
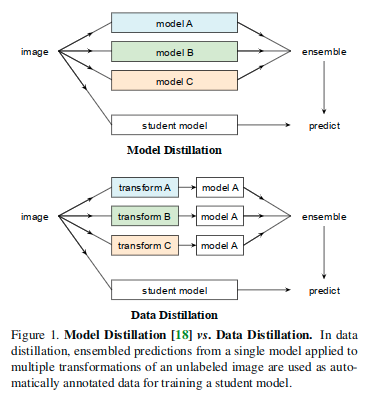
这篇文章提出了一个新的蒸馏方式——数据蒸馏(data distillation),以及一种新的监督学习——omni-supervised learning(全方位监督学习)。
全方位监督学习是以现存有标记数据集上的性能作为下限,这有望超越最先进的全监督方法。这里提出数据蒸馏方法来探索全方位监督学习的设置。数据蒸馏是一种通过整合多种变换下使用单一模型在无标签数据上的不同预测,自动生成新的训练标注(伪标签)的方法。文章认为,视觉识别模型最近已经变得足够精确,现在有可能将有关自我训练(self-training)的经典思想应用于挑战现实数据。
相关介绍
本文研究了全方位监督学习,即学习者利用尽可能多的带注释的数据(如ImageNet、COCO),并提供可能无限的未标记数据(如来自internet的数据)。这是一种特殊的半监督学习。
- 然而,大多数关于半监督学习的研究通过分割完全注释的数据集来模拟标记/未标记的数据,因此可能会以通过使用所有数据注释的全监督学习作为上限。
- 相反,全方位监督学习是以使用所有有标注数据训练的准确性作为下界,其成功可以通过超过全监督基线的程度来评估。
数据蒸馏是一个简单而且自然的基于自学习(self-training,也就是在无标签数据上做预测,并使用它们来更新模型的训练方式,这实际上是一种半监督学习的方法)的想法。然而文章中简单数据蒸馏方法能够变得现实,很大程度上要归功于过去几年来全监督模型的快速改进。尤其是我们现在配备了准确的模型,相较于正确的预测,能够获得更少的误差。这使得可以信任他们在未曾见过的数据上的预测,并且降低开发启发式数据清洗的需求。数据蒸馏并不需要更改识别模型(例如,不需要更改损失的定义),并且对于处理大规模无标记数据源,也是一种可以扩展的方案。
与先前的一些工作相比,本文的方法基本上更简单。一旦生成了预测的标注,本文方法就会利用它们。就像它们是真正的标签一样。不需要对优化问题或模型结构进行任何修改。
关于大规模数据的使用,[9]在8000万张小图像上进行半监督学习。NEIL[5]采用自我训练的方式,在网络图像数据上执行半监督学习。但这些方法是在深度学习复兴之前开发的。相反,本文的方法用强大的深度神经网络基线评估,并且可以应用于超出图像级分类的结构化预测问题(例如,关键点和框预测问题)。
主要工作
文章主要的贡献:
- 提出一种所谓“数据蒸馏”的方式来处理全方位监督学习
- 构造了一种多转换推理(multi-transform inference)的无标签数据处理方式
- 针对无标记数据的多组伪真值设计了一种整合的方法
文章主要的流程:
- 在大量手工标记数据上按照正常的全监督学习的方式训练好的一个模型
- 无标签数据通过几组不同的变换后获得对应的几组新数据
- 使用训练好的模型在新数据上生成对应的伪标签
- 将生成的多组伪标签进行整合(ensemble),获得一组最终的标签
- 在这些额外的数据和对应生成的伪标签上,重新训练之前的模型
这里对扩充的无标签数据的不同变换处理后使用预先训练的小模型生成数种伪真值,对这些不同变换对应的伪真值进行整合(ensemble)作为该小模型重新训练时的监督。
Multi-transform inference
文章使用了多种变换来对数据进行处理。将一个单一模型作为多转换推理应用于数据点的多变换。在数据蒸馏中,针对大量未标记的数据应用多变换推理。
- 之所以考虑要使用不同变化后的数据的伪标签整合后的结果,是因为考虑到在一个模型自己的预测结果上训练自己(self-training)通常不会提供什么有意义的信息。
- 实际上,在一般的任务中,当测试时,对于数据的转换可以提高单模型的精度,这是众所周知的技巧,这说明它们可以提供单一预测无法捕捉到的重要知识。
- 提升视觉识别模型准确率的一个常用策略是针对使用多个转换处理后的输入来使用相同的模型,并最终将结果集成(模型集成)。
- 这里对于数据集的不同几何变换,可以认为是对于数据的不同观察视角或者是扰动,这可为半监督学习提供有用的信号。
与[G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. arXiv:1503.02531, 2015.](它从多个模型的预测中蒸馏知识)相比,本文蒸馏了运行在未标记数据多个变换处理后的副本上的单一模型的知识。
Generating labels on unlabeled data
通过聚合多变换推断的结果,通常可以获得优于单个变换下的任何模型预测的单个预测(例如,参见图2)。
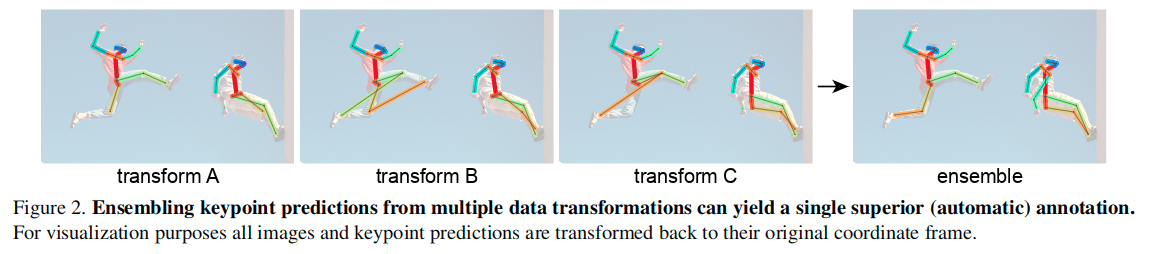
经过观察,整合预测的操作可以产生新知识,并且原则上模型可以使用该信息通过生成标签来自学习。给定一个未标记的图像和一组来自多变换推理的预测,有多种方法可以自动生成图像上的标签。例如在分类问题的情况下,图像可以用类概率的平均值标记[18]。然而,这种策略有两个问题。
- 首先,它生成一个“软”标签(概率向量,而不是类别标签),在重新训练模型时可能不会直接使用。例如,可能需要改变训练损失,使其与软标签兼容。
- 其次,对于结构化输出空间的问题,如对象检测或人体姿态估计,平均输出是没有意义的,因为必须注意尊重输出空间的结构。
考虑到这些因素,本文只是简单地整合或者集成来自多变换推理的预测,其方式是生成的与手动注释数据中可以被发现的相同结构和类型的“硬”标签。生成硬标签通常需要少量特定于任务的逻辑来处理问题的结构(例如,通过NMS来合并多个框)。一旦生成了这样的标签,它们就可以以即插即用方式用于重新训练模型,就像它们是真实的标签一样。最后,虽然这个过程需要多次运行推理,但它实际上是有效的,因为它通常比从头开始训练多个模型“廉价”得多,正如模型蒸馏所要求的那样。
Knowledge distillation
来自无标签数据的新知识可以用来提升模型。为了做到这一点,学生模型(可以和原始模型相同或者不同)在原始的监督数据和无标签数据(通过原始模型自动生成标签)的联合数据集上进行训练。在联合数据集上训练是直接的,并且不需要更改损失函数。然而这里考虑了两点:
- 需要确保每个训练的minibatch是手工标记数据和自动标记数据的混合数据集,也就是要确保每个minibatch中包含一定比例的真实标签,这样更有利于梯度的估计。
- 因为有更多的数据可以获取,训练的计划也得进行一定的调整,保证足够长来充分利用这些数据。
Keypoint Detection
Data transformations:本文选择了一些几何变换进行多变换推理,但也可以进行其他变换,如颜色抖动。唯一的要求是it must be possible to ensemble the resulting predictions。对于几何变换,如果预测是一个几何量(例如,一个关键点的坐标),那么在合并之前必须对每个预测应用逆变换。
- We use two popular transformations: scaling and hor-izontal flipping.
- We resize the unlabeled image to a pre-defined set of scales (denoted by the shorter side of an image): [400, 1200] pixels with a stepsize of 100, which was selected by measuring the keypoint AP for the teacher model when applying these transformations on the validation set.
- The selected transformations can improve the model by a good margin, e.g. for ResNet-50 from 65.1 to 67.8 AP, which is then used as the teacher. Note that unless stated, we do not apply these transformation at test time for all baseline/distilled models.
Ensembling:关于处理数据最关键的集成策略,这里针对使用的模型和任务都需要特殊调整。
keypoint detection使用的是Mask R-CNN,包含两个阶段,第一个阶段是RPN(区域提案网络),第二个阶段包含三个头部,分别针对RoI(感兴趣区域)进行边界框分类、回归和keypoint预测处理,其中keypoint分支输出一个heatmap,这用来为每个keypoint类型预测一个one-hot mask。
关于集成策略,一个直接的想法就是针对每一个阶段和每一个头部的结果集成多变换推理结果,但在实验中,为了简单,仅是在keypoint头部使用了多变换推理。其他头部和阶段的输出都是单尺度并且没有任何变换的。这样的简化,使得能够拥有一套一致的检测框来服务针对于所有转换的RoI。在一个单独的RoI上,可以提取来自所有转换的keypoint heatmaps,尽管他们来自不同的几何变换,这些heatmaps都是以相同的RoI的局部坐标系为参照的。因此可以直接平均这些heatmaps的输出来集成结果。在集成结果中,选择值最大的索引,并且生成预测的keypoint位置。
Selecting predictions:
- 为了生成好的训练标签,期望预测框和keypoint是足够可靠的,否则预测结果中就会包含大量的假阳性(false positives)结果(也就是误检)。
- 这里使用了一个预测检测得分作为对于预测质量的一个代理并且仅对在某个得分阈值之上的预测生成标注。
- 实际发现,如果得分阈值使得“每个未标记图片中的注释实例的平均数量”大致等于“每个标记图片中的实例平均数量”时,结果表现良好。
- 尽管这一点假设了未标记数据和标记数据遵循着相似的分布规律,但是实际试验中发现,即使不能保证假设,结果也会比较鲁棒,有着不错的表现。
- 同时也需要考虑在扩充数据中的假阴性预测的问题(也就是漏检),并且生成的标注没必要被看做是完整的(也就是说没有标注也并不意味着是真实的背景。
- 然而,在实际中,对于训练接测器而言,尝试对来自扩充数据的背景区域采样与否,在准确率上没有观察到什么差异。
- 为了简化,所有的试验中,都将生成的数据看作是完整的,也就是说,直接认为所有的生成标注是正确的。
Generating keypoint annotations:对于每个选定的预测,其中包含着K个单独的keypoint(例如左耳,鼻子等等),因为许多的目标视角并不能显示出所有的keypoint类型,所以预测的keypoint可能包含着假阳性预测(误检)。所以按照前面的思路,这里选择了一个阈值,使得关键点的平均数量在监督集合和生成集合中近似相等。
Retraining:在原始监督数据和自动生成注释的数据的联合数据集上训练学生模型。为了在minibatch层级上维持监督的质量,这里使用对于两种数据使用了一个固定的比例。
- 具体来说,除非特殊说明,对于每个minibatch中数据选择的时候随机采样,并确保原始有监督图片和生成标签的图像的预期比例为6:4。
- 使用了一个和老师模型有着相同架构的学生模型,它可以从教师模型开始微调,或者直接从初始化权重(例如ImageNet上预训练)重新训练。实际中发现重新训练的策略始终能带来更好的表现,这表明教师模型可能处于较差的局部最优,而重新训练可能有助于跳出局部最优点。在所有的实验中都选择了重新训练。
data distillation:在COCO数据集上进行针对keypoint detection任务的数据蒸馏操作。
- 实际使用的数据包含三大部分:
- COCO labeled images. These are the original labeled COCO images that contain ground-truth person and keypoint annotations.
- In this paper, we refer to the 80k training images as co-80, a 35k subset of the 2014 validation images as co-35, and their union as co-115 (in the 2017 version of COCO, co-115 is the train2017 set).
- We do not use the original train/val nomenclature because their roles may change in different experiments.
- COCO unlabeled images. The 2017 version of COCO provides a collection of 120k unlabeled images, which we call un-120.
- These images are expected to have a similar distribution as the labeled COCO images.
- Sports-1M static frames. We will show that our method can be robust to a dissimilar distribution of unlabeled data. We collect these images by using static frames from the Sports-1M video dataset.
- We randomly sample 180k videos from this dataset. Then we randomly sample 1 frame from each video, noting that we do not exploit any temporal information even if it is possible.
- This strategy gives us 180k static images. We call this set s1m-180.
- We do not use any available labels from this static image set.
- COCO labeled images. These are the original labeled COCO images that contain ground-truth person and keypoint annotations.
- 主要设计的实验:
- Small-scale data as a sanity check: we use co-35 as the labeled data and treat co-80 as unlabeled.
- Large-scale data with similar distribution: we use co-115 as the labeled data and un-120 as unlabeled.
- Large-scale data with dissimilar distribution: we use co-115 as the labeled data and s1m-180 as unlabeled.
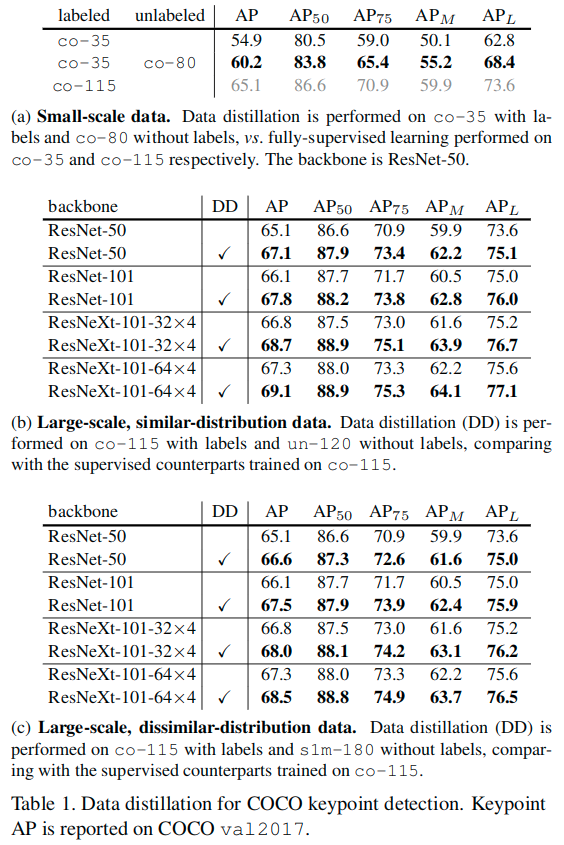
关于表a中小规模数据集和大规模数据集结果。在许多半监督学习方法和数据集中,小规模数据上的现象已经得到了广泛的观察:如果所有的训练数据都有标签,那么使用所有的标签时,半监督学习的准确性将会达到上限。
我们认为全方位监督学习是一个真实的场景,不像上面模拟的半监督数据集。尽管可以给很多图片进行标记,但总有更多未标记的数据可用(例如,互联网上的图片数据)。因此,对于全方位监督学习是有精度下限的。此外,当使用更大的数据集训练时,基线会更高(例如,65.1%),使得模型从未标记的数据中获得提升的空间更小。因此,可以认为大规模、高精度的范式是更具挑战性的并且在实践中更加让人感兴趣。
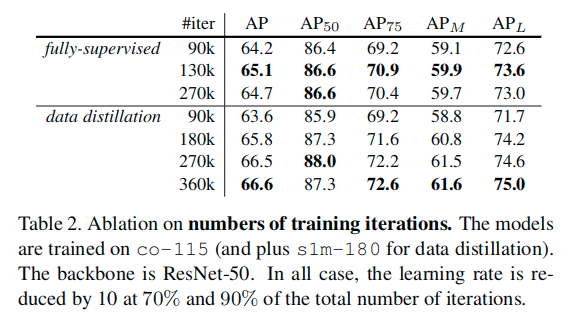
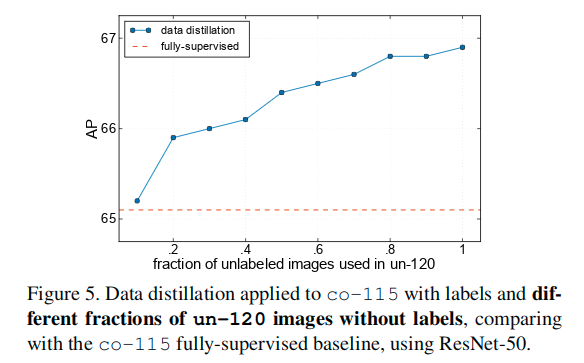
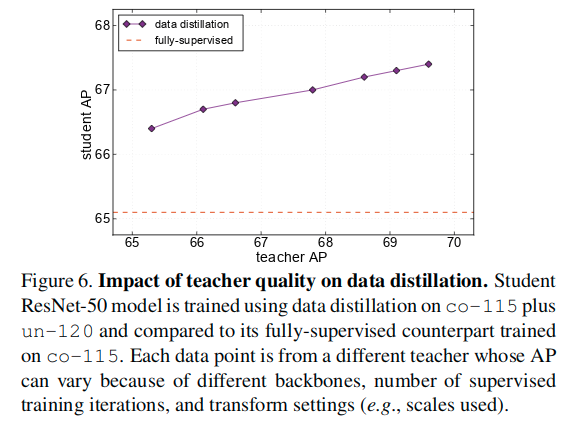
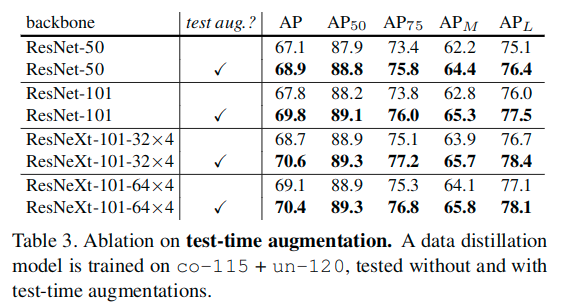
Our data distillation method exploits multi-transform inference to generate labels. Multi-transform inference can also be applied at test-time to further improve results, a strategy typically called test-time augmentation. Table 3 shows the results of applying test-time augmentations on a data distillation model. The augmentations are the same as those used to generate distillation labels. It shows that test-time augmentations can still improve the results over our data distillation model.
Interestingly, the student model’s 68.9 AP (ResNet-50, in Table 3) is higher than its corresponding (test-time augmented) teacher’s 67.8 AP. We believe that this is a signal of our approach being able to learn new knowledge from the extra unlabeled data, instead of simply learning to be robust to the transforms. Even though we use multiple data-agnostic transforms, the distilled labels are data-dependent and may convey knowledge from the extra data. This result also suggests that performing data distillation in an iterative fashion may improve the results further. We leave this direction for future work.
Object Detection
We investigate the generality of our approach by applying it to another task with minimal modification.
- We perform data distillation for object detection on the COCO dataset. Here our data splits involve co-35/80/115 as defined above. We test on minival.
- Our object detector is Faster R-CNN with the FPN backbone and the RoIAlign improvement.
- We adopt the joint end-to-end training as described in [Faster R-CNN: To-wards real-time object detection with region proposal networks]. Note that this is unlike in our keypoint experiments where we froze the RPN stage (which created the same set of boxes for keypoint ensembling).
- To produce the ensemble results, we simply take the union set of the boxes predicted under different transformations, and combine them using bounding box voting [Object detection via a multi-region & semantic segmentation-aware cnn model] (a process similar to non-maximum suppression that merges the suppressed boxes). This ensembling strategy on the union set of boxes shows the flexibility of our method: it is agnostic to how the results from multiple transformations are aggregated.
- The object detection task involves multiple categories. A single threshold of score for generating labels may lead to strong biases.
- To address this issue, we set a per-category threshold of score confidence for annotating objects in the unlabeled data.
- We choose a threshold for each category such that its average number of annotated instances per image in the unlabeled dataset matches the average number of instances in the labeled dataset.

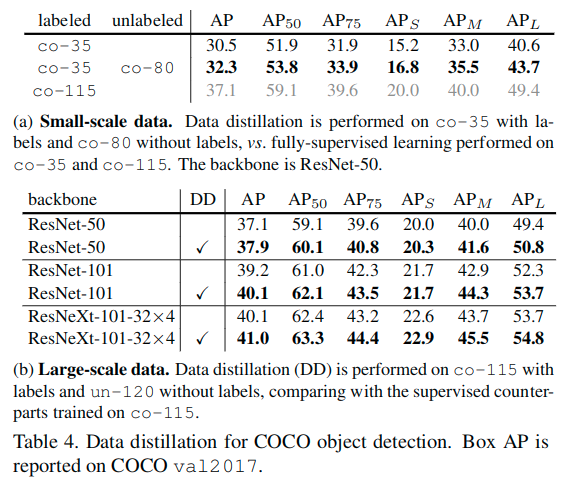
这里依然使用了小规模数据和大规模数据来进行测试。
- Small-scale data: we use co-35 as the labeled data and treat co-80 as unlabeled.
- Large-scale data: we use co-115 as the labeled data and un-120 as unlabeled.
相关链接

若有收获,就点个赞吧
0 人点赞
