前面我们前面做的一大段实验,目的是为了大家能够理解MySQL的主从集群。而主从集群的作用,在我们开发角度更大的是作为读写分离的支持,也是我们后面学习ShardingSphere的重点。我们这一部分就来介绍下分库分表。
分库分表就是业务系统将数据写请求分发到master节点,而读请求分发到slave节点的一种方案,可以大大提高整个数据库集群的性能。但是要注意,分库分表的一整套逻辑全部是由客户端自行实现的。而对于MySQL集群,数据主从同步是实现读写分离的一个必要前提条件。
1、分库分表有什么用
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目 的。
例如:微服务架构中,每个服务都分配一个独立的数据库,这就是分库。而对一些业务日志表,按月拆分成不同的表,这就是分表。
2、分库分表的方式
分库分表包含分库和分表 两个部分,而这两个部分可以统称为数据分片,其目的都是将数据拆分成不同的存储单元。另外,从分拆的角度上,可以分为垂直分片和水平分片。
- 垂直分片: 按照业务来对数据进行分片,又称为纵向分片。他的核心理念就是转库专用。在拆分之前,一个数据库由多个数据表组成,每个表对应不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库或表中,从而将压力分散至不同的数据库或表。例如,下图将用户表和订单表垂直分片到不同的数据库:
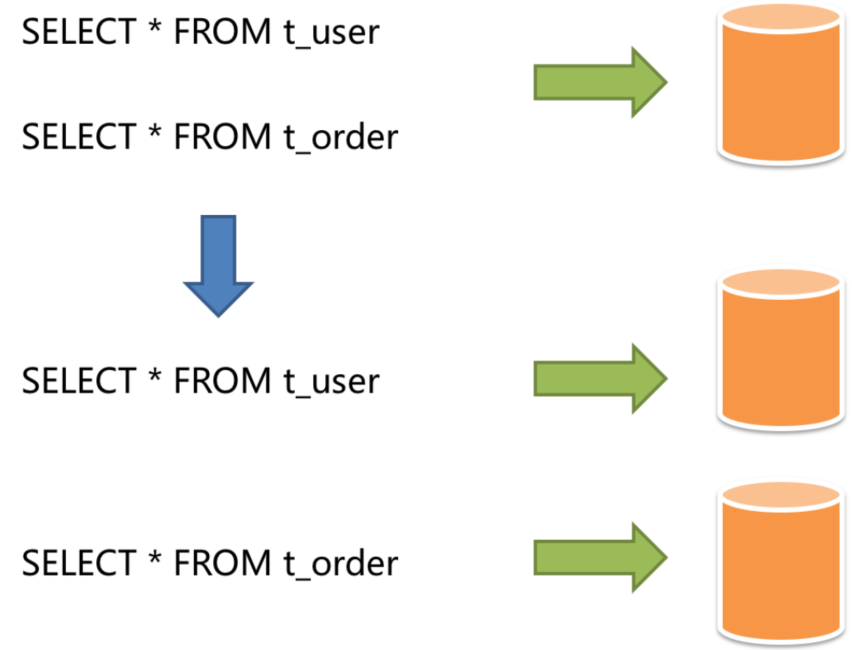
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对业务需求快速变化的。而且,他也无法真正的解决单点数据库的性能瓶颈。垂直分片可以缓解数据量和访问量带来的问题,但无法根治。如果垂直分片之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
- 水平分片:又称横向分片。相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。例如,像下图根据主键机构分片。
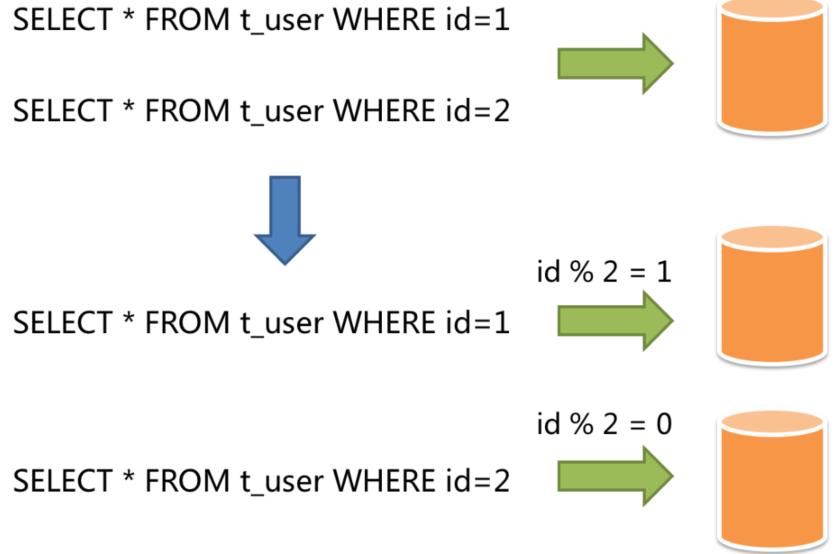
常用的分片策略有:
取余\取模 : 优点 均匀存放数据,缺点 扩容非常麻烦
按照范围分片 : 比较好扩容, 数据分布不够均匀
按照时间分片 : 比较容易将热点数据区分出来。
按照枚举值分片 : 例如按地区分片
按照目标字段前缀指定进行分区:自定义业务规则分片
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库水平分表方案
3、分库分表的缺点
虽然数据分片解决了性能、可用性以及单点备份恢复等问题,但是分布式的架构在获得收益的同时,也引入了非常多新的问题。
- 事务一致性问题
原本单机数据库有很好的事务机制能够帮我们保证数据一致性。但是分库分表后,由于数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题。
- 跨节点关联查询问题
在没有分库时,我们可以进行很容易的进行跨表的关联查询。但是在分库后,表被分散到了不同的数据库,就无法进行关联查询了。
这时就需要将关联查询拆分成多次查询,然后将获得的结果进行拼装。
- 跨节点分页、排序函数
跨节点多库进行查询时,limit分页、order by排序等问题,就变得比较复杂了。需要先在不同的分片节点中将数据 进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。
这时非常容易出现内存崩溃的问题。
- 主键避重问题
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据 库生成的ID无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。
- 公共表处理
实际的应用场景中,参数表、数据字典表等都是数据量较小,变动少,而且属于高频联合查询的依赖表。这一类表一般就需要在每个数据库中都保存一份,并且所有对公共表的操作都要分发到所有的分库去执行。
- 运维工作量
面对散乱的分库分表之后的数据,应用开发工程师和数据库管理员对数据库的操作都变得非常繁重。对于每一次数据读写操作,他们都需要知道要往哪个具体的数据库的分表去操作,这也是其中重要的挑战之一。
4、什么时候需要分库分表?
在阿里巴巴公布的开发手册中,建议MySQL单表记录如果达到500W这个级别,或者单表容量达到2GB,一般就建议进行分库分表。而考虑到分库分表需要对数据进行再平衡,所以如果要使用分库分表,就要在系统设计之初就详细考虑好分库分表的方案,这里要分两种情况。
一般对于用户数据这一类后期增长比较缓慢的数据,一般可以按照三年左右的业务量来预估使用人数,按照标准预设好分库分表的方案。
而对于业务数据这一类增长快速且稳定的数据,一般则需要按照预估量的两倍左右预设分库分表方案。并且由于分库分表的后期扩容是非常麻烦的,所以在进行分库分表时,尽量根据情况,多分一些表。最好是计算一下数据增量,永远不用增加更多的表。
另外,在设计分库分表方案时,要尽量兼顾业务场景和数据分布。在支持业务场景的前提下,尽量保证数据能够分得更均匀。
最后,一旦用到了分库分表,就会表现为对数据查询业务的灵活性有一定的影响,例如如果按userId进行分片,那按age来进行查询,就必然会增加很多麻烦。如果再要进行排序、分页、聚合等操作,很容易就扛不住了。这时候,都要尽量在分库分表的同时,再补充设计一个降级方案,例如将数据转存一份到ES,ES可以实现更灵活的大数据聚合查询。
5、常见的分库分表组件
由于分库分表之后,数据被分散在不同的数据库、服务器。因此,对数据的操作也就无法通过常规方式完成,并且 它还带来了一系列的问题。好在,这些问题不是所有都需要我们在应用层面上解决,市面上有很多中间件可供我们 选择,我们来了解一下它。
- shardingsphere 官网地址:https://shardingsphere.apache.org/document/current/cn/overview/
Sharding-JDBC是当当网研发的开源分布式数据库中间件,他是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和 数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
这也是我们这次学习的重点。
- mycat 官网地址: http://www.mycat.org.cn/
基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得MYCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,我们能看到更远。业界优秀的开源项目和创新思路被广泛融入到MYCAT的基因中,使得MYCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。
MyCAT虽然是从阿里的技术体系中出来的,但是跟阿里其实没什么关系。
- DBLE 官网地址:https://opensource.actionsky.com/
该网站包含几个重要产品。其中分布式中间件可以认为是MyCAT的一个增强版,专注于MySQL的集群化管理。另外还有数据传输组件和分布式事务框架组件可供选择。

若有收获,就点个赞吧
0 人点赞
