转自浙江大学可视化分析小组博客
发布于:2019-11-21 顾宇辉 / 报告 / 论文评述 / 访问:243
论文:Searching the Visual Style and Structure of D3 Visualizations
作者:Enamul Hoque, Maneesh Agrawala
发表:Proc IEEE InfoVis 2019, IEEE, 2019
本文针对D3可视化提供了一个搜索引擎,该引擎允许根据视觉样式和底层结构来进行查询,从而支持可视化开发人员进行设计空间探索以及信息查询。
动机
- 机器无法直接访问图表数据。
可视化的设计探索和统计分析困难。
- 开发人员搜寻样例来编码。
- 研究人员分析频繁的设计模式。
系统介绍
搜索引擎组成
本文提出的搜索引擎主要由3个部分组成:可视化爬虫,可视化解构和搜索界面。
可视化爬取
系统爬取了7860件D3可视化作品,来源包括d3.js,bl.ocks.org,the “Big List of D3 Example”,the New York Times,the Wall Street Journal等网站。可视化解构
针对每个可视化作品,系统会解析该可视化的数据、符号、数据到符号的映射以及背景颜色等非数据相关的属性,然后以json格式保存在数据库。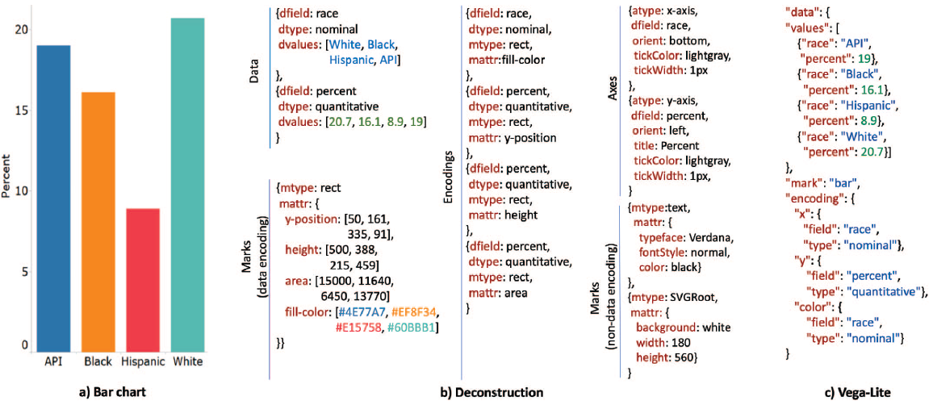
系统界面
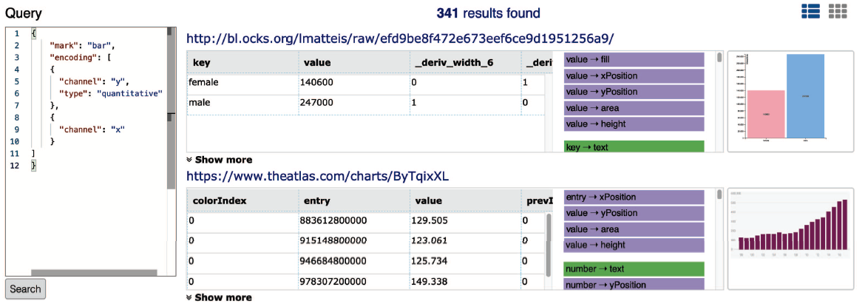
系统使用了基于Vega-lite的查询语法。查询返回的结果排序会基于排名策略和随机策略两种策略。排名策略会按按匹配的编码数量排序,若相同则比较不匹配的编码数量。应用
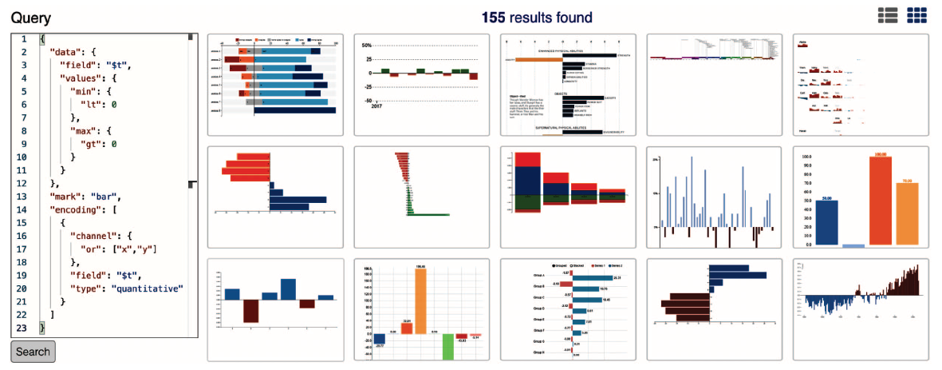
探索设计空间
查找正负值都有的柱形图可视化设计
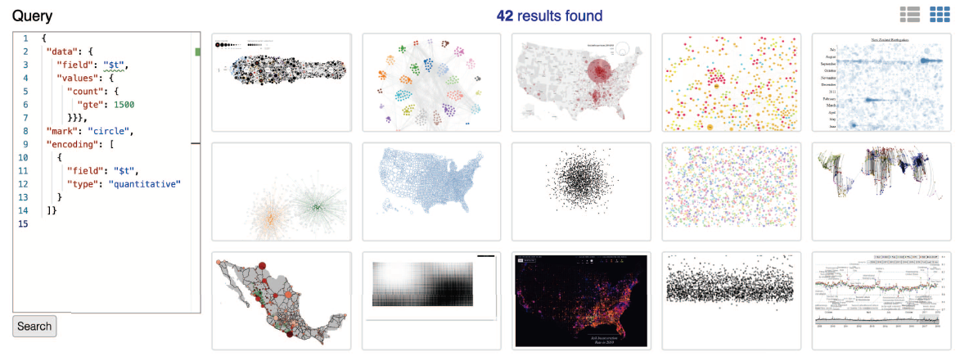
- 查找数据量大于1500的可视化设计
- 通过样例来查找编码相近的可视化设计
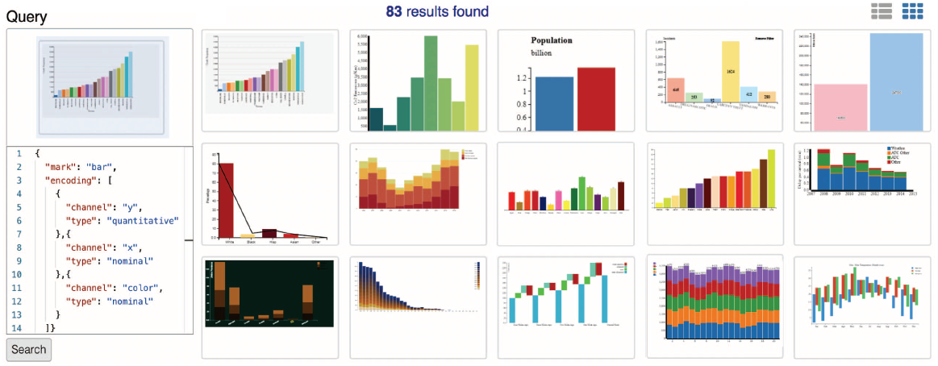
- 查找背景颜色相似(在LAB色彩空间上)的可视化设计
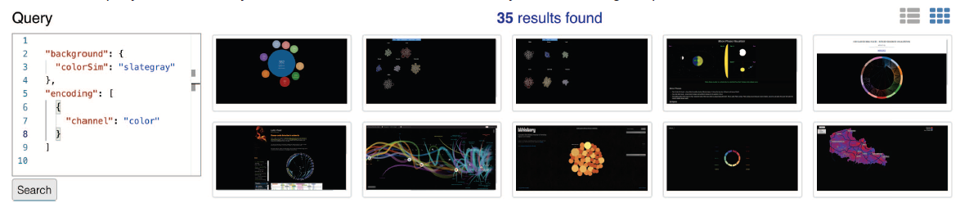
信息查询
用户如果希望找到与特定主题相关的可视化,可以通过指定相应的关键字来搜索。例如查找美国选举相关的可视化:
| 1234 | {“keyword”: “US election”,”encoding”: [{“channel”: “color”, “type”: “nominal”,”values”: {“and”:[“red”, “blue”]} }]} |
|---|---|
有时数据字段的名称可能与用户指定的名称完全不同,而是使用语义相似的同义词。对于这种情况,本文使用word2vec向量模型来计算单词间的语义相似度,可以通过“wordSim”字段来指定。
| 1 | {“data”:{“field”: {“wordSim”: “population”}}} |
|---|---|
可视化设计统计分析
为了确定D3图表开发人员常用的视觉设计模式,本文使用搜索引擎对7860件D3可视化集合进行了统计分析。同时为了进行比较,独立分析了从《纽约时报》抓取的457件D3图表的子集合。
根据统计结果,对标记的使用,标记属性的使用,多属性映射的使用,相关/不相关属性对的使用以及填充颜色的使用5个方面进行了讨论。分析表明,可视化开发人员在创建D3可视化时往往遵循最佳设计实践。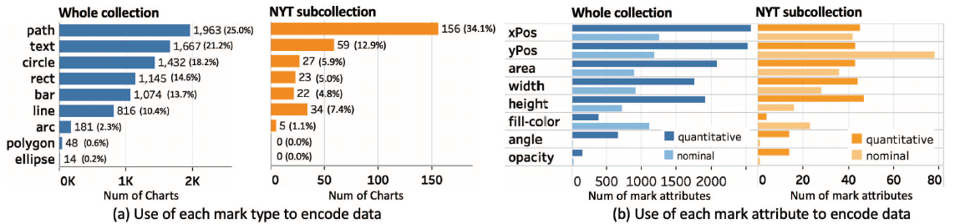
user study
为了评估本文搜索引擎的有效性,本文设计了user study:12名拥有可视化经验的人员分别使用本文的系统以及SightLine来进行探索性的搜索任务,每个任务都对应了在某个场景下需要用户查找符合某些设计标准的5个可视化作品。最后实验人员需要完成问卷。问卷结果表明在有效性,满意度和明确性上本文的系统高于SightLine。
讨论
不足

若有收获,就点个赞吧
0 人点赞
