合并数组
合并列 - join
注意 必须行索引有相同 列索引有所不同才能合并在一起
>>> a = pd.DataFrame(np.arange(12).reshape(3,4),columns=list('wxyz'))>>> aw x y z0 0 1 2 31 4 5 6 72 8 9 10 11>>> b = pd.DataFrame(np.arange(4).reshape(2,2),columns=list('sb'))>>> bs b0 0 11 2 3>>> a.join(b)w x y z s b0 0 1 2 3 0.0 1.01 4 5 6 7 2.0 3.02 8 9 10 11 NaN NaN>>> b.join(a)s b w x y z0 0 1 0 1 2 31 2 3 4 5 6 7
合并行 - merge
没有看的很懂http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html
在a的下方拼接b:
import pandas as pdimport numpy as npa = pd.DataFrame(np.arange(9).reshape(3,3), columns=list('abc'))b = pd.DataFrame(np.arange(12,24).reshape(4,3), columns=list('abc'))print(a.merge(b,how='outer'))---------output---------------a b c0 0 1 21 3 4 52 6 7 83 12 13 144 15 16 175 18 19 206 21 22 23
如果有不同的列将补全nan:
import pandas as pdimport numpy as npa = pd.DataFrame(np.arange(9).reshape(3,3), columns=list('abc'))b = pd.DataFrame(np.arange(20,36).reshape(4,4), columns=list('abcd'))print(a.merge(b,how='outer'))print(b.merge(a,how='outer'))-----------output-----------------a b c d0 0 1 2 NaN1 3 4 5 NaN2 6 7 8 NaN3 20 21 22 23.04 24 25 26 27.05 28 29 30 31.06 32 33 34 35.0
获取两个数组中某一列有重合部分的所有行的全部数据
aa b c0 0 1 21 3 4 52 6 7 8ba b c d0 3 11 12 131 14 15 16 172 18 19 20 213 22 23 24 25b.merge(a,on='a')a b_x c_x d b_y c_y0 3 11 12 13 4 5在ab两个数组中 b c两列是命名重复的,merge取了a列相同(3)的所有行,_x是属于b的(前面一个),_y是属于a的(后面一个)
分组和聚合
groupby分组
import pandas as pdimport numpy as npa = pd.DataFrame(np.arange(9).reshape(3,3), columns=list('abc'))b = a.groupby(by='a')print(a)for i in b:print(i)------output------a b c0 0 1 21 3 4 52 6 7 8(0, a b c0 0 1 2)(3, a b c1 3 4 5)(6, a b c2 6 7 8)可见 i 是元组类型,当a包含许多国家的多种保护动物的数据,我们便可以迅速将他们按国家分类
如果在这里直接print(b.count())
将直接统计出 相同a的不同个体b,c的数量和。(比如计算有多少类保护动物,总数多少)
groupby还可以用来计算不同组别的均值
参考:http://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html
>>> df = pd.DataFrame({'Animal' : ['Falcon', 'Falcon',... 'Parrot', 'Parrot'],... 'Max Speed' : [380., 370., 24., 26.]})>>> dfAnimal Max Speed0 Falcon 380.01 Falcon 370.02 Parrot 24.03 Parrot 26.0>>> df.groupby(['Animal']).mean()Max SpeedAnimalFalcon 375.0Parrot 25.0
多条件分组
1985-2016自杀情况.zip
原始数据大概是这样的
我想看一下每个国家每年的人口和人类发展指数,其中有一个问题就是.mean()将age省略的,原因有可能是里面压根就不是数字,无法计算,但是呢 我也没想到什么好办法将 ‘DataFrameGroupBy’ objects转化为frame.DataFrame
import pandas as pdimport numpy as npdata = pd.read_csv('/home/kesci/master.csv')data = data.loc[:,['country','year','age','population','HDI for year']]print(data.groupby(by=['country','year']).mean().sort_values(by='population'))
输出大约是:(hdi前面部分没有数据)
population HDI for yearcountry yearSan Marino 1999 2.099333e+03 NaN2000 2.114083e+03 NaN2005 2.355333e+03 NaNSaint Kitts and Nevis 1990 3.258333e+03 NaN1992 3.258333e+03 NaN1991 3.258333e+03 NaNSeychelles 1985 4.775000e+03 NaN1986 4.783333e+03 NaN1987 4.858333e+03 NaNAntigua and Barbuda 1989 4.936500e+03 NaN1990 4.944500e+03 NaN1988 4.963667e+03 NaN1987 5.021750e+03 NaN1991 5.032833e+03 NaN1986 5.105833e+03 NaN1992 5.145083e+03 NaNKiribati 1991 5.154583e+03 NaN
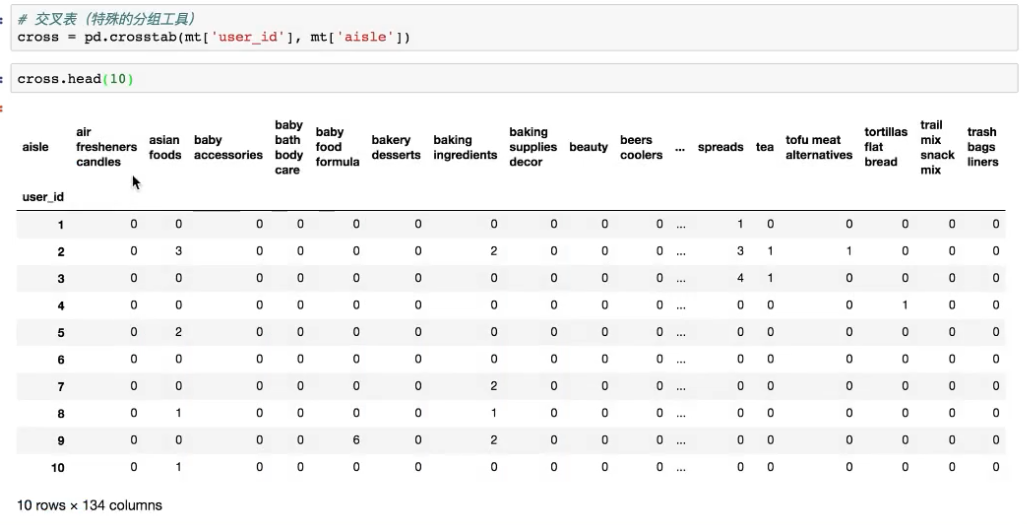
交叉分组
例如在用户购买商品类别的统计中 我们我们有一张mt表,我们想要获取一个用户user_id购买的商品类别aisle购买次数的统计,我们可以使用pd.crosstab(mt[columns1],mt[columns2])来建立一张新的表格
对每一列进行条件赋值(修改)apply - lambda
例如我想将timeStamp修改为全为日期而不要具体时间的
count timeStamp0 1 [2015-12-10, 17:10:52]1 1 [2015-12-10, 17:29:21]2 1 [2015-12-10, 14:39:21]3 1 [2015-12-10, 16:47:36]4 1 [2015-12-10, 16:56:52]5 1 [2015-12-10, 15:39:04]last_data["timeStamp"] = last_data.timeStamp.apply(lambda x: x[0] if True else np.nan)count timeStamp0 1 2015-12-101 1 2015-12-102 1 2015-12-103 1 2015-12-104 1 2015-12-105 1 2015-12-10
last_data["timeStamp"] = last_data.timeStamp.apply(lambda x: x[0] if True else np.nan)
**
参考:
import numpy as npimport pandas as pddata = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'Shenzhen', 'Hangzhou', 'Chongqing'],'year': [2016,2016,2015,2017,2016, 2016],'population': [2100, 2300, 1000, 700, 500, 500]}frame = pd.DataFrame(data, columns = ['year', 'city', 'population', 'debt'])# 使用apply函数, 如果city字段包含'ing'关键词,则'判断'这一列赋值为1,否则为0frame['panduan'] = frame.city.apply(lambda x: 1 if 'ing' in x else 0)print(frame)
删除列
Series方法与DataFrame差不多,这里只介绍后者如何使用,前者相似。
df = pd.DataFrame(np.arange(12).reshape(3,4),columns=[‘A’, ‘B’, ‘C’, ‘D’])
In [4]: df
Out[4]:
A B C D
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
axis=1(按列方向操作)、inplace=True(修改完数据,在原数据上保存)
一:按标签来删除列
df.drop([‘B’,’C’],axis=1,inplace=True)
A D
0 0 3
1 4 7
2 8 11
二:按序号来删除列
x = [1,2] #删除多列需给定列表,否则参数过多
df.drop(df.columns[x],axis=1,inplace=True)
A D
0 0 3
1 4 7
2 8 11
三:按序号来删除行
df.drop([0,1],inplace=True) #默认axis=0
A B C D
2 8 9 10 11
——————————-
参考:https://blog.csdn.net/qq_36523839/article/details/80061326

若有收获,就点个赞吧
0 人点赞
