CommonJS 模块
- 用户通过 require 函数,引入本地文件系统中的某个模块
- 开发者通过 exports 与 module.exports 这两个特殊变量,把想要公布给外界的功能,从当前模块中导出
自制的模块加载器
``typescript function loadModule (filename, module, require) { const wrappedSrc =
`; eval(wrappedSrc); }(function (module, exports, require){${fs.readFileSync(filename, 'utf8')}})(module, module.exports, require)
function require (moduleName) { const id = require.resolve(moduleName); if (require.cache[id]) { return require.cache[id].exports; }
// 模块的元数据const module = {exports: {},id}// 更新缓存require.cache[id] = module;// 载入模块loadModule(id, module, require);// 返回导出的变量return module.exports;
}
require.cache = {};
require.resolve = (moduleName) => { // 根据 moduleName 解析出完整的模块 id }
1. 通过 moduleName 模块名称解析出模块的完整路径1. 如果该模块存在缓存中直接返回缓存结果1. 构建一个首次加载该模块的对象1. 将该对象缓存起来1. 利用 loadModule 函数读取该模块的源代码,并利用 eval 执行这些代码。模块的开发者在编写模块源码时,可以修改或替换 module.exports 对象,从而导出自己想要公布的内容1. 将 module.exports 返回给调用方,其中包含了模块开发者想要公布的那套 API<a name="TmW5t"></a>## require 函数是同步函数<a name="jMZSP"></a>## 模块解析算法resolve() 函数的解析算法的作用:- 要加载的是不是文件模块,需要区分相对路径和绝对路径- 要加载的是不是核心模块- 要加载的是不是包模块?如果没有找到与 moduleName 相匹配的核心模块,就从发起加载请求的这个模块开始,逐层向上搜索名为 node_modules 的目录,看看里面有没有能够与 moduleName 匹配的模块,如果有,就载入,如果没有,就沿着目录树继续向上走,并在相应的 node_modules 目录中搜索,直到到达文件系统的根部为止- 先看看有没有以 moduleName 命名的后缀名为 .js 的文件- 其次看看有没有名为 moduleName 的目录且该目录下有没有名为 index.js 的文件- 最后看看有没有名 moduleName 的目录,其目录下有没有 package.json 文件,若有,则采用其中的 main 属性所指定的目录或文件<a name="r4BMj"></a>## 循环依赖> CommonJS 规范从加载策略来说是运行时加载,即代码执行到需要加载模块的那一行代码的时候,才会去加载并执行对应的模块。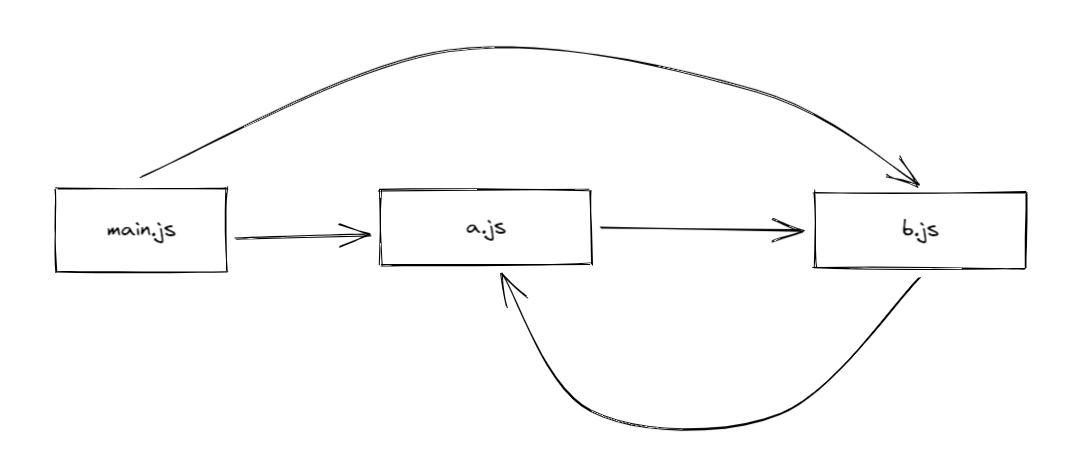```typescript// a.jsexports.loaded = false;const b = require('./b');module.exports = {b,loaded: true}// b.jsexports.loaded = false;const a = require('./a')module.exports = {a,loaded: true}// main.jsconst a = require('./a');const b = require('./b');console.log('A ->', JSON.stringify(a))console.log('B ->', JSON.stringify(b))

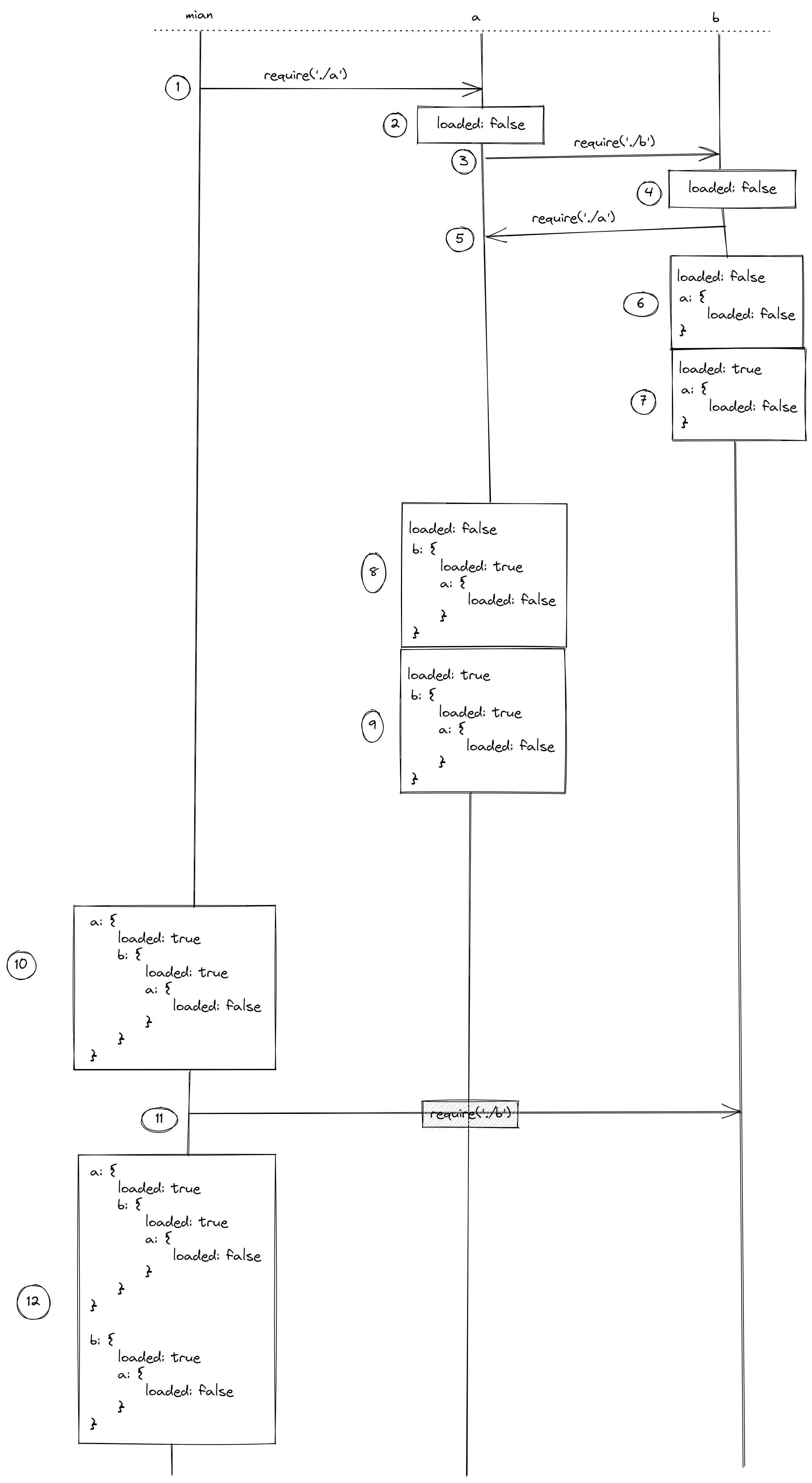
- 整个流程从 main.js 开始,模块一开始载入 a.js 模块
- a.js 首先导出一个名为 loaded 的值,设为 false
- a.js 模块要求导入 b.js 模块
- b.js 模块导出一个名为 loaded 的值,设为 false
- b.js 反过来要求载入 a.js ,形成循环依赖
- 由于系统已经开始处理 a.js 模块,所以 b.js 模块会把 a.js 目前已经导出的内容,立即复制到本模块
- b.js 把原本导出的 loaded 改为 true
- b.js 执行结束,控制权回到 a.js,它会把 b.js 模块当前状态拷贝一份
- a.js 把原本导出的 loaded 改为 true
- a.js 执行结束,控制权回到 main.js,它会把 a.js 模块当前状态拷贝一份
- main.js 模块要求载入 b.js,由于该模块已经载入,因此系统立即从缓存中返回该模块
- main.js 把 b.js 当前状态拷贝一份,放到自己这里
定义模块所用的模式
命名导出模式
```typescript // logger.js exports.info = (message) => { console.log(‘message >>>’, message); }
exports.verbose = (message) => { console.log(‘verbose >>>’, message); }
// main.js const logger = require(‘./logger’); logger.info(‘info’); logger.verbose(‘verbose’);
<a name="sKpP4"></a>### 函数导出模式```typescript// logger.jsmodule.exports = (message) => {console.log('message >>>', message);}exports.verbose = (message) => {console.log('verbose >>>', message);}// main.jsconst logger = require('./logger');logger('info');logger.verbose('verbose');
类导出模式
// logger.jsclass Logger {constructor(name) {this.name = name;}log (message) {console.log('messge >>>', message);}info (message) {this.log(`info ${message}`);}verbose (message) {this.log(`verbose ${message}`);}}module.exports = Logger;// main.jsconst Logger = require('./logger');const dbLogger = new Logger('DB');dbLogger.info('info');const accessLogger = new Logger('ACCESS');accessLogger.verbose('verbose');
实例导出模式
// logger.jsclass Logger {constructor(name) {this.count = 0;this.name = name;}log (message) {this.count++;console.log('messge >>>', message);}}module.exports = new Logger('DEFAULT');// main.jsconst logger = require('./logger');logger.info('info');
通过 monkey patching 模式修改其他模块或全局作用域
// patcher.jsrequire('./logger').customMessage = () => {console.log('this is custom');}// main.jsrequire('./patcher');const logger = require('./logger');logger.customMessage();
ECMAScript 模块(ESM)
和 CommonJS 的一个重要区别,在于 ES 模块是静态的(static),即引入这种模块的那些语句,必须写在最顶层,而且要置于条件语句之外。受引用的模块,只能使用常量字符串,而不能依赖那种需要在运行期动态求值的表达式。
命令导出模式与命令引入
ES 模块里的所有内容,默认都是私有的,只有那些明确导出的实体,才能够为其他模块所访问
export function log (message) {console.log(message);}export const LEVEL = 12;export class Logger {constructor (name) {this.name = name;}log () {console.log(this.name);}}import * as loggerModule from './logger.js'console.log(loggerModule);import { LEVEL } from './logger.js';console.log(LEVEL);import { log as log2} from './logger.js';log2('message');
默认导出与默认引入
export default class Logger {constructor (name) {this.name = name;}log () {console.log(this.name);}}import MyLogger from './logger.js';let logger = new MyLogger('name');logger.log();
混用命名导出与默认导出
export default class Logger {constructor (name) {this.name = name;}log () {console.log(this.name);}}export function info(message) {console.log(message);}import MyLogger, { info } from './logger.js';let logger = new MyLogger('name');logger.log();info('info');
- 某些情况下,默认导出可能会减弱 dead code elimination(‘死代码’消除, tree shaking)的效果。比如,某个模块可能只默认导出一个实体,而这个实体是一个对象,开发者把想要公布的所有功能,都分别设置成该对象的属性。在这种情况下,如果用户把这个默认导出的对象引入进来,那么大部分模块绑定工具均认定,整个对象全都需要在应用程序中使用,他们不会再去详细考虑该对象的每项属性所对应的那个功能,到底有没有在程序里面用到。
异步引入(async import、dynamic import)
这种引入操作可以在程序运行的过程中,通过特殊的 import() 运算符实现,这个运算符从语法上看,相当于一个函数,它接受模块标识符做参数,并返回一个 Promise,这个 Promise 以后可以解析为模块对象 ```typescript // string-el.js export const HELLO = ‘hello’;
// string-en.js export const HELLO = ‘en hello’;
// main.js const SUPPORT_LANGUAGES = [‘el’, ‘en’]; const selectedLanguage = process.argv[2];
if (SUPPORT_LANGUAGES.includes(selectedLanguage)) { console.error(‘error’); process.exit(1); }
const translationModule = ./string-${selectedLanguage}.js;
import(translationModule)
.then((strings) => {
console.log(strings.HELLO);
})
<a name="uzY8E"></a>## 模块的加载过程<a name="GFRQ4"></a>### 载入模块所经历的各个阶段> 解释器的目标是构建一张图以描述所要载入的这些模块之间的依赖关系,这种图也称为依赖图(dependency graph)node 解释器启动时,会得到一些需要执行的代码,这些代码通常是以 JS 文件的形式传给他的。这份文件就是解析关系时的出发点,也称为入口点(entry point)。解释器会从入口点开始,寻找所有的 import 语句,如果在寻找过程中又遇到 import 语句,就会以深度优先的方式递归,直到把所有代码都解析并执行完毕为止。1. 构造(construction,也称为剖析 parsing):寻找所有的引入语句,并递归地从相关文件里加载每个模块的内容1. 实例化(Instantiation):针对每个导出的实体,在内存中保留一个带有名称的引用,但暂且不给它赋值。另外,还要针对所有的 import 语句及 export 语句创建引用,以记录它们之间的依赖关系(linking)。这一阶段不执行任何 JS 代码1. 执行(Evaluation)> 简单的说,第一阶段是找到依赖图中所有的点,第二阶段是在有依赖关系的点之间创建路径,第三阶段则是按照正确的顺序遍历这些路径。和 CommonJS 的区别:- CommonJs 是动态的,一边解析依赖图,一边执行相关的文件。所以只要看到 require 语句,就可以断定,当程序来到这条语句时,肯定已经把前面应该执行的代码,全都执行完了。- ESM 系统中的三个阶段是彼此分离的,必须先把依赖图完整地构造出来,才能开始执行代码。因此,引入模块和导出模块的操作,必须是静态的,而不能等到执行代码才去做。<a name="J6kBs"></a>### 只读的 live 绑定> ES 在引进来的模块与该模块所导出的值之间,建立了一种 live 绑定关系,而这种绑定关系在引入方这一端是只能读而不能写的。```typescript// counter.jsexport let count = 0;export function increment () {count++;}// main.jsimport { count, increment } from "./counter.js";console.log(count); // 0increment();console.log(count); // 1count++; // TypeError: Assignment to constant variable
而 CommonJS 系统中,如果有某个模块要引入 CommonJS 模块,系统会对后者的整个 exports 对象做拷贝(浅拷贝,shallow copy),从而将其中的内容复制到当前模块里面。于是,数字或字符串等原始类型的变量就会出现复本,而不会与原模块中的相关变量联动。
解析循环依赖
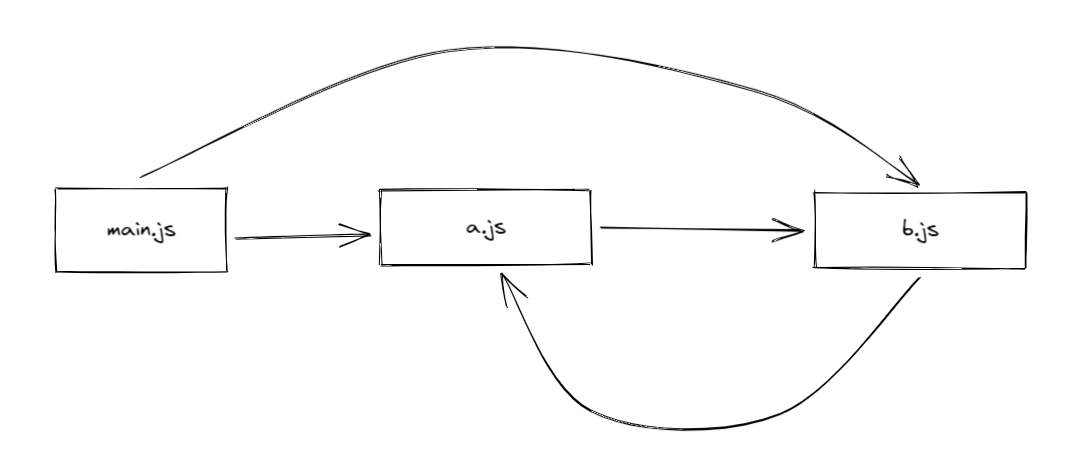
// a.jsimport * as bModule from './b.js';export let loaded = false;export const b = bModule;loaded = true;// b.jsimport * as aModule from './a.js';export let loaded = false;export const a = aModule;loaded = true;// main.jsimport * as a from './a.js';import * as b from './b.js';console.log('a >>>>', a);console.log('b >>>>', b);
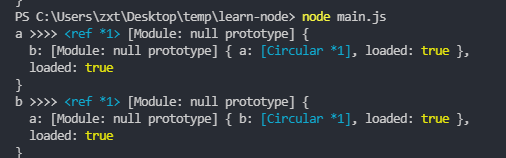
a 里面的那个 b,跟当前范围中的那个 b,实际上是同一个实例。
第一阶段:剖析
解释器从入口点(main.js)开始,剖析模块之间的依赖关系。只关注模块里面的 import 语句,引入加载对应的源代码。解释器以深度优先的方式探索依赖关系图,而且只把图中的每个模块访问一次。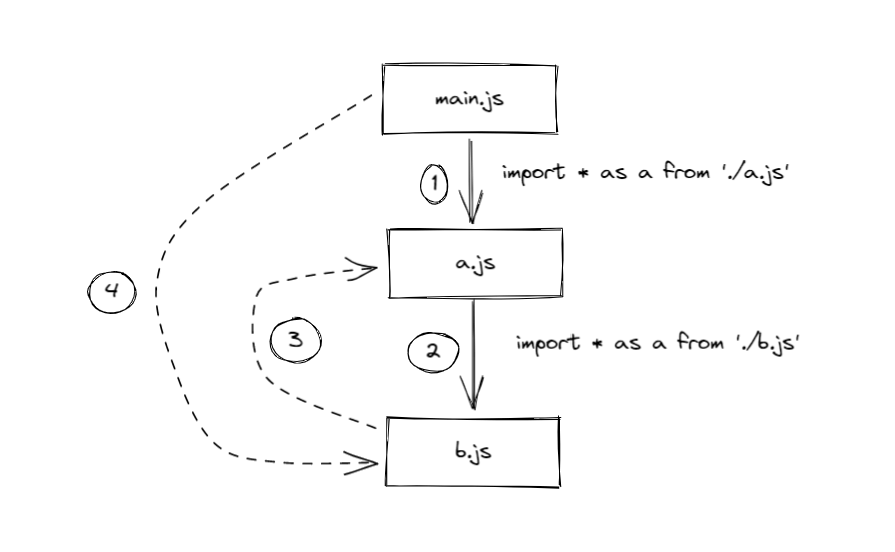
从 b.js 往下剖析,发现一条 import 语句要引入 a.js,但 a.js 刚才已经访问过,所以不会沿着这条路径走
第二阶段:实例化
解释器会从树状结构的底部开始,逐渐向顶部走。每走到一个模块,他就寻找该模块所要导出的全部属性,并在内存中构建一张映射表,以存放此模块所要导出的属性名称与该属性即将拥有的取值(这些值在这个阶段不做初始化)
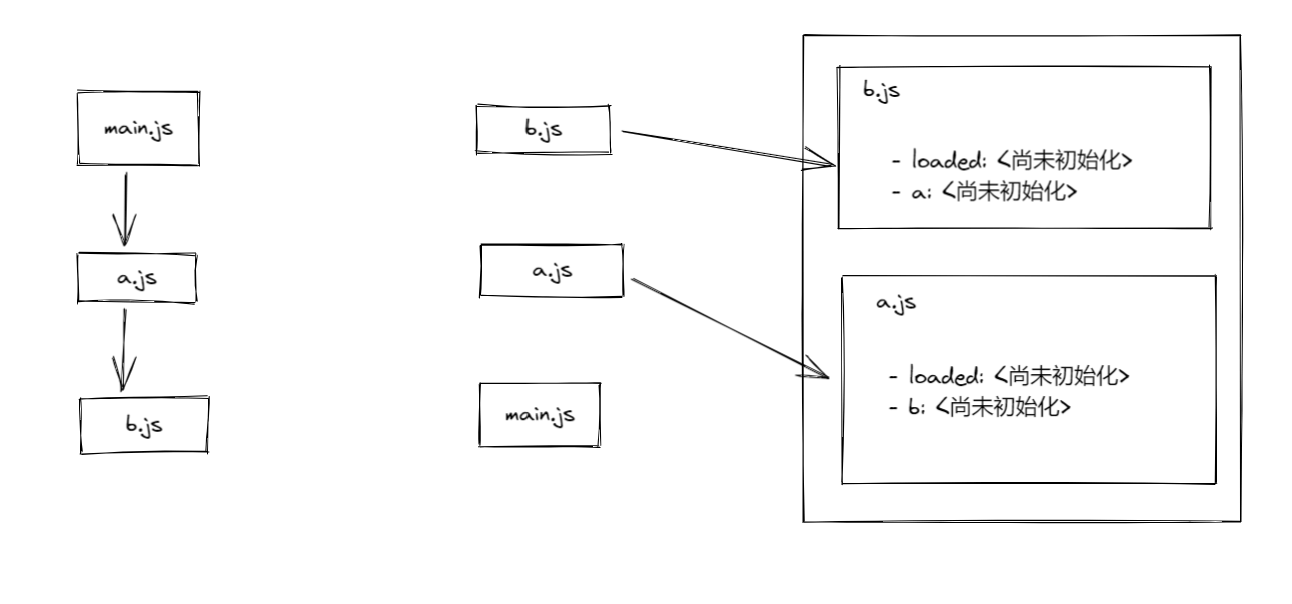
实例化阶段所构造的这套 exports 映射图,只记录导出的名称与该名称即将拥有的值之间的关系,至于这个值本身,则不在本阶段给予初始化。
走完上面的步骤后,解释器还要再过一遍,这次会把各模块导出的名称与引入这些名称的那些模块给链接起来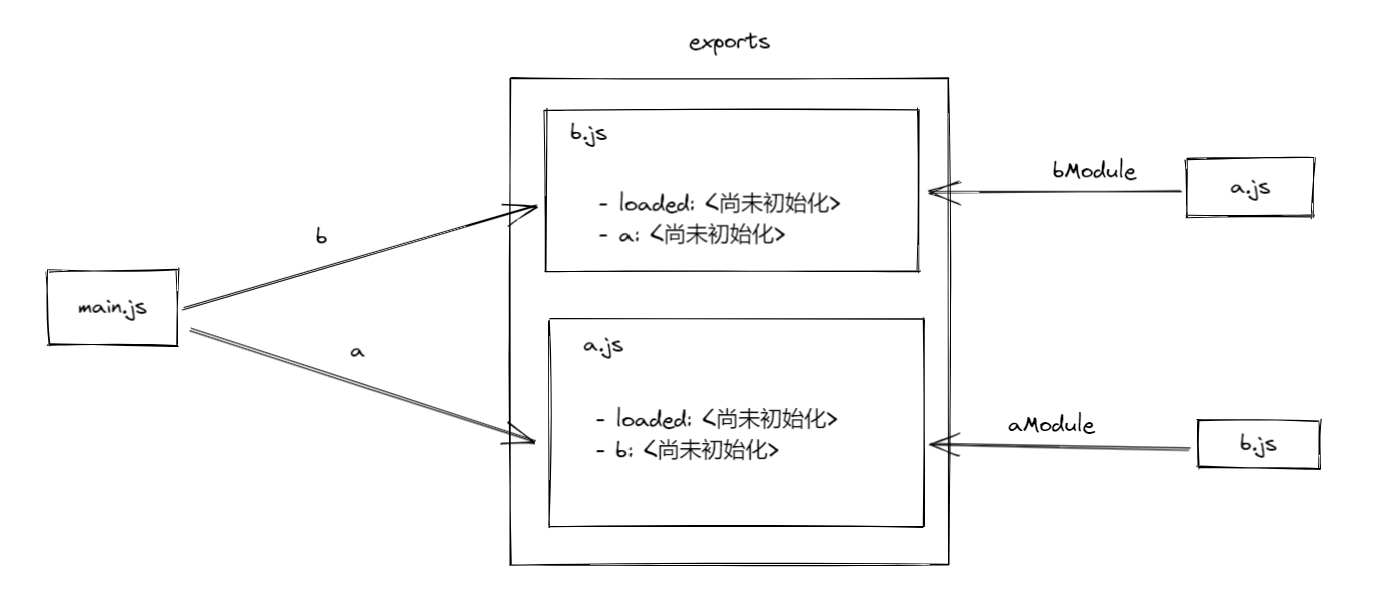
模块 b.js 要与模块 a.js 所导出的内容相链接,这条链接叫做 aModule第三阶段:执行
系统要执行每份文件里面的代码。它按照后序的深度优先(post-order depth first)顺序,由下而上的访问最初的那张依赖图,并逐个执行访问到的文件。
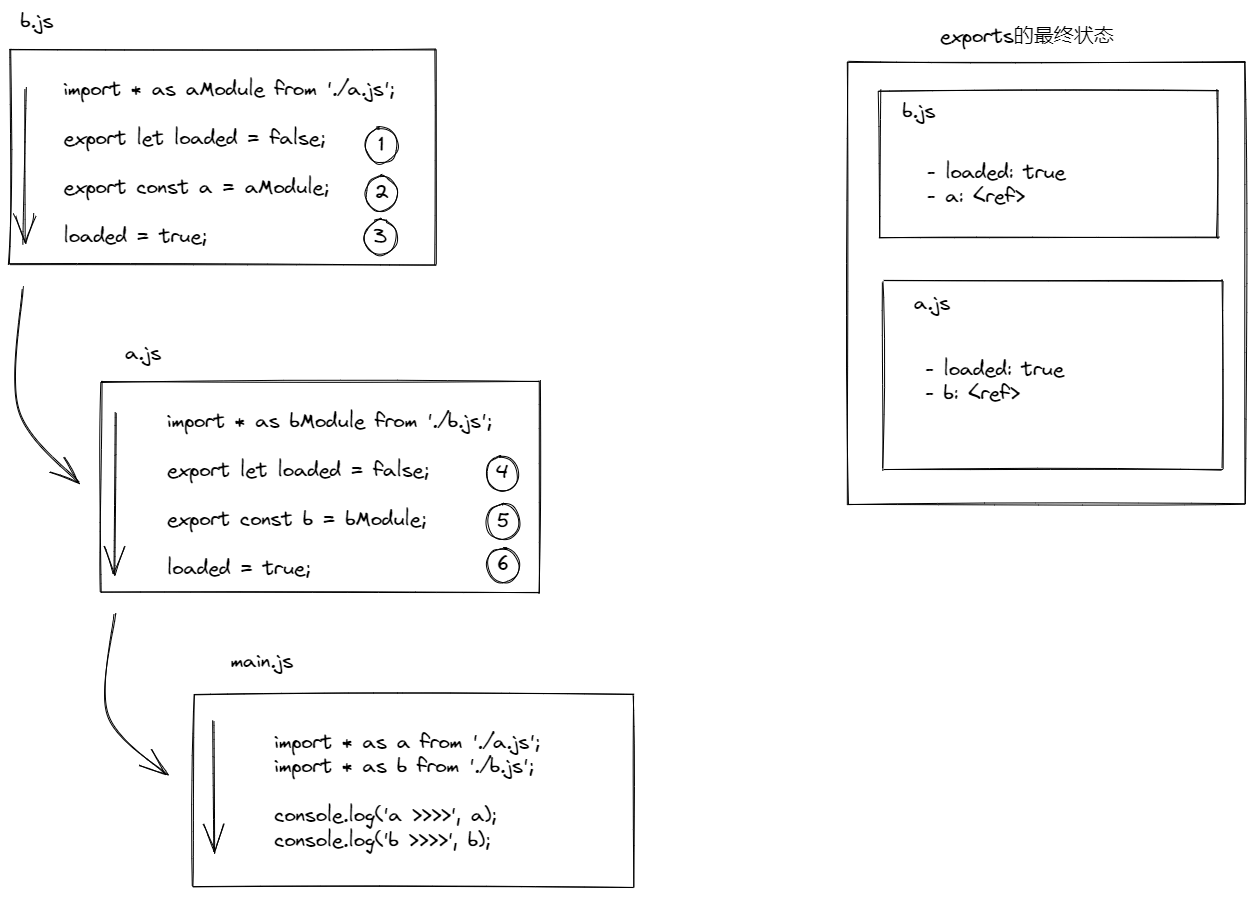
这时,各模块所导出的属性全都求值完毕,由于系统是通过引用而不是复制来引入模块的,因此就算模块之间有循环依赖关系,每个模块也还是能够完整地看到对方的最终状态。参考资料

若有收获,就点个赞吧
0 人点赞
