
@inproceedings{Zagoruyko2017AT,author = {Sergey Zagoruyko and Nikos Komodakis},title = {Paying More Attention to Attention: Improving the Performance ofConvolutional Neural Networks via Attention Transfer},booktitle = {ICLR},url = {https://arxiv.org/abs/1612.03928},year = {2017}}
主要工作
本文的教师-学生模型希望学生模型可以学习到:
- 网络内部特征的注意力图
- 最终的输出知识
提出了一个注意力转移的蒸馏方法,使用过程中的特征的注意力图来进行蒸馏。
这里提出了两种注意力,一种是ACTIVATION-BASED ATTENTION TRANSFER,另一种是GRADIENT-BASED ATTENTION TRANSFER。重点在于计算损失的时候有差异。
主要结构
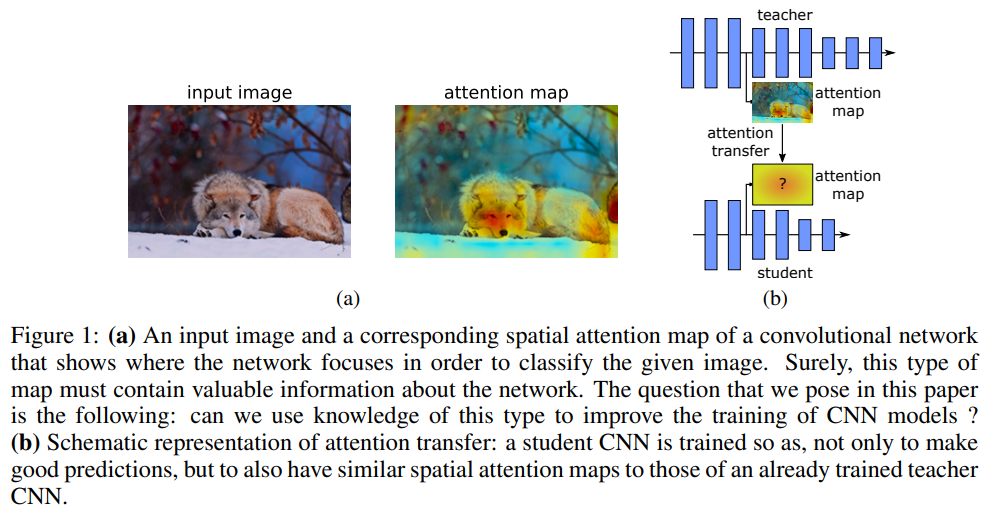

损失相关
这里直接放代码:
# 对于最后的输出
def distillation(y, teacher_scores, labels, T, alpha):
p = F.log_softmax(y/T, dim=1)
q = F.softmax(teacher_scores/T, dim=1)
l_kl = F.kl_div(p, q, size_average=False) * (T**2) / y.shape[0]
l_ce = F.cross_entropy(y, labels)
return l_kl * alpha + l_ce * (1. - alpha)
# 对于过程中间的每个要监督的位置
def at(x):
return F.normalize(x.pow(2).mean(1).view(x.size(0), -1))
def at_loss(x, y):
return (at(x) - at(y)).pow(2).mean()
相关链接

若有收获,就点个赞吧
0 人点赞
