一、测试目的
1.前面的章节都是基于理论上的分析讲解,并没有深入到线上实际的数据库场景,我们都知道分库分表绝不是把数据库表按照预设的规则进行数据分片那么简单,分库分表仅仅只是一个开始,而后面有一大堆的细节要处理,如果我们对这些细节的掌握程度不够的话,那会让我们的开发工作带来非常多的麻烦。
2.在很多时候我所见过的线上数据库都不是预先进行了分库分表预设的,都是在运行到一定的数据量级了,已经意识到没办法再这样持续下去了才会想起分库分表的,那么此时数据又要如何迁移呢?又会遇到那一些问题呢?
3.ShardingSphere的四种分库分表分别策略有什么区别?
带着这此细节问题,我们下面即将进行一次完整的分库分表试验,以做到我们对分库分表有足够的了解和把握。
二、表数据量以及磁盘文件大小
1.用户表,数据量100万
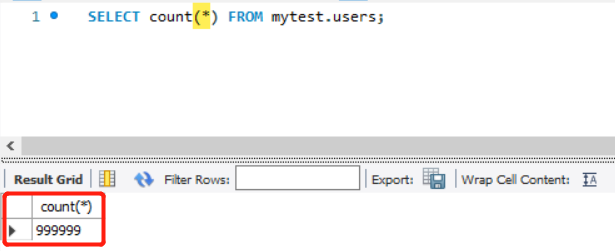
单表文件大小
单表查询效率,可以看到100万数据,在用到索引查询的情况下,效率是很快的,duration time是sql真正执行的时间,fetch time 就是数据在网络上传输花费的时间
2.产品表,数量1万

单表文件大小
单表查询效率
3.订单表,数量1000万
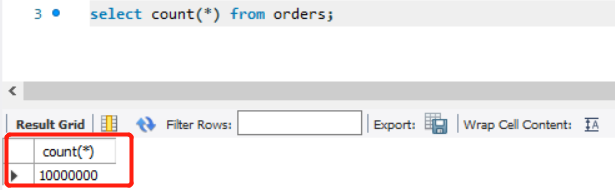
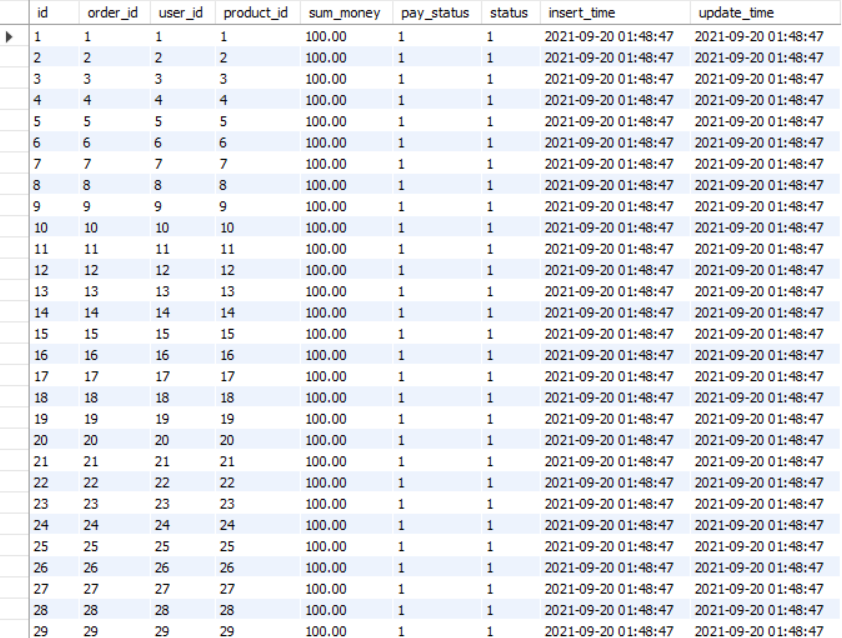

4.数据查询效率
从下面结果可以看出,在用到索引的情况下,1000万数据情况下mysql的执行效率还是非常高的:
下面将product_id索引移除看看效果,执行时间从0.031秒到0.922秒,执行要将近一秒,可以看得出,走索引与不走索引的差别是非常大的。
5.数据插入效率

6.数据更新效率

7.删除效率

三、进行分库分表
1.在了解了当前数据库的curd性能之后,我们着手开始订单表的分库分表操作
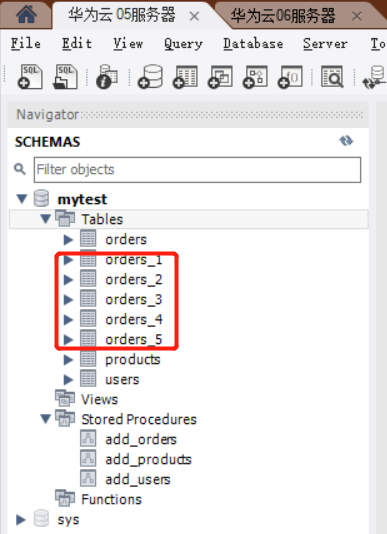
2.订单表分库分表确认
按照阿里巴巴的mysql分库分表建议是单表达到500W或者单表文件达到2G就建议进行分库分表,而且分库分表建议是规划好公司3年的增长量,也就是要考虑到公司未来3年的业务增长速度情况,假如公司订单表一年增长1000万,那么未来三年的话就要预计出3000万的订单数据表出来,再加上现已有的1000万订单就是4000万,当然我们要多预算一点,保守预估未来3年总订单达到5000万,按照这个要求,我们要分10个表,单表预估存500W。
订单这类数据其实是可以用时间进行分片的,毕竟以前的数据其实查询的是不多的,更多的往往是近三个月或者半年的数据,但这样也有一个问题就是表压力会很集中,其它的库以及表没起到分压的功能,所以这里用order_id字段进行hash取模分片处理,让各个库以及表进行平衡分压处理。
3.订单表设计
这里用两个数据库(A\B)进行分库,两个数据库在同一内网络,每个数据库里分5个订单表
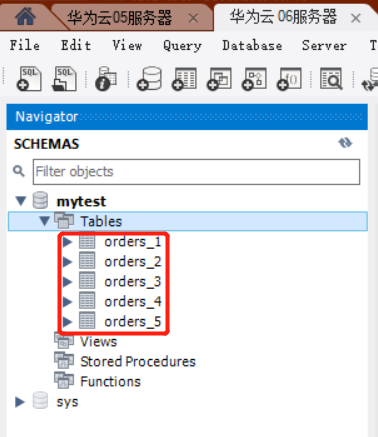
A库是完整的数据库,包括了用户表、产品表、订单表(orders1-5),而B库侧是仅有订单表(orders_1-5)的数据库。
1.逻辑表:orders
2.真实表:orders_1-5
3.绑定表:分片规则一致的主表和子表,如orders和orders_info
4.广播表:也叫公共表,将数据广播到各个库相同的表中去,如m1、m2中同时有两张t_dict表,insert操作会同时往m1、m2的t_dict表中都插入数据。
5.分片键:用于数据分片的字段,如order_id字段,如果没有分片键将会执行全路由,性能会很差。
6.分片算法:支持通过=、Between和in分片。由开发者去实现,灵活度很高。
7.分片策略:分片键+分片算法, 如orders$->{order_id%5}
四、在SpringBoot工程中引入ShardingSphere进行四种分片策略测试
1.依赖配置
<dependencyManagement><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-dependencies</artifactId><version>2.3.1.RELEASE</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><dependencies><!--spring-boot-starter--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId><version>2.4.2</version></dependency><!--spring-boot-starter-test--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>2.4.2</version><scope>test</scope></dependency><!--mysql--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.20</version></dependency><!--引入mybatis--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.1.3</version></dependency><!--引入sharding-jdbc--><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.1</version></dependency><!--引入junit--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency></dependencies><!--打包jar--><build><finalName>service-common</finalName><plugins><!--spring-boot-maven-plugin--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.4.2</version><!--解决打包出来的jar文件中没有主清单属性问题--><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin></plugins></build>
2.单库多表的yml配置,inline方式
server:port: 8001spring:application:name: service-commonshardingsphere:datasource:names: m1 #配置数据源m1:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://139.9.51.215:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888sharding:tables:orders: #定义orders逻辑表actual-data-nodes: m1.orders_$->{1..5} #配置所有的真实分表key-generator: #这里配置分片主键生成策略type: SNOWFLAKE #分片键生成算法column: order_id #选择要为那一个字段生成idprops:worker:id: 1 #雪花算法参数,可选,用于区分不同微服务所生成的雪花idtable-strategy: #这里配置分表策略inline: #选择inline策略方式sharding-column: order_id #根据那一个分片键进行分表algorithm-expression: orders_$->{order_id%5+1} #配置分片算法props:sql:show: true #开启sql日志输出main:allow-bean-definition-overriding: true
3.多库多表的yml配置,inline方式
server:port: 8001spring:application:name: service-commonshardingsphere:datasource:names: m1,m2 #配置数据源m1:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://139.9.51.215:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888m2:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://124.71.7.195:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888sharding:tables:orders: #定义orders逻辑表actual-data-nodes: m$->{1..2}.orders_$->{1..5} #配置所有的真实分表key-generator: #这里配置分片主键生成策略type: SNOWFLAKE #分片键生成算法column: order_id #选择要为那一个字段生成idprops:worker:id: 1 #雪花算法参数,可选,用于区分不同微服务所生成的雪花idtable-strategy: #这里配置分表策略inline: #选择inline策略方式sharding-column: order_id #根据那一个分片键进行分表algorithm-expression: orders_$->{order_id%5+1} #配置分片算法database-strategy: #这里配置分库策略inline: #选择inline分库方式sharding-column: order_id #根据那一个分片键进行分库algorithm-expression: m$->{order_id%2+1} #配置分库算法props:sql:show: true #开启sql日志输出main:allow-bean-definition-overriding: true
4.多库多表的yml配置,standard模式(标准分片模式,支持对单个表字段进行自定义算法分片)
server:port: 8001spring:application:name: service-commonshardingsphere:datasource:names: m1,m2 #配置数据源m1:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://139.9.51.215:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888m2:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://124.71.7.195:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888sharding:tables:orders: #定义orders逻辑表actual-data-nodes: m$->{1..2}.orders_$->{1..5} #配置所有的真实分表key-generator: #这里配置分片主键生成策略type: SNOWFLAKE #分片键生成算法column: order_id #选择要为那一个字段生成idprops:worker:id: 1 #雪花算法参数,可选,用于区分不同微服务所生成的雪花idtable-strategy: #这里配置分表策略standard: #选择standard策略方式sharding-column: order_id #根据那一个分片键进行分表precise-algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyPreciseTableShardingAlgorithm #实现表逻辑的精准查找range-algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyRangeTableShardingAlgorithm #实现表逻辑的范围查找database-strategy: #这里配置分库策略standard: #选择standard分库方式sharding-column: order_id #根据那一个分片键进行分库precise-algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyPreciseDSShardingAlgorithm #实现数据库精确算法range-algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyRangeDSShardingAlgorithm #实现数据库范围算法props:sql:show: true #开启sql日志输出main:allow-bean-definition-overriding: true
5.多库多表的yml配置,complex模式(复杂分片模式,支持对多个表字段进行自定义算法分片)
server:port: 8001spring:application:name: service-commonshardingsphere:datasource:names: m1,m2 #配置数据源m1:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://139.9.51.215:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888m2:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://124.71.7.195:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888sharding:tables:orders: #定义orders逻辑表actual-data-nodes: m$->{1..2}.orders_$->{1..5} #配置所有的真实分表key-generator: #这里配置分片主键生成策略type: SNOWFLAKE #分片键生成算法column: order_id #选择要为那一个字段生成idprops:worker:id: 1 #雪花算法参数,可选,用于区分不同微服务所生成的雪花idtable-strategy: #这里配置分表策略complex: #选择complex策略方式sharding-columns: order_id, user_id #根据那几个分片键进行分表algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyComplexTableShardingAlgorithm #实现表逻辑的精准查找database-strategy: #这里配置分库策略complex: #选择complex分库方式sharding-columns: order_id, user_id #根据那几个分片键进行分库algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyComplexDSShardingAlgorithm #实现数据库精确算法props:sql:show: true #开启sql日志输出main:allow-bean-definition-overriding: true
如下图,用user_id进行查找,也仅会执行一次数据库查找,也就是user_id也被提前分配到了指定的库与表里了。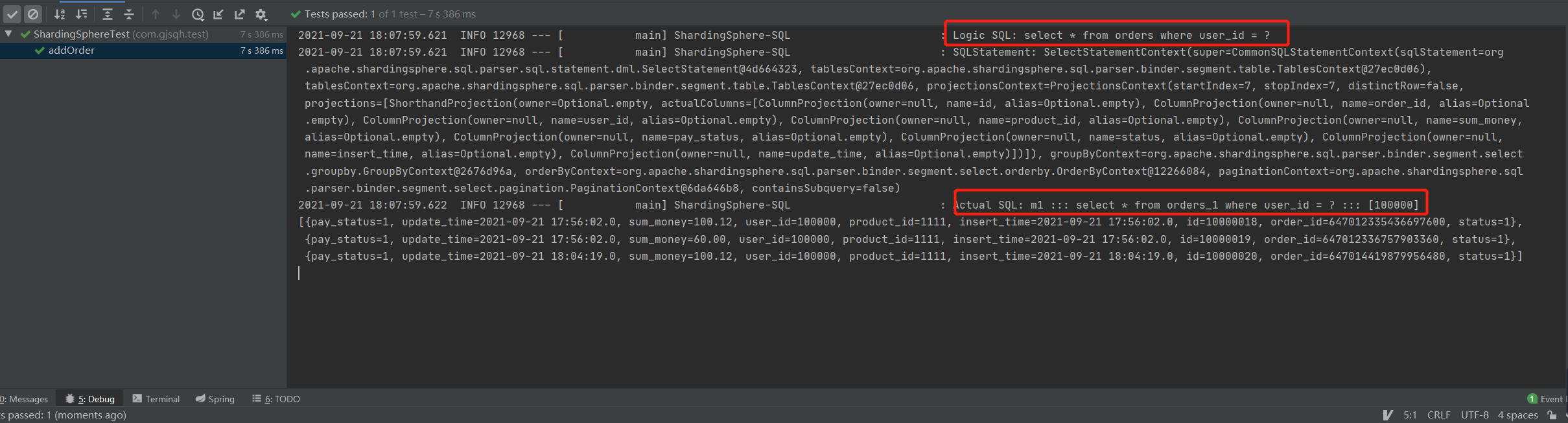
6.多库多表的yml配置,hint模式(强制路由分片模式)
没有分片键,只需要配置一个算法类,例如强制只查找某一个表,如orders_2
server:port: 8001spring:application:name: service-commonshardingsphere:datasource:names: m1,m2 #配置数据源m1:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://139.9.51.215:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888m2:type: com.zaxxer.hikari.HikariDataSource #采用hikari连接池driver-class-name: com.mysql.cj.jdbc.Driver #配置driver-classjdbc-url: jdbc:mysql://124.71.7.195:3306/mytest?serverTimezone=UTC&allowMultiQueries=true&characterEncoding=utf-8username: azhipassword: azhi2021888sharding:tables:orders: #定义orders逻辑表actual-data-nodes: m$->{1..2}.orders_$->{1..5} #配置所有的真实分表key-generator: #这里配置分片主键生成策略type: SNOWFLAKE #分片键生成算法column: order_id #选择要为那一个字段生成idprops:worker:id: 1 #雪花算法参数,可选,用于区分不同微服务所生成的雪花idtable-strategy: #这里配置分表策略hint: #选择hint策略方式algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyHintTableShardingAlgorithm #实现表逻辑的精准查找database-strategy: #这里配置分库策略standard: #选择standard分库方式sharding-column: order_id #根据那一个分片键进行分库precise-algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyPreciseDSShardingAlgorithm #实现数据库精确算法range-algorithm-class-name: com.gjsqh.shardingSphere.algorithem.MyRangeDSShardingAlgorithm #实现数据库范围算法props:sql:show: true #开启sql日志输出main:allow-bean-definition-overriding: true
@Testpublic void queryCourseByHint(){//通过HintManager只查找某个表,如orders_2HintManager hintManager = HintManager.getInstance();hintManager.addTableShardingValue("orders",2);List<Course> courses = courseMapper.selectList(null);courses.forEach(course -> System.out.println(course));hintManager.close();}
7.简单测试用mapper
@Servicepublic interface OrdersMapper {@Insert({"insert into orders( user_id, product_id, sum_money,pay_status)" +" values(#{user_id},#{product_id}, 100.12,1);"})int addOrder(@Param("user_id") long user_id,@Param("product_id") long product_id);@Select("select * from orders where id = #{id}")List<Map<String,Object>> getOrdersById(@Param("id")long id);@Select("select * from orders where order_id = #{order_id}")Map<String,Object> getOrdersByOrderId(@Param("order_id")long order_id);@Select("select * from orders where user_id = #{user_id}")List<Map<String,Object>> getOrdersByUserId(@Param("user_id")long user_id);@Select("select * from orders where sum_money >= #{sum_money1} and sum_money <= #{sum_money2} order by insert_time desc")List<Map<String,Object>> getOrdersByMoney(@Param("sum_money1")double sum_money1,@Param("sum_money2")double sum_money2);}
8.ShardingSphereTest
@RunWith(SpringRunner.class)@SpringBootTestpublic class ShardingSphereTest {@ResourceOrdersMapper ordersMapper;@ResourceUsersMapper usersMapper;@Testpublic void addOrder(){/*int count = 0;for(int i =0;i<10;i++){count = ordersMapper.addOrder(100000,1111);System.out.println("执行结果"+count);}*//*count = usersMapper.addUsers(1000005,"phone","name");System.out.println("执行结果"+count);*//*List<Map<String,Object>> list_map = ordersMapper.getOrdersById(10000024);System.out.println(list_map);*/Map<String,Object> map = ordersMapper.getOrdersByOrderId(647012336871149569L);System.out.println(map);/*List<Map<String,Object>> list_map = ordersMapper.getOrdersByUserId(100000);System.out.println(list_map);*//*List<Map<String,Object>> list_map = ordersMapper.getOrdersByMoney(50,80);System.out.println(list_map);*/}}
getOrdersById、getOrdersByUserId、getOrdersByMoney这三个都是要搜索所有表的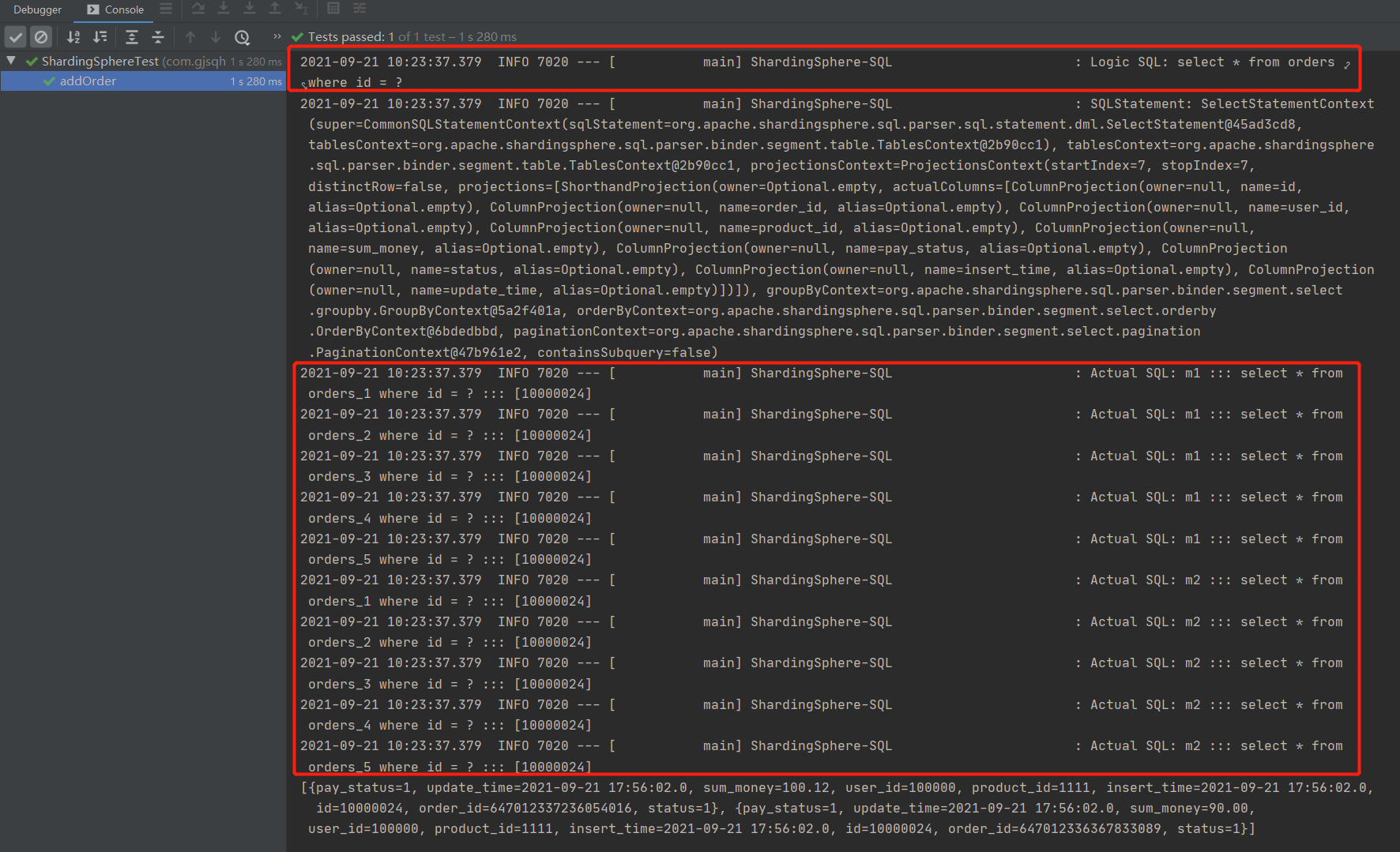
getOrdersByOrderId是通过主键OrderId查找的,ShardingSphere直接知道数据放在那里的,只查找一张表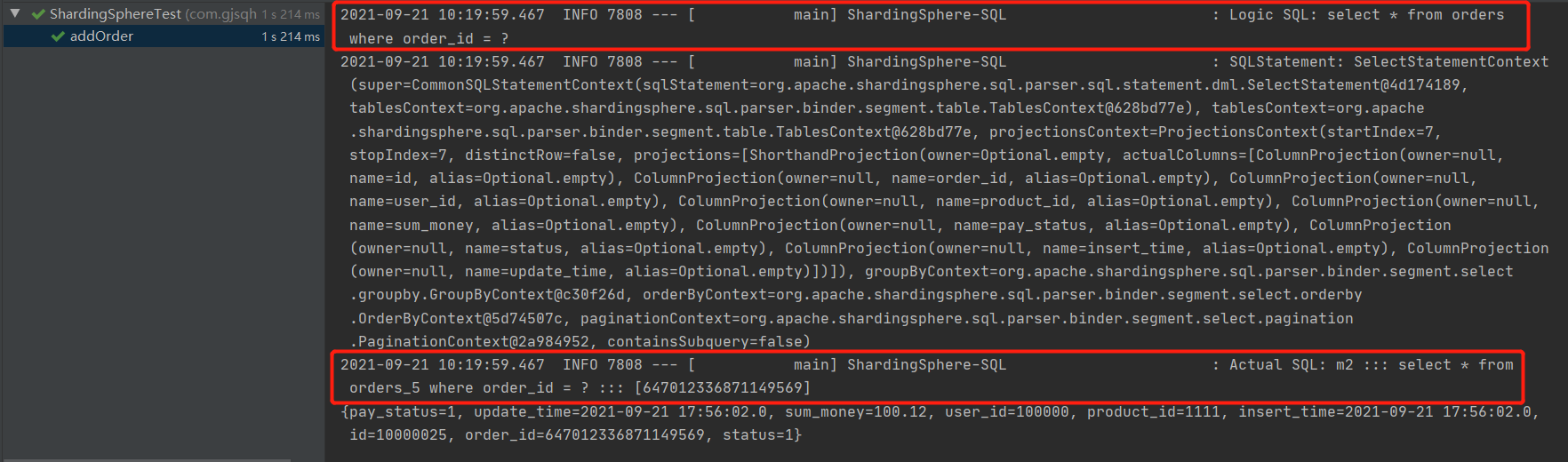
五、广播表、绑定表
六、分库分表后所带来的SQL功能限制
1.单条新增测试
2.批量新增测试
3.范围查询测试
inline方式不支持,其余的支持
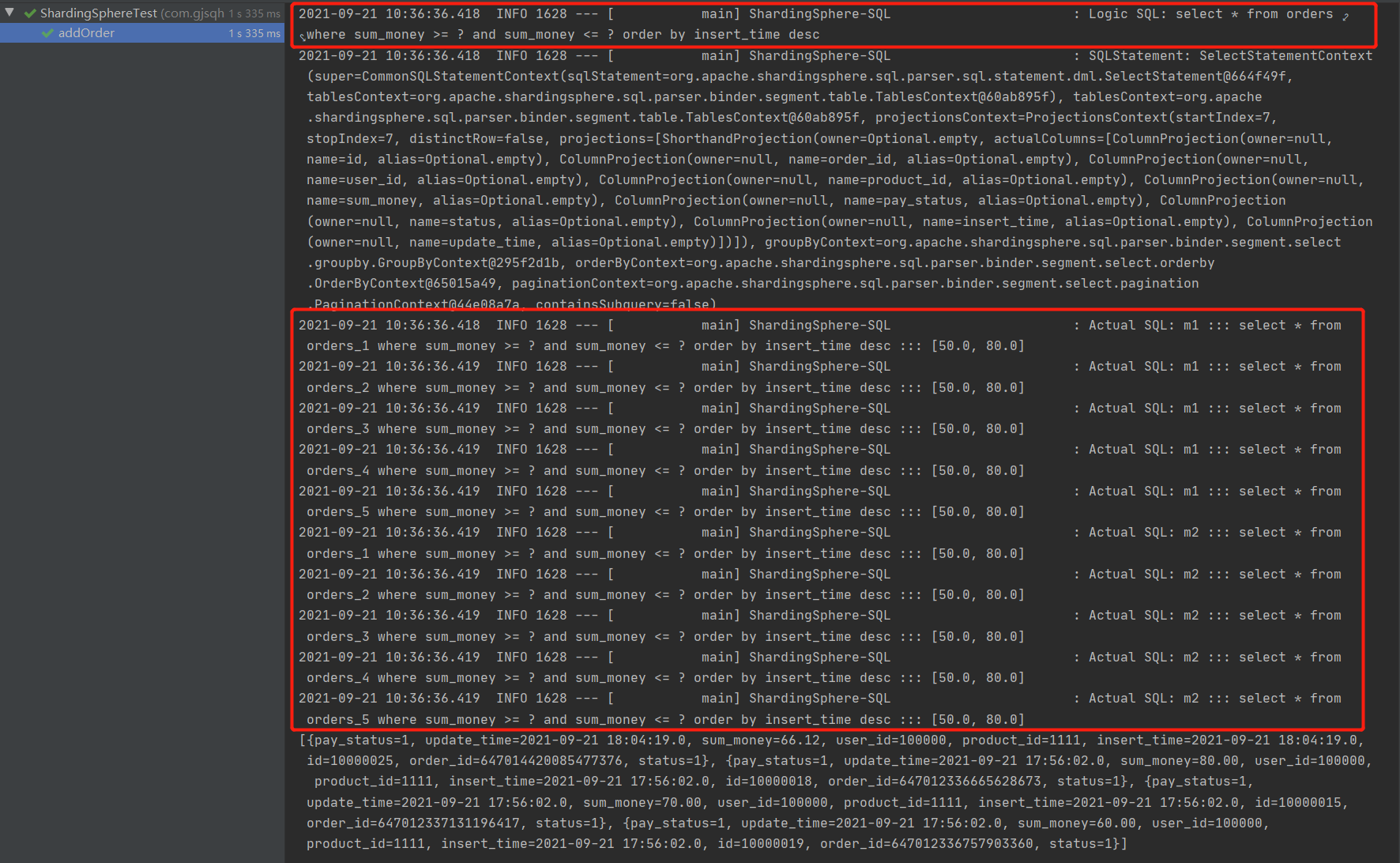
1.非主键范围查找,inline分片方式支持非主键范围查找
@Select("select * from orders where sum_money >= #{sum_money1} and sum_money <= #{sum_money2} order by insert_time desc")List<Map<String,Object>> getOrdersByMoney(@Param("sum_money1")double sum_money1,@Param("sum_money2")double sum_money2);
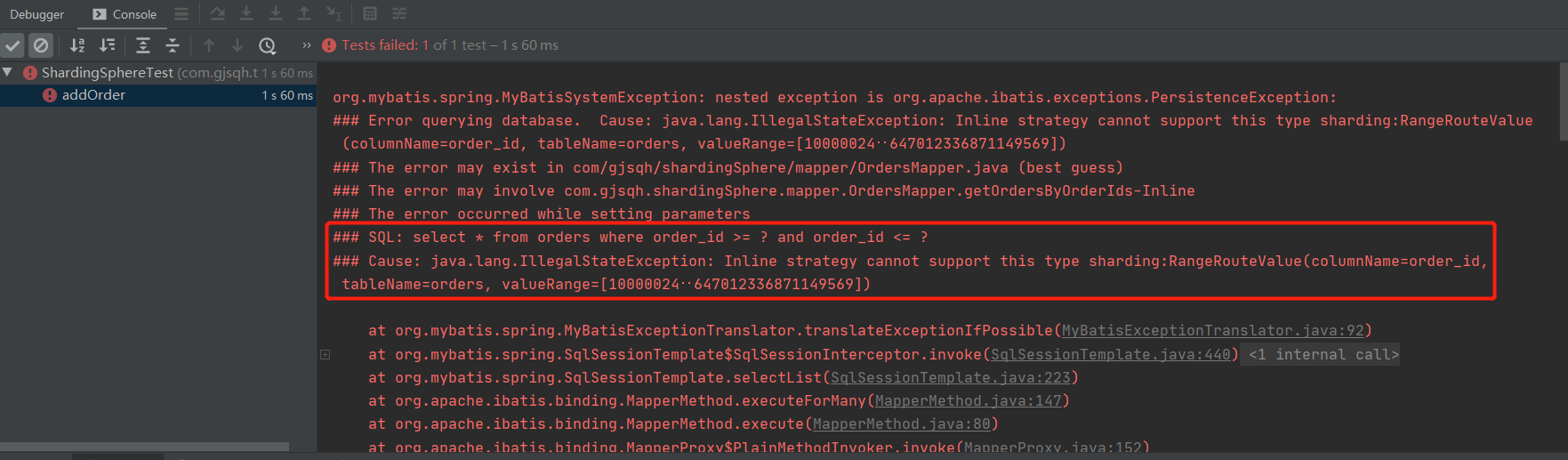
2.主键范围查找,inline分片方式不支持主键范围查找
@Select("select * from orders where order_id >= #{order_id1} and order_id <= #{order_id2}")List<Map<String,Object>> getOrdersByOrderIds(@Param("order_id1")long order_id1,@Param("order_id2")long order_id2);
4.分页查询测试
5.join查询测试
6.GroupBy查询测试
7.事务测试
支持

若有收获,就点个赞吧
0 人点赞
