
相关链接
- 论文: https://arxiv.org/pdf/1606.02147.pdf
- 解读:https://blog.csdn.net/u011974639/article/details/78956380
结构细节
结构块
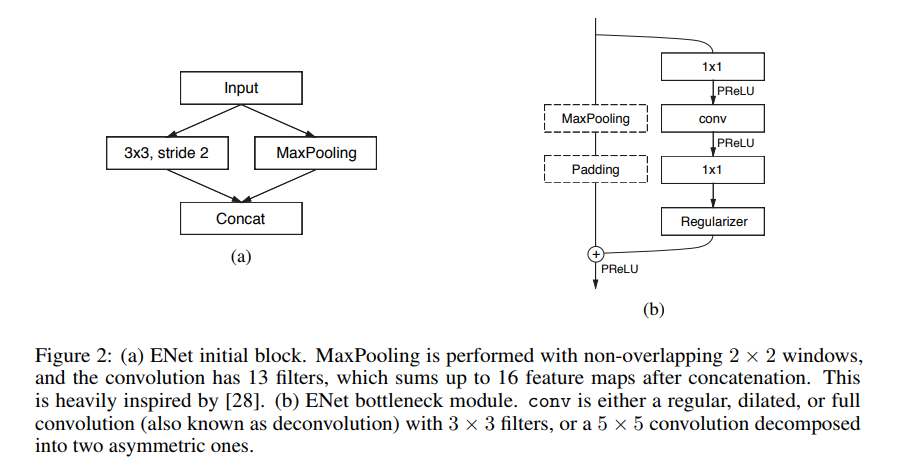
每个block共两条路线,学习残差。这里主要讲在encoder阶段的构成。分为两种情况:
- 下采样的bottleneck:
- 主线包括三个卷积层
- 先是2×2投影做降采样。
- 然后是卷积(有三种可能,Conv普通卷积,asymmetric分解卷积,Dilated空洞卷积)。
- 后面再接一个1×1的做升维。
- 注意每个卷积层后均接Batch Norm和PReLU。
- 辅线包括最大池化和Padding层
- 最大池化负责提取上下文信息。
- Padding负责填充通道,达到后续的残差融合。
- 融合后再接PReLU。
- 主线包括三个卷积层
- 非下采样的bottleneck:
- 主线包括三个卷积层
- 先是1×1投影。
- 然后是卷积(有三种可能,Conv普通卷积,asymmetric分解卷积,Dilated空洞卷积)。
- 后面再接一个1×1的做升维。
- 注意每个卷积层后均接Batch Norm和PReLU。
- 辅线
- 直接恒等映射(只有下采样才会增加通道数,故这里不需要padding层)。
- 融合后再接PReLU。
- 主线包括三个卷积层
整体结构
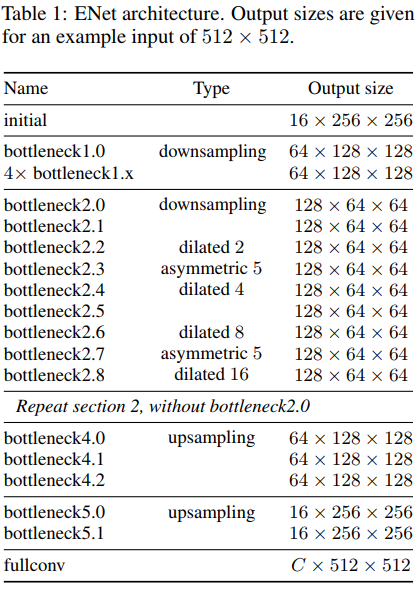
ENet模型大致分为5个Stage:
- initial:初始化模块。左边是做3×3/str=2的卷积,右边是做MaxPooling,将两边结果concat一起,做通道合并,这样可以上来显著减少存储空间。
- Stage 1:encoder阶段。包括5个bottleneck,第一个bottleneck做下采样,后面4个重复的bottleneck。
- Stage 2-3:encoder阶段。
- stage2的bottleneck2.0做了下采样,后面有时加空洞卷积,或分解卷积。
- stage3没有下采样,其他都一样。
- Stage 4~5:属于decoder阶段。比较简单,一个上采样配置两个普通的bottleneck。
模型架构在任何投影上都没有使用bias,这样可以减少内核调用和存储操作。 在每个卷积操作中使用Batch Norm。encoder阶段是使用padding配合max pooling做下采样。在decoder时使用max unpooling配合空洞卷积完成上采样。
一些说明
许多移动应用需要实时语义分割(Real-time Semantic Segmentation)模型,现有的深度神经网络难以实现,问题在于深度神经网络需要大量的浮点运算,导致运行时间长,从而降低了时效性。ENet即针对这一问题提出的一种新型有效的深度神经网络,相比于现有的模型,在速度加快了18×倍,浮点计算量上减少了75×,参数减少了79×,且有相似的精度。ENet在CamVid, Cityscapes and SUN datasets做了相关对比测试。
在Semantic Segmentation领域,已经提出了几种神经网络体系结构,如SegNet或FCN。这些模型大多基于VGG架构,相比于传统方法,虽然精度上去了,但面临着模型参数多和前向推导时间长等问题,这对于许多需要10fp且长时间运行的移动设备难以实用。
本文中提出一种新的神经网络架构:ENet。优化了模型参数,保持模型的高精度和快速的前向推理时间。没有使用任何后端处理(可以配合一些后端处理,提高准确率)。在Cityscapes、CamVid、SUN dataset上做了验证,并使用NVIDIA Jetson TX1嵌入式设备和NVIDIA Titan X GPU上做了benchmark。
常见的Semantic Segmentation架构是使用两个独立的神经网络架构:一个encoder一个decoder。但是这些模型参数量太大,达不到实时要求。
有一些其他的体系使用更简单的分类器,然后使用条件随机场(CRF)最为后端处理步骤进行级联,但是这个方法难以标记小目标。CNN也可以与RNN相结合,但是这个会降低速度。

若有收获,就点个赞吧
0 人点赞
