DataCon2020优秀解题思路分享:恶意代码分析方向(广州大学loom战队)
解题思路
冬奥会期间各类体育赛事一票难求,暗网中出现了很多高价倒卖门票的不法行为,一度使得虚拟货币市场交易十分火爆,挖型恶意代码的数量也呈爆发式增长,不少个人用户、企业用户受到感染,沦为免费矿工。为对抗挖木马,需要针对近期互联网上流行的恶意软件进行深入分析,研究并设计挖型恶意代码的检测方法,保卫广大用户的财产安全.
恶意代码分析赛道官方给出的训练集有4000个白样本和2000个黑样本(挖代码),测试集为6000个,每一个样本的格式为损坏的PE文件。其实我的解题思路和代码实现方案可以说都极其的简单(确实),但简单的步骤都分析的很详细。
特征工程
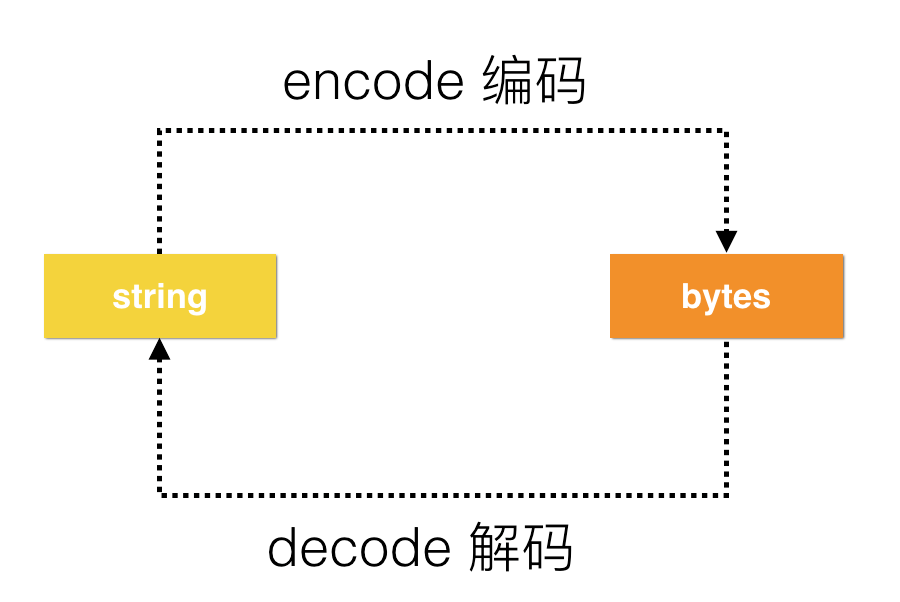
因为官方给出的数据为损坏的PE文件,故不能使用一些成熟的PE解析工具提取特征,故仅仅把PE文件当作一种二进制文件看待!通过以二进制字节码的形式读取文件,然后再解码成字符串,期望黑白样本中的字符串分布存在一些显著特征。
从上面图中可以分析出一些简单的结论,黑白样本中的字符串不论是种类上还是数量上确实存在一些差异,这也初步的验证了我的猜想,字节码直接解码成字符串这一操作可能有效,接下来就是详细分析黑白样本字符串分布情况。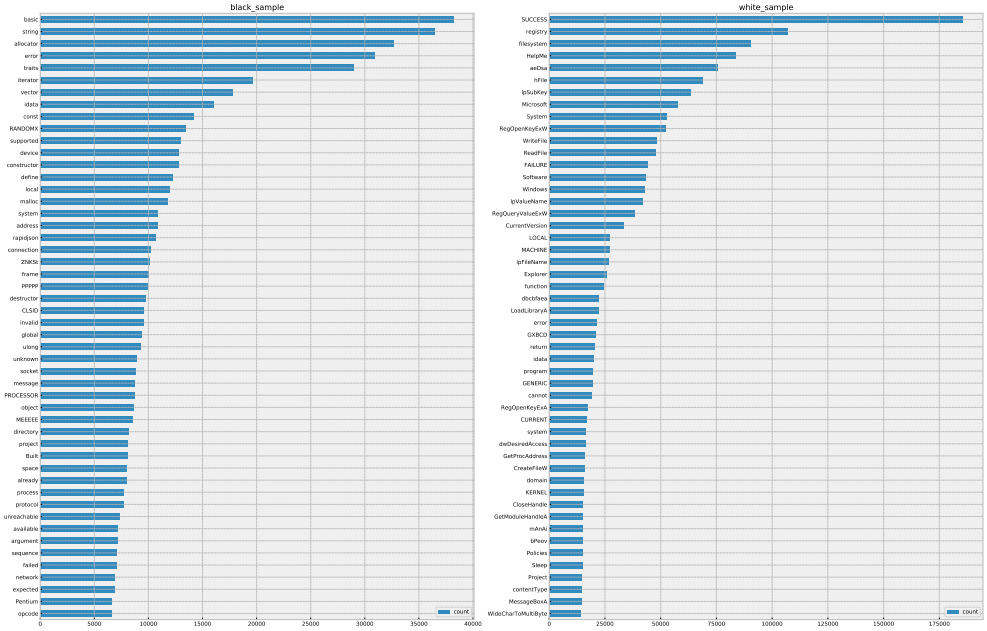
在详细分析阶段发现,黑样本包含网络、系统、读写文件之类的字符串偏多;白样本包含成功、本地、注册等相关的字符串偏多。到这里可以得出一个很重要的结论,黑白样本中字符串的分布情况存在显著差异。因此我的特征工程为: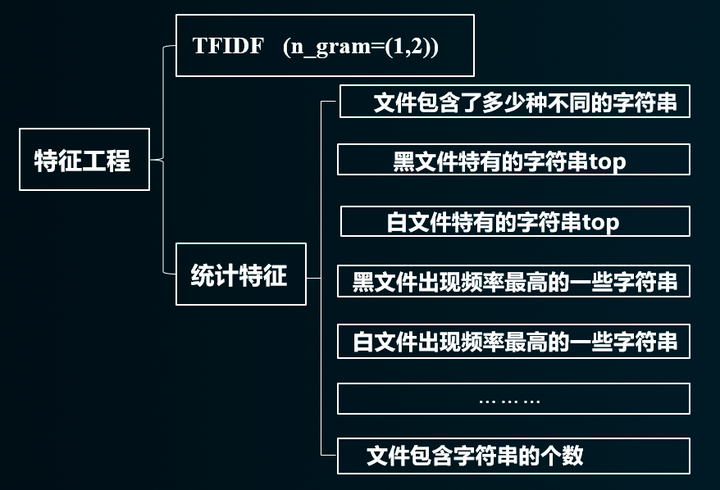
为了验证上述特征工程的有效性,使用t-SNE算法可视化特征矩阵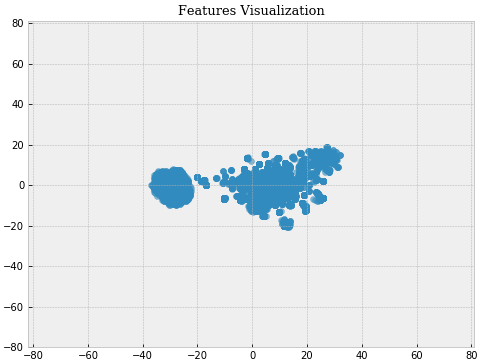
从图中可以看出,本方案的特征工程基本上使得所有的数据点呈现两个类簇,这说明该特征工程十分有效,而且就算主办方没有给出数据的标签,本方案也能使用无监督的聚类算法使得数据分为两个类簇,换句话说如果要解决原始问题可以把有监督学习转化为无监督学习,这一点我觉得是比较兴奋的。
算法的设计与结果展示
因为特征工程已经做的比较好了,所以对于模型的选择上不用过于纠结,选择一个比较擅长的模型即可,我这里选择了XGBoost模型。
因为主办方给出的数据才6000,训练样本还是比较小的,在本地实验的过程中发现,使用不同的随机种子,auc值在千分位点抖动的比较厉害。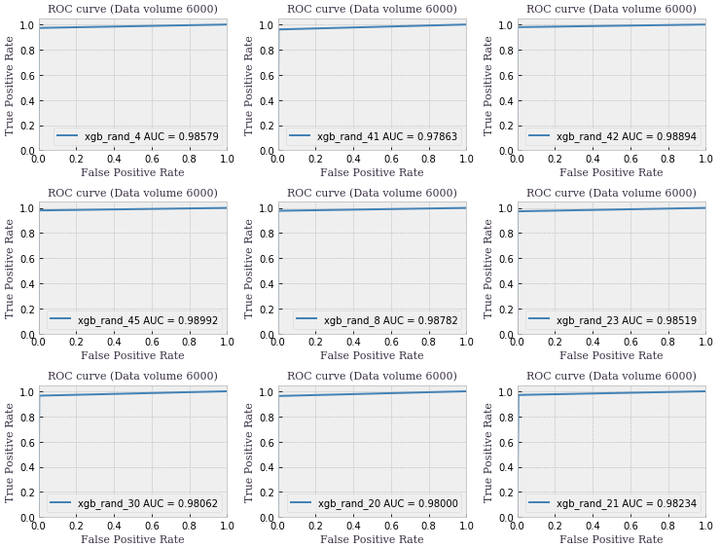
XGBoost模型以拟合残差为目的,所以在训练样本量比较小的情况下容易导致方差较大,根据方差偏差均衡理论,为了解决抖动这个问题,选择采用Bagging集成学习来减小方差,期望达到方差偏差均衡。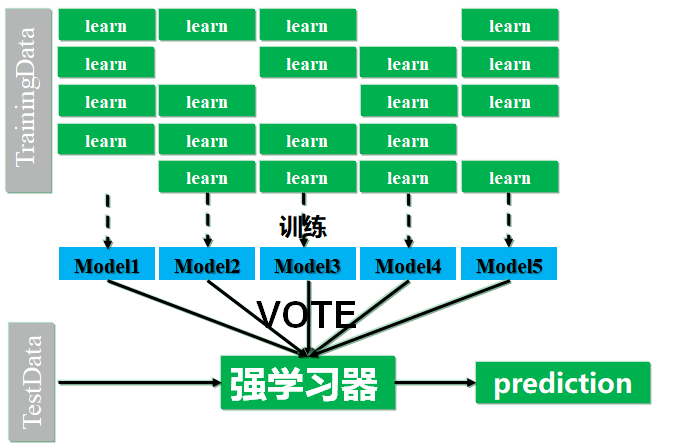
Bagging的主要思想就是,从训练数据集里随机抽取样本,用抽取到的样本训练模型,通过所有模型一起投票来确定最终的预测值。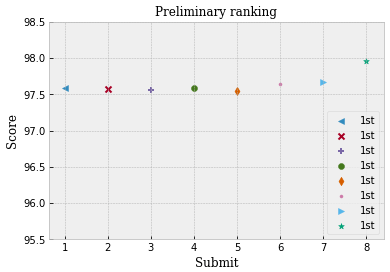
从提交结果的得分情况来看,前7次提交使用的都是单模型,也同样占据着排行榜第一,最后一次提交使用的是集成模型的结果,可以发现得分进一步的提升。
方案小结
- 特征工程简单,普适性很强,适用于EXE文件、ELF文件、dll文件等多种恶意代码存在的形式;
- 模型设计简单,搭配上述特征工程训练、推理速度超快,而且效果良好
可改进的方向
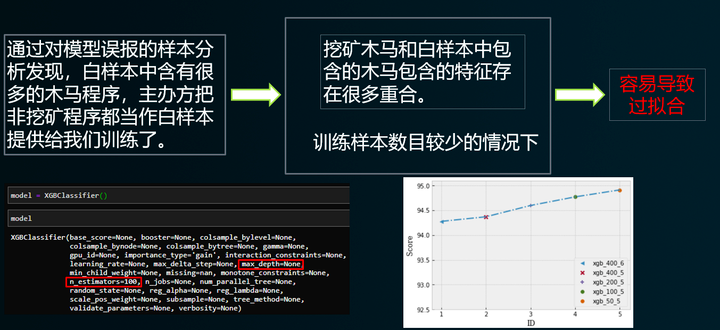
通过进一步弱化基模型的拟合能力,最后采用集成学习来提升整体模型的泛化能力。

若有收获,就点个赞吧
0 人点赞
