如何应对初始化过程中需要执行异步任务的组件
初始化过程中含有异步任务的组件所面对的问题
import { EventEmitter } from 'events'class DB extends EventEmitter {connected = falseconnect () {// simulate the delay of the connectionsetTimeout(() => {this.connected = truethis.emit('connected')}, 500)}async query (queryString) {// 初始化未完成,用户无法做查询if (!this.connected) {throw new Error('Not connected yet')}console.log(`Query executed: ${queryString}`)}}export const db = new DB()
本地初始化检查
在程序调用该模块的 API 前,先确保模块的初始化工作已经完成,即这个模块在执行每一种异步操作之前,都必须先检查自己是否已经初始化完毕
import { once } from 'events'import { db } from './db.js'db.connect()async function updateLastAccess () {if (!db.connected) {// 监听 connected 事件来判断是否已经初始化完毕await once(db, 'connected')}await db.query(`INSERT (${Date.now()}) INTO "LastAccesses"`)}updateLastAccess()setTimeout(() => {updateLastAccess()}, 600)
延迟启动
先把组件自身的初始化流程做完,然后再安排执行那些依赖于该组件的操作
import { once } from 'events'import { db } from './db.js'async function initialize () {db.connect()await once(db, 'connected')}async function updateLastAccess () {await db.query(`INSERT (${Date.now()}) INTO "LastAccesses"`)}initialize().then(() => {updateLastAccess()setTimeout(() => {updateLastAccess()}, 600)})
该方法存在的缺点:
- 必须提前确定有哪些组件会用到这个初始化过程中带有异步操作的组件
- 整个应用程序的启动时间可能会拖得比较长
- 如果某些组件在程序运行过程中,需要重新初始化也不好处理
预初始化队列(pre-initialization queue)
采用队列与 Command 命令模式,如果组件还没有初始化好,那就把这些必须在组件初始化完毕之后才能执行的方法调用(method invocation)操作,添加到队列里面,等所有的初始化步骤都完成之后,再将队列中的这些操作取出来执行
import { EventEmitter } from 'events'class DB extends EventEmitter {connected = falsecommandsQueue = []async query (queryString) {if (!this.connected) {console.log(`Request queued: ${queryString}`)return new Promise((resolve, reject) => {const command = () => {this.query(queryString).then(resolve, reject)}this.commandsQueue.push(command)})}console.log(`Query executed: ${queryString}`)}connect () {// simulate the delay of the connectionsetTimeout(() => {this.connected = truethis.emit('connected')this.commandsQueue.forEach(command => command())this.commandsQueue = []}, 500)}}export const db = new DB()
使用 State 模式来提升代码的模块程度:
上述代码存在以下两种状态:
- 该组件已经初始化完毕:在这个状态下,每个方法都只需要直接实现自己的业务逻辑即可,而不用担心组件的初始化问题
- 组件还没有初始化完毕:这个状态实现的方法不会真的去执行业务逻辑,只是把用户想要执行的操作及其参数封装到 command(命令)对象中,并将该对象推入队列而已 ```typescript import { EventEmitter } from ‘events’
// 记录必须等待初始化完毕才执行的方法 const METHODS_REQUIRING_CONNECTION = [‘query’] const deactivate = Symbol(‘deactivate’)
// 表示完成初始化的状态
class InitializedState {
async query (queryString) {
console.log(Query executed: ${queryString})
}
}
class QueuingState { constructor (db) { this.db = db this.commandsQueue = []
METHODS_REQUIRING_CONNECTION.forEach(methodName => {this[methodName] = function (...args) {console.log('Command queued:', methodName, args)return new Promise((resolve, reject) => {const command = () => {db[methodName](...args).then(resolve, reject)}this.commandsQueue.push(command)})}})
}
// 组件在离开(deactivate)该状态时触发该方法 // 使用 Symbol 避免 DB 类中存在同名方法导致冲突 [deactivate] () { this.commandsQueue.forEach(command => command()) this.commandsQueue = [] } }
class DB extends EventEmitter { constructor () { super() this.state = new QueuingState(this) }
async query (queryString) { return this.state.query(queryString) }
connect () { // simulate the delay of the connection setTimeout(() => { this.connected = true this.emit(‘connected’) const oldState = this.state this.state = new InitializedState(this) oldState[deactivate] && oldStatedeactivate }, 500) } }
export const db = new DB()
<a name="hyOdW"></a># 批量处理异步请求并缓存处理结果<a name="kB8PE"></a>## 批量处理异步请求如果在执行某个异步函数的时候,程序中还有相同的调用操作尚未执行完毕,可以让这次调用操作跟正在等待处理的那次操作一起得到执行,而不用发出全新的调用请求。<br />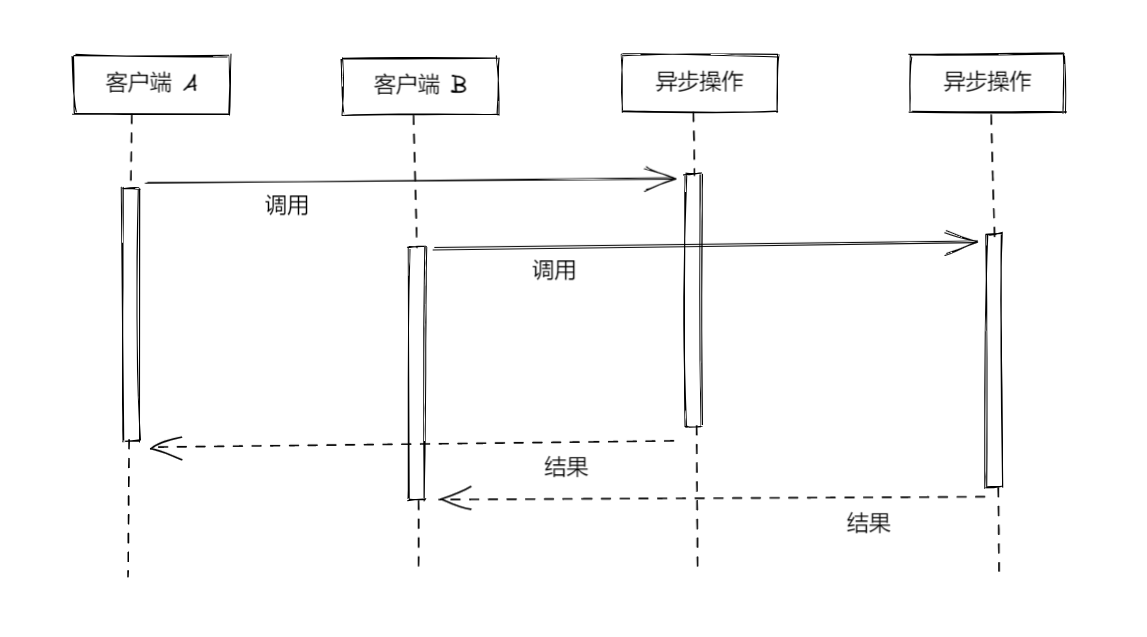<br />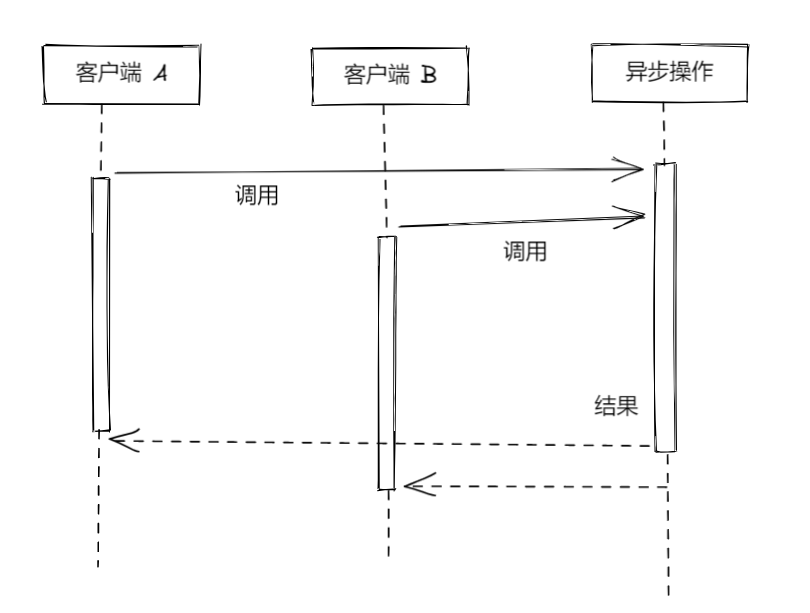<a name="VDAMv"></a>## 用更好的办法来缓存异步请求的处理结果把批处理与缓存相结合(combined request batching and caching pattern)<br />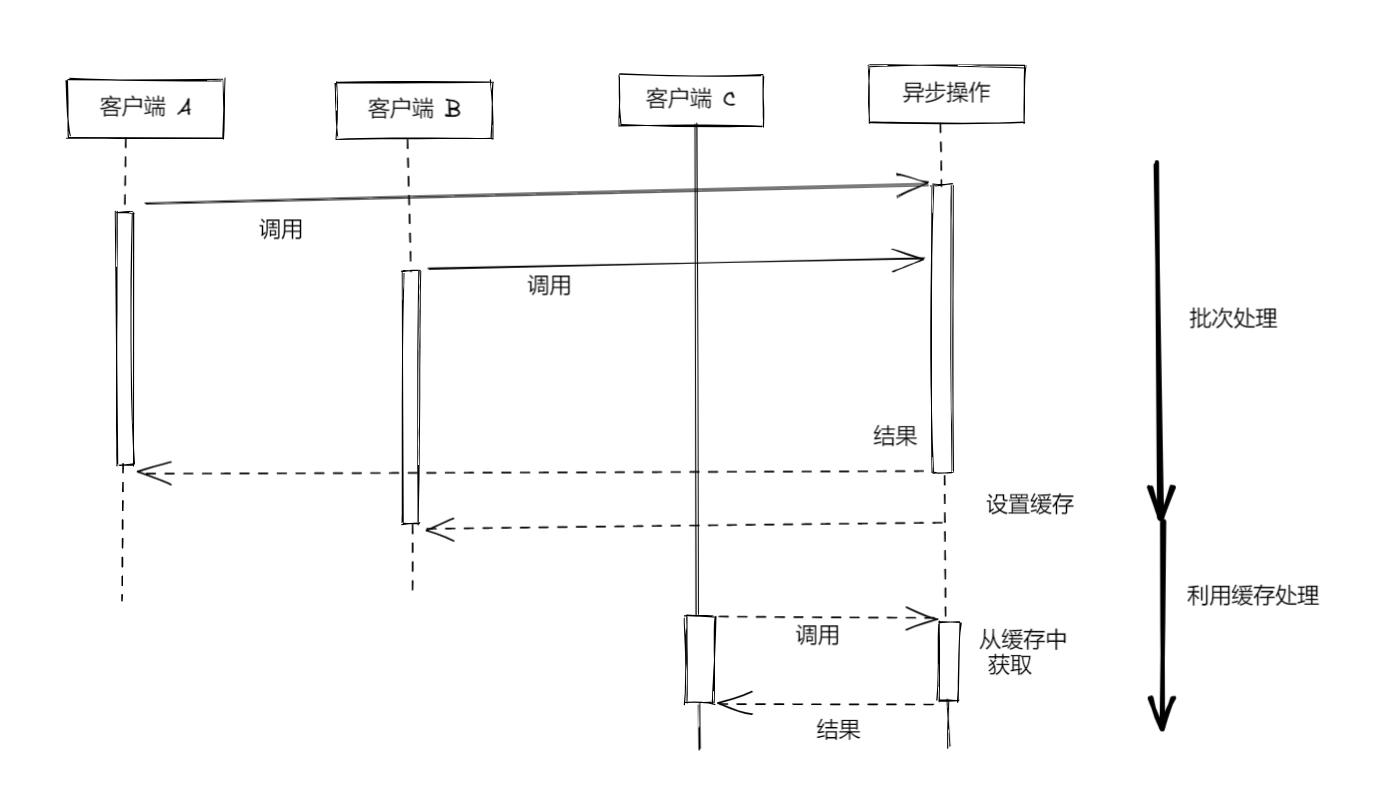1. 在缓存还没有得到设置的情况下,凡是内容相同的调用请求,都编入同一批次加以处理。等到请求处理完毕,把缓存一次设置好1. 缓存已经得到设置,此时程序可以直接从缓存中获取执行结果<a name="x78C2"></a>## 不带缓存或批处理机制的 API 服务```typescriptimport level from 'level'import sublevel from 'subleveldown'const db = level('example-db')const salesDb = sublevel(db, 'sales', { valueEncoding: 'json' })export async function totalSales (product) {const now = Date.now()let sum = 0for await (const transaction of salesDb.createValueStream()) {if (!product || transaction.product === product) {sum += transaction.amount}}console.log(`totalSales() took: ${Date.now() - now}ms`)return sum}
import { createServer } from 'http'import { totalSales } from './totalSales.js'createServer(async (req, res) => {const url = new URL(req.url, 'http://localhost')const product = url.searchParams.get('product')console.log(`Processing query: ${url.search}`)const sum = await totalSales(product)res.setHeader('Content-Type', 'application/json')res.writeHead(200)res.end(JSON.stringify({product,sum}))}).listen(8000, () => console.log('Server started'))
利用 Promise 实现批处理与缓存
Promise 能够实现这两个功能的原因:
- 同一个 Promise 能够挂接多个 then() 监听器:借助这个特性能够实现批处理
- then() 监听器肯定能够得到调用,而且只会调用一次。就算是在 Promise 已经解决之后才挂接这个监听器的,它依然会得到执行,then() 总是会以异步的方式执行:这些特性说明 Promise 天然具有一种缓存的特性
让 Web 服务器采用批处理的方式返回销售总量
如果程序调用 API 的时候,发现目前已经有一个相同的调用请求正在处理,那么它就不发出新的请求,而是等待正在处理的这项请求执行完毕。利用 Promise 实现上述功能,只需要构建一张映射表(map),key 就是某一项调用请求所涉及的具体参数,value 就是用 Promise 表示的这些请求的具体情况。 在遇到请求的时候,用请求参数在映射表中查询,如果存在直接返回 Promise 对象,否则再发出新的调用请求。
import { totalSales as totalSalesRaw } from './totalSales.js'const runningRequests = new Map()export function totalSales (product) {if (runningRequests.has(product)) {console.log('Batching')return runningRequests.get(product)}const resultPromise = totalSalesRaw(product)runningRequests.set(product, resultPromise)resultPromise.finally(() => {runningRequests.delete(product)})return resultPromise}
request batching(批量处理请求)模式最适合用于负载较高且 API 执行速度较慢的场合,这种场合运用批处理,可以把大量的请求归到同一组里面执行
让 Web 服务器采用批处理与缓存相结合的方式返回销售总量
import { totalSales as totalSalesRaw } from './totalSales.js'const CACHE_TTL = 30 * 1000 // 30 seconds TTLconst cache = new Map()export function totalSales (product) {if (cache.has(product)) {console.log('Cache hit')return cache.get(product)}const resultPromise = totalSalesRaw(product)cache.set(product, resultPromise)resultPromise.then(() => {setTimeout(() => {cache.delete(product)}, CACHE_TTL)}, err => {cache.delete(product)throw err})return resultPromise}
实现缓存机制时的注意事项
- 缓存较多时,占用的内存较大:可以使用 LRU(least recently used,最久未用)策略或 FIFO(first in first out,先进先出)策略,来限制缓存的数据量
- 如果应用程序跨越多个进程,那么把缓存数据简单地放在每条进程自身的内存中,可能导致每个服务器实例看到不同的缓存值:让多份实例能够访问同一缓存(Redis)
- 为了让缓存长期发挥作用并及时得到更新,除了根据各条缓存数据的加入或使用时间来制定缓存失效策略,还可以手工管理缓存,但会相当复杂(如果发现程序里的某个值发生了变化,而这个值在缓存里面也有着相应的条目,那我们可以考虑手工同步两者)
取消异步操作
采用最基本方案创建可叫停的函数
每执行一次异步调用,就判断一下,这项调用是否应该取消,如果应该,那就提前退出这个函数export function asyncRoutine (label) {console.log(`Starting async routine ${label}`)return new Promise(resolve => {setTimeout(() => {console.log(`Async routine ${label} completed`)resolve(`Async routine ${label} result`)}, 100)})}
```typescript import { asyncRoutine } from ‘./asyncRoutine.js’ import { CancelError } from ‘./cancelError.js’export class CancelError extends Error {constructor () {super('Canceled')this.isCanceled = true}}
async function cancelable (cancelObj) { const resA = await asyncRoutine(‘A’) console.log(resA)
// 判断是否需要叫停函数 if (cancelObj.cancelRequested) { throw new CancelError() }
const resB = await asyncRoutine(‘B’) console.log(resB) if (cancelObj.cancelRequested) { throw new CancelError() }
const resC = await asyncRoutine(‘C’) console.log(resC) }
const cancelObj = { cancelRequested: false }
// 只有当 cancelable 把控制权交还给事件循环后,外部代码才能设置 cancelRequested 的状态 // 所以 cancelable 只需要在这项异步操作执行完毕后,去检查 cancelRequested 的取值即可 // 而没必要检查的太过频繁 cancelable(cancelObj) .catch(err => { if (err instanceof CancelError) { console.log(‘Function canceled’) } else { console.error(err) } })
setTimeout(() => { cancelObj.cancelRequested = true }, 100)
<a name="twW9f"></a>## 把可叫停的异步函数所要执行的异步调用包装起来设计包装器,提供包装函数(wrapping function),把异步函数所要执行的异步操作,连同判断该函数是否应该提前退出的那些逻辑,一并包装起来。```typescriptimport { CancelError } from './cancelError.js'export function createCancelWrapper () {let cancelRequested = falsefunction cancel () {cancelRequested = true}function cancelWrapper (func, ...args) {if (cancelRequested) {return Promise.reject(new CancelError())}return func(...args)}return { cancelWrapper, cancel }}
import { asyncRoutine } from './asyncRoutine.js'import { createCancelWrapper } from './cancelWrapper.js'import { CancelError } from './cancelError.js'async function cancelable (cancelWrapper) {const resA = await cancelWrapper(asyncRoutine, 'A')console.log(resA)const resB = await cancelWrapper(asyncRoutine, 'B')console.log(resB)const resC = await cancelWrapper(asyncRoutine, 'C')console.log(resC)}const { cancelWrapper, cancel } = createCancelWrapper()cancelable(cancelWrapper).catch(err => {if (err instanceof CancelError) {console.log('Function canceled')} else {console.error(err)}})setTimeout(() => {cancel()}, 100)
利用生成器实现可叫停的异步函数
import { CancelError } from './cancelError.js'// generatorFunction 是个生成器函数,表示有待监控的原函数export function createAsyncCancelable (generatorFunction) {return function asyncCancelable (...args) {const generatorObject = generatorFunction(...args)let cancelRequested = falsefunction cancel () {cancelRequested = true}const promise = new Promise((resolve, reject) => {// prevResult 表示原函数里面的上一条 yield 语句所产生的结果async function nextStep (prevResult) {if (cancelRequested) {return reject(new CancelError())}if (prevResult.done) {return resolve(prevResult.value)}try {nextStep(generatorObject.next(await prevResult.value))} catch (err) {try {nextStep(generatorObject.throw(err))} catch (err2) {reject(err2)}}}nextStep({})})return { promise, cancel }}}
import { asyncRoutine } from './asyncRoutine.js'import { createAsyncCancelable } from './createAsyncCancelable.js'import { CancelError } from './cancelError.js'const cancelable = createAsyncCancelable(function * () {const resA = yield asyncRoutine('A')console.log(resA)const resB = yield asyncRoutine('B')console.log(resB)const resC = yield asyncRoutine('C')console.log(resC)})const { promise, cancel } = cancelable()promise.catch(err => {if (err instanceof CancelError) {console.log('Function canceled')} else {console.error(err)}})setTimeout(() => {cancel()}, 100)
运行 CPU 密集型任务
如果执行的不是异步操作,而是耗时很久的同步任务,需要等同步任务执行完毕,才能交还控制权,这样的任务称为 CPU-bound(CPU 密集型)任务,因为它依赖的是 CPU 资源,并且依赖得很迫切,而不是某些任务那样主要依赖 I/O 资源
解决 subset sum(子集合加总)问题
import { EventEmitter } from 'events'export class SubsetSum extends EventEmitter {constructor (sum, set) {super()this.sum = sumthis.set = setthis.totalSubsets = 0}// 递归找寻原集合中的每一个非空子集_combine (set, subset) {for (let i = 0; i < set.length; i++) {const newSubset = subset.concat(set[i])this._combine(set.slice(i + 1), newSubset)this._processSubset(newSubset)}}// 检查子集之和是否符合目标值_processSubset (subset) {console.log('Subset', ++this.totalSubsets, subset)const res = subset.reduce((prev, item) => (prev + item), 0)// 找到目标后向外暴露事件if (res === this.sum) {this.emit('match', subset)}}// 将整个流程串联起来start () {this._combine(this.set, [])this.emit('end')}}
通过 setImmediate 分步执行
CPU 密集型算法,通常都是由一系列步骤组成,我们没必要非得把这一系列步骤一次性执行完毕,可以每执行一步(或几步)就把控制权还给事件循环一次,这样事件循环就可以利用这个时间段,来执行那些还在等待的 I/O 操作
简单的实现方案:利用 setImmediate 函数让程序在事件循环把等待处理的这些 I/O 操作执行完后,能够继续执行算法的下一个步骤
import { EventEmitter } from 'events'export class SubsetSum extends EventEmitter {constructor (sum, set) {super()this.sum = sumthis.set = setthis.totalSubsets = 0}// 将递归操作放到 setImmediate 中去做,可以给事件循环留出时间空隙_combineInterleaved (set, subset) {this.runningCombine++setImmediate(() => {this._combine(set, subset)if (--this.runningCombine === 0) {this.emit('end')}})}_combine (set, subset) {for (let i = 0; i < set.length; i++) {const newSubset = subset.concat(set[i])this._combineInterleaved(set.slice(i + 1), newSubset)this._processSubset(newSubset)}}_processSubset (subset) {console.log('Subset', ++this.totalSubsets, subset)const res = subset.reduce((prev, item) => prev + item, 0)if (res === this.sum) {this.emit('match', subset)}}start () {this.runningCombine = 0this._combineInterleaved(this.set, [])}}
存在的问题:
- 效率不够理想,把某项任务的下一个步骤安排到稍后去执行,会给程序增加少量开销,如果算法的步骤特别多,这些开销累计起来会比较大,因为这些步骤会过久地占用 CPU 资源
如果任务的每一步都需要花费比较长的时间,事件循环会在一个比较长的时间段内失去响应,出现卡顿现象
使用外部进程执行任务
把计算子集合加总问题的任务交给外部进程去执行
为什么不等到真正使用进程的时候再去建立新的进程?
新建一条进程是个相当耗费资源的操作,需要耗费时间,所以不如提前建立好一批进程,让它们一直运行着,并把它们放在进程池中。程序可以随时取出一条使用,节省时间,又不会过多地占用 CPU 周期
- 能够限定同时运行的进程数量,让应用程序不会无休止地创建新的进程,可以防止有人对程序发起 DOS(denial-of-service,拒绝服务)攻击
实现线程池
```typescript import { fork } from ‘child_process’
export class ProcessPool { constructor (file, poolMax) { this.file = file // 表示需要用子进程来运行的那个 Node.js 程序 this.poolMax = poolMax // 表示进程池中最多能有几个实例运行 this.pool = [] // 表示进程池中准备好接受新任务的那些进程 this.active = [] // 表示当前正在执行任务的那些进程 this.waiting = [] // 存放回调的队列 }
// 从进程池取出空余进程执行任务 acquire () { return new Promise((resolve, reject) => { let worker if (this.pool.length > 0) { worker = this.pool.pop() this.active.push(worker) return resolve(worker) }
if (this.active.length >= this.poolMax) {return this.waiting.push({ resolve, reject })}worker = fork(this.file)worker.once('message', message => {// 进程给我们发送 ready 信息,表明其已经启动起来,可以接受新的任务if (message === 'ready') {this.active.push(worker)return resolve(worker)}worker.kill()reject(new Error('Improper process start'))})worker.once('exit', code => {console.log(`Worker exited with code ${code}`)this.active = this.active.filter(w => worker !== w)this.pool = this.pool.filter(w => worker !== w)})})
}
// 把执行完任务的进程放回进程池中 release (worker) { if (this.waiting.length > 0) { const { resolve } = this.waiting.shift() return resolve(worker) }
// waiting 列表没有任务请求需要处理,将这条进程从 active 列表删除,放回进程池this.active = this.active.filter(w => worker !== w)this.pool.push(worker)
} }
要想减低程序占用内存的数量,并让进程池更灵活,可以使用下面两项优化技术:- 如果某条进程闲置的时间达到一定限度,那就终止该进程,以释放内存- 添加一套机制,用来终止那些失去响应的进程,或者重启那些崩溃的进程<a name="qlSeJ"></a>#### 与子进程交互工作进程都是使用 child_process.fork() 创建,用该函数创建出的子进程,自动具备一条基于消息的简单通道,可以用来与其交互```typescriptimport { EventEmitter } from 'events'import { dirname, join } from 'path'import { fileURLToPath } from 'url'import { ProcessPool } from './processPool.js'const __dirname = dirname(fileURLToPath(import.meta.url))const workerFile = join(__dirname,'workers', 'subsetSumProcessWorker.js')const workers = new ProcessPool(workerFile, 2)export class SubsetSum extends EventEmitter {constructor (sum, set) {super()this.sum = sumthis.set = set}async start () {const worker = await workers.acquire()worker.send({ sum: this.sum, set: this.set })const onMessage = msg => {if (msg.event === 'end') {worker.removeListener('message', onMessage)workers.release(worker)}this.emit(msg.event, msg.data)}worker.on('message', onMessage)}}
实现子进程自己的逻辑
import { SubsetSum } from '../subsetSum.js'process.on('message', msg => {const subsetSum = new SubsetSum(msg.sum, msg.set)subsetSum.on('match', data => {process.send({ event: 'match', data: data })})subsetSum.on('end', data => {process.send({ event: 'end', data: data })})subsetSum.start()})process.send('ready')
如果子进程不是 Node.js 程序,我们就无法像刚才那样,在它上面调用 on() 与 send() 等方法。这种情况下,可以利用子进程公布给上级进程的标准输入流与标准输出流,自己建立一套协议,让双方通过这套协议所描述的结构来通行
用工作线程执行任务
工作线程(worker thread)占据的内存数量比进程少,且这些线程都位于同一条主进程中,所以启动起来较快。
工作线程本身并不跟主应用程序所在的线程共享信息,而是运行在自己的 v8 实例中,该实例拥有独立的 Node.js 运行时环境与事件循环。它跟主线程之间,可以利用基于消息的通信渠道来沟通,两者之间可以传输 ArrayBuffer 对象,用户可以利用 SharedArrayBuffer 对象做数据同步(这通常还需要借助 Atomics)
import { Worker } from 'worker_threads'export class ThreadPool {constructor (file, poolMax) {this.file = filethis.poolMax = poolMaxthis.pool = []this.active = []this.waiting = []}acquire () {return new Promise((resolve, reject) => {let workerif (this.pool.length > 0) {worker = this.pool.pop()this.active.push(worker)return resolve(worker)}if (this.active.length >= this.poolMax) {return this.waiting.push({ resolve, reject })}worker = new Worker(this.file)worker.once('online', () => {this.active.push(worker)resolve(worker)})worker.once('exit', code => {console.log(`Worker exited with code ${code}`)this.active = this.active.filter(w => worker !== w)this.pool = this.pool.filter(w => worker !== w)})})}release (worker) {if (this.waiting.length > 0) {const { resolve } = this.waiting.shift()return resolve(worker)}this.active = this.active.filter(w => worker !== w)this.pool.push(worker)}}
import { EventEmitter } from 'events'import { dirname, join } from 'path'import { fileURLToPath } from 'url'import { ThreadPool } from './threadPool.js'const __dirname = dirname(fileURLToPath(import.meta.url))const workerFile = join(__dirname,'workers', 'subsetSumThreadWorker.js')const workers = new ThreadPool(workerFile, 2)export class SubsetSum extends EventEmitter {constructor (sum, set) {super()this.sum = sumthis.set = set}async start () {const worker = await workers.acquire()worker.postMessage({ sum: this.sum, set: this.set })const onMessage = msg => {if (msg.event === 'end') {worker.removeListener('message', onMessage)workers.release(worker)}this.emit(msg.event, msg.data)}worker.on('message', onMessage)}}
import { parentPort } from 'worker_threads'import { SubsetSum } from '../subsetSum.js'parentPort.on('message', msg => {const subsetSum = new SubsetSum(msg.sum, msg.set)subsetSum.on('match', data => {parentPort.postMessage({ event: 'match', data: data })})subsetSum.on('end', data => {parentPort.postMessage({ event: 'end', data: data })})subsetSum.start()})

若有收获,就点个赞吧
0 人点赞
