创建节点和关系 create
创建一个家谱
CREATE (erzi:Person {id:'erzi'}),(baba:Person {id:'baba'}),(yeye:Person {id:'yeye',name:'zhangsan'}),(nainai:Person {id:'nainai'}),(mama:Person {id:'mama'}),(bozi:Person {id:'bozi'}),(erzi)-[:fathor]->(baba),(baba)-[:fathor]->(yeye),(baba)-[:mother]->(nainai),(erzi)-[:mother]->(mama),(erzi)-[:girlFrend]->(bozi)
查询 match
MATCH (n:Person) where n.RETURN n
添加新关系merge
先查询出来再merge
Match (n:Person {id:'erzi'}),(f:Person {id:'bozi'})Merge (n)-[:fuqi]->(f)
merge如果有则查询,如果没有则创建,相当于create或match
替换关系merge
Match (n:Person ),(f:Person)where n.and f.Merge (n)-[r:fuqi]->(f) delete rMerge (n)-[:FUQI]->(f)return n,f
更新set
更新属性
Match (n:Person {id:'baba'}) set n.name='张三' return n
属性名是写数据时自动创建,无schme特性,这点痛no-sql库;支持非结构化数据——非结构化:不同行得数据可以有不同得列个数
Match (n:Person {id:'baba'}) set n.name='张三',n.age=50 return n
删除 delete, remove
delete: 操作删除节点和关系
remove: 操作删除标签和属性
两个命令都应该和match命令一起用
删除节点和关系
MATCH (s:Teacher)-[r:teach]->(d:Student) delete r,s,d //删除与该关系相关的老师和学生及labelMATCH (n:Test) remove n:Test //删除label
仅仅删一个关系,不删节点
Match (a:Person),(b:Person) where a.and b.merge (a)-[r:FUQI]->(b) DELETE r
排序 order by
降序
MATCH (n:Person) RETURN n order by n.id,n.name desc LIMIT 25`
升序
MATCH (n:Person) RETURN n order by n.id LIMIT 25
Limit和Skip
Limit:显示多少行,最前边开始,一般查询都会带limit控制行数
Skip:跳过前多少行
MATCH (n:Person) RETURN n order by n.id desc skip 2 LIMIT 25
Union和union all
Union:把多段Match的return结果上限组合成一个结果集,会自动去掉重复行;
Union all:作用同Union,但不去重,常用,因为一般不会需要去重
MATCH (n:Person) where n.age>20 RETURN n.id,n.ageunion allMATCH (n:Person) where n.RETURN n.id,n.age
Null 需要注意什么
可以把检索出的空行去掉
MATCH (n:Person)where n.age>20 RETURN n.id,n.ageunion allMATCH (n:Person)where n.and n.ageis not nullRETURN n.id,n.age
where属性is null;is not null 其实同关系sql语法
in 语法
功能同上
MATCH (n:Person) where n.age>20 RETURN n.id,n.age union all MATCH (n:Person) where n.id in ['erzi','bozi','baba'] RETURN n.id,n.age
内置id
每个节点或relation都有个系统分配的id,从0开始递增,全局唯一!
create(a:Person{iid:’123’}) //这里的id是一个属性,和内置id是两码事
通过函数id(node/relation)可以获取id值
不透明,犹如Oracle里的rowid
用户可定义id属性,与内置id无关
Relation具有方向性
create节点之间关系时,必须指定方向,否则会报错:
查询时有时不关心关系的方向性,可以不带方向查询
MATCH (n:Person)-[:FUQI]-(s:Person) RETURN distinct n,s
索引index
增加搜索性能
create index on :Person(id); //创建id字段索引
drop index on :Person(id); //删除索引
根据查询需要,把查询多的字段建索引
create index on :Person(name) //给name字段也建索引;
- 不需要给索引其名称,只需要设置索引的字段即可;
- 通过该字段的查询都走索引,不论索引字段有没有套函数
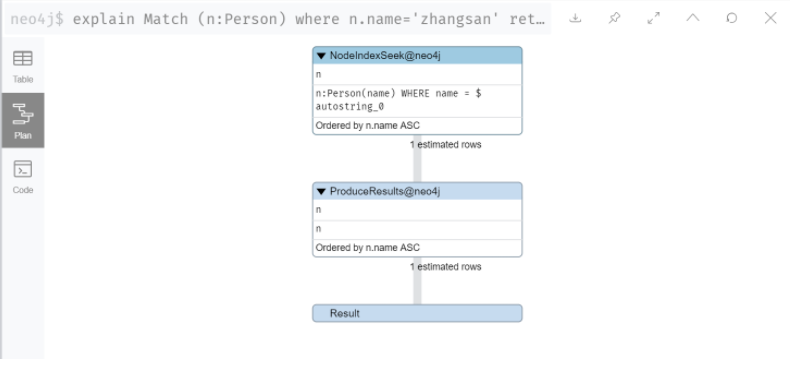
可以给某一属性设置唯一约束
CREATE CONSTRAINT ON (a:Person) ASSERT a.id IS UNIQUE // 创建约束drop CONSTRAINT ON (a:Person) ASSERT a.id IS UNIQUE //删除约束
函数
功能 描述
UPPER 它用于将所有字母更改为大写字母。
LOWER 它用于将所有字母改为小写字母。
SUBSTRING 它用于获取给定String的子字符串。
REPLACE 它用于替换一个字符串的子字符串。
Match (n:Person) return SUBSTRING(n.id,2,0),n.id
聚集函数 描述
COUNT 它返回由MATCH命令返回的行数。
MAX 它从MATCH命令返回的一组行返回最大值。
MIN 它返回由MATCH命令返回的一组行的最小值。
SUM 它返回由MATCH命令返回的所有行的求和值。
AVG 它返回由MATCH命令返回的所有行的平均值。
聚集函数
Neo4j 无group by
Match (n:Person) return count(*)Match (n:Person) return avg(n.age) //只包含age不为空的node
shortestPath 查询最短路径
6层关系理论:任何两个事物之间的关系都不会超过6层。
查询最短路径的必要性
allShortestPaths
//[*..n] 用于表示获取n层关系match p=shortestPath((n:Person {id:'mama'})-[*..3]-(b:Person {id:'nainai'})) return p //随机显示一条n层关系路match p=allshortestPaths((n:Person {id:'mama'})-[*..3]-(b:Person {id:'nainai'})) return p //显示全部关系链路
关系链路越短,代表这两个节点的关系越密切!
语法大全手册

若有收获,就点个赞吧
0 人点赞
