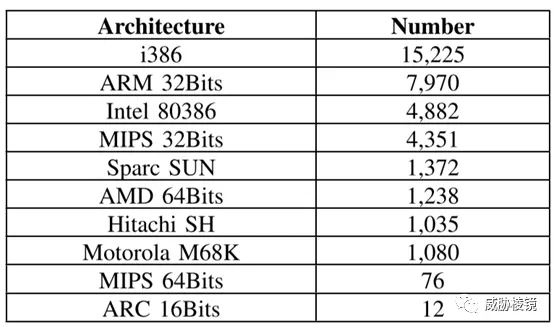
架构
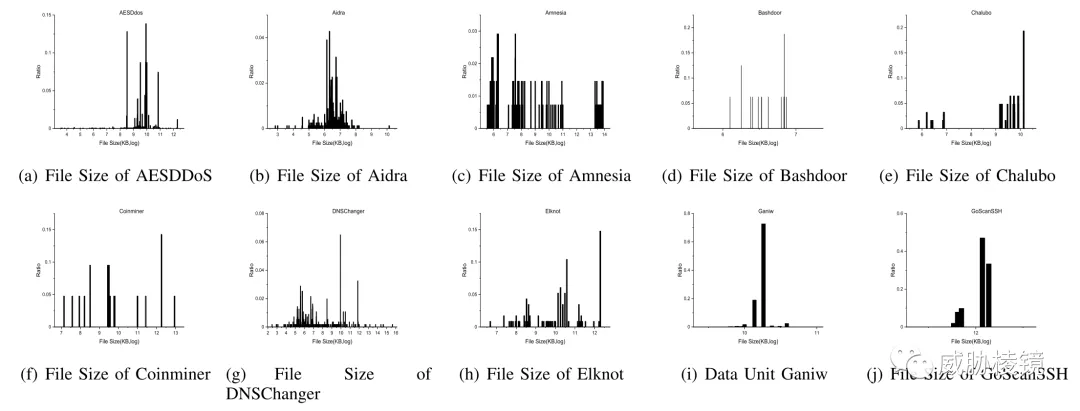
大小
一些家族在其二进制文件中嵌入了硬编码的弱口令列表,这导致文件大小变大。
Bit
系统调用
许多家族通过使用名为 gethostname 的系统调用来获取主机名。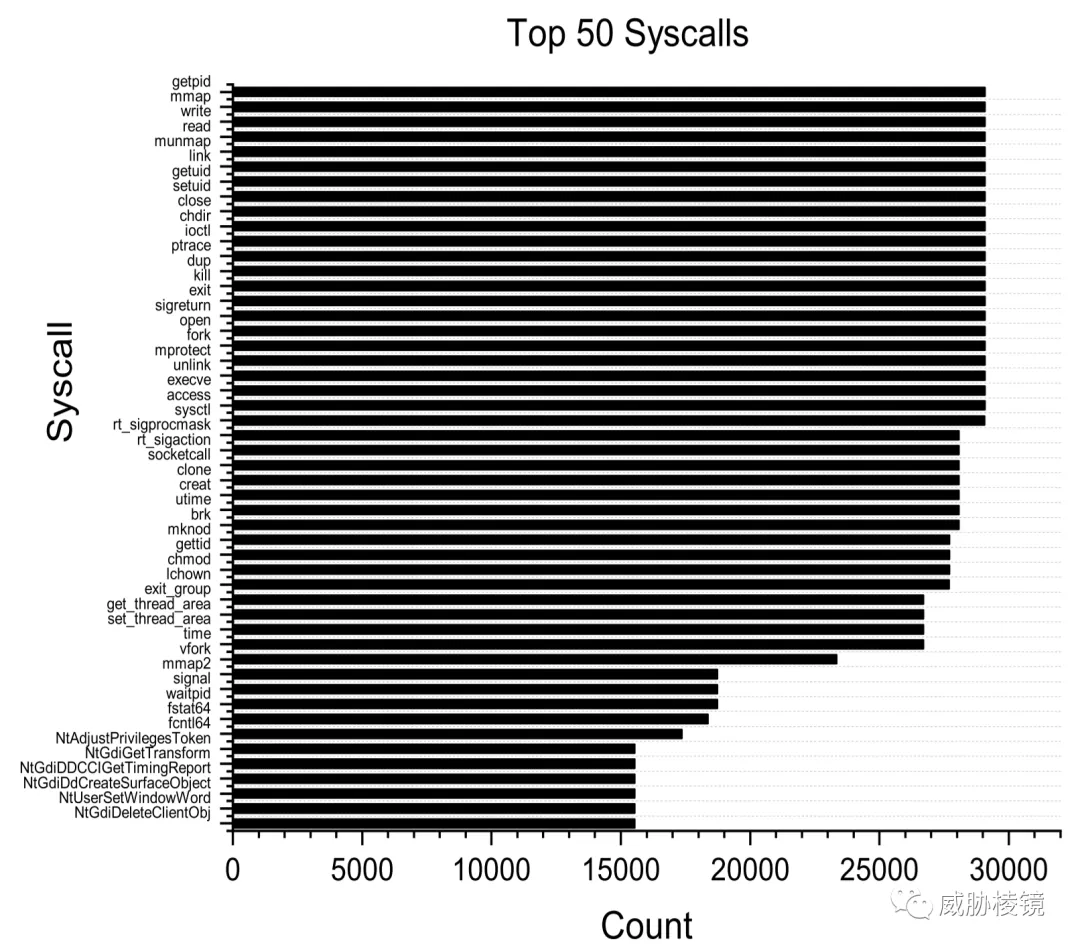
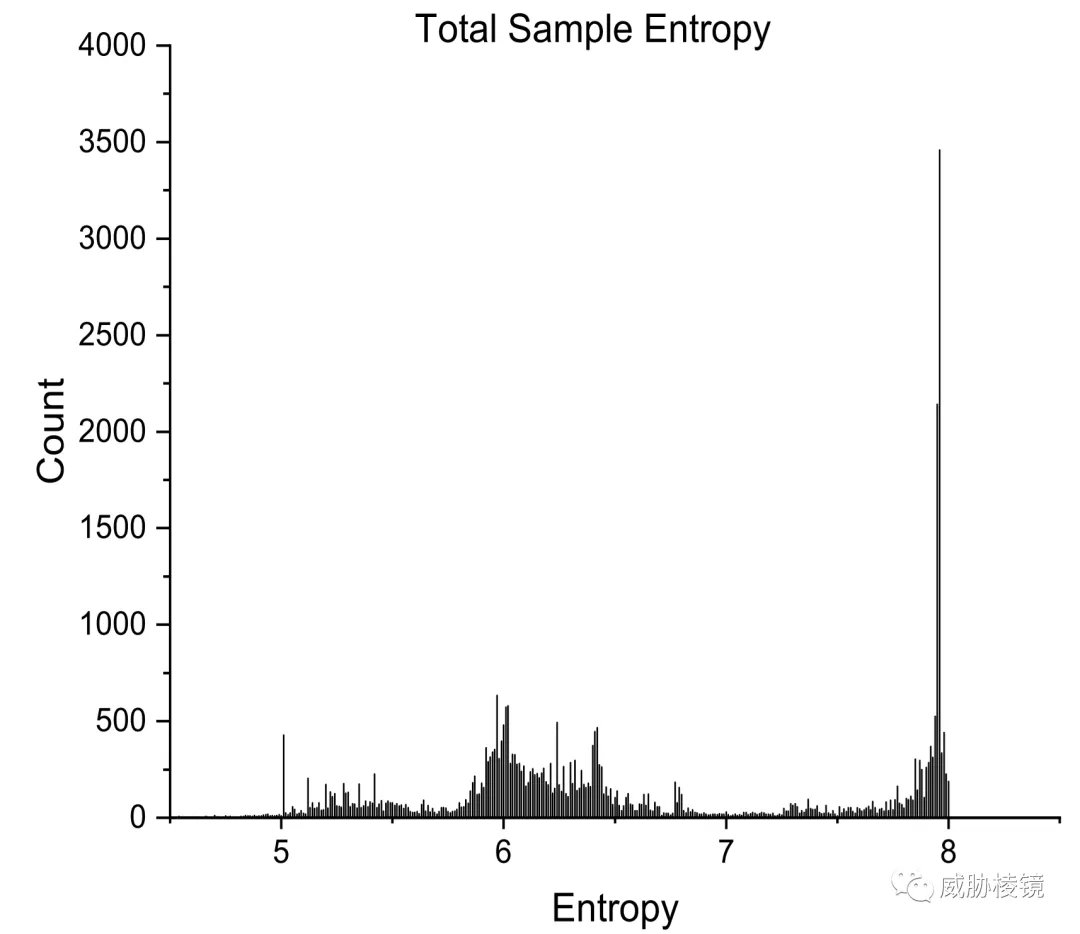
加壳
提醒
本人仅记录需要从文章中获取到的主要信息,文章还有接近一般的内容没有收到到本文中。
更多请点击【阅读原文】

若有收获,就点个赞吧
0 人点赞
