概述
本篇博客是记录使用spring batch做数据迁移时时遇到的一个关键问题:数据迁移量大时如何保证内存。当我们在使用spring batch时,我们必须配置三个东西: reader,processor,和writer。其中,reader用于从数据库中读数据,当数据量较小时,reader的逻辑不会对内存带来太多压力,但是当我们要去读的数据量非常大的时候,我们就不得不考虑内存等方面的问题,因为若数据量非常大,内存,执行时间等等都会受到影响。
问题是什么
在上面的内容当中我们已经提到了,我们面临的问题是数据迁移量大时的内存问题。但是这样的描述非常笼统,因此博主决定将这一部分单独拎出来说。
在学习了spring batch的知识之后我们应该很清楚的一点是,每一个spring batch的step都包含如下的部分:

即读数据,处理数据,写数据。这三个步骤里面最可能会导致内存变大问题的无疑是读数据环节。读数据作为spring batch的数据输入,是整个spring batch job的开头逻辑。
若我们的数据量不大,如只有几十万条,那我们无疑不会面临内存问题,即便一次将所有数据加载到内存当中,占的内存也不会非常多,且spring batch数据迁移的速度非常之快,几十万条的数据往往是几十秒的时间就可以迁移完成。但是当数据量变大之后,问题就不一样了。当我们的数据量达到数百万或上千万时,若一次性将所有数据全部读到内存当中,则会占据远远超出正常范围的非常大的内存。该问题示意图如下所示:
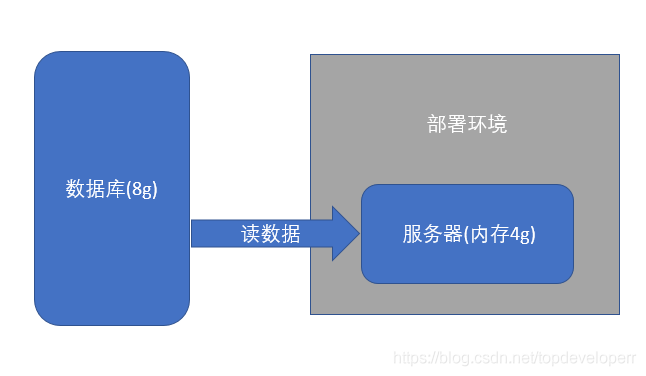
我们写的任何程序都会有一个运行内存,假设这个内存的总容量现在只有4g,而我们数据库里需要操作的数据有8g,那么无疑,一次性的将数据读出来就会出错。这便是需要考虑得问题。
Spring提供的reader实现
spring提供了非常丰富的Reader实现,其中比较常用的从数据库读数据的有JdbcCursorItemReader,JdbcPagingItemReader等。
JdbcCursorItemReader
使用JdbcCursorItemReader的示例代码如下:
@Beanpublic JdbcCursorItemReader<CustomerCredit> itemReader() {return new JdbcCursorItemReaderBuilder<CustomerCredit>().dataSource(this.dataSource).name("creditReader").sql("select ID, NAME, CREDIT from CUSTOMER").rowMapper(new CustomerCreditRowMapper()).build();}
JdbcCursorItemReader的好处在于使用简单,但是我们从它的sql就能发现,JdbcCursorItemReader会一次把所有的数据全部拿回来,当数据量过大而服务器内存不够时,就会遇到下面无法分配内存的问题:

报错信息为:Resource exhaustion event:The JVM was unable to allocate memory from the heap. 意思就是需要分配内存的数据太多,但是无法找到足够的内存了。关于这个问题的更多分析可以参考这篇博客:GC (Allocation Failure)
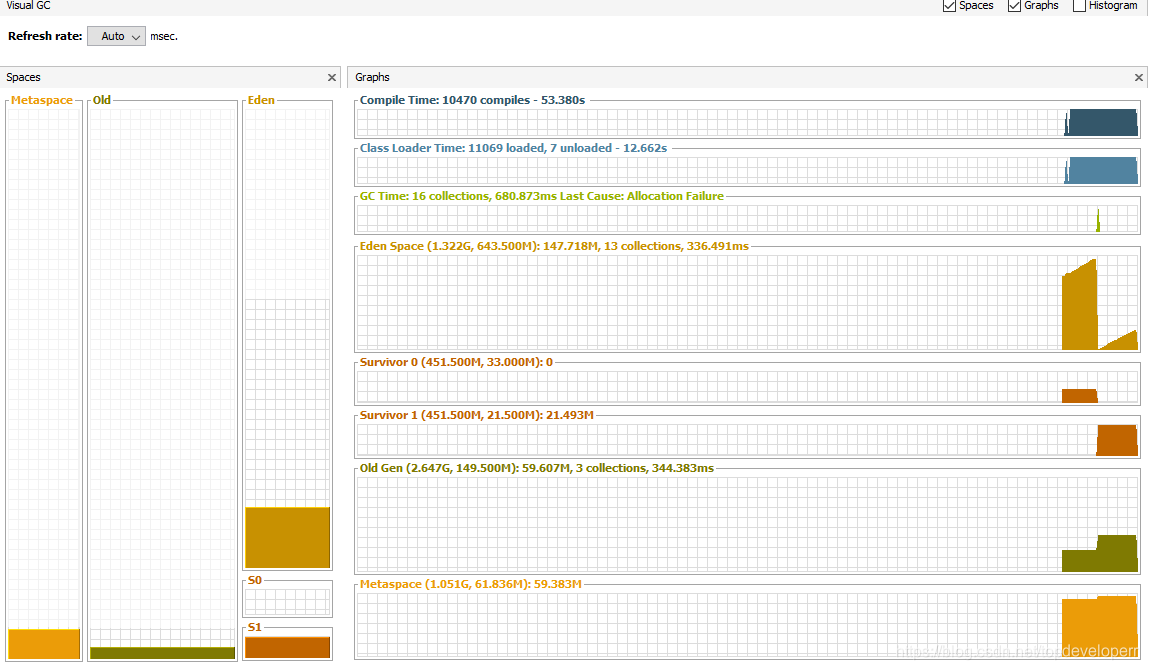
反映在内存里,堆内存会呈现出如下的情况:(下面使用JVisualVM监控堆内存)
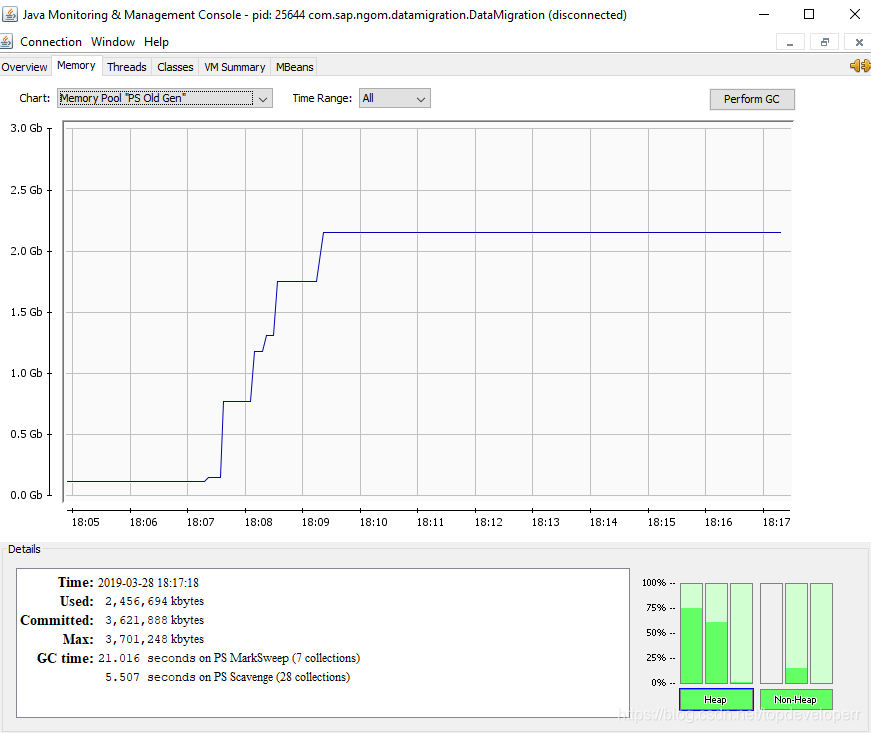
随着每一次数据读入,堆内存都会增大,原因是不是JdbcCursorItemReader一次性读回了所有的数据?返回之后就会存在一个对象里面,而这个对象的尺寸过大,因此直接进入了老年代。在数据迁移完成之前,这些数据都不会被回收。如下图所示:
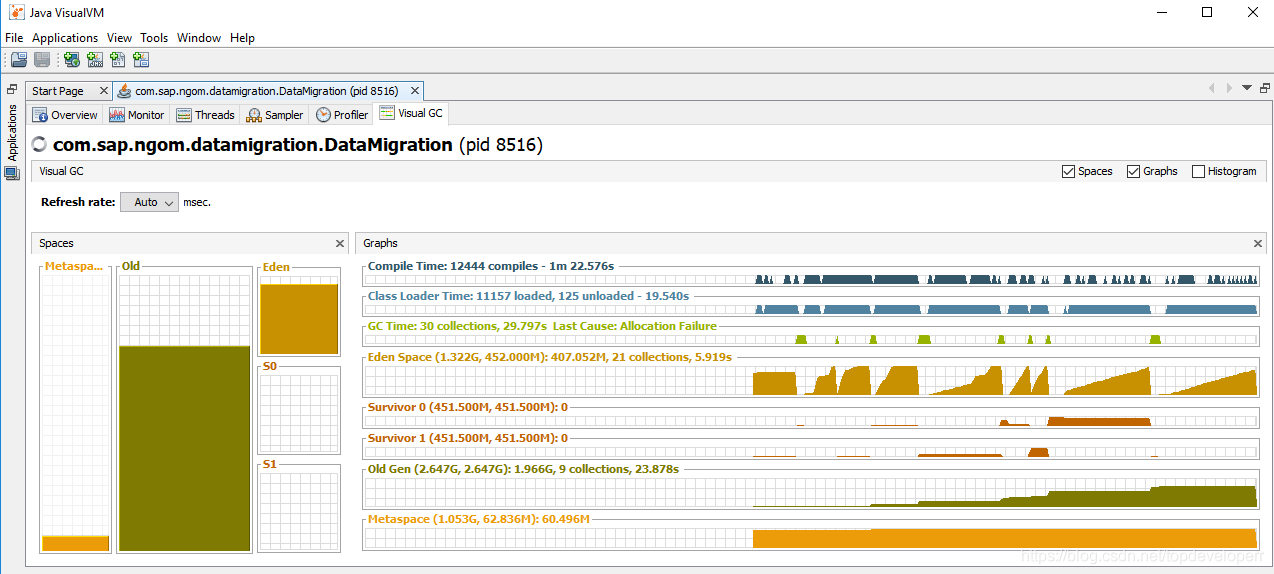
毫无疑问,当我们的数据量大时使用这种类型的reader来读取数据需要注意点什么东西。
JdbcCursorItemReader 是基于游标技术的 JDBC 实现。它直接与 ResultSet 一起工作,并且需要一条 SQL 语句来针对从 DataSource 获得的连接运行。所以当你使用JdbcCursorItemReader时候需要查看你的数据库是否开启了游标查询功能。
此外JdbcTemplate中有一个重要的参数:**fetchSize**,它向 JDBC 驱动程序提供有关应从数据库中获取的行数的提示。默认情况下,不给出任何提示。如果不给出任何提示的话,就采用数据库里标定的数值,比如Oracle是defaultRowPrefetch = 10: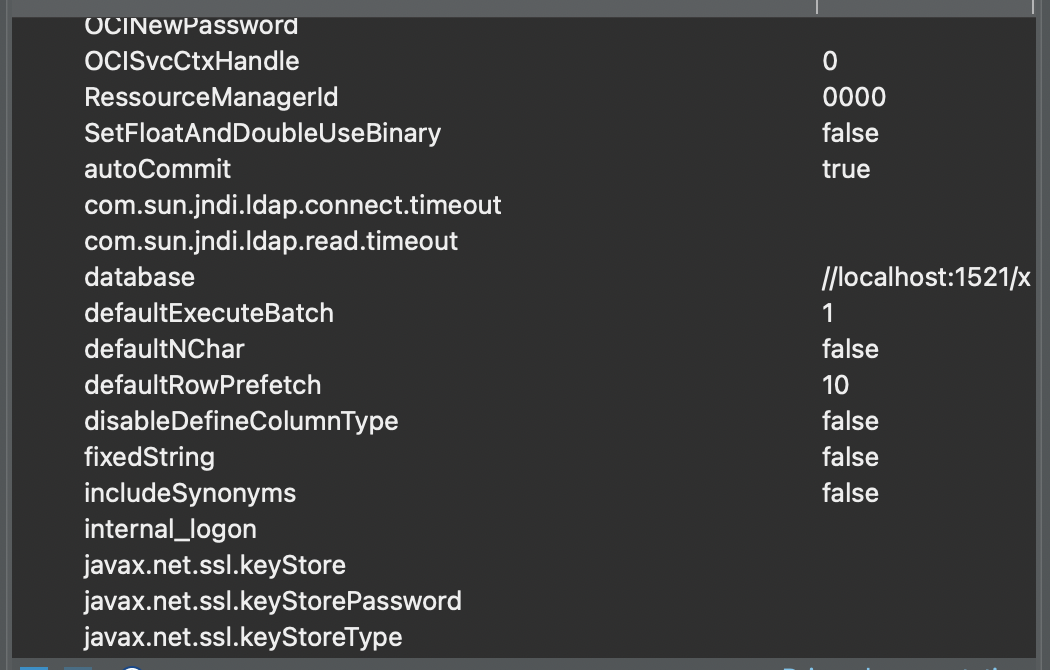
为此我们需要设置 JdbcCursorItemReader#setFetchSize(50)。这将告诉 Spring Batch 在 PreparedStatement 上设置该值,你可以在这了解一下PreparedStatement相关参数Connection.prepareStatement。
同时需要注意你的.properties里面的配置文件的数据库连接URL是否开启了允许fetchSize:jdbc:oceanbase:oracle://your_ip:your_port/your_user?useCursorFetch=true。
当然,你也可以使用另一种reader来解决此问题:JdbcPagingItemReader
JdbcPagingItemReader
JdbcPagingItemReader的作用和它的名字一样,它可以分页读取数据,但是使用起来相比于JdbcCursorItemReader更加复杂,示例代码如下:
@Beanpublic JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {Map<String, Object> parameterValues = new HashMap<>();parameterValues.put("status", "NEW");return new JdbcPagingItemReaderBuilder<CustomerCredit>().name("creditReader").dataSource(dataSource).queryProvider(queryProvider).parameterValues(parameterValues).rowMapper(customerCreditMapper()).pageSize(1000).build();}@Beanpublic SqlPagingQueryProviderFactoryBean queryProvider() {SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();provider.setSelectClause("select id, name, credit");provider.setFromClause("from customer");provider.setWhereClause("where status=:status");provider.setSortKey("id");return provider;}
可以看到我们能够设置page的大小,JdbcPagingItemReader将根据这个页的大小,每次读取这么多的数据,因此这些数据返回保存的对象,就只会是小对象,因此他们不会直接在老年代里分配,而是先分配在年轻代,随着年轻代不断变大,minor gc也不断进行,回收掉已经处理完的数据,老年代的内存使用量不会有任何增大,类似下图:
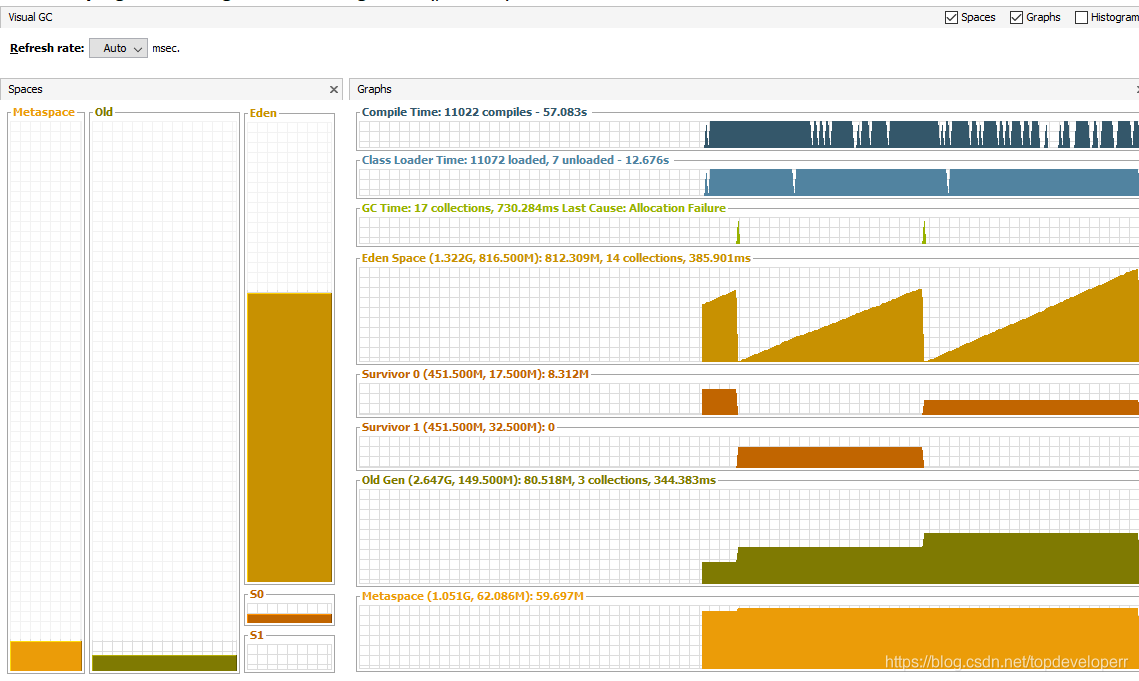
老年代内存不会有任何变化,年轻带会随着服务器数据迁移进行而增大同时被回收。
在使用JdbcPagingItemReader时,有一个必须注意的地方就是排序关键字是必须指定的,原因在于排序是分页实现原理的技术基础。sortKey和我们指定的其他字句一起构建出SQL语句出来。在sortKey上必须使用unique key constraint约束,因为只有这样才能得以确保执行之间不会丢失任何数据。这也可以说是JdbcCursorItemReader相对便利的一点优势。
JdbcPagingItemReader使用案例
- This is the model class Student.
Student.java
public class Student {private String id;private String name;}
- The mapper class will map each row of data in the ResultSet.
StudentMapper.java
public class StudentMapper implements RowMapper<Student> {@Overridepublic Student mapRow(final ResultSet rs, final int rowNum) {Student student = new Student();student.setId(rs.getString(“id”));student.setName(rs.getString(“name”));return student;}}
- The main reader class
StudentDataReader.java
public class StudentDataReader {@Autowiredprivate DataSource dataSource;private static final String GET_STUDENT_INFO = “SELECT * from STUDENTS where id = :id and name = :name “;public JdbcPagingItemReader<Student> getPaginationReader(Student student) {final JdbcPagingItemReader<Student> reader = new JdbcPagingItemReader<>();final StudentMapper studentMapper = new StudentMapper();reader.setDataSource(dataSource);reader.setFetchSize(100);reader.setPageSize(100);reader.setRowMapper(studentMapper);reader.setQueryProvider(createQuery()); Map<String, Object> parameters = new HashMap<>();parameters.put(“id”, student.getId());parameters.put(“name”, student.getName());reader.setParameterValues(parameters);return reader;}private PostgresPagingQueryProvider createQuery() {final Map<String, Order> sortKeys = new HashMap<>();sortKeys.put(“id”, Order.ASCENDING);final PostgresPagingQueryProvider queryProvider = new PostgresPagingQueryProvider();queryProvider.setSelectClause(“*”);queryProvider.setFromClause(getFromClause());queryProvider.setSortKeys(sortKeys);return queryProvider;}private String getFromClause() {return “( “ + GET_STUDENT_INFO + “)” + “ AS RESULT_TABLE “;}}
- PagingQueryProvider - It executes the SQL built by the PagingQueryProvider to retrieve requested data.
- setPageSize(int)- The query is executed using paged requests of a size specified in setPageSize(int). The number of rows to retrieve at a time. pageSize is the number of rows to fetch per page.
In the above example, it will fetch 100 rows at a time.
- setFetchSize(int) - Gives the JDBC driver a hint as to the number of rows that should be fetched from the database when more rows are needed for the ResultSet object. If the fetch size specified is zero, the JDBC driver ignores the value. It takes the number of rows to fetch.
- setSortKeys(Map
Additional pages are requested when needed as read () method is called, returning an object corresponding to the current position.
- setSelectClause(String selectClause) - SELECT clause part of SQL query string.
- setFromClause(String fromClause) - FROM clause part of SQL query string. In this example, our query will look like
SELECT * (SELECT * from STUDENTS where id = :id and name = :name) AS RESULT_TABLE
总结
数据量小时选择的方案差别不会很大,当数据量大时,为了有好的内存表现则使用分页的reader是必要的。但同时,因为要实现分页,也会带来一些不可避免的限制。
参考资料
Spring batch pagination with JdbcPagingItemReader Class JdbcPagingItemReader
Cursor-based ItemReader Implementations

若有收获,就点个赞吧
0 人点赞
