
@inproceedings{ying2018DML,author = {Ying Zhang and Tao Xiang and Timothy M. Hospedales and Huchuan Lu},title = {Deep Mutual Learning},booktitle = {CVPR},year = {2018}}
主要工作
提出了一种简单且普遍适用的方法,通过在相同/不同的未预训练的网络中进行相互蒸馏,来提高深层神经网络的性能。通过这种方法,我们可以获得比静态教师从强网络中提取的网络性能更好的紧凑网络。
和有教师指导的蒸馏模型相比,相互学习策略具有以下优点:
- 随着学生网络的增加其效率也得到提高;
- 它可以应用在各种各样的网络中,包括大小不同的网络;
- 即使是非常大的网络采用相互学习策略,其性能也能够得到提升
由于是学生网络相互学习,而不是传统知识萃取,文章也说明了两个以上网络共同学习的策略,并从熵值的角度给出理论支持。
主要结构
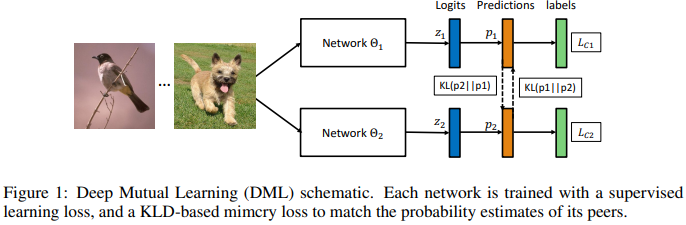

损失函数
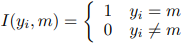
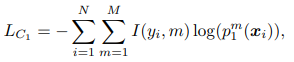
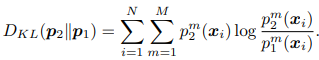
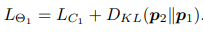
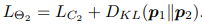
这里展示是两个小网络情况下对于分类任务损失的计算。也可以扩展到多个小网络的情况。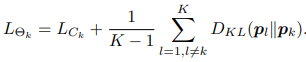
或者是平均: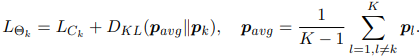
相关链接

若有收获,就点个赞吧
0 人点赞
