
主要的新意:
- 提出了一个保留相似性损失,来促使学生网络学习老师网络在对于数据内部的关系表达的知识
- 该损失可以和一些现有的方法相配合,实现更好的蒸馏效果
- 实验设计中,尝试了一种迁移学习的比较实验
主要想法
这篇文章应该是ICCV2019的一篇文章(根据极市平台https://github.com/extreme-assistant/iccv2019的提前的统计)。本文针对的是分类任务,尝试从一种新的角度来构建知识蒸馏,即通过所谓“保留相似性”的手段来实现更好的蒸馏。
本文的构思主要基于一个核心前提:语义相似的输入趋向于在训练好的网络中产生相似的激活模式,反之亦然。基于此,本文提出了核心的假设:如果两个输入在教师网络中有着高度相似的激活,那么引导学生网络趋向于对该输入同样产生高的相似激活(反之亦然)的参数组合,那将是有利的(对于学生更好的学习老师网络的能力与知识)。
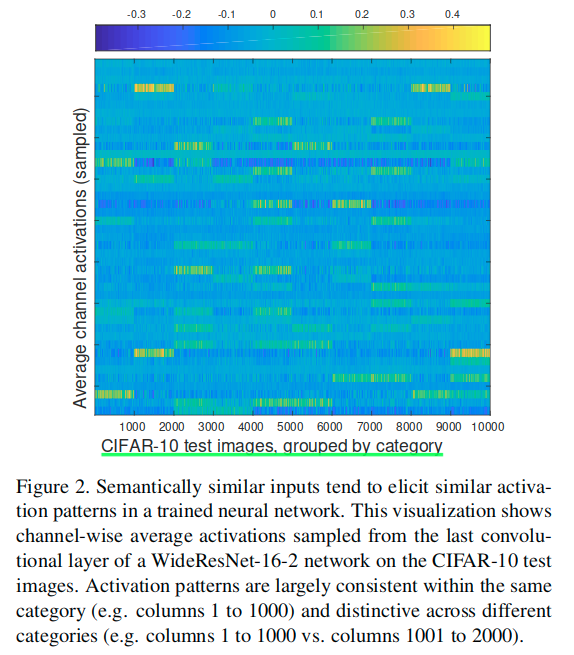
这个图指示了CIFAR-10中10000张图片分别对应于教师网络最后一个卷积层的激活值中所有通道内计算均值得到的矢量,整体绘制出来得到的结果。这里分成了十类,每一类对应相邻的1000张图片,可见,相邻的1000张图片的激活情况是类似的,而不同类别之间有明显差异。
相关工作
关于知识蒸馏的研究,除了类似与本文的对于知识捕获(或者说是“损失定义”),也有在研究关于学生网络和教师网络的架构设计。
- 由于MobileNet和ShuffleNet的有效性,Crowley等人对教师网络中的规则卷积替换成更为轻量的分组卷积和对点卷积。
- Ashok等人,开发了一个强化学习方法,来学习学生网络。
- Polino等人,论证了如何使用完全精确的教师网络来训练量化的学生网络。
也有创新的“正交”的工作探索通常的学生教师模型训练范式的替代方案。
- Wang等人[KDGAN: Knowledge distillation with generative adversarial networks]引入一个额外的判别器网络,并使用一个蒸馏和对抗损失来训练学生、教师和判别器。
- Lan等人[Knowledge distillation by on-the-fly native ensemble]提出了一种基于多分支网络结构的教师与多名学生一起训练的实时本地集成教师模型(on-the-fly native ensemble teacher model)。
模型压缩简单回顾:
Resource efficiency considerations have led to a recent increase in interest in efficient neural architectures, as well as in algorithms for compressing trained deep networks.
- Knowledge distillation was first introduced as a technique for neural network compression.
- Weight pruning methods remove unimportant weights from the network, sparsifying the network connectivity structure. The induced sparsity is unstructured when individual connections are pruned, or structured when entire channels or filters are pruned. Unstructured sparsity usually results in better accuracy but requires specialized sparse matrix multiplication libraries [Faster CNNs with direct sparse convolutions and guided pruning] or hardware engines [EIE: Efficient inference engine on compressed deep neural network] in practice.
- Quantized networks, such as fixed-point, binary, ternary, and arbitrary-bit networks, encode weights and/or activations using a small number of bits, or at lower precision. Fractional or arbitrary-bit quantization encodes individual weights at different precisions, allowing multiple precisions to be used within a single network layer.
- Low-rank factorization methods produce compact low-rank approximations of filter matrices.
- Techniques from different categories have also been optimized jointly or combined sequentially to achieve higher compression rates [Coreset-based neu-ral network compression, Deep compression: Com-pressing deep neural networks with pruning, trained quanti-zation and Huffman coding, CLIP-Q: Deep network compression learning by in-parallel pruning-quantization].
知识蒸馏的优势:
- State-of-the-art network compression methods can achieve significant reductions in network size, in some cases by an order of magnitude, but often require specialized software or hardware support. For example, unstructured pruning requires optimized sparse matrix multiplication routines to realize practical acceleration, platform constraint-aware compression requires hard-ware simulators or empirical measurements, and arbitrary-bit quantization requires specialized hardware.
- One of the advantages of knowledge distillation is that it is easily implemented in any off-the-shelf deep learning framework without the need for extra software or hardware.
- Moreover, distillation can be integrated with other network compression techniques for further gains in performance [Model compression via distillation and quantization].
网络结构
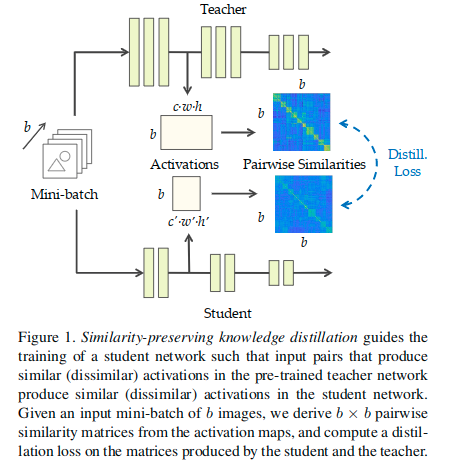
这里是对大小为b的batch中。所有图片一起编码,进而得到一个bxb的相似性矩阵。
主要工作
在这些想法的加持下,本文构造了一种除了最终用于分类的交叉熵损失之外的保留相似性知识蒸馏损失(similarity-preserving knowledge distillation loss):
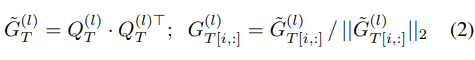
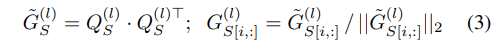
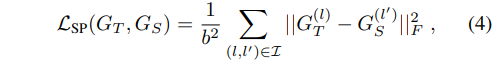
这里的损失是:
- 针对同一batch数据得到教师模型和学生模型在网络特定层次(教师的l层和学生的l’层)的特征针对batch的相似性关联矩阵
- 通过计算来自教师模型和学生模型各自关联矩阵的差值的F范数的平方,再针对所有的层次的匹配对计算结果进行加和,针对b^2计算均值可得最终的保留相似性知识蒸馏损失
- 注意2和3中的公式分母的形式,对于矩阵的右下角标为2的情况,表示的是row-wise L2 normalization
矩阵的谱范数,参见链接,具体计算可以写作:
,这里的
表示的是对内部输入取其最大的特征值,对应的范数并不相同(随着论文的第二版的更新,论文中补充了这部分的介绍) - 式子4中的F范数表示的是Frobenius norm(矩阵的各个元素平方之和再开平方根,它通常也叫做矩阵的L2范数,它的有点在它是一个凸函数,可以求导求解,易于计算,参见链接)
进而在整体训练的时候使用如下损失来进行对学生网络的监督:
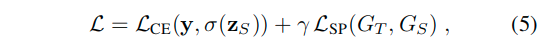
这里的 是一个超参数,用来平衡损失。
是一个超参数,用来平衡损失。
图3中展示了对于CIFAR-10测试集上的数个batch的G矩阵可视化结果,这里的激活是从最后一个卷积层收集而来的。
- 每一列表示一个单独的batch,两个网络都是一致的。
- 每个batch的图像中,对于样本的顺序已经通过其真值类别分组。一个batch包含128张图片样本。在两行的G矩阵中,显示了独特的块状模式,这指示了者系网络的最后一层的激活,在相同类别的时候有着相似的结果,而不同类别也有着不同的结果,也就是前者有着更大的相似性,后者相似性较小。
- 图中每个块大小不同,这主要是因为不同类别在每个batch中包含的样本数不同。
- 上下对比也可以看出来,对于复杂模型(下面),块状模式更加明显突出,这也反映出来,其对于捕获数据集的语义信息有着更强的能力。
- 这样的现象也在一定程度上支撑了本文的假设,也反映出前面提出的相似性损失的意义与价值所在,就是促使学生网络可以更好的模仿学习老师模型对于数据特征中的关联信息的学习。

与过去方法的差异
- knowledge distillation:使用的是类别得分作为蒸馏知识的传递媒介,而提出的保留相似性知识蒸馏损失则是定义在特征激活之上
- FitNets、flow-based distillation、attention transfer:也使用了定义在激活之上的蒸馏损失,但是存在一个关键的不同在于这些先前的蒸馏方法鼓励学生模仿老师表征空间的不同方面。我们的方法不同于这种常见的方法,它的目的是尽可能保留(模仿学习)输入样本的成对激活相似性。与其模仿表征空间,倒不如直接模仿教师模型在特征值处理过程中获取的特征之间的关系。它的行为并不受老师模型的表征空间的旋转而改变。
实验细节
关于实验的设计:We now turn to the experimental validation of our distillation approach on three public datasets.
- We start with CIFAR-10 as it is a commonly adopted dataset for comparing distillation methods, and its relatively small size allows multiple student and teacher combinations to be evaluated.
- We then consider the task of transfer learning, and show how distillation and fine-tuning can be combined to perform transfer learning on a texture dataset with limited training data.
- Finally, we report results on the larger CINIC-10 dataset.
CIFAR-10
CIFAR-10 consists of 50,000 training images and 10,000 testing images at a resolution of 32x32.The dataset covers ten object classes, with each class having an equal number of images.
- We conducted experiments using wide residual networks (WideResNets) following [4, 41].
- We adopted the standard protocol for training wide residual networks on CIFAR-10 (SGD with Nesterov momentum; 200 epochs; batch size of 128; and an initial learning rate of 0.1, decayed by a factor of 0.2 at epochs 60, 120, and 160).
- We applied the standard horizontal flip and random crop data augmentation.
- We performed baseline comparisons with respect to traditional knowledge distillation (softened class scores) and attention transfer.
- For traditional knowledge distillation, we set = 0.9 and T = 4 following the CIFAR-10 experiments in [4, 41].
- Attention transfer losses were applied for each of the three residual block groups. We set the weight of the distillation loss in attention transfer and similarity-preserving distillation by held-out validation(链接) on a subset of the training set (
 =1000 for attention transfer,
=1000 for attention transfer,  =3000 for similarity-preserving distillation).
=3000 for similarity-preserving distillation).
在CIFAR-10上进行试验的时候,使用的是WideResNets结构,具体细节可见原文,使用更为复杂的结构作为教师模型,对应的小模型作为学生模型,这里针对的是相同架构不同复杂度的模型分别应用不同的蒸馏方法后的比较。
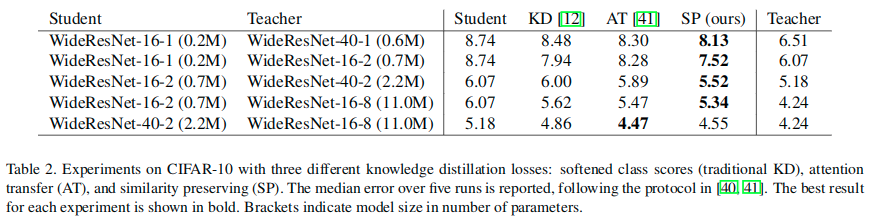
The above similarity-preserving distillation results were produced using only the activations collected from the last convolution layers of the student and teacher networks. We also experimented with using the activations at the end of each WideResNet block, but found no improvement in performance. We therefore used only the activations at the final convolution layers in the subsequent experiments. Activation similarities may be less informative in the earlier layers of the network because these layers encode more generic features, which tend to be present across many images. Progressing deeper in the network, the channels encode increasingly specialized features, and the activation patterns of semantically similar images become more distinctive.
Transfer learning combining distillation with fine-tuning
Suppose we are faced with a novel recognition task in a specialized image domain with limited training data. 这里从自然图像分类任务迁移到了纹理材料分类任务。
- A natural strategy to adopt is to transfer the knowledge of a network pre-trained on ImageNet (or another suitable large-scale dataset) to the new recognition task by fine-tuning.
- Here, we combine knowledge distillation with fine-tuning:
- we initialize the student network with source domain (in this case, ImageNet) pretrained weights,
- then fine-tune the student to the target domain using both distillation and cross-entropy losses(式子5).
- We analyzed this scenario using the describable textures dataset [Describing textures in the wild], which is composed of 5,640 images covering 47 texture categories.
- Image sizes range from 300x300 to 640x640.
- We applied ImageNet-style data augmentation with horizontal flipping and random resized cropping during training.
- At test time, images were resized to 256x256 and center cropped to 224x224 for input to the networks.
- For evaluation, we adopted the standard ten training-validation-testing splits.
- To demonstrate the versatility of our method on different network architectures, and in particular its compatibility with mobile-friendly architectures, we experimented with variants of MobileNet and MobileNetV2.
- We compared with an attention transfer baseline.
- Softened class score based distillation is not directly comparable in this setting because the classes in the source and target domains are disjoint(类别数量不同). The teacher would first have to be fine-tuned to the target domain, which significantly increases training time and may not be practical when employing expensive teachers or trasferring to large datasets.
- Similarity-preserving distillation can be applied directly to train the student, without first fine-tuning the teacher, since it aims to preserve similarities instead of mimicking the teacher’s representation space.
- We set the hyperparameters for attention transfer and similarity-preserving distillation by held-out validation on the ten standard splits.
- All net-works were trained using SGD with Nesterov momentum, a batch size of 96, and for 60 epochs with an initial learning rate of 0.01 reduced to 0.001 after 30 epochs.
表五中显示了迁移学习的一些实验结果。
The results suggest that there may be a challenging domain shift in the important image areas for the network to attend. Moreover, while attention transfer summarizes the activation map by summing out the channel dimension, similarity-preserving distillation makes use of the full activation map in computing the similarity-based distillation loss, which may be more robust in the presence of a domain shift in attention.
CINIC-10
- The CINIC-10 dataset is designed to be a middle option relative to CIFAR-10 and ImageNet: it is composed of 32x32 images in the style of CIFAR-10, but at a total of 270,000 images its scale is closer to that of ImageNet. We adopted CINIC-10 for rapid experimentation because several GPU-months would have been required to perform full held-out validation and training on ImageNet for our method and all baselines.
- For the student and teacher architectures, we experimented with variants of the state-of-the-art mobile archi-tecture ShuffleNetV2.
- We used the standard training validation-testing split and set the hyperparameters for similarity-preserving distillation and all baselines by held-out validation.
- KD:{
 =0.6, T=16}
=0.6, T=16} - AT:
 = 50
= 50 - SP:
 = 2000
= 2000 - KD+SP:{
 =0.6, T=16,
=0.6, T=16,  =2000}
=2000} - AT+SP:{
 = 30,
= 30,  = 2000}
= 2000}
- KD:{
All networks were trained using SGD with Nesterov momentum, a batch size of 96, for 140 epochs with an initial learning rate of 0.01 decayed by a factor of 10 after the 100th and 120th epochs. We applied CIFAR-style data augmentation with horizontal flips and random crops during training.
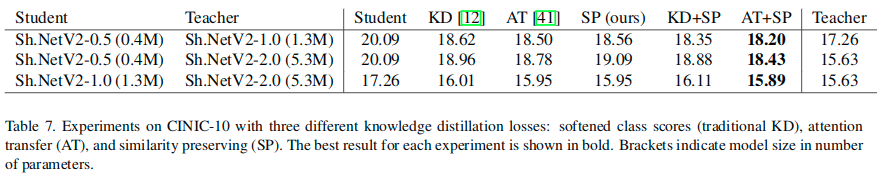
This result shows that similarity-preserving distillation complements atten-tion transfer and captures teacher knowledge that is not fully encoded in spatial attention maps
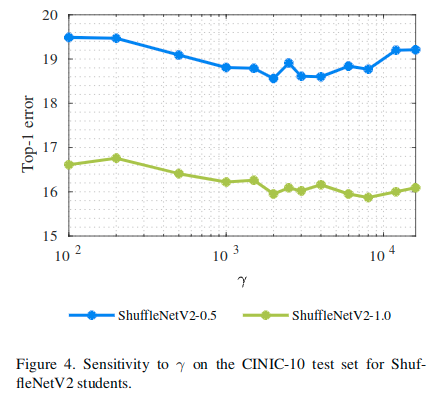
Sensitivity analysis
图4中显示了超参数 对于性能的影响。将其从100调整至16000,进行多次测试,得到了一个较为直观的结果。 In all experiments, we set by held-out validation.
对于性能的影响。将其从100调整至16000,进行多次测试,得到了一个较为直观的结果。 In all experiments, we set by held-out validation.
相关链接

若有收获,就点个赞吧
0 人点赞
