
这也是CVPR2019的一篇作品。同样是使用蒸馏的手段。
主要工作
- 成功的在语义分割任务上应用了蒸馏技巧,实现了更小更优的模型
- 在像素级蒸馏的基础上设计了新的结构化的蒸馏方法:
- 成对蒸馏(特征之间的任意位置之间的相似性)
- 整体蒸馏(使用GAN)
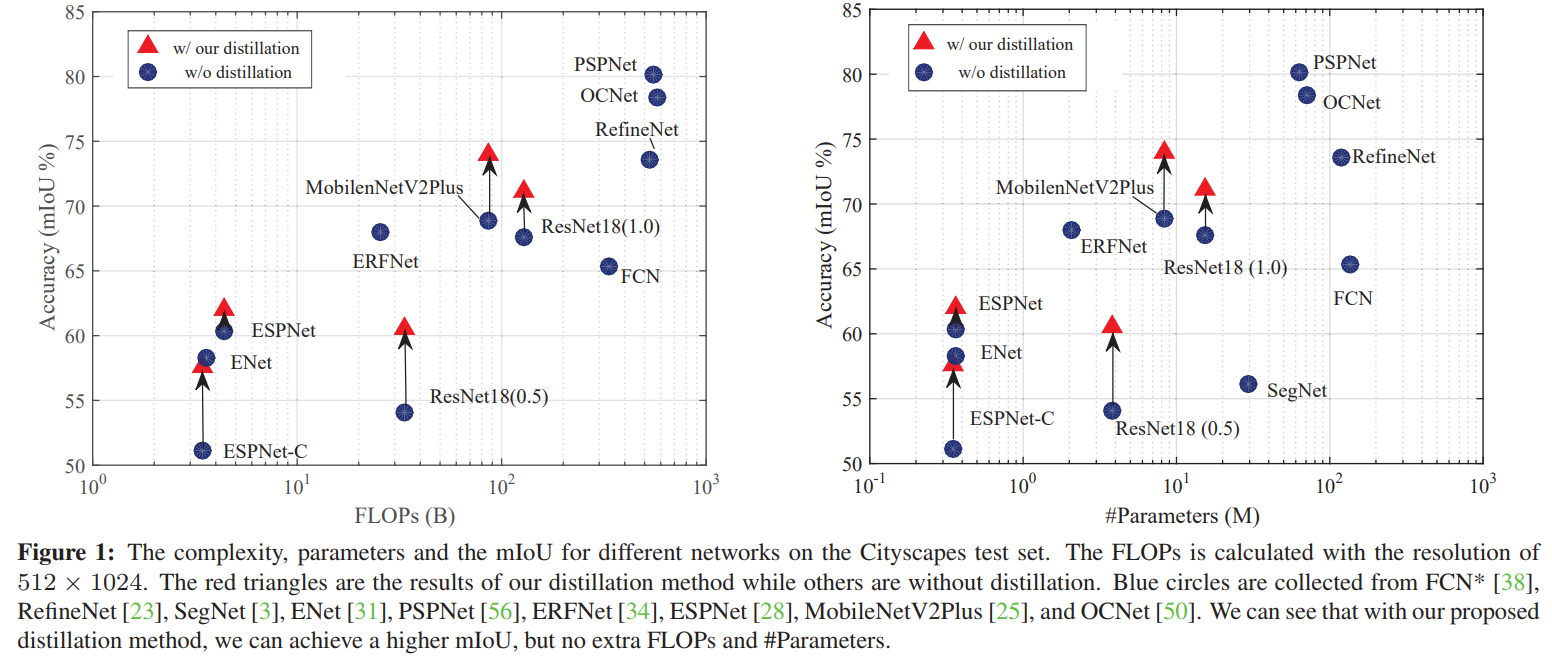
网络结构
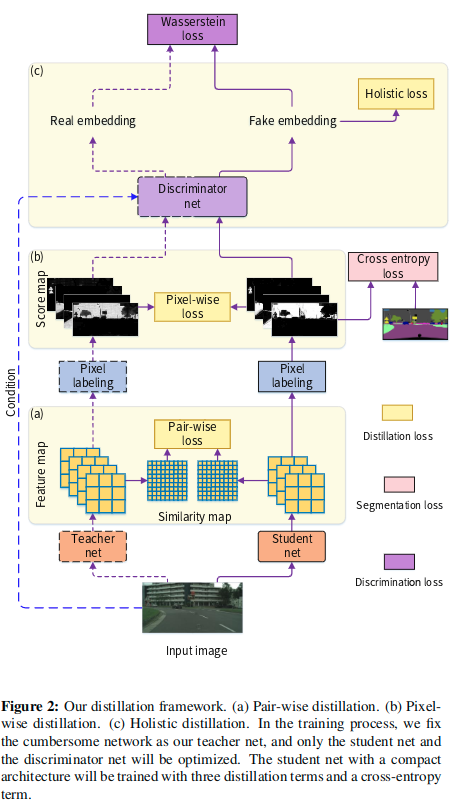
可见,主要包含五种损失,像素损失,交叉熵损失,成对损失,整体损失以及Wasserstein损失,这些损失主要可以归类为像素级蒸馏、成对蒸馏和整体蒸馏。接下来分别介绍。
将蒸馏的思想用到分割任务中,最直接的想法就是像素级蒸馏,同事这里也提出了两种结构化知识蒸馏策略,成对蒸馏和整体蒸馏,来实现更好的知识迁移。
Pixel-wise distillation
通过将分割问题看做是一个独立的像素标记问题,直接使用知识蒸馏手段将每个来自紧凑网络(学生网络)的像素的类别概率对齐。
直接使用蒸馏手段,通过使用来自笨重网络的类别概率作为训练紧凑网络的软标签(soft targets)。使用的损失函数如下:
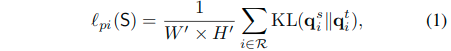
这里的qsi表示产生自紧凑网络S的第i个像素,qit表示产生自笨重网络T的第i个像素。这里使用KL散度来计算两个概率之间的差异。集合R表示所有的像素的索引。
Pair-wise distillation
受成对马尔可夫随机场框架被广泛用于改善空间标记的连续性的启发,这里使用成对关系,尤其是像素间的成对相似性。
这里使用了一个平方误差来衡量各个位置之间的成对相似性蒸馏损失:
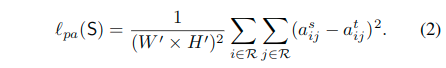
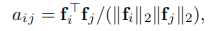
这里的aijt表示笨重网络T的第i个像素和第j个像素之间的相似性,而aijs表示紧凑网络S的第i个像素和第j个像素之间的相似性。这里使用两处位置上的特征矢量的余弦距离来表示相似性。
Holistic distillation
也考虑了对齐两个网络产生的分割图的高阶关系。使用分割图的高阶嵌入来表示。
这里使用条件生成对抗学习来表示整体蒸馏问题。
- 紧凑网络可以看做是以输入的RGB图像I为条件的生成器
- 紧凑网络预测的分割图Qs可以看做是一个伪样本
- 最终的目标是期望Qs可以相似于教师网络产生的分割图Qt,这也被看作是真实样本
- 使用Wasserstein距离来评估真实分布与伪分布的差异
整体蒸馏的损失可以表达如下:
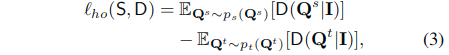
- E表示计算期望的操作
- D表示嵌入网络,表现如同GAN中的判别器,将Q和I一起投影到整体嵌入得分上
- 通过梯度惩罚来满足Lipschitz条件
- 来自S和T网络的分割图和作为条件的RGB图像分别拼接作为嵌入网络D的输入
- D是一个有着五个卷积层的全卷积网络,两个自注意力模块被插入到最后三层中间来捕获结构信息,这样的判别器能够生成一个整体嵌入表达,以指示输入图像和分割图的匹配程度
优化过程
整体的损失函数可以表达为:
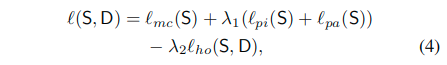
- 其中lmc(S)表示多类别交叉熵损失
- 这里通过lambda1和lambda2加权了像素、成对蒸馏损失和整体蒸馏损失,二者分别设置为10和0.1,来使这些损失值相当
- The objective function is the summation of the losses over the mini-batch of training samples. For description clarity, we ignore the summation operation.
最小化目标函数来优化学生网络S的参数,同时最大化(负的lho,也就是最小化lho)它以优化判别器D的参数。主要通过以下两步的迭代:

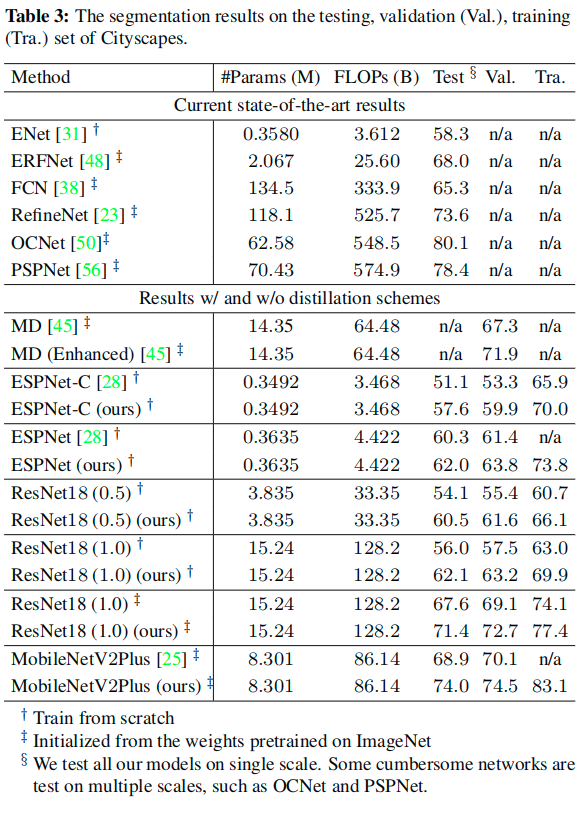
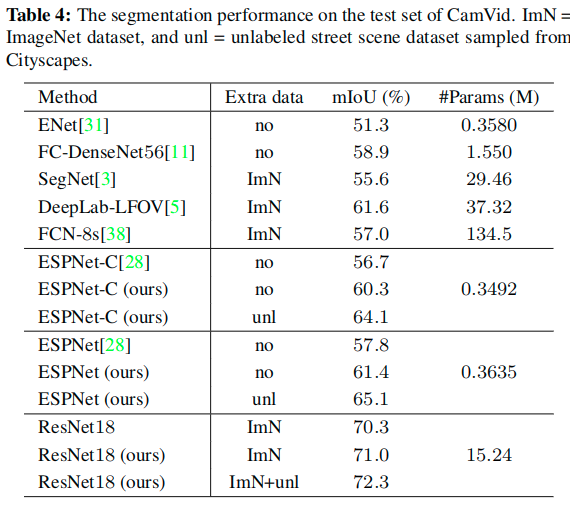
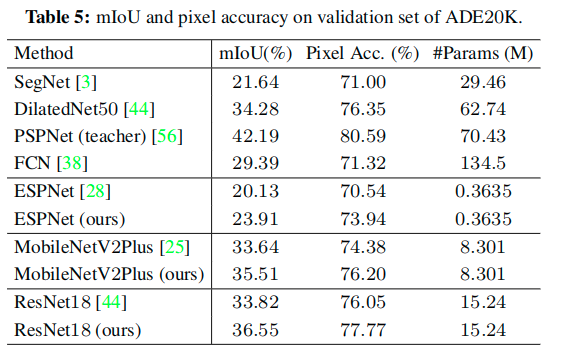
实验细节
- Network structures
- We adopt state-of-the-art segmentation architecture PSPNet with a ResNet101 as the cumbersome network (teacher) T.
- We study recent public compact networks, and employ several different architectures to verify the effectiveness of the distillation framework.
- We first consider ResNet18 as a basic student network and conduct ablation studies on it.
- Then, we employ an open source MobileNetV2Plus, which is based on a pretrained MobileNetV2 model on the ImageNet dataset.
- We also test the structure of ESPNet-C and ESPNet that are very compact and have low complexity.
- Training setup
- Most segmentation networks in this paper are trained by mini-batch stochastic gradient descent (SGD) with the momentum (0.9) and the weight decay (0:0005) for 40000 iterations.
- The learning rate is initialized as 0.01 and is multiplied by (1-iter/max_iter )^0.9 .
- We random cut the the images into
 as the training input.
as the training input. - Normal data augmentation methods are applied during training, such as random scaling (from 0.5 to 2.1) and random flipping.
- Other than this, we follow the settings in the corresponding publications [28] to reproduce the results of ES-PNet and ESPNet-C, and train the compact networks under our distillation framework.
- Evaluation Metrics: We use the following metrics to evaluate the segmentation accuracy, as well as the model size and the efficiency.
- The Intersection over Union (IoU) score is calculated as the ratio of interval and union between the ground truth mask and the predicted segmentation mask for each class.
- We use the mean IoU of all classes (mIoU) to study the distillation effectiveness.
- We also report the class IoU to study the effect of distillation on different classes.
- Pixel accuracy is the ratio of the pixels with the correct semantic labels to the overall pixels.
- The Intersection over Union (IoU) score is calculated as the ratio of interval and union between the ground truth mask and the predicted segmentation mask for each class.
- The model size is represented by the number of network parameters and the complexity is evaluated by the sum of floating point operations (FLOPs) in one forward on a fixed input size.
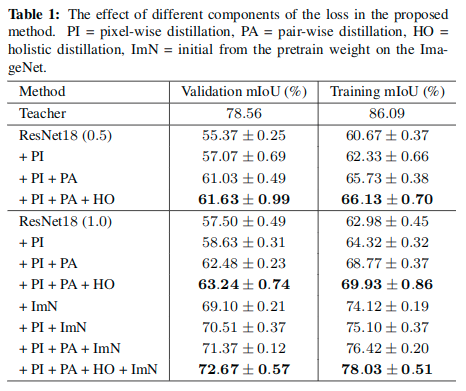
Furthermore, we illustrate that GAN is able to distill the holistic knowledge. For each image, we feed three segmentation maps, output by the teacher net, the student net w/o holistic distillation, and the student net w/ holistic distillation, into the discriminator D, and compare the embedding scores of the student net to the teacher net.
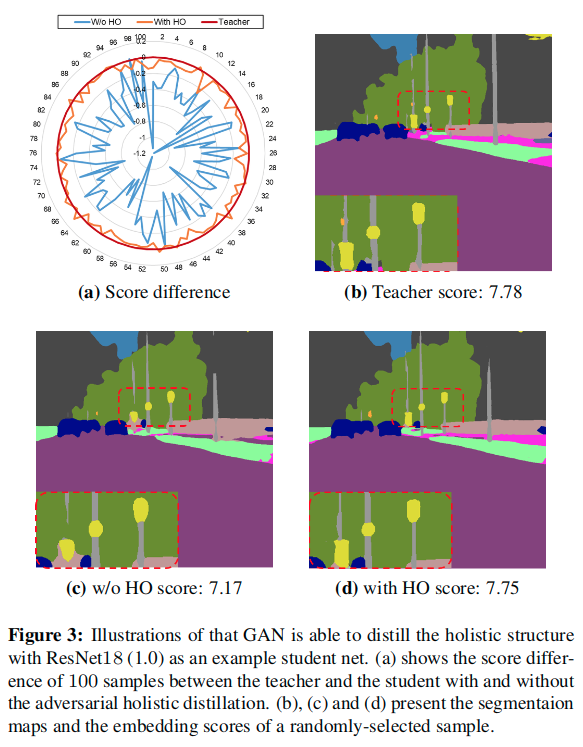
3a shows the difference of embedding scores, with holistic distillation, the segmentation maps produced from student net can achieve a similar score to the teacher, indicating that GAN helps distill the holistic structure knowledge. 具体如何设置可见该图的描述,这里的对比应该就是在训练小网络的时候不使用整体蒸馏损失,但是还会使用它来训练判别器。 3b, 3c and 3d are segmentation maps and their corresponding embedding scores of a randomly-selected image. The well-trained D can assign a higher score to a high quality segmentation maps, and the student net with the holistic dis-tillation can generate segmentation maps with higher scores and better quality.
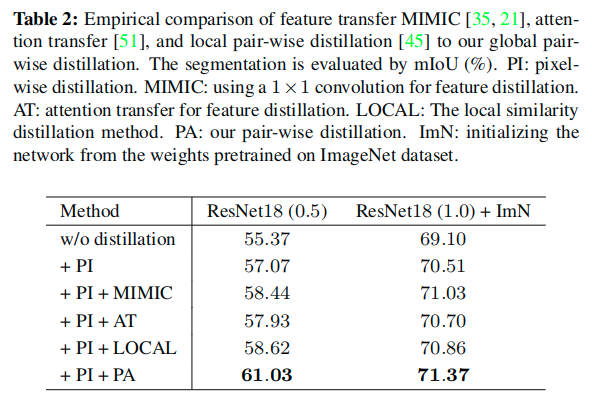
这里和其他的集中成对蒸馏的变体进行了比较,通过替换提出的成对蒸馏,使用如下的三种方法来对比:
- MIMIC [Mimicking very efficient net-work for object detection] 提出的Feature Distillation:通过使用1x1卷积层匹配教师网络和学生网络特征的维度,以对齐每个像素的特征
- Attention Transfer [Paying more attention to attention: Improving the performance of convolutional neu-ral networks via attention transfer] 提出的Feature Distillation:集成响应图得到一个单通道的所谓的注意力图,然后从学生到老师来转换注意力图
- Local pair-wise distillation [Improving fast segmentation with teacher-student learning] :蒸馏一个局部的相似性图,表示每个像素和其周围的8个邻居像素的相似性
实验分析:
- MIMIC and attention transfer, which transfers the knowledge for each pixel separately, comes from that we transfer the structured knowledge other than aligning the feature for each individual pixel.
- The superiority to the local pair-wise distillation shows the effectiveness of our global pare-wise distillation which is able to transfer the whole structure information other than a local boundary information.
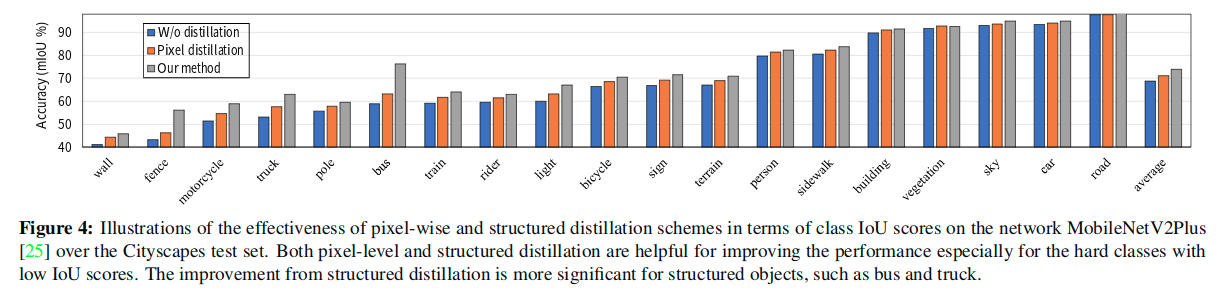
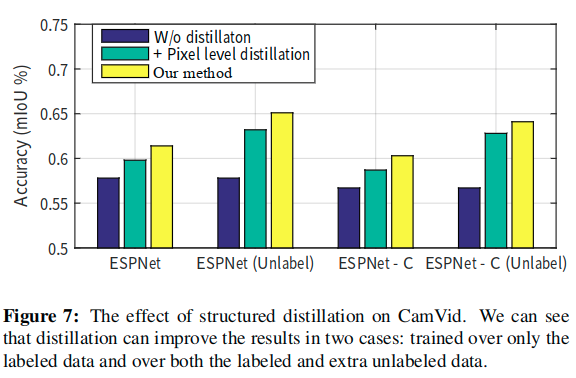
一些感想
- 关于蒸馏方法研究的实验的设置:
- 比较浮点运算数量和参数量
- 评估该任务常用的评价指标
- 对比的模型的选择:
- 在特定数据集上对比不同设置(多个创新点的叠加、不同backbone等)下自身网络的效果
- 在特定数据集上对比不同蒸馏手段下带来的效果提升
- 在该领域主要的数据集上和现有轻量快速网络比较
- 密集预测任务,直接用老师的预测来监督学生的预测,这可以认为是像素级蒸馏
参考链接

若有收获,就点个赞吧
0 人点赞
