
主要工作
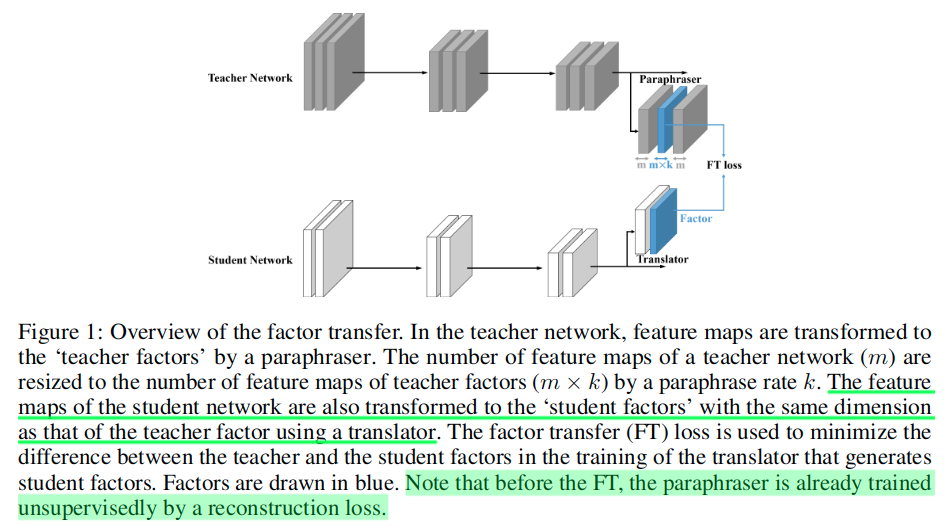
这篇NeurIPS2018的文章构造了教师模型和学生模型,通过训练希望学生模型可以通过自己的translator学习到老师模型经过paraphraser简化过的知识信息(Factor Transfer)。
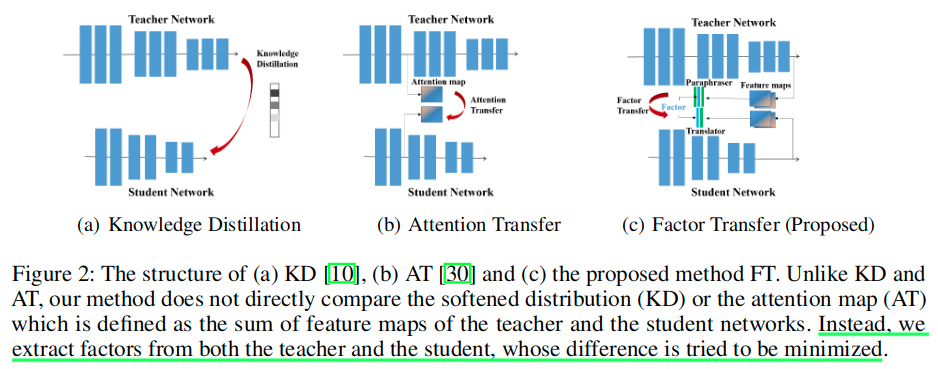
这篇文章的想法与Knowledge Adaptation for Efficient Semantic Segmentation的构造思路不谋而合,都认为直接匹配注意力图(AT方法)或者使用软化的教师输出分布(原始KD)方法。 对于学生而言,直接转移教师的输出忽略了教师网络和学生网络之间的固有差异,例如网络结构,通道数量和初始条件。因此,需要重新解释教师网络的输出以解决这些差异。
这里的paraphraser和自编码器类似,不过这里没有调整宽和高,只是调整了通道数以保证在最终的使用中和学生模型的translator可以匹配(通道一致)。
关于自编码器可以看这篇文章,介绍的非常棒:
- https://keras-cn.readthedocs.io/en/latest/legacy/blog/autoencoder/
- https://ynuwm.github.io/2017/05/14/%E8%87%AA%E7%BC%96%E7%A0%81%E5%99%A8AutoEncoder/
The architecture of our paraphraser is different from convolutional autoencoders in that convolution layers do not downsample the spatial dimension of an input since the paraphraser uses sufficiently downsampled feature maps of a teacher network as the input.
We trained the paraphraser in an unsupervised way, expecting it to extract knowledges different from what can be obtained with supervised loss term.
At the student side, we trained the student network with the translator to assimilate the factors extracted from the paraphraser.
Since the teacher network and the student network are focusing on the same task, we extracted factors from the feature maps of the last group as clearly can be seen in Figure 1 because the last layer of a trained network must contain enough information for the task.
- We define the output of paraphraser’s middle layer, as ‘teacher factors’ of the teacher network,
- and for the student network, we use the translator made up of several convolution layers to generate ‘student factors’ which are trained to replicate the ‘teacher factors’.
With these modules, our knowledge transfer process consists of the following two main steps:
- In the first step, the paraphraser is trained by a reconstruction loss. Then, teacher factors are extracted from the teacher network by a paraphraser.
- In the second step, these teacher factors are transferred to the student factors such that the student network learns from them.
主要结构
损失函数
- 训练教师模型的paraphraser时使用的重构损失
- x表示该模块输入的特征图,输出的特征图为P(x)
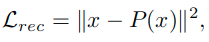
- 训练学生模型使用的联合损失
- 包含了分类损失和factor transfer的损失,可以知道,这里的FT和FS形状和通道数是一致的,计算时都是用了除以自身的L2范数来归一化,关于这里使用的p范数,这里作者考虑了L1和L2两种,实际中差别不大,最终选择L1
- 这里的Lcls表示的是输出进过softmax之后和真值y计算交叉熵
- 不同于教师模型的paraphraser,学生网络的translator是和学生网络一起通过端到端的形式训练的
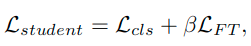
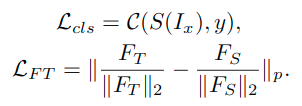
相关链接

若有收获,就点个赞吧
0 人点赞
