BERT(language representation model):Bidirectional Encoder Representations from Transformers。
- BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
- The pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks(such as question answering and language inference)without substantial task-specifific architecture modififications.
- BERT alleviates the previously mentioned unidirectionality constraint by using a “masked language model” (MLM) pre-training objective.
- MLM randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context.
- The MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer.
- In addition to the masked language model, we also use a “next sentence prediction” task that jointly pretrains text-pair representations.
1、背景
Language model pre-training has been shown to be effective for improving many natural language processing tasks
- sentence-level tasks(aim to predict the relationships between sentences by analyzing them holistically)
- natural language inference
- paraphrasing
- token-level tasks(models are required to produce fifine-grained output at the token level)
- named entity recognition
- question answering
- sentence-level tasks(aim to predict the relationships between sentences by analyzing them holistically)
There are two existing strategies for applying pre-trained language representations to down-stream tasks(The two approaches share the same objective function during pre-training)
- feature-based
- ELMo
- uses task-specific architectures that include the pre-trained representations as additional features.
- ELMo
- fine-tuning(introduces minimal task-specifific parameters, and is trained on the downstream tasks by simply fine-tuning all pre-trained parameters. )
- feature-based
Differences in pre-training model architectures:
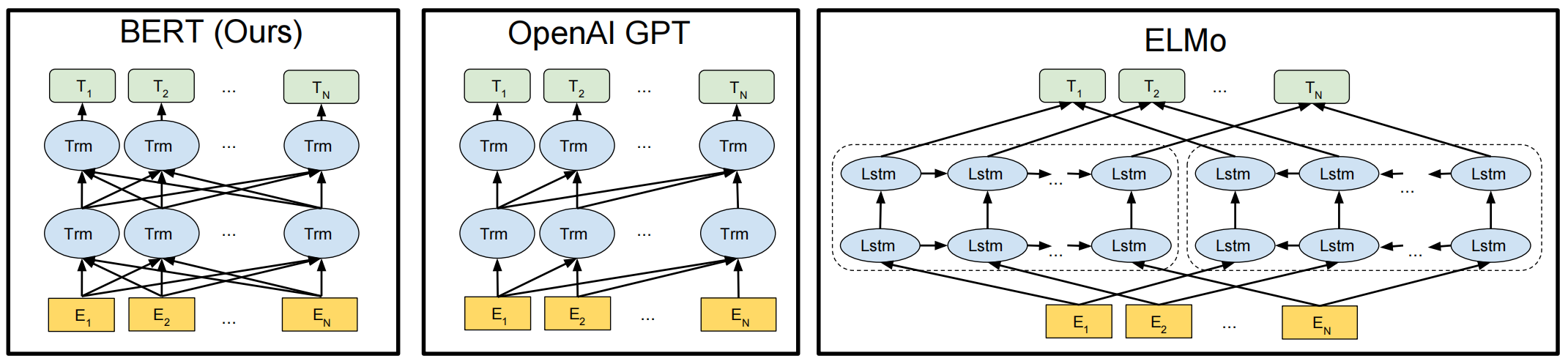
- 架构对比
- BERT:uses a bidirectional Transformer.
- only BERT representations are jointly conditioned on both left and right context in all layers.
- OpenAI GPT:uses a left-to-right Transformer.
- ELMo:uses the concatenation of independently trained left-to-right and right-to-left LSTMs to generate features for downstream tasks.
- BERT:uses a bidirectional Transformer.
- in addition to the architecture differences, BERT and OpenAI GPT are fine-tuning approaches, while ELMo is a feature-based approach.
- BERT 与 GPT
- BERT Transformer uses bidirectional self-attention, while the GPT Transformer uses constrained self-attention where every token can only attend to context to its left.
- In fact, many of the design decisions in BERT were intentionally made to make it as close to GPT as possible so that the two methods could be minimally compared. | | GPT | BERT | | —- | —- | —- | | Training data | BooksCorpus (800M words) | BooksCorpus (800M words) Wikipedia (2,500M words) | | [SEP] 和 [CLS] | only introduced at fine-tuning time | learns [SEP], [CLS] and sentence A/B embeddings during pre-training | | steps & batch size | 1M steps with a batch size of 32,000 words | 1M steps with a batch size of 128,000 words | | learning rate | 5e-5 for all fine-tuning experiments | chooses a task-specifific fine-tuning learning rate which performs the best on the development set |
2、BERT 原理、架构图
There are two steps in our framework: pre-training_ _and fifine-tuning.
- During pre-training, the model is trained on unlabeled data over different pre-training tasks.
- For fine-tuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are fifine-tuned using labeled data from the downstream tasks. Each downstream task has separate fine-tuned models(even though they are initialized with the same pre-trained parameters)
模型基础:a multi-layer bidirectional Transformer encoder
- BERT 架构图如下(Question Ansering)
E:input embeddingC:final hidden vector of the special[CLS]token[CLS]is the special symbol for classifification output[SEP]is the special symbol to separate non-consecutive token sequences
Ti:final hidden vector for the i-th input token (contextual representation of tokeni)

- For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings:
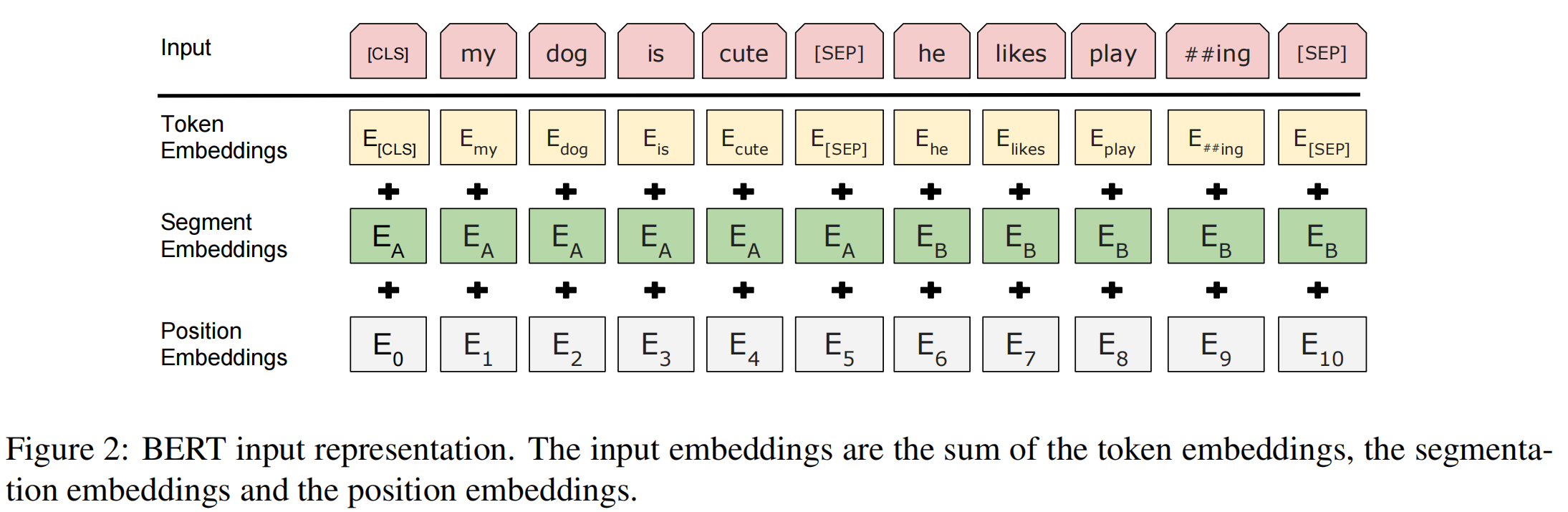
BERT_base 和 BERT_large
- BERTBASE(L=12, H=768, A=12, Total Parameters=110M;have the same model size as OpenAI GPT for comparison purposes)
- L:number of layers(Transformer blocks)
- H:hidden size
- A:number of self-attention heads
- BERTLARGE(L=24, H=1024, A=16, Total Parameters=340M)
In all cases we set the feed-forward/fifilter size to be 4H(3072 for the H = 768, 4096 for the H = 1024)
(2)Input/Output Representations
input representation can unambiguously represent both a single sentence and a pair of sentences (如
- 此次的“sentence”为:an arbitrary span of contiguous text, rather than an actual linguistic sentence.
- Sentence pairs are packed together into a single sequence. We differentiate the sentences in two ways:
- First, we separate them with a special token (
[SEP]). - Second, we add a learned embedding to every token indicating whether it belongs to sentence
Aor sentenceB.
- First, we separate them with a special token (
use WordPiece embeddings with a 30,000 token vocabulary. The first token of every sequence is always a special classifification token (
[CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification tasks.3、Pre-training BERT
we pre-train BERT using two unsupervised tasks:Masked LM 、Next Sentence Prediction (NSP)
(1)Masked LM
Intuitively, it is reasonable to believe that a deep bidirectional model is strictly more powerful than either a left-to-right model or the shallow concatenation of a left-to-right and a right-to-left model.
- In order to train a deep bidirectional representation, we simply mask some percentage of the input tokens at random, and then predict those masked tokens.
- we mask 15% of all WordPiece tokens in each sequence at random, and only predict the masked words rather than reconstructing the entire input.
- In this case, the final hidden vectors corresponding to the mask tokens are fed into an output softmax over the vocabulary, as in a standard LM.
- Although this allows us to obtain a bidirectional pre-trained model, a downside is that we are creating a mismatch between pre-training and fine-tuning, since the
[MASK]token does not appear during fine-tuning. To mitigate this, we do not always replace “masked” words with the actual[MASK]token.- The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with:
- 80% of the time:
[MASK]token - 10% of the time:a random token
- 10% of the time:the unchanged i-th token
- 80% of the time:
- Note that the purpose of the masking strategies is to reduce the mismatch between pre-training and fifine-tuning, as the
[MASK]symbol never appears during the fine-tuning stage. - Then,
Tiwill be used to predict the original token with cross entropy loss.
- The training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, we replace the i-th token with:
- Ablation over different masking strategies(task:MNLI、NER):

(2)NSP(Next Sentence Prediction)
- Many important downstream tasks(such as:Question Answering (QA) and Natural Language Inference (NLI))are based on understanding the _relationship _between two sentences, which is not directly captured by language modeling.
- In order to train a model that understands sentence relationships, we pre-train for a binarized _next sentence prediction _task that can be trivially generated from any monolingual corpus.
- Specififically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as
IsNext), and 50% of the time it is a random sentence from the corpus (labeled asNotNext). _C_(参见第 2 章的架构图)is used for next sentence prediction (NSP)
- Specififically, when choosing the sentences A and B for each pretraining example, 50% of the time B is the actual next sentence that follows A (labeled as
- The next sentence prediction task can be illustrated in the following examples:
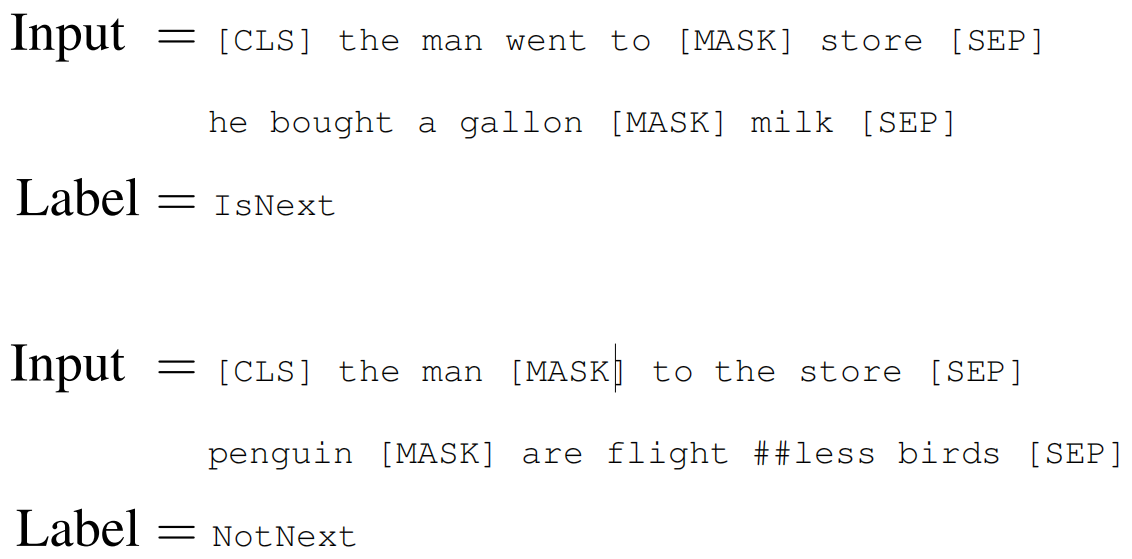
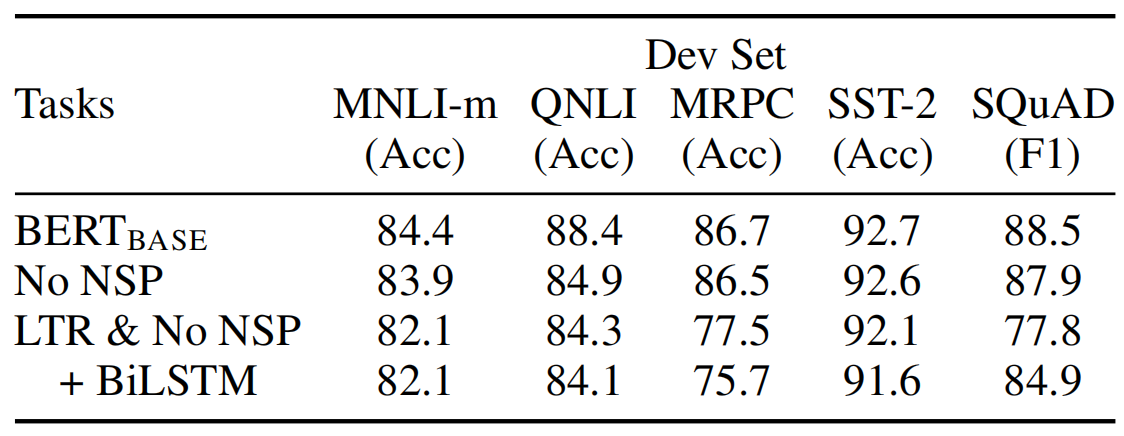
NSP 的必要性分析(Ablation analysis)
- 不同 pre-training 策略后基于 BERT_base 进行 fine-tuning 的结果(与第 4 章 fine-tuning 相关)
- No NSP:trained without the next sentence prediction task.
- LTR & No NSP:trained as a left-to-right LM without the next sentence prediction(like OpenAI GPT)
- BiLSTM: adds a randomly initialized BiLSTM on top of the “LTR + No NSP” model during fifine-tuning.
(3)pre-training:data & Procedure
(a)data
- BooksCorpus (800M words)
English Wikipedia (2,500M words)
To generate each training input sequence, we sample two spans of text from the corpus, which we refer to as “sentences” even though they are typically much longer than single sentences (but can be shorter also).
- The first sentence receives the
Aembedding and the second receives theBembedding. - 50% of the time
Bis the actual next sentence that followsAand 50% of the time it is a random sentence, which is done for the “next sentence prediction” task.
- The first sentence receives the
- They are sampled such that the combined length is _≤ _512 tokens. The LM masking is applied after WordPiece tokenization with a uniform masking rate of 15%, and no special consideration given to partial word pieces.
训练参数、目标
- 训练参数
- batch size of 256 sequences (256 sequences * 512 tokens = 128,000 tokens/batch) for 1,000,000 steps, which is approximately 40 epochs over the 3.3 billion word corpus.
- Adam with learning rate of 1e-4, β_1 = 0.9, β2 = 0.999, L2 weight decay of 0._01, learning rate warmup over the first 10,000 steps, and linear decay of the learning rate.
- dropout probability of 0.1 on all layers.
- use a
geluactivation rather than the standardrelu, following OpenAI GPT。
- 训练目标
- The training loss is the sum of the mean masked LM likelihood and the mean next sentence prediction likelihood.
- 训练环境(Each pretraining took 4 days to complete)
- BERT_base:4 Cloud TPUs in Pod confifiguration (16 TPU chips total)
- BERT_large:16 Cloud TPUs (64 TPU chips total)
- 训练技巧
- Longer sequences are disproportionately expensive because attention is quadratic to the sequence length.
- To speed up pretraing in our experiments, we pre-train the model with sequence length of 128 for 90% of the steps. Then, we train the rest 10% of the steps of sequence of 512 to learn the positional embeddings.
4、fine-tuning & task-specific details
- 训练参数
Fine-tuning is straightforward since the self-attention mechanism in the Transformer allows BERT to model many downstream tasks(whether they involve single text or text pairs)by swapping out the appropriate inputs and outputs.
- For applications involving text pairs:
- a common pattern is to independently encode text pairs before applying bidirectional cross attention.
- BERT instead uses the self-attention mechanism to unify these two stages, as encoding a concatenated text pair with self-attention effectively includes _bidirectional _cross attention between two sentences.
- For each task, we simply plug in the task-specifific inputs and outputs into BERT and fine-tune all the parameters end-to-end.
- At the input, sentence
Aand sentenceBfrom pre-training are analogous to:- 1)sentence pairs in paraphrasing
- 2)hypothesis-premise pairs in entailment
- 3)question-passage pairs in question answering
- 4)a degenerate text-∅ pair in text classifification or sequence tagging
- At the output
- the token representations are fed into an output layer for token-level tasks(such as sequence tagging or question answering)
- the
[CLS]representation is fed into an output layer for classifification(such as entailment or sentiment analysis)
- At the input, sentence
- Compared to pre-training, fine-tuning is relatively inexpensive.
- fine-tuning 小结:
- a simple classification layer is added to the pre-trained model, and all parameters are jointly fine-tuned on a down-stream task.
- Our task-specific models are formed by incorporating BERT with one additional output layer, so a minimal number of parameters need to be learned from scratch.
- 训练参数
- most model hyperparameters are the same as in pre-training, with the exception of the batch size, learning rate, and number of training epochs.
- dropout probability:was always kept at 0.1
- The optimal hyperparameter values are task-specific, but we found the following range of possible values to work well across all tasks:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 2, 3, 4
We also observed that large data sets (e.g., 100k+ labeled training examples) were far less sensitive to hyperparameter choice than small data sets.
GLUE(General Language Understanding Evaluation)benchmark:a collection of diverse natural language understanding tasks.
- GLUE datasets
- MNLI(Multi-Genre Natural Language Inference)
- a large-scale, crowdsourced entailment classifification task
- Given a pair of sentences, the goal is to predict whether the second sentence is an entailment, contradiction, or _neutral _with respect to the fifirst one.
- QQP(Quora Question Pairs)
- a binary classification task where the goal is to determine if two questions asked on Quora are semantically equivalent.
- QNLI(Question Natural Language Inference)
- a version of the Stanford Question Answering Dataset which has been converted to a binary classifification task
- The positive examples are (question, sentence) pairs which do contain the correct answer, and the negative examples are (question, sentence) from the same paragraph which do not contain the answer.
- SST-2(Stanford Sentiment Treebank)
- a binary single-sentence classifification task consisting of sentences extracted from movie reviews with human annotations of their sentiment
- CoLA(Corpus of Linguistic Acceptability)
- a binary single-sentence classifification task, where the goal is to predict whether an English sentence is linguistically “acceptable” or not.
- STS-B(Semantic Textual Similarity Benchmark)
- a collection of sentence pairs drawn from news headlines and other sources.
- They were annotated with a score from 1 to 5 denoting how similar the two sentences are in terms of semantic meaning.
- MRPC(Microsoft Research Paraphrase Corpus)
- consists of sentence pairs automatically extracted from online news sources, with human annotations for whether the sentences in the pair are semantically equivalent.
- RTE(Recognizing Textual Entailment)
- a binary entailment task similar to MNLI, but with much less training data
- WNLI(Winograd NLI)
- a small natural language inference dataset.
- The GLUE webpage notes that there are issues with the construction of this dataset, and every trained system that’s been submitted to GLUE has performed worse than the 65.1 baseline accuracy of predicting the majority class.
- MNLI(Multi-Genre Natural Language Inference)
- fine-tuning 过程
- use the final hidden vector
_C__ _corresponding to the first input token[CLS]as the aggregate representation. - The only new parameters introduced during fine-tuning are classification layer weights
 , where
, where  _is the number of labels. We compute a standard classifification loss with
_is the number of labels. We compute a standard classifification loss with  _and
_and  ,如:
,如:
- use the final hidden vector
- 训练参数
- batch size:32
- epochs:3(fine-tune over the data for all GLUE tasks)
- learning rate:5e-5, 4e-5, 3e-5, and 2e-5。
- For each task, we selected the best fine-tuning learning rate on the Dev set.
- For BERT_large:
- we found that fine-tuning was sometimes unstable on small datasets, so we ran several random restarts and selected the best model on the Dev set.
- With random restarts, we use the same pre-trained checkpoint but perform different fine-tuning data shuffling and classififier layer initialization.
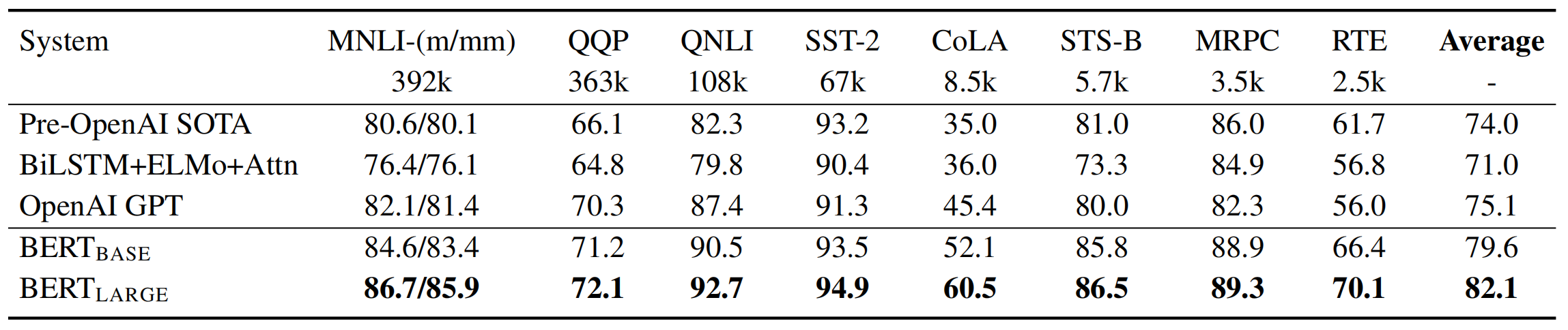
- 实验结果(GLUE Test results)
- scored by the evaluation server (https://gluebenchmark.com/leaderboard)
- The number below each task denotes the number of training examples.
- “Average” column is slightly different than the offificial GLUE score, since we exclude the problematic WNLI set.
- BERT and OpenAI GPT are single model, single task.
- F1 scores are reported for QQP and MRPC
- Spearman correlations are reported for STS-B
- Accuracy scores are reported for the other tasks.
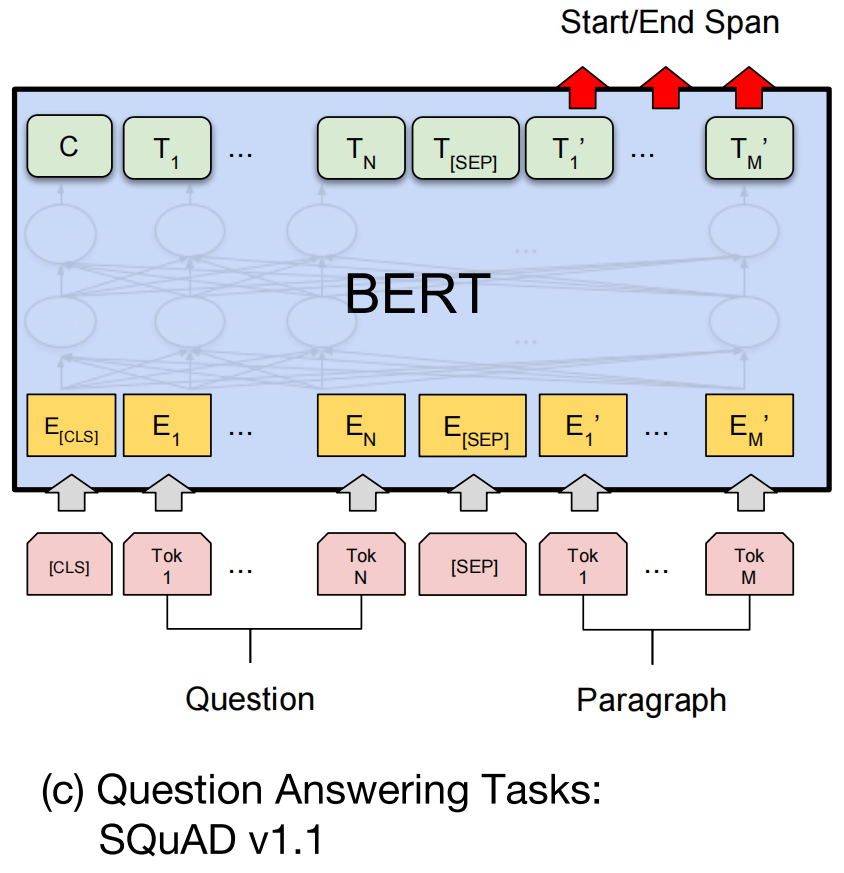
(2)SQuAD(token-level tasks)
(a)SQuAD v1.1
- SQuAD v1.1(Stanford Question Answering Dataset)
- a collection of 100k crowd-sourced question/answer pairs
- Given a question and a passage from Wikipedia containing the answer, the task is to predict the answer text span in the passage.
- For question answering task:
- represent the input question and passage as a single packed sequence, with the question using the
Aembedding and the passage using theBembedding. - only introduce a start vector
 _and an end vector
_and an end vector  _during fine-tuning.
_during fine-tuning. - The probability of word
ibeing the start of the answer span is computed as a dot product between and
and  _ _followed by a softmax over all of the words in the paragraph(the end of the answer span 同理):
_ _followed by a softmax over all of the words in the paragraph(the end of the answer span 同理): - The score of a candidate span from position
ito positionj_ _is defined as , and the maximum scoring span where
, and the maximum scoring span where  is used as a prediction.
is used as a prediction. - The training objective is the sum of the log-likelihoods of the correct start and end positions.
- represent the input question and passage as a single packed sequence, with the question using the

- 训练参数
- epochs:3
- learning rate:5e-5
- batch size:32
- 实验结果
- The top results from the SQuAD leaderboard do not have up-to-date public system descriptions available, and are allowed to use any public data when training their systems.
- We therefore use modest data augmentation in our system by first fine-tuning on TriviaQA befor fine-tuning on SQuAD.

(b)SQuAD v2.0
- The SQuAD 2.0 task extends the SQuAD 1.1 problem defifinition by allowing for the possibility that no short answer exists in the provided paragraph, making the problem more realistic.
- We use a simple approach to extend the SQuAD v1.1 BERT model for this task:
- We treat questions that do not have an answer as having an answer span with start and end at the
[CLS]token. - The probability space for the start and end answer span positions is extended to include the position of the
[CLS]token.
- We treat questions that do not have an answer as having an answer span with start and end at the
- For prediction
- we compare the score of the no-answer span:
 to the score of the best non-null span
to the score of the best non-null span
- We predict a non-null answer when
 ,where the threshold
,where the threshold is selected on the dev set to maximize F1.
is selected on the dev set to maximize F1.
- we compare the score of the no-answer span:
- We did not use TriviaQA data for this model.
- 模型参数:
- epochs:2
- learning rate:5e-5
- batch size:48
- 实验结果

(3)SWAG
- SWAG(Situations With Adversarial Generations)dataset
- contains 113k sentence-pair completion examples that evaluate grounded common-sense inference
- Given a sentence, the task is to choose the most plausible continuation among four choices.
- fine-tuning on the SWAG dataset
- construct four input sequences, each containing the concatenation of the given sentence (sentence
A) and a possible continuation (sentenceB). - The only task-specifific parameters introduced is a vector whose dot product with the
[CLS]token representation_C__ _denotes a score for each choice which is normalized with a softmax layer. - 训练参数
- epochs:3
- learning rate:2e-5
- batch size:16
- construct four input sequences, each containing the concatenation of the given sentence (sentence
- 实验结果

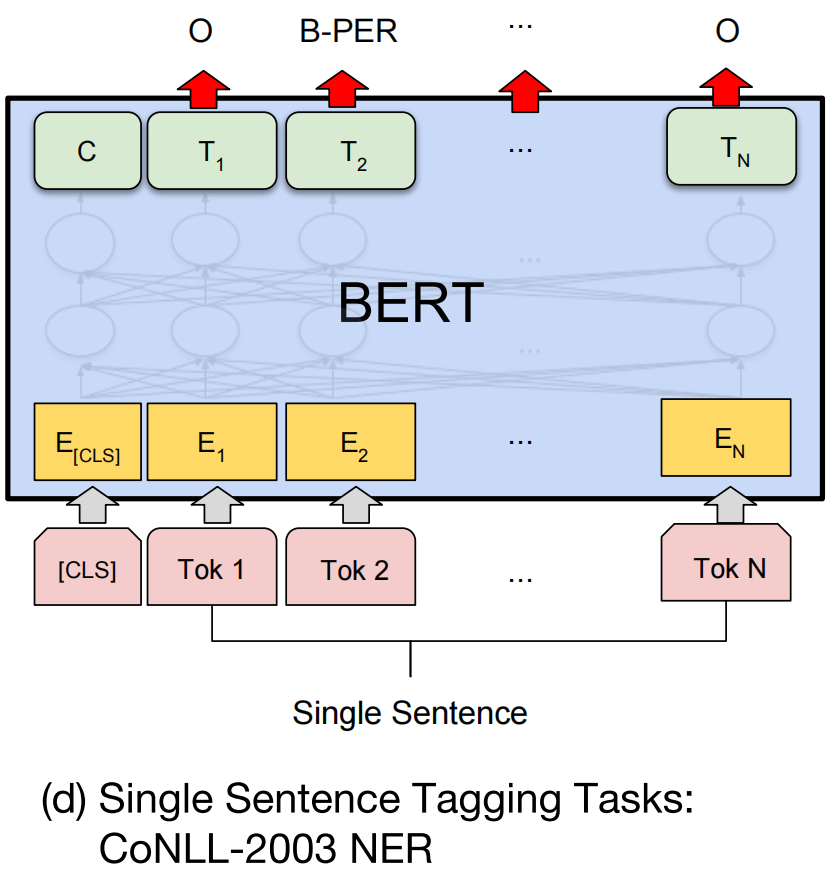
(4)NER(CoNLL-2003)(token-level tasks)
- 不同方法的实验结果
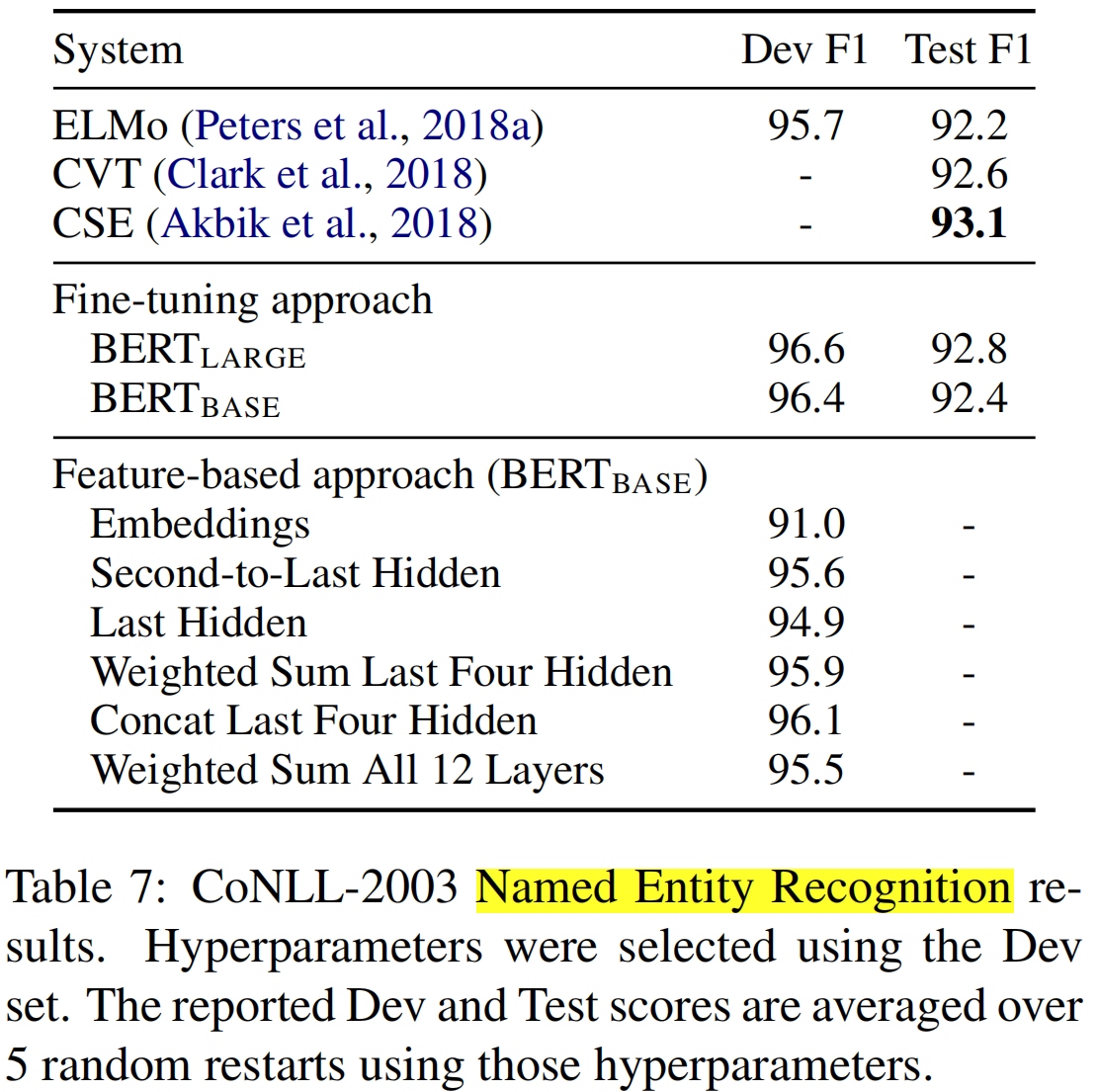
(a)fine-tuning approach
- 方式
- In the input to BERT, we use a case-preserving WordPiece model, and we include the maximal document context provided by the data.
- Following standard practice, we formulate this as a tagging task but do not use a CRF layer in the output. We use the representation of the first sub-token as the input to the token-level classifier over the NER label set.
(b)feature-based approach
- The feature-based approach, where fixed features are extracted from the pre-trained model, has certain advantages:
- not all tasks can be easily represented by a Transformer encoder architecture, and therefore require a task-specifific model architecture to be added.
- there are major computational benefits to pre-compute an expensive representation of the training data once and then run many experiments with cheaper models on top of this representation.
- 方式:
- Extracting the activations from one or more layers _without _fine-tuning any parameters of BERT.
- These contextual embeddings are used as input to a randomly initialized two-layer 768-dimensional BiLSTM before the classification layer.
6、FAQ(Ablation analysis)
- 1)Does BERT really need such a large amount of pre-training (128,000 words/batch * 1,000,000 steps) to achieve high fifine-tuning accuracy?
- Answer: Yes, BERT_base achieves almost 1.0% additional accuracy on MNLI when trained on 1M steps compared to 500k steps.
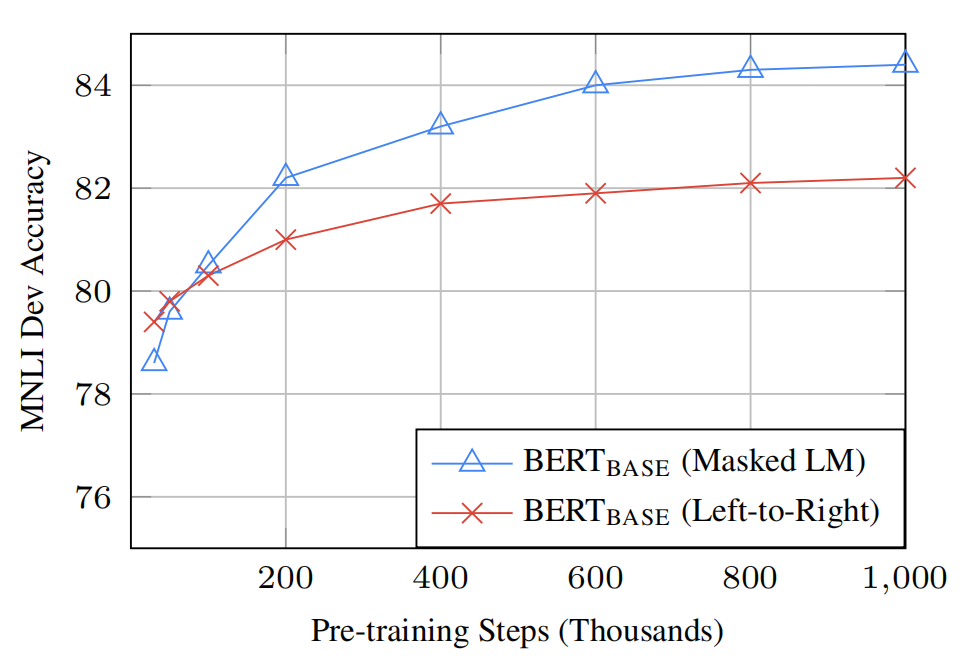
- 2)Question: Does MLM pre-training converge slower than LTR(which predicts every token)pre-training, since only 15% of words are predicted in each batch rather than every word?
- Answer: The MLM model does converge slightly slower than the LTR model. However, in terms of absolute accuracy the MLM model begins to outperform the LTR model almost immediately.

若有收获,就点个赞吧
0 人点赞
