JdbcTemplate配置Druid多数据源的核心在于创建JdbcTemplate时候为其分配不同的数据源,然后在需要访问不同数据库的时候使用对应的JdbcTemplate即可。这里介绍在Spring Boot中基于Oracle和Mysql配置Druid多数据源。
引入依赖
先根据开启Spring Boot开启一个最简单的Spring Boot应用,然后引入如下依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!-- oracle驱动 --><dependency><groupId>com.oracle.database.jdbc</groupId><artifactId>ojdbc8</artifactId><version>21.1.0.0</version></dependency><dependency><groupId>com.oracle.database.jdbc</groupId><artifactId>ucp</artifactId><version>21.1.0.0</version></dependency><!-- mysql驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!-- druid数据源驱动 --><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.6</version></dependency>
初始化数据库
Spring Boot 2.5.0 版本更新:
# Spring Boot 2.5.0 init schema & data# 执行初始化脚本的用户名称spring.sql.init.username=root# 执行初始化脚本的用户密码spring.sql.init.password=# 初始化的schema脚本位置spring.sql.init.schema-locations=classpath*:schema-all.sql
除了上面用到的配置属性之外,还有一些其他的配置,下面详细讲解一下作用。
spring.sql.init.enabled:是否启动初始化的开关,默认是true。如果不想执行初始化脚本,设置为false即可。通过-D的命令行参数会更容易控制。spring.sql.init.username和spring.sql.init.password:配置执行初始化脚本的用户名与密码。这个非常有必要,因为安全管理要求,通常给业务应用分配的用户对一些建表删表等命令没有权限。这样就可以与datasource中的用户分开管理。pring.sql.init.schema-locations:配置与schema变更相关的sql脚本,可配置多个(默认用;分割)spring.sql.init.data-locations:用来配置与数据相关的sql脚本,可配置多个(默认用;分割)spring.sql.init.encoding:配置脚本文件的编码spring.sql.init.separator:配置多个sql文件的分隔符,默认是;spring.sql.init.continue-on-error:如果执行脚本过程中碰到错误是否继续,默认是false`;Spring Boot can automatically create the schema (DDL scripts) of your JDBC DataSource or R2DBC ConnectionFactory and initialize it (DML scripts). It loads SQL from the standard root classpath locations: schema.sql and data.sql, respectively. In addition, Spring Boot processes the schema-${platform}.sql and data-${platform}.sql files (if present), where platform is the value of spring.sql.init.platform. This allows you to switch to database-specific scripts if necessary. For example, you might choose to set it to the vendor name of the database (hsqldb, h2, oracle, mysql, postgresql, and so on). By default, SQL database initialization is only performed when using an embedded in-memory database. To always initialize an SQL database, irrespective of its type, set spring.sql.init.mode to always. Similarly, to disable initialization, set spring.sql.init.mode to never. By default, Spring Boot enables the fail-fast feature of its script-based database initializer. This means that, if the scripts cause exceptions, the application fails to start. You can tune that behavior by setting spring.sql.init.continue-on-error.
准备数据
DROP TABLE if exists STUDENT;CREATE TABLE STUDENT (SNO VARCHAR2(3) NOT NULL primary key,SNAME VARCHAR2(9) NOT NULL ,SSEX CHAR(2) NOT NULL ,database VARCHAR2(10) NULL);INSERT INTO STUDENT VALUES ('001', 'KangKang', 'M ', 'h2');INSERT INTO STUDENT VALUES ('002', 'Mike', 'M ', 'h2');INSERT INTO STUDENT VALUES ('003', 'Jane', 'F ', 'h2');INSERT INTO STUDENT VALUES ('004', 'Maria', 'F ', 'h2');
多数据源配置
接着在Spring Boot配置文件application.yml中配置多数据源:
server:context-path: /webspring:datasource:druid:# 数据库访问配置, 使用druid数据源# 数据源1 mysqlmysql:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&autoReconnect=true&failOverReadOnly=false&zeroDateTimeBehavior=convertToNullusername: rootpassword: 123456# 数据源2 oracleoracle:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: oracle.jdbc.driver.OracleDriverurl: jdbc:oracle:thin:@localhost:1521/xe #jdbc:oracle:thin:@ip:port/instanceusername: scottpassword: tiger# 连接池配置initial-size: 5min-idle: 5max-active: 20# 连接等待超时时间max-wait: 30000# 配置检测可以关闭的空闲连接间隔时间time-between-eviction-runs-millis: 60000# 配置连接在池中的最小生存时间min-evictable-idle-time-millis: 300000validation-query: select '1' from dualtest-while-idle: truetest-on-borrow: falsetest-on-return: false# 打开PSCache,并且指定每个连接上PSCache的大小pool-prepared-statements: truemax-open-prepared-statements: 20max-pool-prepared-statement-per-connection-size: 20# 配置监控统计拦截的filters, 去掉后监控界面sql无法统计, 'wall'用于防火墙filters: stat,wall# Spring监控AOP切入点,如x.y.z.service.*,配置多个英文逗号分隔aop-patterns: com.springboot.servie.*# WebStatFilter配置web-stat-filter:enabled: true# 添加过滤规则url-pattern: /*# 忽略过滤的格式exclusions: '*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*'# StatViewServlet配置stat-view-servlet:enabled: true# 访问路径为/druid时,跳转到StatViewServleturl-pattern: /druid/*# 是否能够重置数据reset-enable: false# 需要账号密码才能访问控制台login-username: druidlogin-password: druid123# IP白名单# allow: 127.0.0.1# IP黑名单(共同存在时,deny优先于allow)# deny: 192.168.1.218# 配置StatFilterfilter:stat:log-slow-sql: true
MySQL+H2:
server:servlet:application-display-name: ProjectTemplate-Webcontext-path: /webspring:h2:console:path: /h2-consoleenabled: truesettings:web-allow-others: truedatasource:druid:# 数据库访问配置, 使用druid数据源# 数据源1 mysqlmysql:# 驱动配置信息db-type: com.alibaba.druid.pool.DruidDataSource#mysql 配置driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/shop?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=falseusername: testpassword: 12345678# 数据源2 H2h2:db-type: com.alibaba.druid.pool.DruidDataSource #使用阿里druid连接池url: jdbc:h2:~/test #test是我创建的数据库名username: sapassword:driver-class-name: org.h2.Driver# schema: classpath:schema-h2.sql #程序运行时,使用schema.sql来创建数据库中的表# data: classpath:data-h2.sql #程序运行时,使用data.sql来创建初始数据# 连接池配置initial-size: 5min-idle: 5max-active: 20# 连接等待超时时间max-wait: 30000# 配置检测可以关闭的空闲连接间隔时间time-between-eviction-runs-millis: 60000# 配置连接在池中的最小生存时间min-evictable-idle-time-millis: 300000test-while-idle: truetest-on-borrow: falsetest-on-return: false# 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,# testOnBorrow、testOnReturn、testWhileIdle都不会起作用。validation-query: select 1 from dual# 是否缓存preparedStatement,也就是PSCache 官方建议MySQL下建议关闭 个人建议如果想用SQL防火墙 建议打开# 打开PSCache,并且指定每个连接上PSCache的大小pool-prepared-statements: truemax-open-prepared-statements: 20max-pool-prepared-statement-per-connection-size: 20# 配置监控统计拦截的filters, 去掉后监控界面sql无法统计, 'wall'用于防火墙filters: stat,wall# Spring监控AOP切入点,如x.y.z.service.*,配置多个英文逗号分隔aop-patterns: com.springboot.service.*# WebStatFilter配置web-stat-filter:enabled: true# 添加过滤规则url-pattern: /*# 忽略过滤的格式exclusions: '*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*'# StatViewServlet配置stat-view-servlet:enabled: true# 访问路径为/druid时,跳转到StatViewServleturl-pattern: /druid/*# 是否能够重置数据reset-enable: false# 需要账号密码才能访问控制台login-username: druidlogin-password: druid123# IP白名单allow:# IP黑名单(共同存在时,deny优先于allow)# deny: 192.168.1.218# 配置StatFilterfilter:stat:log-slow-sql: truesql:init:mode: embeddedplatform: h2# classpath 等价于 main/java + main/resources + 第三方jar包的根目录schema-locations: classpath:schema-h2.sql #程序运行时,使用schema.sql来创建数据库中的表data-locations: classpath:data-h2.sql #程序运行时,使用data.sql来创建初始数据
然后根据配置,可以知道 H2的console目录在[http://localhost:8080/web/h2-console/](http://localhost:8080/web/h2-console/)
然后创建一个多数据源配置类,根据application.yml分别配置一个Mysql和Oracle的数据源,并且将这两个数据源注入到两个不同的JdbcTemplate中:
@Configurationpublic class DataSourceConfig {@Primary@Bean(name = "mysqldatasource")@ConfigurationProperties("spring.datasource.druid.mysql")public DataSource dataSourceOne(){return DruidDataSourceBuilder.create().build();}@Bean(name = "oracledatasource")@ConfigurationProperties("spring.datasource.druid.oracle")public DataSource dataSourceTwo(){return DruidDataSourceBuilder.create().build();}@Bean(name = "mysqlJdbcTemplate")public JdbcTemplate primaryJdbcTemplate(@Qualifier("mysqldatasource") DataSource dataSource) {return new JdbcTemplate(dataSource);}@Bean(name = "oracleJdbcTemplate")public JdbcTemplate secondaryJdbcTemplate(@Qualifier("oracledatasource") DataSource dataSource) {return new JdbcTemplate(dataSource);}}
上述代码根据application.yml创建了mysqldatasource和oracledatasource数据源,其中mysqldatasource用@Primary标注为主数据源,接着根据这两个数据源创建了mysqlJdbcTemplate和oracleJdbcTemplate。
@Primary标志这个Bean如果在多个同类Bean候选时,该Bean优先被考虑。多数据源配置的时候,必须要有一个主数据源,用@Primary标志该Bean。
数据源创建完毕,接下来开始进行测试代码编写。
测试
首先往Mysql和Oracle中创建测试表,并插入一些测试数据:
Mysql:
DROP TABLE IF EXISTS `student`;CREATE TABLE `student` (`sno` varchar(3) NOT NULL,`sname` varchar(9) NOT NULL,`ssex` char(2) NOT NULL,`database` varchar(10) DEFAULT NULL) DEFAULT CHARSET=utf8;INSERT INTO `student` VALUES ('001', '康康', 'M', 'mysql');INSERT INTO `student` VALUES ('002', '麦克', 'M', 'mysql');
Oracle:
DROP TABLE "SCOTT"."STUDENT";CREATE TABLE "SCOTT"."STUDENT" ("SNO" VARCHAR2(3 BYTE) NOT NULL ,"SNAME" VARCHAR2(9 BYTE) NOT NULL ,"SSEX" CHAR(2 BYTE) NOT NULL ,"database" VARCHAR2(10 BYTE) NULL);INSERT INTO "SCOTT"."STUDENT" VALUES ('001', 'KangKang', 'M ', 'oracle');INSERT INTO "SCOTT"."STUDENT" VALUES ('002', 'Mike', 'M ', 'oracle');INSERT INTO "SCOTT"."STUDENT" VALUES ('003', 'Jane', 'F ', 'oracle');INSERT INTO "SCOTT"."STUDENT" VALUES ('004', 'Maria', 'F ', 'oracle');
接着创建两个Dao及其实现类,分别用于从Mysql和Oracle中获取数据:
MysqlStudentDao接口:
public interface MysqlStudentDao {List<Map<String, Object>> getAllStudents();}
MysqlStudentDao实现;
@Repositorypublic class MysqlStudentDaoImp implements MysqlStudentDao{@Autowired@Qualifier("mysqlJdbcTemplate")private JdbcTemplate jdbcTemplate;@Overridepublic List<Map<String, Object>> getAllStudents() {return this.jdbcTemplate.queryForList("select * from student");}}
可看到,在MysqlStudentDaoImp中注入的是mysqlJdbcTemplate。
OracleStudentDao接口:
public interface OracleStudentDao {List<Map<String, Object>> getAllStudents();}
OracleStudentDao实现:
@Repositorypublic class OracleStudentDaoImp implements OracleStudentDao{@Autowired@Qualifier("oracleJdbcTemplate")private JdbcTemplate jdbcTemplate;@Overridepublic List<Map<String, Object>> getAllStudents() {return this.jdbcTemplate.queryForList("select * from student");}}
在OracleStudentDaoImp中注入的是oracleJdbcTemplate。
随后编写Service层:
StudentService接口:
public interface StudentService {List<Map<String, Object>> getAllStudentsFromOralce();List<Map<String, Object>> getAllStudentsFromMysql();}
StudentService实现:
@Service("studentService")public class StudentServiceImp implements StudentService{@Autowiredprivate OracleStudentDao oracleStudentDao;@Autowiredprivate MysqlStudentDao mysqlStudentDao;@Overridepublic List<Map<String, Object>> getAllStudentsFromOralce() {return this.oracleStudentDao.getAllStudents();}@Overridepublic List<Map<String, Object>> getAllStudentsFromMysql() {return this.mysqlStudentDao.getAllStudents();}}
最后编写一个Controller:
@RestControllerpublic class StudentController {@Autowiredprivate StudentService studentService;@RequestMapping("querystudentsfromoracle")public List<Map<String, Object>> queryStudentsFromOracle(){return this.studentService.getAllStudentsFromOralce();}@RequestMapping("querystudentsfrommysql")public List<Map<String, Object>> queryStudentsFromMysql(){return this.studentService.getAllStudentsFromMysql();}}
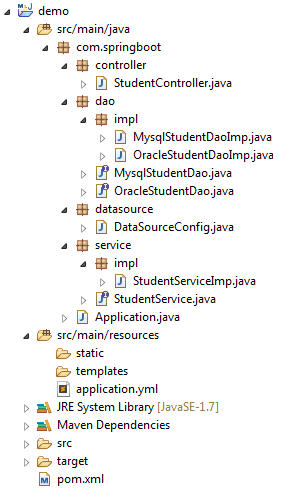
最终项目目录如下图所示:
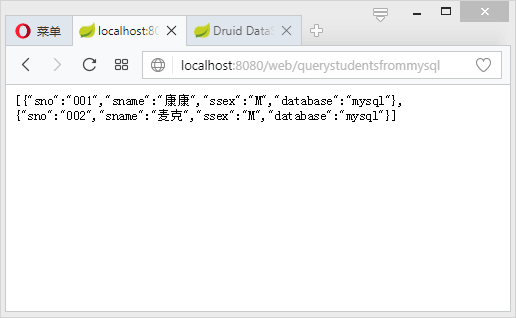
启动项目,访问:http://localhost:8080/web/querystudentsfrommysql:
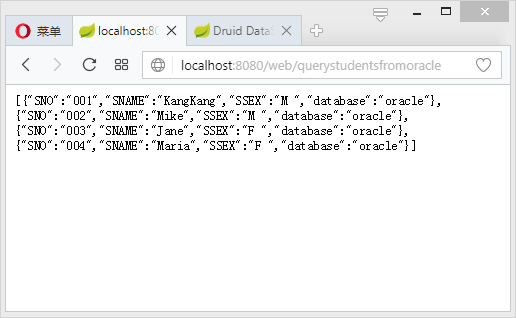
http://localhost:8080/web/querystudentsfromoracle:

若有收获,就点个赞吧
0 人点赞
