
主要工作
这篇文章是BMVC 2019的一篇文章,可以看做是对Self-supervised knowledge distillation using singular value decomposition算法的改进。最大的不同之处在于SVD这篇使用径向基函数来生成关于特征转换的知识,而本文则是使用注意力网络(AN)来生成嵌入知识。文章认为这样获得的知识更加清晰(clearly)。
本文是一种基于图考虑数据间关系的方法,不同于之前考虑数据关系的蒸馏手段。文章也说:The main contribution point of the proposed method is to define graph-based knowledge for the first time.
文章利用non-local结构构建的注意力网络(这里在强调的是GNN)来挖掘数据之间的关系,继而实现知识的传输。教师网络的嵌入过程的知识被multi-head attention(MHA)蒸馏到图中,并且多任务学习使得学生网络可以获得关系归纳偏置。MHA可以提供清晰的关于原始数据集的信息,这可以极大地提升学生模型的性能。
文章构建的模块通过使用两个特征矢量集合作为输入,通过基于特征转换信息来获取数据内部(intra-data)的关系。使用模块中的attention heads表达两个特征矢量集合之间的不同的关系,这也是CNN网络最重要的知识。
归类现有蒸馏方法
这篇文章将之前的蒸馏方法进行了一个简单的归类:
- Response-based knowledge.
- Response-based knowledge is defined by the neural response of the hidden layer or the output layer of the network and was first introduced in Soft-logits [Distilling the knowledge in a neural network] proposed by Hinton et al.
- This method is simple, so it is good for general purpose, but it is relatively naive and has a small amount of information.
- Recently, various methods have been introduced to enhance teacher knowledge[Low-resolution face recognition in the wild via selective knowledge distillation, Improved knowledge distillation via teacher assistant: Bridging the gap between student and teacher].
- Multi-connection knowledge.
- In order to solve the problem that the amount of information of response-based knowledge is small, multi-connection knowledge which increases knowledge by sensing several points of the TN was presented [Fitnets: Hints for thin deep nets].
- However, since the complex knowledge of the TN is transferred as it is, it is impossible for the SN to mimic the TN. Since the SN is over-constrained, negative transfer may occur.
- Therefore, techniques for softening this phenomenon have recently been proposed [Knowledge transfer via distillation of activation boundaries formed by hidden neurons].
- Shared representation knowledge.
- To soften the constraints caused by teacher knowledge, Yim et al. proposed knowledge using shared representation [A gift from knowledge distillation: Fast optimization, network minimization and transfer learning].
- Shared representation knowledge is defined by the relation between two feature maps. While multiple connection is an approach to increase the amount of knowledge, shared representation is an approach to soften knowledge. So it can give proper constraint to the SN.
- Recently, Lee et al. proposed a method to find the relation of feature maps more effectively by using SVD [Self-supervised knowledge distillation using singular value decomposition].
主要结构
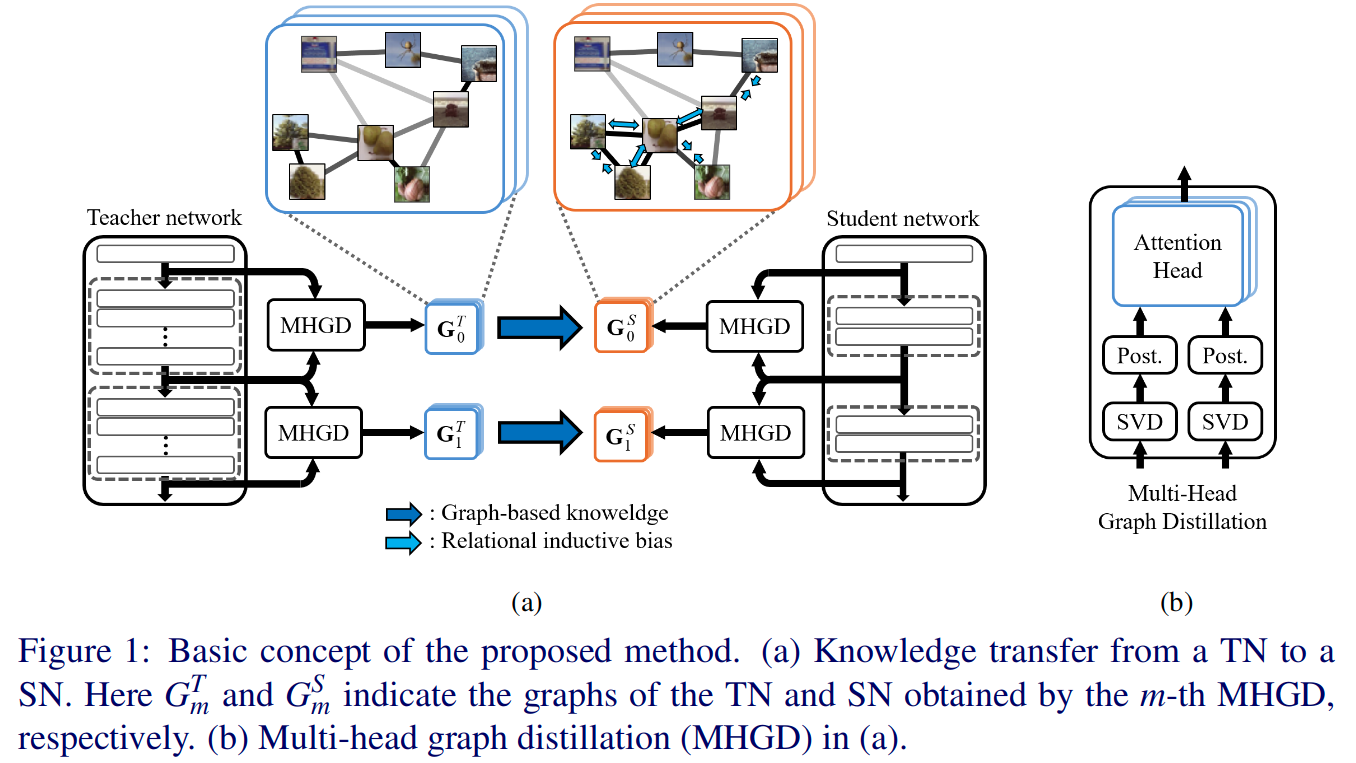
- 这里b中使用的SVD技术和后处理技术和Self-supervised knowledge distillation using singular value decomposition一样
- 最终使用目标任务(target task)和迁移蒸馏知识的任务一起进行多任务的训练
- 主要包含两个阶段:
- 学习MHGD的MHA来蒸馏关于教师网络的嵌入过程的知识
- 学习学生网络,通过转移生成自MHGD的基于图的知识
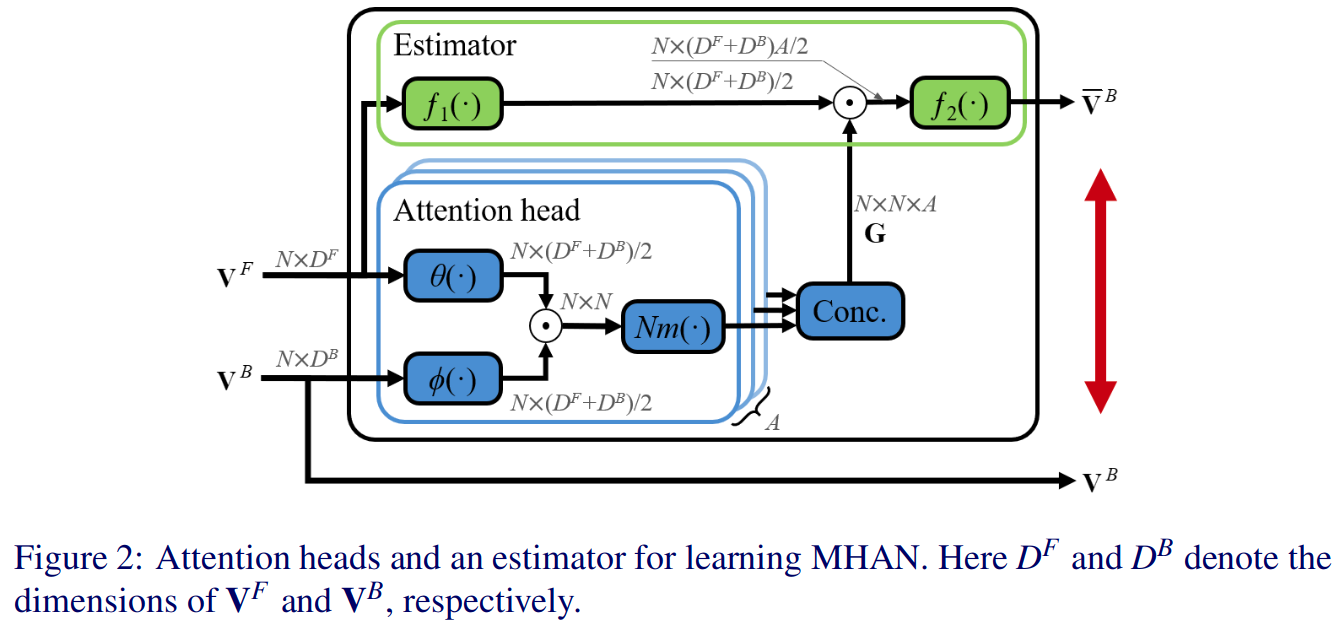
- 对于给定的任务,Attention Network可以计算key和query的近似关系,所以这里使用key、query来获取有用而嵌入知识。在这里对于给定key的query的估计可以看做是一个任务,而这个使得MHAN可以通过不需要标签的方式来学习。
- 这里的VF和VB表示的是MHAN的key和query,分别称为前端特征矢量集(frontend feature vector set)和后端特征矢量集(backend feature vector set),这都可以通过KD-SVD方法压缩两个特征图来获得。但是对应于网络中的特征,具体是如何对应的呢?(可以看下面代码,可以知道就是一个block的前后特征)
def MHGD(student_feature_maps, teacher_feature_maps):'''Seunghyun Lee, Byung Cheol Song.Graph-based Knowledge Distillation by Multi-head Attention Network.British Machine Vision Conference (BMVC) 2019'''with tf.variable_scope('MHGD'):GNN_losses = []num_head = 8V_Tb = V_Sb = Nonenum_feat = len(student_feature_maps)for i, sfm, tfm in zip(range(num_feat), student_feature_maps, teacher_feature_maps):with tf.variable_scope('Compress_feature_map%d'%i):Sigma_T, U_T, V_T = SVP.SVD_eid(tfm, 1, name = 'TSVD%d'%i)_, U_S, V_S = SVP.SVD_eid(sfm, 4, name = 'SSVD%d'%i)V_S, V_T = SVP.Align_rsv(V_S, V_T)D = V_T.get_shape().as_list()[1]V_T = tf.reshape(V_T,[-1,D])V_S = tf.reshape(V_S,[-1,D])with tf.variable_scope('MHA%d'%i):if i > 0:_,D_, = V_Sb.get_shape().as_list()D2 = (D+D_)//2G_T = Attention_head(V_T, V_Tb, D2, num_head, 'Attention', is_training = True)V_T_ = Estimator(V_Tb, G_T, D, num_head, 'Estimator', is_training = True)tf.add_to_collection('MHA_loss', tf.reduce_mean(1-tf.reduce_sum(V_T_*V_T, -1)) )G_T = Attention_head(V_T, V_Tb, D2, num_head, 'Attention', reuse = True)G_S = Attention_head(V_S, V_Sb, D2, num_head, 'Attention', reuse = True)G_T = tf.tanh(G_T)G_S = tf.tanh(G_S)GNN_losses.append(kld_loss(G_S, G_T))V_Tb, V_Sb = V_T, V_Stransfer_loss = tf.add_n(GNN_losses)return transfer_lossdef ResBlock(x, depth, stride, get_feat, name):with tf.variable_scope(name):out = tcl.batch_norm(tcl.conv2d(x, depth, [3,3], stride, scope='conv0'), scope='bn0')out = tcl.batch_norm(tcl.conv2d(out, depth, [3,3], 1, scope='conv1'), scope='bn1',activation_fn = None)if stride > 1 or depth != x.get_shape().as_list()[-1]:x = tcl.batch_norm(tcl.conv2d(x, depth, [1,1], stride, scope='conv2'), scope='bn2', activation_fn = None)out_ = x+outout = tf.nn.relu(out_)if get_feat:tf.add_to_collection('feat_noact', out_)tf.add_to_collection('feat', out) # ****** 这里获取了特征输出return outdef NetworkBlock(x, nb_layers, depth, stride, name = ''):with tf.variable_scope(name):for i in range(nb_layers):x = ResBlock(x, depth, stride = stride if i == 0 else 1,get_feat = True if i == nb_layers-1 else False, name = 'BasicBlock%d'%i)return xdef ResNet(image, label, scope, is_training, Distill = None):end_points = {}is_training, auxiliary_is_training = is_trainingif image.get_shape().as_list()[1] == 32:nChannels = [32, 64, 128, 256]stride = [1,2,2]else:nChannels = [16, 32, 64, 128, 256, 512]stride = [1,2,2,2,2]n = 1 if scope != 'Teacher' else 5with tf.variable_scope(scope):with tcf.arg_scope([tcl.conv2d, tcl.fully_connected, tcl.batch_norm], trainable = True):with tcf.arg_scope([tcl.dropout, tcl.batch_norm], is_training = is_training):std = tcl.conv2d(image, nChannels[0], [3,3], 1, scope='conv0')std = tcl.batch_norm(std, scope='bn0')for i in range(len(stride)):std = NetworkBlock(std, n, nChannels[1+i], stride[i], name = 'Resblock%d'%i)fc = tf.reduce_mean(std, [1,2])logits = tcl.fully_connected(fc , label.get_shape().as_list()[-1],biases_initializer = tf.zeros_initializer(),biases_regularizer = tcl.l2_regularizer(5e-4),scope = 'full')end_points['Logits'] = logitsif Distill is not None:if Distill == 'DML':teacher_trainable = Trueweight_decay = 5e-4teacher_is_training = tf.logical_not(is_training)else:teacher_trainable = Falseweight_decay = 0.teacher_is_training = Falsearg_scope = ResNet_arg_scope_teacher(weight_decay=weight_decay)with tf.variable_scope('Teacher'):with tcf.arg_scope(arg_scope):with tcf.arg_scope([tcl.conv2d, tcl.fully_connected, tcl.batch_norm], trainable = teacher_trainable):with tcf.arg_scope([tcl.batch_norm], is_training = teacher_is_training):n = 5tch = tcl.conv2d(image, nChannels[0], [3,3], 1, scope='conv0')tch = tcl.batch_norm(tch, scope='bn0')for i in range(len(stride)):tch = NetworkBlock(tch, n, nChannels[1+i], stride[i], name = 'Resblock%d'%i)fc = tf.reduce_mean(tch, [1,2])logits_tch = tcl.fully_connected(fc , label.get_shape().as_list()[-1],biases_initializer = tf.zeros_initializer(),biases_regularizer = tcl.l2_regularizer(weight_decay) if weight_decay > 0. else None,scope = 'full')end_points['Logits_tch'] = logits_tchwith tf.variable_scope('Distillation'):feats = tf.get_collection('feat')student_feats = feats[:len(feats)//2]teacher_feats = feats[len(feats)//2:]feats_noact = tf.get_collection('feat')student_feats_noact = feats_noact[:len(feats)//2]teacher_feats_noact = feats_noact[len(feats)//2:]...elif Distill == 'MHGD':tf.add_to_collection('dist', Relation.MHGD(student_feats, teacher_feats))return end_points
损失函数
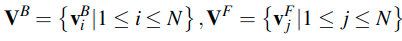
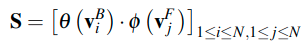
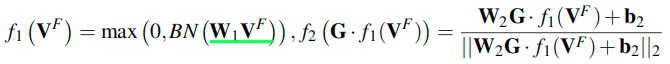
这是训练MHAN时使用的损失,这里包含M个注意力头。
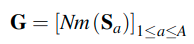
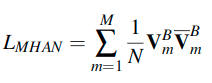
As a result, G has two kinds of information.
- The first information is about the feature transform, which is the relation representing the flow of solving procedure (FSP).
- The second information is about intra-data relations.
这里的f1和f2都是包含全连接层,这里的
应该表示的是矩阵乘法,这里有多个矩阵的乘法来映射特征。f1对VF进行了一次转换,G和f1进行乘法,又转换了一次,f2中也会进行一次转换。
Since the TN is typically a large and complex network, it may be impossible for the SN to mimic teacher knowledge or the teacher knowledge can be an over-constraint. Thus, Nm(S) is modified to smoothen the teacher knowledge as follows. 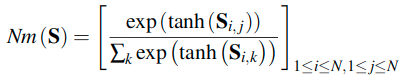
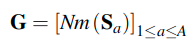
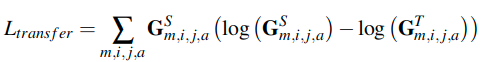
这里使用了交叉熵计算最终的迁移任务的损失。这里的GT获取自教师网络,GS获取自学生网络。Nm中使用Tanh来讲输入值归一化到[-1, 1]之间,这可以有效的平滑G,因为这可以优雅的满足大的注意力值。
这里没有描述学生网络是如何训练的,没有提学生网络部分的AN是如何训练的。代码没太看明白。。。
相关链接

若有收获,就点个赞吧
0 人点赞
