总体来说
验证码识别包括2个部分,一部分是图像处理,一部分是图像识别,图像处理的好坏从根本上决定了最后是否能够识别成功。
图像处理
观察验证码 尝试处理














例如这8张图,我们应该观察出以下几个特征
- 图片存在噪点
- 存在干扰线
- 都是大写字母
- 字母是斜体
- 字母之间又粘连现象
- 图片是彩色 但字母颜色较深
下面从信息与算法的角度展开图像处理的介绍
处理噪点
一般有两种处理噪点的方法。
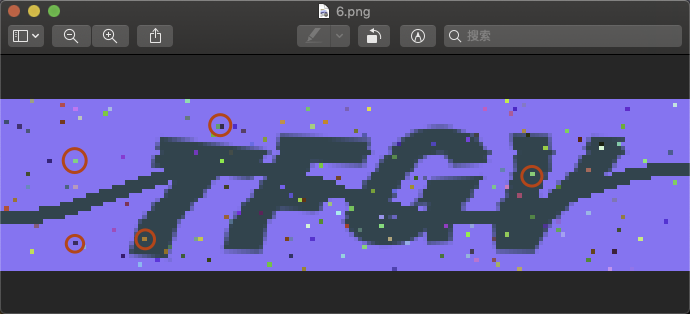
一种是 8临域去噪点法,原理是通过判断像素点与临近8个背景像素点的区别来去除噪点,当周围超过n个(一般设置5~7)与自身不同当像素时,则判断这个像素为噪点,将噪点转化为与周围大多数像素一样的像素。这次实战感受非常深的一点 就是 从众法则:只要和大多数一样 那就看上去没有什么错。
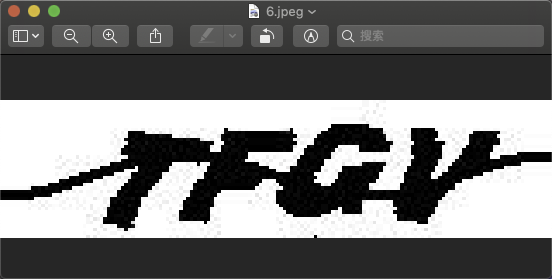
第二种是连通域去噪点法,(也称种子染色法、洪水去噪点法…),原理就像它的名字,计算连通域的面积,如果面积太小就认为它是噪点,同理将它去除。

如果你仔细思考两种算法,应该会有这样的感觉:连通域去噪点法似乎好于八临域去噪点法,因为它可以除去更大的噪点。事实上确实是这样的,但是可以通过多次使用八临域去噪点法来达到相似的效果,不过这样造成的其他影响是识别部分变得比较臃肿,多次使用后图形边缘的曲率变化会逐渐减小,渐渐拥有“圆”的轮廓。
干扰线处理

看到干扰线,我曾经冒出过这样的想法,就是能不能从图片的边缘定位干扰线,然后根据其走势将其去除呢?
世界上干扰线又千万种,如果我们更具趋势来写算法,那么这个算法的复用性就太低了一点,那么能不能退而求其次呢?于是想到了判断一列种连续黑色相似点的个数,如果连续个数不超过4(通常2~6)那么我们便认为这是干扰线的一部分,同理将其变为其他的大多数一样的像素点。
斜体矫正
斜体矫正的目的是为了更好的分割与识别。原理是平移,将每一行向左或向右平移不同距离,最后形成矫正的效果。pans就是矫正列表,正左负右平移。pans列表的元素个数需要是图片的高度,例子中图片 height 是40.
图像分割
我的思路是扫描空白的列,选取两个边缘空白列中间的列数组成一个包含若干个数组的列表,判断列表的长度,去除数组长度小于3(列)的数组。如果列表长度大于所需要的列表长度(这个例子中是4),那么返回最长的4个,如果列表个数小于4个,判断其中数组长度 大于所需要数组长度1.3 小于所需要数组长度2.3的列表,将其平均分为2个列表,同理大于所需要数组长度2.3倍的列表将会被平均分为3份。

若有收获,就点个赞吧
0 人点赞
