
这是一篇针对语义分割进行蒸馏的论文。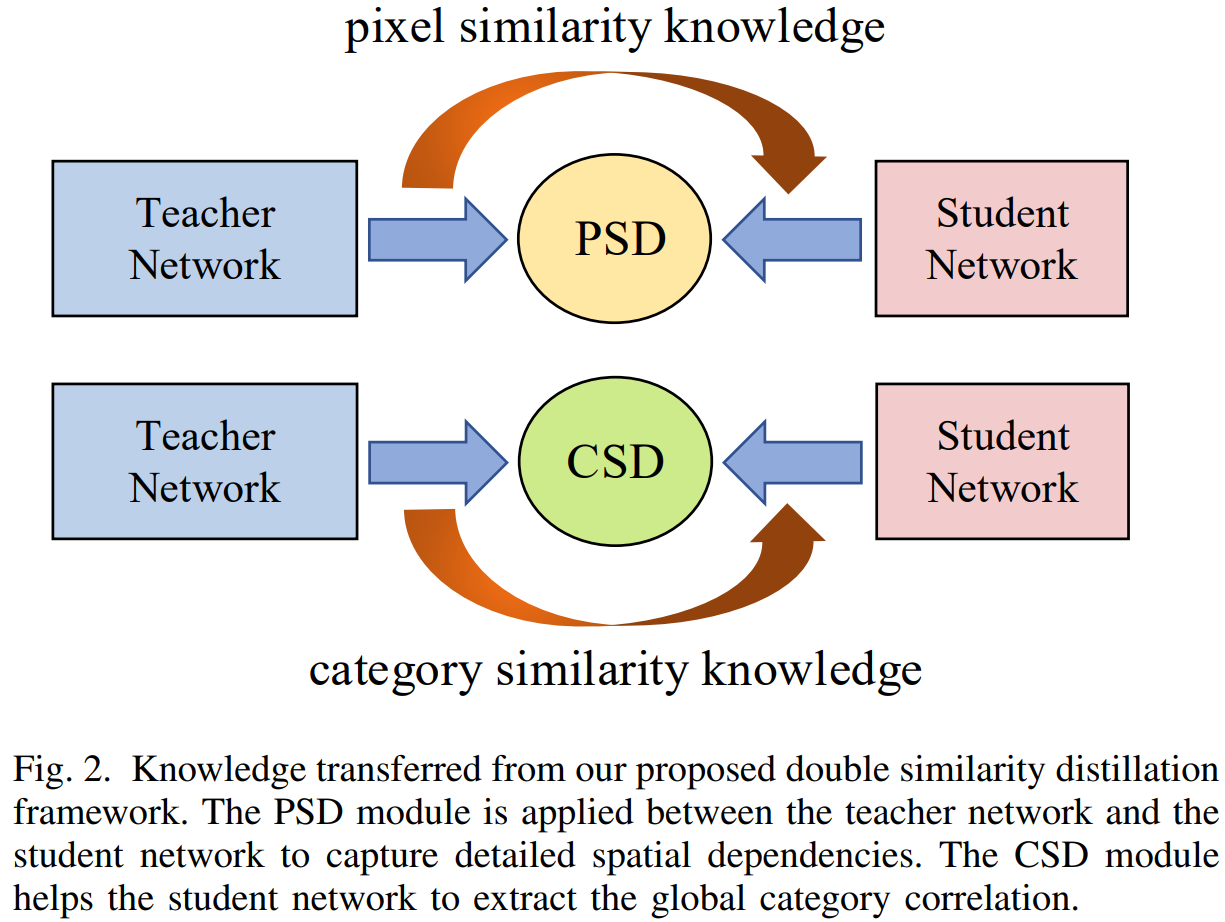
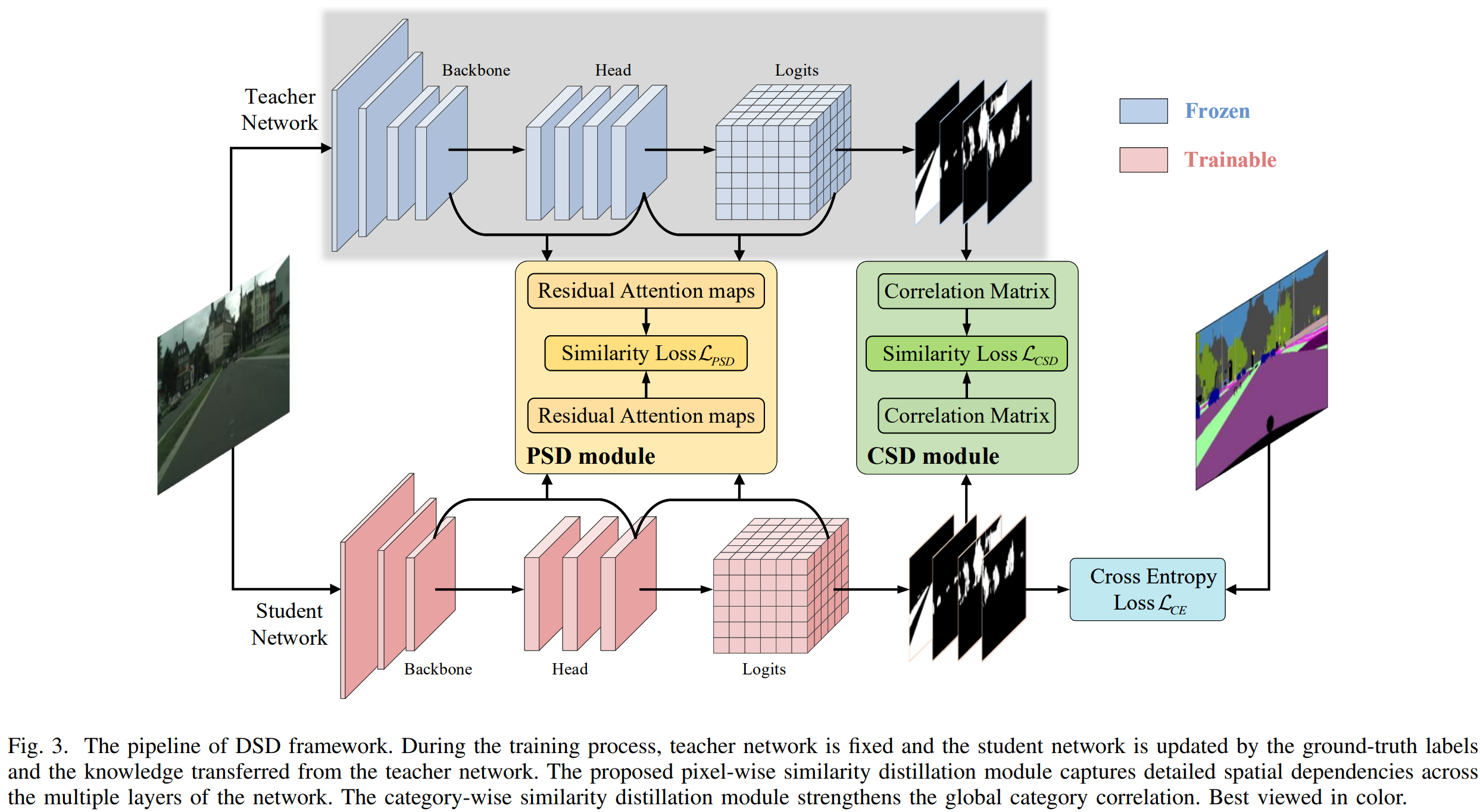
提出了两个核心蒸馏策略,一个是Pixel-wise Similarity Distillation Module,这用于以较少的参数和计算量学习空间依赖关系。另一个是Category-wise Similarity Distillation Module,用于学习全局的类别信息的相关性。
PSD
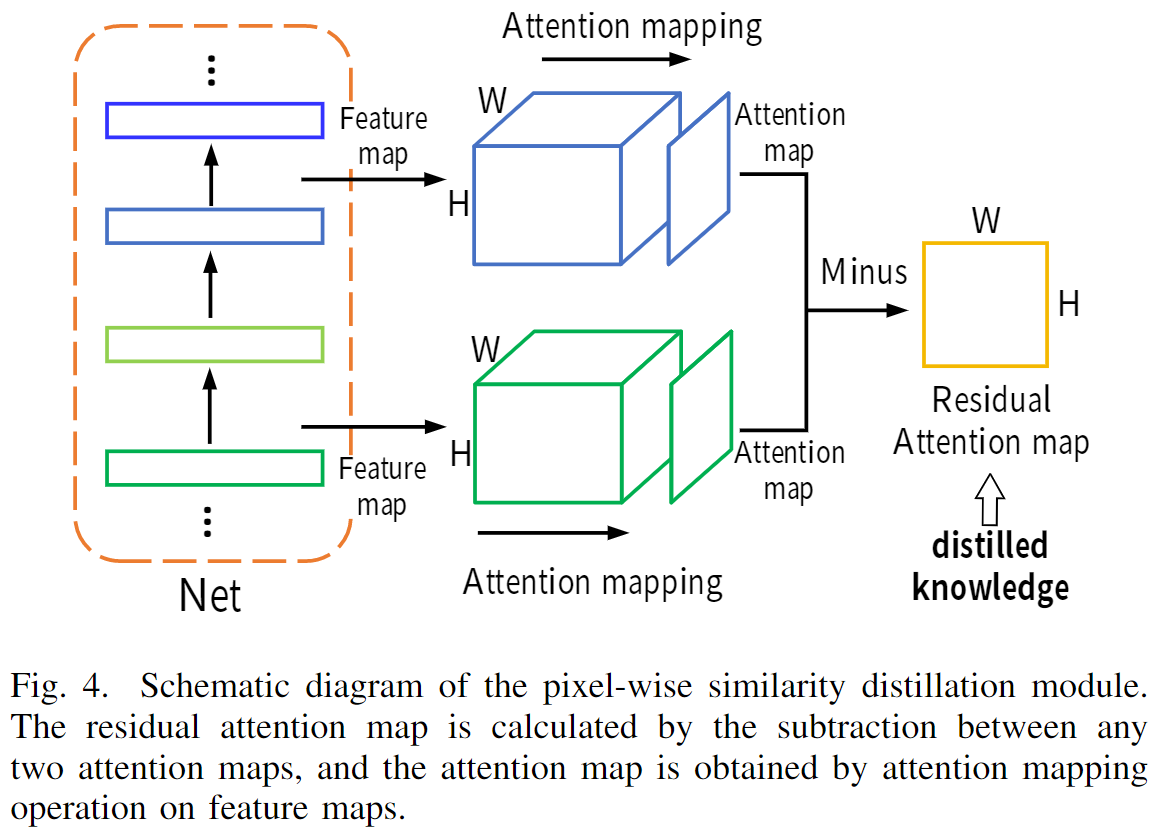

这里使用相邻层的特征图计算归一化注意力图的差值。
注意力图的计算基于Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer(ICLR 2017) 中提出的运算形式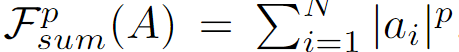
设置p为2来获取映射函数。
Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transf
这里使用L2损失监督: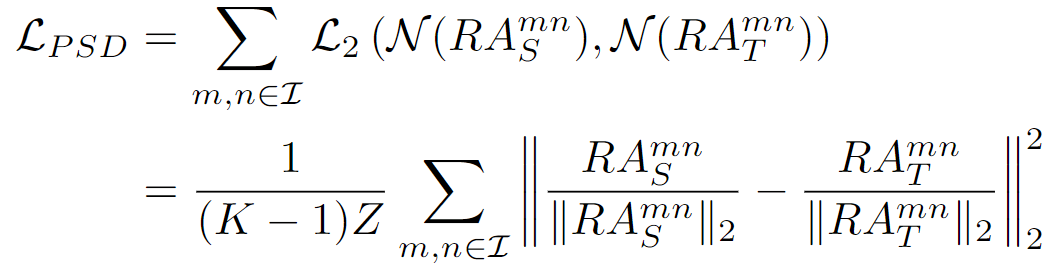
CSD
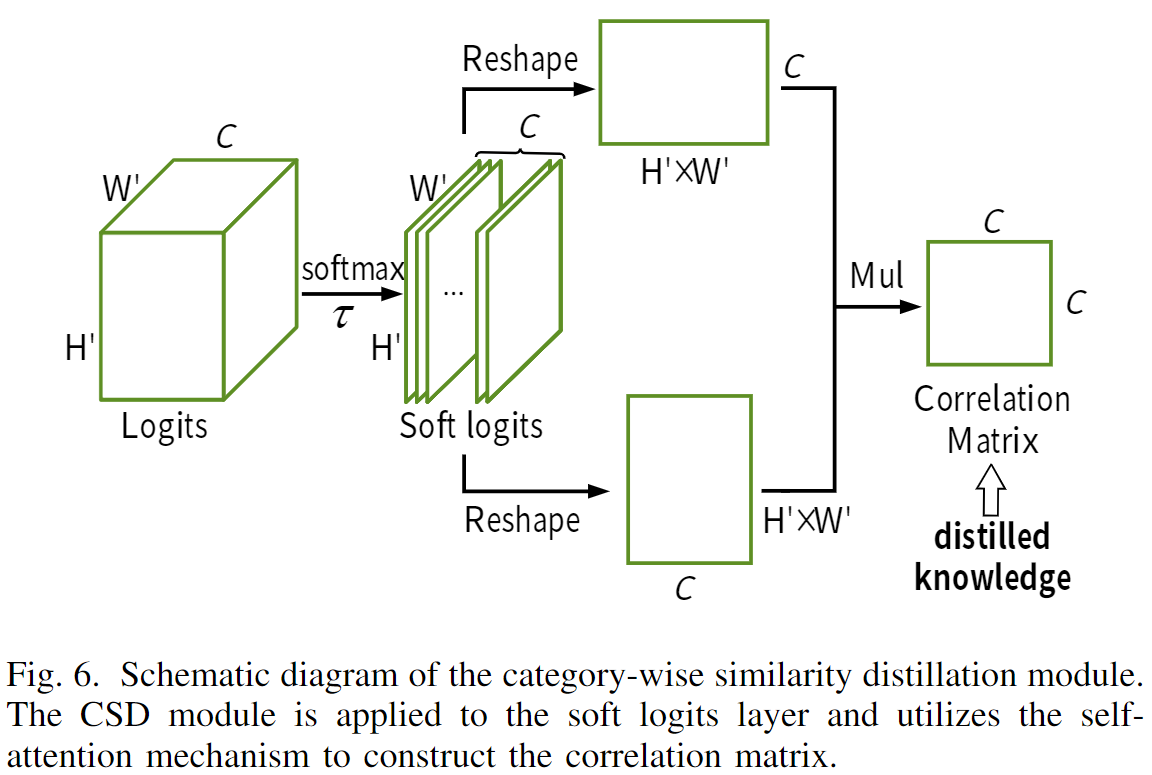
这里直接对logits使用带有温度系数的softmax处理获得soft logits。之后计算通道相关性。
Then, we can get the soft logits q = softmax(z/τ), where τ is the temperature to soften the output.
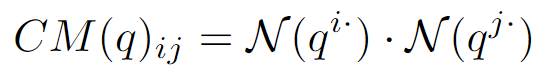
注意,这里的N表示L2归一化。
denotes the l2-normalized feature vector.
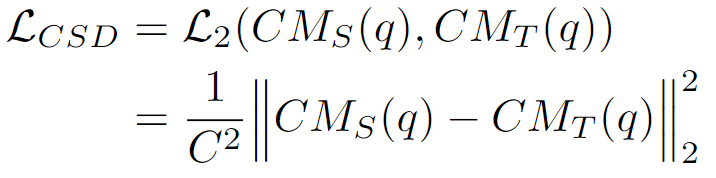
链接

若有收获,就点个赞吧
0 人点赞
