1、TF-IDF 介绍
- TF-IDF:{Term Frequency}-{Inverse Document Frequency},是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
- TF-IDF 算法是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
- 字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
- TF-IDF 的主要思想:如果某个单词在一篇文章中出现的频率 TF 高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- TF-IDF 实际上是:
TF * IDF- 某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。
- 显然,一个词在文章中出现很多次,那么这个词肯定有着很大的作用(‘的’、‘是’等停用词除外)。
- 假设把停用词都过滤掉、只考虑剩下有实际意义的词。这样又会遇到了另一个问题:可能发现 “中国”、”蜜蜂”、”养殖” 这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
- 显然不是这样。因为 “中国” 是很常见的词,相对而言,”蜜蜂” 和 “养殖” 不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,”蜜蜂” 和 “养殖” 的重要程度要大于 “中国”,也就是说,在关键词排序上面,”蜜蜂” 和 “养殖” 应该排在 “中国” 的前面。
- 所以,需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
- 用统计学语言表达,就是在词频的基础上,要对每个词分配一个 “重要性” 权重。最常见的词(”的”、”是”、”在”)给予最小的权重,较常见的词(”中国”)给予较小的权重,较少见的词(”蜜蜂”、”养殖”)给予较大的权重。这个权重叫做 “逆文档频率”(Inverse Document Frequency,IDF),它的大小与一个词的常见程度成反比。
- 知道了”词频”(TF)和”逆文档频率”(IDF)以后,将这两个值相乘,就得到了一个词的 TF-IDF 值。某个词对文章的重要性越高,它的 TF-IDF 值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
- TF-IDF 加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
- 除了 TF-IDF 以外,搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
- 从事 SEO 行业时间比较长的人应该都听说过 TF-IDF 算法,TF-IDF 算法属于搜索引擎中的核心部分。TF-IDF 算法是增加相关词的覆盖率,以及高优布局关键词密度,从而在百度谷歌等搜索引擎内容质量这一项上的排名加分,获取超高分值。
注: TF-IDF 算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
(1)TF(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率(次数)。这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件。
 ,即:
,即:
逆向文件频率 (IDF) :某一特定词语的 IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
- 如果包含词条t的文档越少, IDF 越大,则说明词条具有很好的类别区分能力。
 ,即:
,即:
 (Term
(Term within document
within document )
) :Fregency of
:Fregency of in
in
 :Number of documents containing
:Number of documents containing 
 :Total number of documents
:Total number of documents
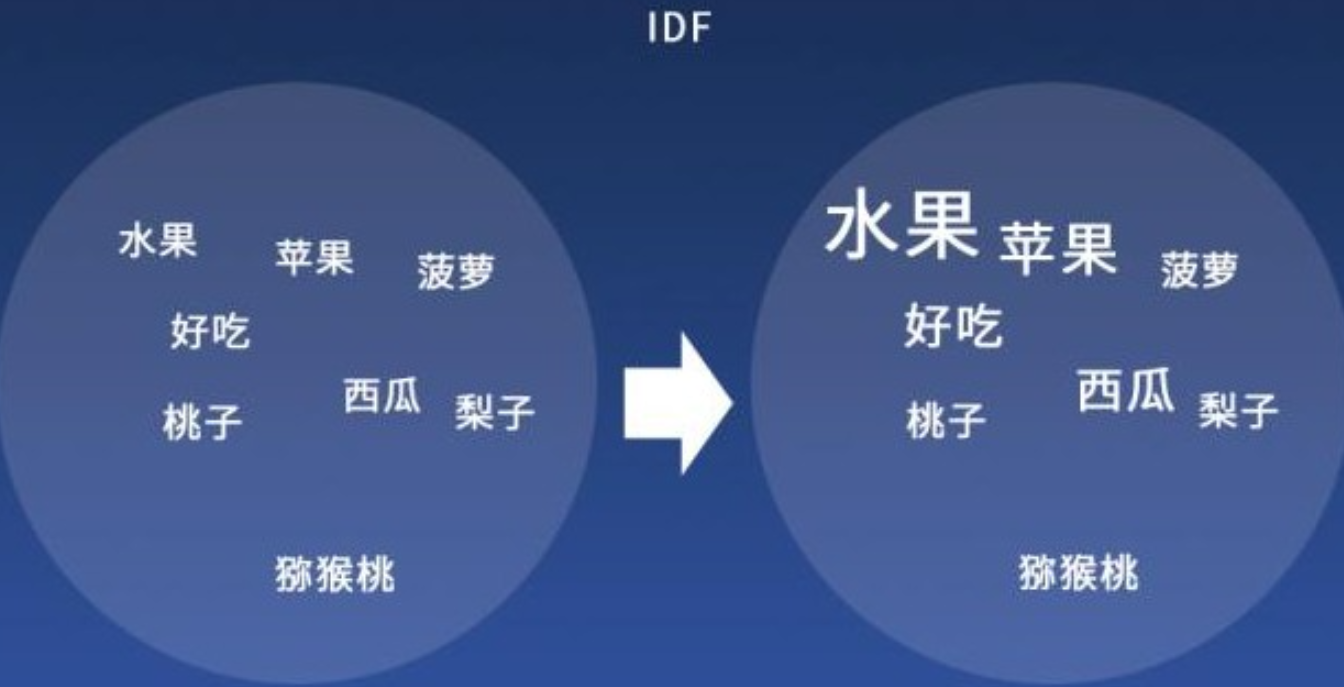
假如我们在百度上搜索“水果”这个词,百度爬虫抓取的网站内容有下面 5 个,你觉得哪个内容排名第一?
内容1: 水果有水果,水果,水果,水果,水果内容2: 水果有苹果,桃子,西瓜,菠萝,梨子内容3: 蔬菜都很好吃,我最爱吃茄子了内容4: 苹果,梨子都是很好吃的水果内容5:好吃的水果有西瓜,苹果,葡萄,其他水果还有菠萝,猕猴桃
大家凭直觉,内容 2 跟内容 5 应该排名靠前,内容 5 很可能是第 1,内容 2 是排名第 2。最终的排名顺序为 52413。
- 至于为什么呢?核心词为“水果”,5 和 2 里都有“水果”和“苹果”两个关键词且 5 里有出现两次“水果”,4 比 2 少了一个苹果关键词,1 里面包括有“水果”这个关键词但有堆砌行为,3 和核心词没有相关性。
- 其实按照 TF-IDF 算法也能得出这个结论。
以下是 TF-IDF 算法简化解读版,真实的 TF-IDF 算法比这个要正规复杂很多。
(1)计算 IDF(Inverse Document Frequency,逆文档频率)
先统计各个词语被包含的文章数。比如“水果”被 4 篇文章(1、2、4、5)引用,4 就是“水果”的逆文档频率。
- 分词后,各个单词的逆文档频率如下:
- 水果=4、苹果=3、好吃=2、菠萝=2、西瓜=2、梨子=2,桃子=1、猕猴桃=1、蔬菜=1,茄子=1
 是该词在文件
是该词在文件 中出现的次数,分母则是文件
中出现的次数,分母则是文件 中所有词汇出现的次数总和。
中所有词汇出现的次数总和。
 :语料库中的文件总数。
:语料库中的文件总数。 :包含词语
:包含词语 的文件数目(即
的文件数目(即 的文件数目)
的文件数目)
- 注意:
IDF= log(语料库中的文件总数 / 包含词语 t 的文件数目),即:
- 为了便于理解,这里做了精简。
- 按照直觉,如果一篇文章把逆文档频率最高的前面的词都包含了,说明这篇文章内容更贴合用户意图,更受到搜索引擎喜欢。回到例子,“水果、苹果”是本例中重要性最高的 2 个词,如果内容中包含“水果、苹果”,那么这篇内容质量就越好。
所以把包含“水果、苹果”的内容拿出来,就是比较靠谱的内容了:
内容2: 水果有苹果,桃子,西瓜,菠萝,梨子内容4: 苹果,梨子都是很好吃的水果内容5: 好吃的水果有西瓜,苹果,葡萄,其他水果还有菠萝,猕猴桃
(2)计算词频(TF)
把内容 1、3 砍掉,剩下的内容 2、4、5 怎么排序。我们想一下,一个词语在内容中出现的次数越高,说明这个词语对这篇文章更重要。本例“水果”是核心词,那么因为内容 5 中出现“水果”两次,内容2、4 次数是 1,那么内容 5 胜出。最后的排序结果如下:
内容5: 好吃的水果有西瓜,苹果,葡萄,其他水果还有菠萝,猕猴桃 (第一名)内容2: 水果有苹果,桃子,西瓜,菠萝,梨子(第二名)内容4: 苹果,梨子都是很好吃的水果(第三名)内容1: 水果有水果,水果,水果,水果,水果(相关度不够,被剔除)内容3: 蔬菜都很好吃,我最爱吃茄子了( 相关度不够,被剔除 )
3、TF-IDF 对 SEO 优化的重要性
TF-IDF 算法不仅可以衡量关键词对页面的重要性,更能衡量文章的广度相关性。对于百度、google 来说,TF-IDF 算法的出现屏蔽了一大批用关键词密度来获取排名的 SEO 小白,同时提升了搜索质。
百度专利中使用 TFIDF 的实锤。搜索算法来去匆匆,百度算法更新迭代也非常快,但是 TFIDF 算法是目前最核心的搜索算法之一。
- 百度专利文档:《CN102737018A-基于非线性统一权值对检索结果进行排序的方法及装置-公开》

(2)TFIDF 得分比重极高
- 如果搜索引擎确定使用 TF-IDF 对网页内容作为评判质量的因子,那么这个比重有多大?
- 现在的搜索引擎一般用如下的算法计算网站页面得分
score(页面得分) = TFIDF 分 * x + 链接分 * y + 用户体验分 * z- 其中
x+y+z=100% - 大约在 2G 左右的谷歌搜索资料中,我们做了人工智能训练,预测 TFIDF 分值大约占百度 40% 左右的权重,谷歌更是达到了 50%。
- 链接分:通过朋友透露,权重大约占百度 20% 左右,谷歌尚不清楚
- 用户体验得分:百度在 40% 左右
- 其中
所以说,做 SEO 优化(TFIDF 的确是较为关键的一部分):
注意:该代码 tf 计算使用的是整个语料,这里只是个简单例子。 ```python from collections import defaultdict import math import operator
def loadDataSet(): “”” 创建数据样本 Returns: dataset - 实验样本切分的词条 classVec - 类别标签向量 “””
# 切分后的词条dataset = [ ['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],['stop', 'posting', 'stupid', 'worthless', 'garbage'],['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],['quit', 'buying', 'worthless', 'dog', 'food', 'stupid'] ]# 类别标签向量, 1 代表好, 0 代表不好classVec = [0, 1, 0, 1, 0, 1]return dataset, classVec
def feature_select(list_words): “”” 特征选择 TF-IDF 算法 Parameters: list_words:词列表 Returns: dict_feature_select:特征选择词字典 “””
# 总词频统计doc_frequency = defaultdict(int)for word_list in list_words:for i in word_list:doc_frequency[i] += 1# 计算每个词的 TF 值, 并存储到 word_tf 中;word_tf = {}for i in doc_frequency:word_tf[i] = doc_frequency[i] / sum(doc_frequency.values())# 计算每个词的 IDF 值doc_num = len(list_words)# 存储每个词的 idf 值word_idf = {}# 存储包含该词的文档数word_doc = defaultdict(int)for i in doc_frequency:for j in list_words:if i in j:word_doc[i] += 1for i in doc_frequency:word_idf[i] = math.log(doc_num / (word_doc[i]+1))# 计算每个词的 TF*IDF 的值word_tf_idf={}for i in doc_frequency:word_tf_idf[i] = word_tf[i] * word_idf[i]# 对字典按值由大到小排序dict_feature_select = sorted(word_tf_idf.items(),key=operator.itemgetter(1),reverse=True)return dict_feature_select
if name == ‘main‘:
# 加载数据data_list, label_list = loadDataSet()# 所有词的 TF-IDF 值features = feature_select(data_list)print(features)print(len(features))
<a name="XW2Gk"></a>## (2)NLTK 中的实现```pythonfrom nltk.text import TextCollectionfrom nltk.tokenize import word_tokenize# 首先,构建语料库 corpussents=['this is sentence one', 'this is sentence two', 'this is sentence three']# 对每个句子进行分词sents=[word_tokenize(sent) for sent in sents]print(sents)# 构建语料库corpus=TextCollection(sents)print(corpus)# 计算语料库中 "one" 的tf值tf = corpus.tf('one', corpus)# 1/12print(tf)# 计算语料库中 "one" 的 idf 值idf=corpus.idf('one')# log(3/1)print(idf)# 计算语料库中 "one" 的 tf-idf 值tf_idf=corpus.tf_idf('one',corpus)print(tf_idf)
(3)sklearn 中的实现
from sklearn.feature_extraction.text import CountVectorizerfrom sklearn.feature_extraction.text import TfidfTransformerx_train = ['TF-IDF 主要 思想 是','算法 一个 重要 特点 可以 脱离 语料库 背景','如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']x_test=['原始 文本 进行 标记', '主要 思想']# 该类会将文本中的词语转换为词频矩阵, 矩阵元素 a[i][j] 表示 j 词在 i 类文本下的词频vectorizer = CountVectorizer(max_features=10)# 该类会统计每个词语的 tf-idf 权值tf_idf_transformer = TfidfTransformer()# 将文本转为词频矩阵并计算 tf-idftf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))# 将 tf-idf 矩阵抽取出来, 元素 a[i][j] 表示 j 词在 i 类文本中的 tf-idf 权重x_train_weight = tf_idf.toarray()# 对测试集进行 tf-idf 权重计算tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))# 测试集 TF-IDF 权重矩阵x_test_weight = tf_idf.toarray()print('输出x_train文本向量:')print(x_train_weight)"""输出x_train文本向量:[[0.70710678 0. 0.70710678 0. 0. 0.0. 0. 0. 0. ][0. 0.3349067 0. 0.44036207 0. 0.440362070.44036207 0.44036207 0. 0.3349067 ][0. 0.22769009 0. 0. 0.89815533 0.0. 0. 0.29938511 0.22769009]]"""print('输出x_test文本向量:')print(x_test_weight)"""输出x_test文本向量:[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0.][0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]]"""
(4)jieba 中的实现
import jieba.analysetext = """关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作"""keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=())# jy: ['文档', '文本', '关键词', '挖掘', '文本检索']print(keywords)
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())sentence:待提取的文本topK:返回几个 TF/IDF 权重最大的关键词,默认值为 20withWeight:是否一并返回关键词权重值,默认值为 FalseallowPOS:仅包括指定词性的词,默认值为空,即不筛选
5、TF-IDF 算法的不足、改进
(1)不足
- TF-IDF 采用文本逆频率 IDF 对 TF 值加权取权值大的作为关键词,但 IDF 的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能,所以 TF-IDF 算法的精度并不是很高,尤其是当文本集已经分类的情况下。
- 在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词十分有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。
TF-IDF 算法实现简单快速,但是仍有许多不足之处:
【2013-00-00】Improved TF-IDF Keyword Extraction Algorithm.pdf
- 注意:论文引用量不高,仅供参考

若有收获,就点个赞吧
0 人点赞
