
@article{hou2019learning,title={Learning Lightweight Lane Detection CNNs by Self Attention Distillation},author={Hou, Yuenan and Ma, Zheng and Liu, Chunxiao and Loy, Chen Change},journal={arXiv preprint arXiv:1908.00821},year={2019}}
被 ICCV 2019接收。
主要工作
本文的学生-学生模型希望学生模型可以学习到:
- 学生网络自己前期特征注意力图
提出了一种使用自身前期特征图来作为蒸馏监督的监督方法,即所谓的“自注意力蒸馏”——自己蒸自己。
这篇文章和Attention Transfer方法有很大的关联。
Different from Sergey et al. [Paying more attention to attention: improving the performance of convolutional neu-ral networks via attention transfer] who perform attention distillation within two networks, the proposed self attention distillation is performed within the network itself.
主要结构
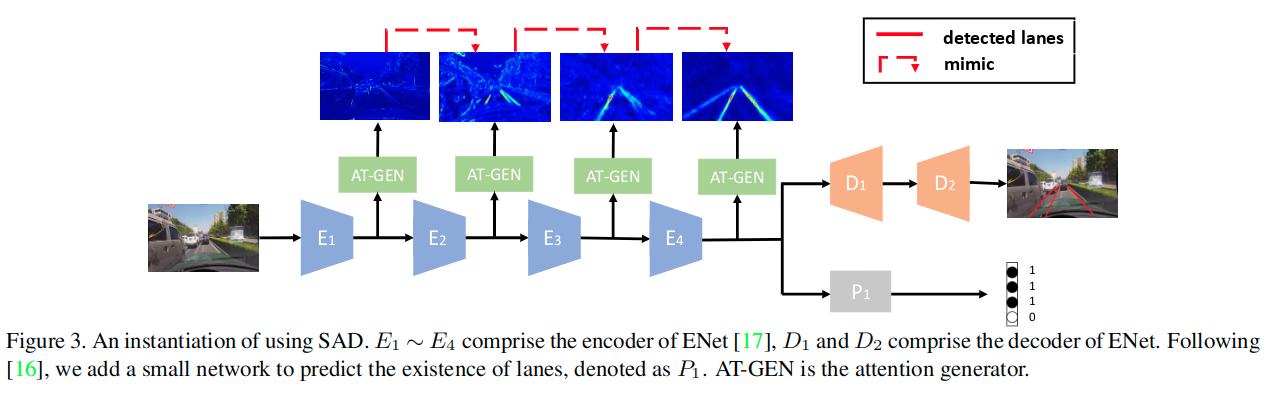
要注意,关于这里的蒸馏路径实际上不知这样的一种,还可以使用类似于DenseNet那样的密集连接方式。实际上可能的蒸馏路径对于M层网络而言,可以有 种连接方式。
种连接方式。
损失函数
最终的损失函数:
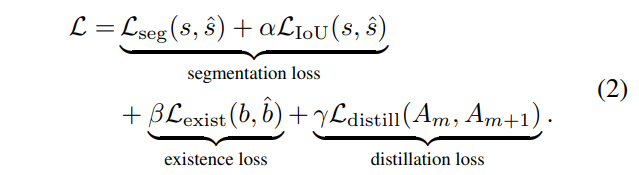
Lseg和LIoU表示分割用的标准交叉熵和IoU损失,Lexist表示二值交叉熵损失,输入为车道线存在与否的图的概率图(推测,应该是概率图,BCELoss),最后是蒸馏损失了,使用的输入是各层的特征。
交叉熵损失和二值交叉熵损失的设置代码:
criterion = torch.nn.NLLLoss(ignore_index=ignore_label, weight=class_weights).cuda()criterion_exist = torch.nn.BCELoss().cuda()...input_var = torch.autograd.Variable(input)target_var = torch.autograd.Variable(target)target_exist_var = torch.autograd.Variable(target_exist)# compute outputoutput, output_exist = model(input_var) # output_midloss = criterion(torch.nn.functional.log_softmax(output, dim=1), target_var)# print(output_exist.data.cpu().numpy().shape)loss_exist = criterion_exist(output_exist, target_exist_var)loss_tot = loss + loss_exist * 0.1
关于蒸馏部分没有在Pytorch代码中实现,所以这里就不放了。
参考链接

若有收获,就点个赞吧
0 人点赞
