回调地狱
import fs from 'fs'import path from 'path'import superagent from 'superagent'import mkdirp from 'mkdirp'import { urlToFilename } from './utils.js'export function spider (url, cb) {const filename = urlToFilename(url)fs.access(filename, err => { // [1]if (err && err.code === 'ENOENT') {console.log(`Downloading ${url} into ${filename}`)superagent.get(url).end((err, res) => { // [2]if (err) {cb(err)} else {mkdirp(path.dirname(filename), err => { // [3]if (err) {cb(err)} else {fs.writeFile(filename, res.text, err => { // [4]if (err) {cb(err)} else {cb(null, filename, true)}})}})}})} else {cb(null, filename, false)}})}
涉及回调的编程技巧与控制流模式
编写回调逻辑时所应遵循的原则
写异步函数的第一准则:不要滥用闭包
减少嵌套层级的原则:
- 尽早退出。根据上下文,使用 return、continue 或 break 等关键字实现退出,而不要编写完整的 if…else 语句
- 用带有名称的函数表示回调逻辑,并把这些函数写在闭包结构的外面,如果需要传递中间结果,通过参数传递
- 提高代码的模块化程度。尽量把代码分成比较小且可复用的函数
运用相关的原则编写回调
尽早返回原则(early return principle):移除 else 语句,在发现错误后立即返回
if (err) {return cb(err);}// 没有出错的情况下应该执行的代码
将可以复用的代码抽离到单独的函数中 ```typescript function saveFile (filename, contents, cb) { mkdirp(path.dirname(filename), err => { if (err) { return cb(err) } fs.writeFile(filename, contents, cb) }) }
function download (url, filename, cb) {
console.log(Downloading ${url})
superagent.get(url).end((err, res) => {
if (err) {
return cb(err)
}
saveFile(filename, res.text, err => {
if (err) {
return cb(err)
}
console.log(Downloaded and saved: ${url})
cb(null, res.text)
})
})
}
export function spider (url, cb) { const filename = urlToFilename(url) fs.access(filename, err => { if (!err || err.code !== ‘ENOENT’) { // [1] return cb(null, filename, false) } download(url, filename, err => { if (err) { return cb(err) } cb(null, filename, true) }) }) }
<a name="OuBXG"></a>## sequential execution (顺序执行)<a name="cDV5W"></a>### executing a known set of tasks in sequence (顺序执行一组固定的任务)重点在于把每项任务都包装成一个单元```typescriptfunction asyncOperation (cb) {process.nextTick(cb)}function task1 (cb) {asyncOperation(() => {task2(cb)})}function task2 (cb) {asyncOperation(() => {task3(cb)})}function task3 (cb) {asyncOperation(() => {cb() // finally executes the callback})}task1(() => {// executed when task1, task2 and task3 are completedconsole.log('tasks 1, 2 and 3 executed')})
按先后顺序迭代集合中的元素(sequential iterator)
创建名为 iterator 的函数,以触发集合中的下一项任务,并确保此任务执行完毕时,会继续触发后面应该执行的那项任务
const tasks = [(cb) => {console.log('Task 1')setTimeout(cb, 1000)},(cb) => {console.log('Task 2')setTimeout(cb, 1000)},(cb) => {console.log('Task 3')setTimeout(cb, 1000)}]function iterate (index) {if (index === tasks.length) {return finish()}const task = tasks[index]task(() => iterate(index + 1))}function finish () {// iteration completedconsole.log('All tasks executed')}iterate(0)
如果 task () 是个同步操作,那么这种算法可能会陷入深层递归,因为此时程序不会像 task() 是异步操作时那样,立即从 iterate 中返回,而是会立即进入下一层递归,可能会让调用栈的深度超过系统的最大值。
如果是异步操作,系统会将 task 函数在异步逻辑里面所请求的下一轮迭代,安排到事件循环的下一个周期去执行,而不会让调用栈继续变深。
平行执行
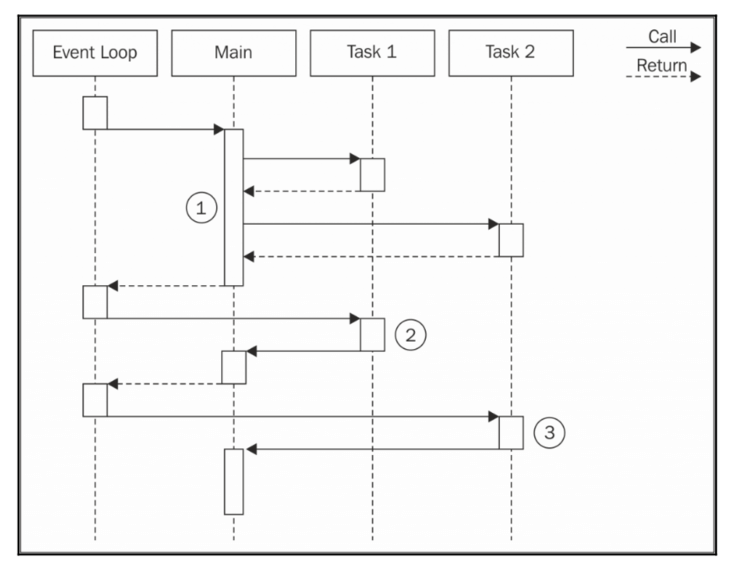
只有异步操作,才能在 node 中平行地运行,因为它们能够通过非阻塞式的 API 得到处理,从而形成并发的效果。Node 平台无法并发地执行同步操作(阻塞式),可以通过和异步穿插起来,或用 setTimeout() 与 setImmediate() 等手段安排此类操作异步地执行。
平行执行集合中的各项任务时所采用的模式
Unlimited parallel execution (数量不限的平行执行)模式 把所有任务全都启动起来,让这些任务平行地运行,并关注已经完成的任务数量,等所有任务都完成后触发回调
function makeSampleTask (name) {return (cb) => {console.log(`${name} started`)setTimeout(() => {console.log(`${name} completed`)cb()}, Math.random() * 2000)}}const tasks = [makeSampleTask('Task 1'),makeSampleTask('Task 2'),makeSampleTask('Task 3'),makeSampleTask('Task 4')]let completed = 0tasks.forEach(task => {task(() => {if (++completed === tasks.length) {finish()}})})function finish () {// all the tasks completedconsole.log('All tasks executed!')}
平行地运行多项任务时,可能会遇到数据竞争现象,即这些任务可能会争用外部资源(例如文件或数据库里的记录)
使用该模式:
function spiderLinks (currentUrl, body, nesting, cb) {if (nesting === 0) {return process.nextTick(cb)}const links = getPageLinks(currentUrl, body)if (links.length === 0) {return process.nextTick(cb)}let completed = 0let hasErrors = falsefunction done (err) {if (err) {hasErrors = truereturn cb(err)}if (++completed === links.length && !hasErrors) {return cb()}}links.forEach(link => spider(link, nesting - 1, done))}
设计 hasErrors 这个变量,用来记录这些平行执行的 spider 任务里面是否有哪个任务在处理过程中发生错误,因为需要在出现这种情况的时候,立即触发 cb 所表示的回调逻辑。另外,在所有 spider 任务都处理完毕的时候,还需要根据这个变量的值,来判断是否需要触发 cb,以免重复触发。
解决并发任务之间的数据争用问题
这种问题出现很频繁的根本原因,在于触发异步操作与获得操作结果之间,是有延迟的。
争用的例子:
export function spider (url, nesting, cb) {const filename = urlToFilename(url)fs.readFile(filename, 'utf8', (err, fileContent) => {if (err) {if (err.code !== 'ENOENT') {return cb(err)}return download(url, filename, (err, requestContent) => {if (err) {return cb(err)}spiderLinks(url, requestContent, nesting, cb)})}spiderLinks(url, fileContent, nesting, cb)})}
在同一个 URL 上操作的两个爬虫任务可能会在两个任务中针对同一份文件调用 fs.readFile(),这两个任务在调用时都发现该文件不存在,所以会分别安排自己的下载任务。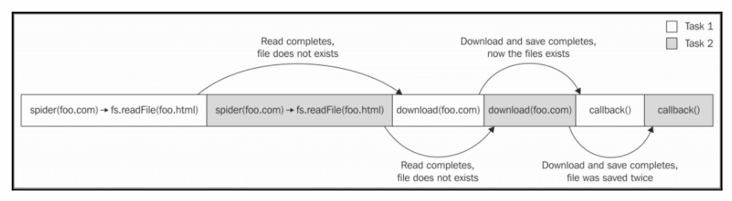
解决办法:
const spidering = new Set();function spider(url, nesting, cb) {if (spidering.has(url)) {return process.nextTick(cb);}spidering.add(url);}
限制任务数量的平行执行
不进行限制可能会导致的问题:
- 将进程能够使用的所有文件描述符用完
- 遭受 Dos (denial-of-service,拒绝服务)攻击
限制并发数量
``typescript function makeSampleTask (name) { return (cb) => { console.log(${name} started`) setTimeout(() => {
}, Math.random() * 2000) } }console.log(`${name} completed`)cb()
const tasks = [ makeSampleTask(‘Task 1’), makeSampleTask(‘Task 2’), makeSampleTask(‘Task 3’), makeSampleTask(‘Task 4’), makeSampleTask(‘Task 5’), makeSampleTask(‘Task 6’), makeSampleTask(‘Task 7’) ]
const concurrency = 2 let running = 0 let completed = 0 let index = 0
function next () { // [1] while (running < concurrency && index < tasks.length) { const task = tasks[index++] task(() => { // [2] if (++completed === tasks.length) { return finish() } running— next() }) running++ } } next()
function finish () { // all the tasks completed console.log(‘All tasks executed!’) }
<a name="fIYZc"></a>### 限制整个程序的并发数量<a name="bfu5J"></a>#### 利用队列确保任务总数不突破全局上限```typescriptexport class TaskQueue {constructor (concurrency) {this.concurrency = concurrencythis.running = 0this.queue = []}pushTask (task) {this.queue.push(task)process.nextTick(this.next.bind(this))return this}next () {while (this.running < this.concurrency && this.queue.length) {const task = this.queue.shift()task(() => {this.running--process.nextTick(this.next.bind(this))})this.running++}}}
在通过 process.nextTick 异步调用 next 时,必须拿 bind 函数给那次调用绑定执行情景(上下文),不然等真正触发时,next 无法获取自身到底应该在什么情景下执行。
完善 TaskQueue 类
将 TaskQueue 变成 EventEmitter 类,具备广播相应事件的能力,使得在任务失败或队列已经清空的时候通知用户
import { EventEmitter } from 'events'export class TaskQueue extends EventEmitter {constructor (concurrency) {super()this.concurrency = concurrencythis.running = 0this.queue = []}pushTask (task) {this.queue.push(task)process.nextTick(this.next.bind(this))return this}next () {if (this.running === 0 && this.queue.length === 0) {return this.emit('empty')}while (this.running < this.concurrency && this.queue.length) {const task = this.queue.shift()task((err) => {if (err) {this.emit('error', err)}this.running--process.nextTick(this.next.bind(this))})this.running++}}}
import { TaskQueue } from './TaskQueue.js'function makeSampleTask (name) {return (cb) => {console.log(`${name} started`)setTimeout(() => {console.log(`${name} completed`)cb()}, Math.random() * 2000)}}const queue = new TaskQueue(2)queue.on('error', console.error)queue.on('empty', () => console.log('Queue drained'))// A task that spawns other 2 sub tasksfunction task1 (cb) {console.log('Task 1 started')queue.pushTask(makeSampleTask('task1 -> subtask 1')).pushTask(makeSampleTask('task1 -> subtask 2'))setTimeout(() => {console.log('Task 1 completed')cb()}, Math.random() * 2000)}// A task that spawns other 3 sub tasksfunction task2 (cb) {console.log('Task 2 started')queue.pushTask(makeSampleTask('task2 -> subtask 1')).pushTask(makeSampleTask('task2 -> subtask 2')).pushTask((done) => done(new Error('Simulated error'))).pushTask(makeSampleTask('task2 -> subtask 3'))setTimeout(() => {console.log('Task 2 completed')cb()}, Math.random() * 2000)}queue.pushTask(task1).pushTask(task2)
参考资料

若有收获,就点个赞吧
0 人点赞
