- 1、基本介绍、安装
- 2、使用示例
- jy: 即初始化 /simcse/tool.py 中的 SimCSE 类(内部同样是基于 transformers 包进行模型管理);
- jy: 如果安装了 GPU 版本的 torch 包, 需确保有空闲 GPU 可用, 否则报错如下:
- RuntimeError: CUDA error: out of memory
- jy: torch.Size([768])
- jy:
- jy: array([[0.01262083, 0.34469506],
- [0.89384234, 0.04842842]], dtype=float32)
- jy: 如果环境中有安装 faiss 包,则以下的 build_index 方法(在 /simcse/tool.py 的 SimCSE 类
- 中定义)会自动导入 faiss 包加速运算; 注意: faiss did not well support Nvidia AMPERE
- GPUs (3090 and A100). In that case, you should change to other GPUs or install
- the CPU version of faiss package.
- jy: [(‘A man is playing a guitar.’, 0.8938424)]
- 3、参考
1、基本介绍、安装
(1)基本介绍
- SimCSE:Simple Contrastive Learning of Sentence Embeddings
- a simple contrastive learning framework that greatly advances the state-of-the-art sentence embeddings.
论文:【2021-09-09】SimCSE:Simple Contrastive Learning of Sentence Embeddings
(2)安装
创建虚拟环境,安装指定版本的 setuptools 包
conda create --name jy-simCSE_py36 python==3.6.5pip install setuptools==49.3.0- 注意:低于此版本后续安装可能会报错(版本参考自项目 github 中的 requirements.txt 说明)
安装 torch
尽管 pip 安装
simcse时会自动安装该依赖包;但相应版本可能与当前机器的 cuda 环境不符(带 GPU 的机器环境),如: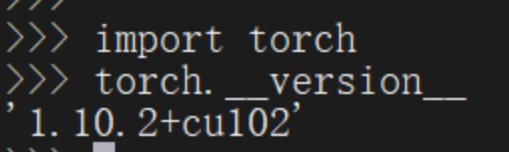
但 cuda 环境如下:

此时在使用
simcse时可能产生如下错误: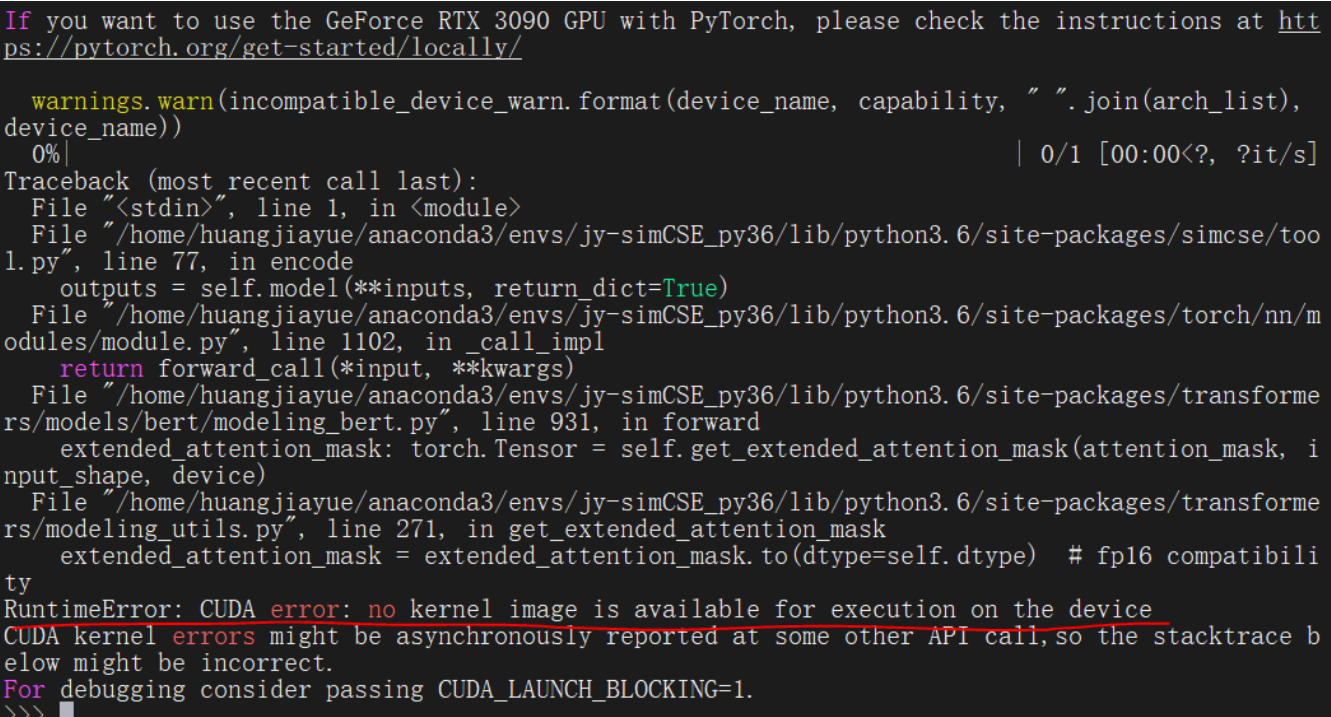
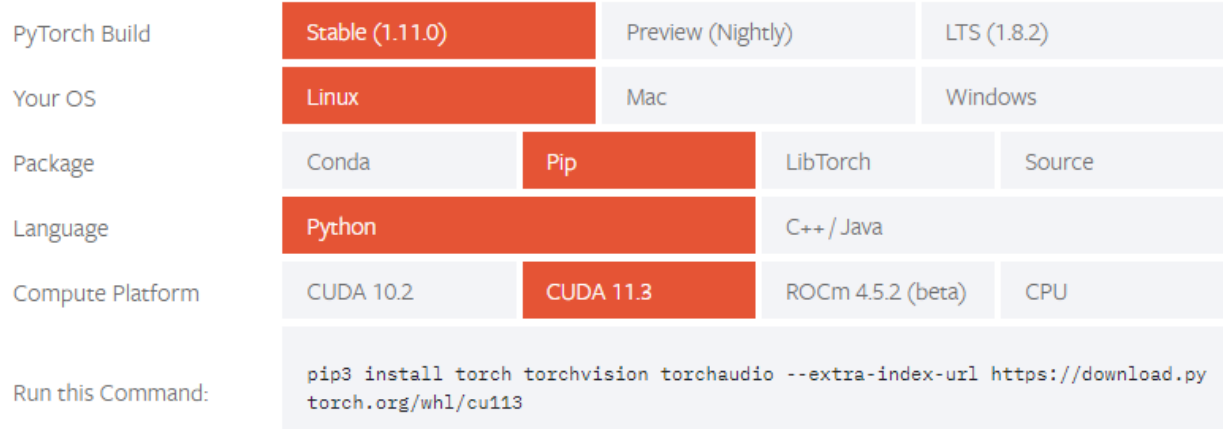
因此,建议根据机器环境手动安装 torch 包
pip install --upgrade pip- pip 版本太低会影响 torch 依赖包 pillow 的安装
- GPU 版本(CUDA > 11)
pip install torch==1.7.1+cu110 -f https://download.pytorch.org/whl/torch_stable.html
CPU 版本(或 CUDA < 11)
pip install torch==1.7.1参考官网:https://pytorch.org/get-started/locally/
安装 simcse
注意:以下两种方式导入模型最终均为基于 huggingface(transformers)导入。
- 模型使用时的代码问题:https://github.com/princeton-nlp/SimCSE/issues/186
(1)使用 /simcse/tool.py 中的 SimCSE 类进行模型导入
```python from simcse import SimCSE
jy: 即初始化 /simcse/tool.py 中的 SimCSE 类(内部同样是基于 transformers 包进行模型管理);
model = SimCSE(“princeton-nlp/sup-simcse-bert-base-uncased”)
jy: 如果安装了 GPU 版本的 torch 包, 需确保有空闲 GPU 可用, 否则报错如下:
RuntimeError: CUDA error: out of memory
embeddings = model.encode(“A woman is reading.”)
jy: torch.Size([768])
print(embeddings.shape)
jy:
print(type(embeddings))
sentences_a = [‘A woman is reading.’, ‘A man is playing a guitar.’] sentences_b = [‘He plays guitar.’, ‘A woman is making a photo.’] similarities = model.similarity(sentences_a, sentences_b)
jy: array([[0.01262083, 0.34469506],
[0.89384234, 0.04842842]], dtype=float32)
print(similarities)
sentences = [‘A woman is reading.’, ‘A man is playing a guitar.’]
jy: 如果环境中有安装 faiss 包,则以下的 build_index 方法(在 /simcse/tool.py 的 SimCSE 类
中定义)会自动导入 faiss 包加速运算; 注意: faiss did not well support Nvidia AMPERE
GPUs (3090 and A100). In that case, you should change to other GPUs or install
the CPU version of faiss package.
model.build_index(sentences) results = model.search(“He plays guitar.”)
jy: [(‘A man is playing a guitar.’, 0.8938424)]
print(results)
<a name="k4Yfa"></a>## (2)基于 transformers 包进行模型导入```pythonimport torchfrom scipy.spatial.distance import cosinefrom transformers import AutoModel, AutoTokenizer# Import our models. The package will take care of downloading the models automaticallytokenizer = AutoTokenizer.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")model = AutoModel.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")# Tokenize input textstexts = ["There's a kid on a skateboard.","A kid is skateboarding.","A kid is inside the house."]inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")# Get the embeddingswith torch.no_grad():embeddings = model(**inputs, output_hidden_states=True, return_dict=True).pooler_output# Calculate cosine similarities# Cosine similarities are in [-1, 1]. Higher means more similarcosine_sim_0_1 = 1 - cosine(embeddings[0], embeddings[1])cosine_sim_0_2 = 1 - cosine(embeddings[0], embeddings[2])print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[1], cosine_sim_0_1))print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[2], cosine_sim_0_2))"""Cosine similarity between "There's a kid on a skateboard." and "A kid is skateboarding." is: 0.943Cosine similarity between "There's a kid on a skateboard." and "A kid is inside the house." is: 0.439"""
(3)使用示例汇总
from simcse import SimCSE
def get_sents_similarity(model, ls_sents1, ls_sents2):
similarities = model.similarity(ls_sents1, ls_sents2)
return similarities
def get_sent_embedding(model, sentence):
return model.encode(sentence)
def similarity_search(model, ls_sents, sent_or_ls_sents, threshold=0.6, top_k=5):
# jy: 如果环境中有安装 faiss 包,则以下的 build_index 方法(在 /simcse/tool.py
# 的 SimCSE 类>中定义)会自动导入 faiss 包加速运算。
# 注意: faiss did not well support Nvidia AMPERE GPUs (3090 and A100). In
# that case, you should change to other GPUs or install the CPU
# version of faiss package.
model.build_index(ls_sents)
results = model.search(sent_or_ls_sents, threshold=threshold, top_k=top_k)
return results
def remove_cn_punct(str_cn):
pattern_cn_punct = "[,|≥|。|、|...|?|=|’|‘|“|”|;|:|!|(|)|%|,|\-|:| |/|\]|\[|(|)|>|<]"
#pattern_cn_punct = "[,|。|、|...|?|’|‘|“|”|;|:|!| |(|)"
str_cn = re.sub(pattern_cn_punct, "", str_cn).strip()
return str_cn
# jy: simcse 官方模型;
#model = SimCSE("princeton-nlp/sup-simcse-bert-base-uncased")
#model = SimCSE("princeton-nlp/unsup-simcse-bert-base-uncased")
# jy: 官方 supervised 模型本地路径;
# a) supervised:
#model_path = "/home/huangjiayue/04_SimCSE/jy_model/sup-simcse-bert-base-uncased"
# b) unsupervised:
model_path = "/home/huangjiayue/04_SimCSE/jy_model/unsup-simcse-bert-base-uncased"
model = SimCSE(model_path)
# 注意:如果安装了 GPU 版本的 torch 包,需确保有空闲 GPU 可用,否则报错 OOM
# ============= (1) 句子向量化 ===========================================
#"""
sentence = "A woman is reading."
embeddings = get_sent_embedding(model, sentence)
# <class 'torch.Tensor'>
print(type(embeddings))
# torch.Size([768])
print(embeddings.shape)
sentence2 = "A man is playing a guitar."
embeddingss = get_sent_embedding(model, sentence2)
#"""
# ============= (2) 句子相似度计算 ========================================
"""
sentences_a = ['A woman is reading.', 'A man is playing a guitar.']
sentences_b = ['He plays guitar.', 'A woman is making a photo.']
# array([[0.01266468, 0.3446282 ],
# [0.8938298 , 0.04850736]], dtype=float32)
similarities = get_sents_similarity(model, sentences_a, sentences_b)
"""
# ============= (3) 相似句子搜索 ========================================
"""
ls_sents = ['A woman is reading.', 'A man is playing a guitar.', "what are you doing"]
#sentences = ["她在阅读", "他在弹吉他"]
#sent_or_ls_sents = "He plays guitar."
sent_or_ls_sents = ["He plays guitar.", "I'm reading"]
#sent_or_ls_sents = ["I'm reading", "He plays guitar.", "I play guitar.", "I read and play guitar."]
similarities = get_sents_similarity(model, sent_or_ls_sents, ls_sents)
print(similarities)
res = similarity_search(model, ls_sents, sent_or_ls_sents, threshold=-1, top_k=5)
print(res)
"""
(4)示例代码流程分析(包含 transformers 的包管理流程)
3、参考

若有收获,就点个赞吧
0 人点赞
