
- 论文:https://arxiv.org/abs/2204.06986
- 代码:https://github.com/winycg/CIRKD
- 解读:https://mp.weixin.qq.com/s/MsvRpR_r2X-BtcXfEFIm7A
Current Knowledge Distillation (KD) methods for semantic segmentation often guide the student to mimic the teacher’s structured information generated from individual data samples. However, they ignore the global semantic relations among pixels across various images that are valuable for KD. This paper proposes a novel Cross-Image Relational KD (CIRKD), which focuses on transferring structured pixel-to-pixel and pixel-to-region relations among the whole images. The motivation is that a good teacher network could construct a well-structured feature space in terms of global pixel dependencies. CIRKD makes the student mimic better structured semantic relations from the teacher, thus improving the segmentation performance.
当前用于视觉分割的知识蒸馏 (KD) 方法通常指导学生模仿教师网络从独立数据样本生成的结构化信息。然而,他们忽略了对KD有价值的跨图像的像素间全局语义关系。本文提出了一种新的跨图像的关系知识蒸馏 (CIRKD),其重点是在整个图像之间迁移pixel-to-pixel和pixel-to-region的关系。其中的动机是一个好的教师网络可以根据全局像素依赖性构建一个结构良好的特征空间。CIRKD使学生更好地模仿教师的结构化语义关系,从而提高分割性能。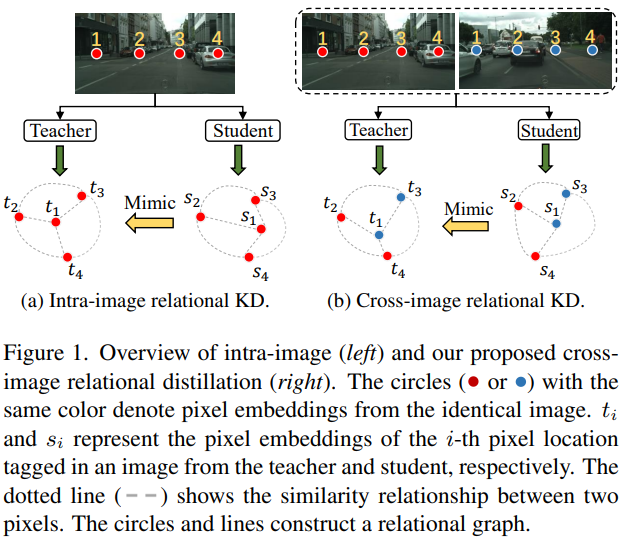
完整算法如下:
完整损失如下: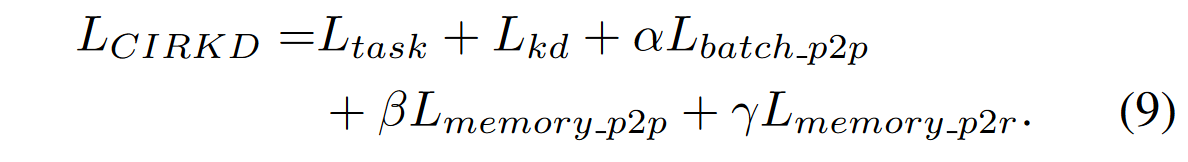
跨图像成对像素相似度蒸馏
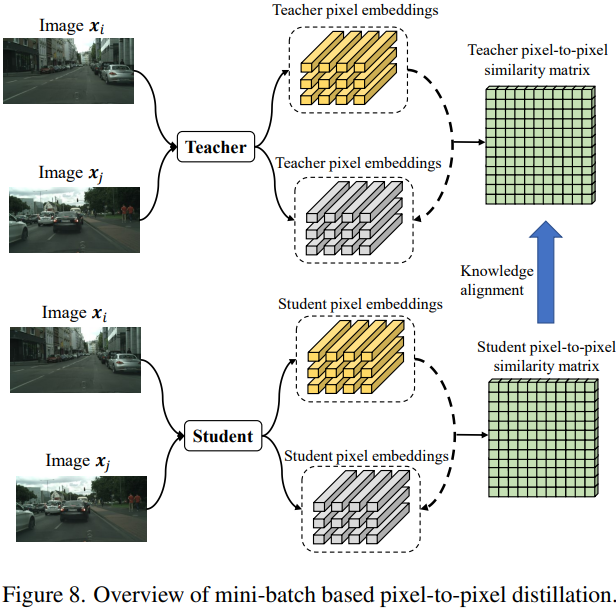
Mini-batch-based Pixel-to-Pixel Distillation
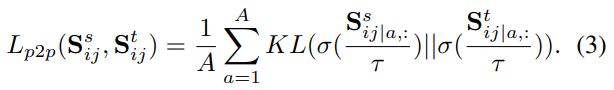
这里的Sij表示batch中的图像i和j之间的全局图像之间的成对相似度,形状为AxA,A=HxW。这里用于计算S的特征Fi和Fj(Axd)都被l2归一化处理过。这里计算KL散度对齐分布时,会对S的每一行a进行温度参数为τ的softmax归一化操作。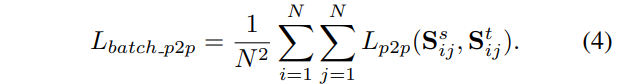
这里对整个batch中的成对点对点关系损失进行了平均。
Memory-based Pixel-to-Pixel Distillation
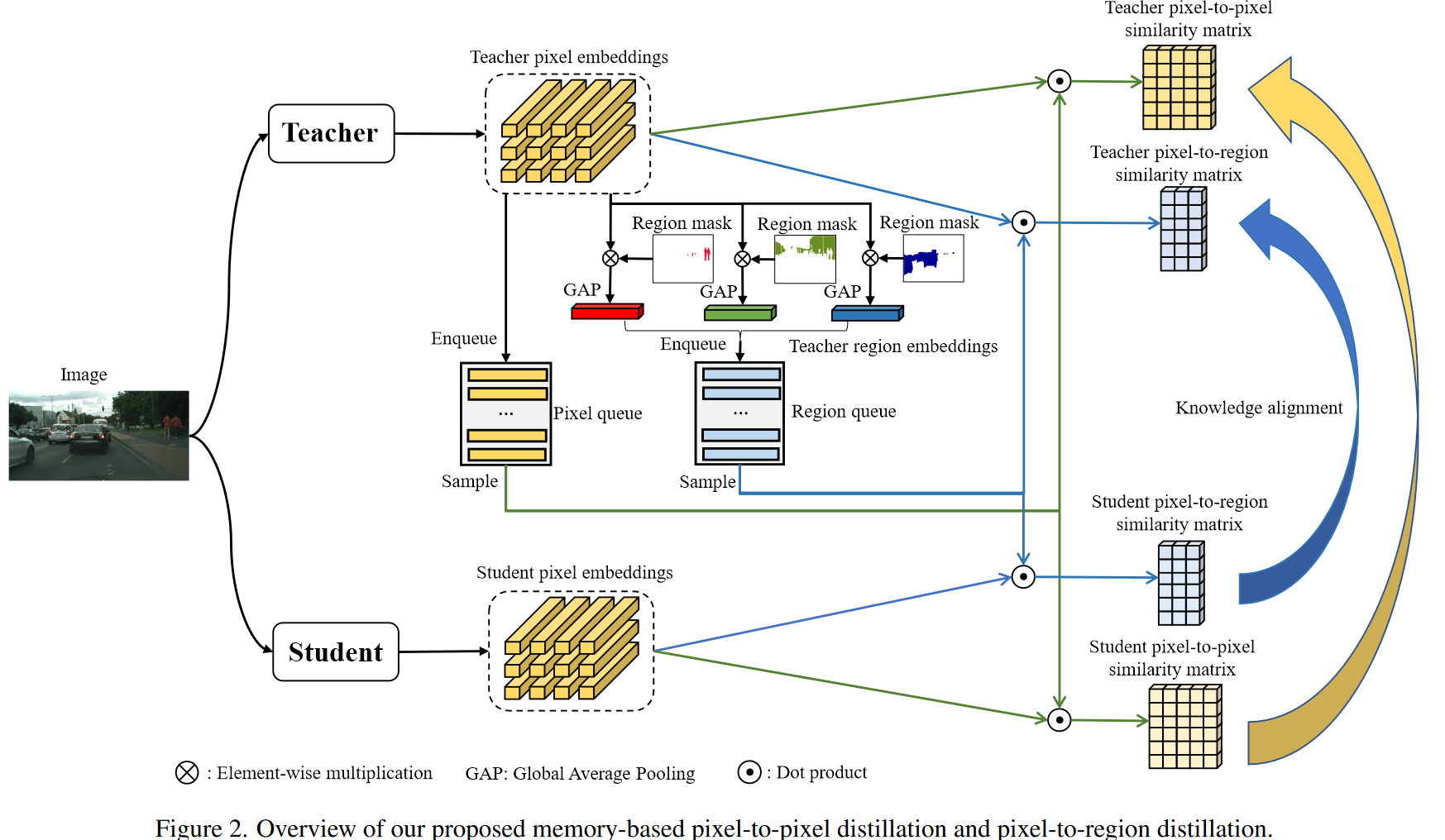
由于语义分割任务不同GPU上的batch基本都很小,一般为1或者2,因此单靠前面的损失是不足充分的模拟全局图像依赖关系。这里收到了基于memroy的对比学习的启发,引入了一个在线像素队列存储过去的小批量样本生成的存储库中的大量像素嵌入。(To address this problem, we introduce an online pixel queue that can store massive pixel embeddings in the memory bank generated from the past mini-batches.) 通过这样的方式可以从一个在线的memory bank中检索过往batch的知识。
由于分割任务图像相同目标区域的大部分像素都是同质的,直接存储所有的像素嵌入可能学习到冗余的关系,并且拖慢蒸馏过程,而且保存数个最后的batch可能也会破坏像素嵌入的多样性。因此这里设计了一种有选择性的存储策略。因此对于每个batch中的图像,仅对每个类别随机采样少量像素嵌入样本,然后将他们压入队列中。借鉴Seed: Self-supervised distillation for visual representation,教师与学生使用共享的像素队列。
队列中存贮蒸馏过程中每次迭代后,从教师生成的像素嵌入中从每一类中采样V个嵌入压入。
队列Qp的形状是CxNpxd,C为类别数,Np是每个类的像素嵌入数量,d是嵌入的维度。相当于这里就是为每一类都维护了一个嵌入队列。每次计算相似度的时候,都是使用教师和学生模型各自的大小为Axd的像素嵌入Fn,来和从像素队列Qp中类平衡采样后得到的集合Vp,其包含Kp个对比嵌入。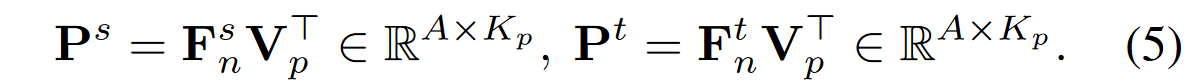
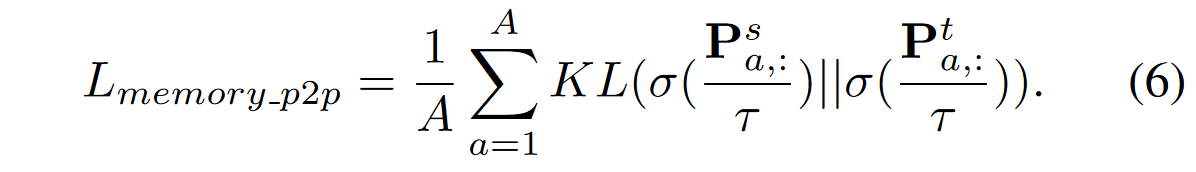
针对教师和学生各自计算像素嵌入和采样得到的类别像素嵌入之间的相似性矩阵,然后针对不同的位置对应的相似度向量归一化后计算KL散度得到损失。
跨图像像素与区域相似度蒸馏
Memory-based Pixel-to-Region Distillation
在像素相似度的基础上,进一步引入了像素和区域之间的相似度,来建模跨图像的像素和类别区域嵌入之间的关系。每个区域嵌入表示这图像中单一语义类别的特征中心。实际实现中对属于同一类的像素执行平均池化获得单一类别区域嵌入。
这里额外维护了一个区域队列Qr,大小为CxNrxd。Nr表示每类区域嵌入的数量。每次迭代从中类别平衡式采样Kr个区域嵌入,构成Vr。后将其与教师和学生模型的像素嵌入计算成对相似度,并同样计算KL散度。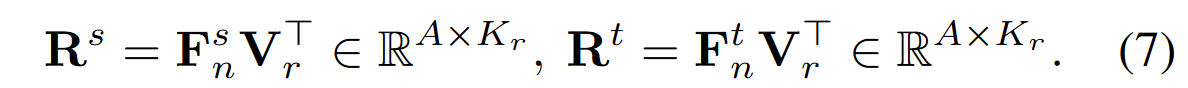
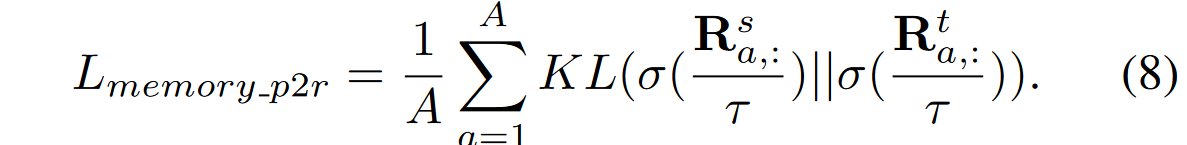
每次都会直接压入所有的教师区域嵌入到队列中。

若有收获,就点个赞吧
0 人点赞
