我们之前的MySQL服务集群,都是使用MySQL自身的功能来搭建的集群。但是这样的集群,不具备高可用的功能。即如果是MySQL主服务挂了,从服务是没办法自动切换成主服务的。而如果要实现MySQL的高可用,需要借助一些第三方工具来实现。
常见的MySQL集群方案有三种: MMM、MHA、MGR。这三种高可用框架都有一些共同点:
- 对主从复制集群中的Master节点进行监控
- 自动的对Master进行迁移,通过VIP。
-
1、MMM
MMM(Master-Master replication managerfor Mysql,Mysql主主复制管理器)是一套由Perl语言实现的脚本程序,可以对mysql集群进行监控和故障迁移。他需要两个Master,同一时间只有一个Master对外提供服务,可以说是主备模式。
他是通过一个VIP(虚拟IP)的机制来保证集群的高可用。整个集群中,在主节点上会通过一个VIP地址来提供数据读写服务,而当出现故障时,VIP就会从原来的主节点漂移到其他节点,由其他节点提供服务。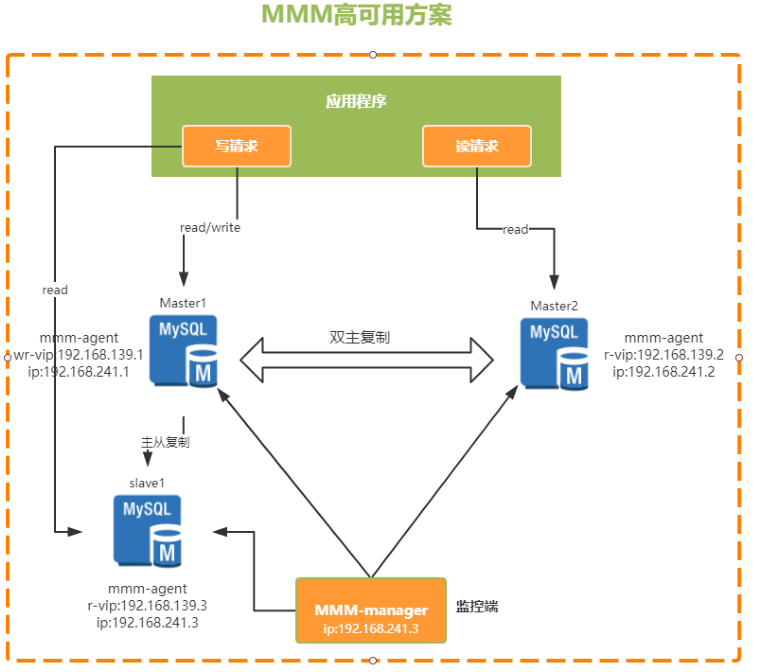
优点: 提供了读写VIP的配置,使读写请求都可以达到高可用
- 工具包相对比较完善,不需要额外的开发脚本
- 完成故障转移之后可以对MySQL集群进行高可用监控
缺点:
- 故障简单粗暴,容易丢失事务,建议采用半同步复制方式,减少失败的概率
- 目前MMM社区已经缺少维护,不支持基于GTID的复制
适用场景:
- 读写都需要高可用的
-
2、MHA
Master High Availability Manager and Tools for MySQL。是由日本人开发的一个基于Perl脚本写的工具。这个工具专门用于监控主库的状态,当发现master节点故障时,会提升其中拥有新数据的slave节点成为新的master节点,在此期间,MHA会通过其他从节点获取额外的信息来避免数据一致性方面的问题。MHA还提供了mater节点的在线切换功能,即按需切换master-slave节点。MHA能够在30秒内实现故障切换,并能在故障切换过程中,最大程度的保证数据一致性。在淘宝内部,也有一个相似的TMHA产品。
MHA是需要单独部署的,分为Manager节点和Node节点,两种节点。其中Manager节点一般是单独部署的一台机器。而Node节点一般是部署在每台MySQL机器上的。 Node节点得通过解析各个MySQL的日志来进行一些操作。
Manager节点会通过探测集群里的Node节点去判断各个Node所在机器上的MySQL运行是否正常,如果发现某个Master故障了,就直接把他的一个Slave提升为Master,然后让其他Slave都挂到新的Master上去,完全透明。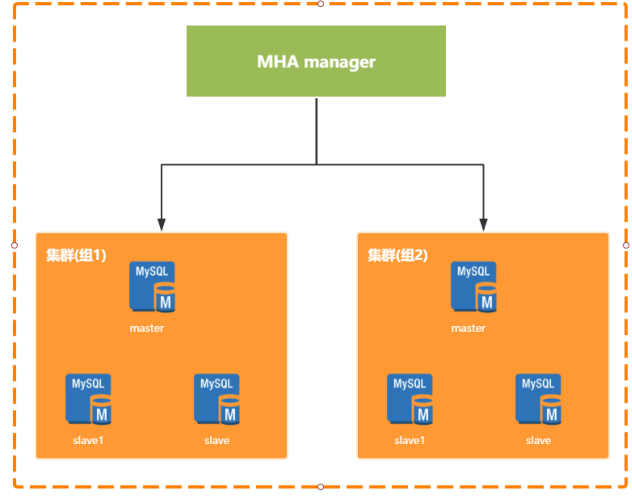
优点: MHA除了支持日志点的复制还支持GTID的方式
- 同MMM相比,MHA会尝试从旧的Master中恢复旧的二进制日志,只是未必每次都能成功。如果希望更少的数据丢失场景,建议使用MHA架构。
缺点:
MHA需要自行开发VIP转移脚本。
MHA只监控Master的状态,未监控Slave的状态
3、MGR
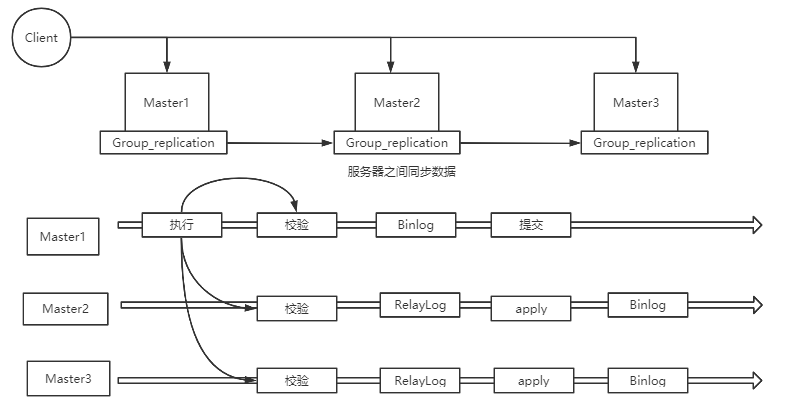
MGR:MySQL Group Replication。 是MySQL官方在5.7.17版本正式推出的一种组复制机制。主要是解决传统异步复制和半同步复制的数据一致性问题。
由若干个节点共同组成一个复制组,一个事务提交后,必须经过超过半数节点的决议并通过后,才可以提交。引入组复制,主要是为了解决传统异步复制和半同步复制可能产生数据不一致的问题。MGR依靠分布式一致性协议(Paxos协议的一个变体),实现了分布式下数据的最终一致性,提供了真正的数据高可用方案(方案落地后是否可靠还有待商榷)。
支持多主模式,但官方推荐单主模式:
- 多主模式下,客户端可以随机向MySQL节点写入数据
- 单主模式下,MGR集群会选出primary节点负责写请求,primary节点与其它节点都可以进行读请求处理.
优点:
- 基本无延迟,延迟比异步的小很多
- 支持多写模式,但是目前还不是很成熟
- 数据的强一致性,可以保证数据事务不丢失
缺点:
- 仅支持innodb,且每个表必须提供主键。
- 只能用在GTID模式下,且日志格式为row格式。
适用的业务场景:
- 对主从延迟比较敏感
- 希望对对写服务提供高可用,又不想安装第三方软件
- 数据强一致的场景

若有收获,就点个赞吧
0 人点赞
