- 1、Add domain-specific vocabulary (new tokens) to a subword tokenizer
- jy: Download a BERT model and its WordPiece tokenizer
- model_name = “bert-base-cased”
- tokenization of the text
- jy: [‘CO’, ‘##VI’, ‘##D’, ‘-‘, ‘19’, ‘affects’, ‘different’, ‘people’, ‘in’, ‘different’, ‘ways’, ‘.’, ‘Most’, ‘infected’, ‘people’, ‘will’, ‘develop’, ‘mild’, ‘to’, ‘moderate’, ‘illness’, ‘and’, ‘recover’, ‘without’, ‘hospital’, ‘##ization’, ‘.’]
- back to text
- jy: ‘COVID - 19 affects different people in different ways. Most infected people will develop mild to moderate illness and recover without hospitalization.’
- jy: We can notice that the BERT WordPiece tokenizer (from the bert-base-cased model)
- tokenize the words COVID and hospitalization with subwords because they do not
- exist as words in the tokenizer vocabulary.
- Verify that the words COVID and hospitalization DO NOT belong to the tokenizer
- vocabulary
- jy: (False, False)
- let’s choose 2 Wikipedia pages for our demonstration (we could have choosen
- an infinity)
- jy: (4707, 3651, 8358)
- jy: We found 3651 tokens (subwords or words) that are not in the vocabulary of
- the original tokenizer.
- get list of new tokens
- get list of new tokens as whole words
- jy: [ BEFORE ] tokenizer vocab size: 28996
- jy: [ AFTER ] tokenizer vocab size: 31497
- jy: added_tokens: 2501
- resize the embeddings matrix of the model
- jy: Embedding(31497, 768)
- jy: Let’s call tokenizer_exBERT our tokenizer with the new tokens.
- tokenization of the text
- jy: [‘CO’, ‘##VI’, ‘##D’, ‘-‘, ‘19’, ‘a’, ‘##f’, ‘fec’, ‘t’, ‘##s’, ‘dif’, ‘fer’, ‘en’, ‘##t’, ‘pe’, ‘o’, ‘ple’, ‘in’, ‘dif’, ‘fer’, ‘en’, ‘##t’, ‘ways’, ‘.’, ‘Mo’, ‘st’, ‘infec’, ‘te’, ‘##d’, ‘pe’, ‘o’, ‘ple’, ‘will’, ‘d’, ‘ev’, ‘e’, ‘lop’, ‘mil’, ‘d’, ‘to’, ‘mod’, ‘e’, ‘ra’, ‘te’, ‘illness’, ‘and’, ‘rec’, ‘over’, ‘without’, ‘ho’, ‘sp’, ‘i’, ‘tal’, ‘i’, ‘##zation’, ‘.’]
- back to text
- jy: ‘COVID - 19 af fec ts dif fer ent pe o ple in dif fer ent ways. Mo st infec ted pe o ple will d ev e lop mil d to mod e ra te illness and rec over without ho sp i tal ization.’
- tokenization of the words COVID and hospitalization
- jy: [‘CO’, ‘##VI’, ‘##D’]
- jy: [‘ho’, ‘sp’, ‘i’, ‘tal’, ‘i’, ‘##zation’]
- list of new tokens
- print(len(new_tokens))
- jy: (3960, 226, 4186)
- jy: We found 226 tokens (whole words) that are not in the vocabulary of the original
- tokenizer, and the words COVID and hospitalization belong to the new tokens list.
- get list of new tokens
- jy: 226 [‘0.002’, ‘0.01’, ‘0.1’, ‘0.4’, ‘0.5’, ‘0.5–1’, ‘1.4’, ‘1.7’, ‘2.2’, ‘202012/01’, ‘4.6’, ‘50,000’, ‘6,174’, ‘B.1.1.7’, ‘COVID-19’, ‘CoV-2’, ‘CoV.’, ‘P.1’, ‘U.S.’, ‘U07.1’]
- jy: (True, True)
- https://edition.cnn.com/2021/04/05/health/us-coronavirus-monday/index.html">source: https://edition.cnn.com/2021/04/05/health/us-coronavirus-monday/index.html
- jy: Now, let’s tokenize this text both with the original BERT tokenizer and its
- enriched version.
- jy: number of tokens by the original BERT tokenizer: 203
- jy: number of tokens by the enriched tokenizer: 193
- jy: 注意, 在文件中补充新词时, 使用 AutoTokenizer 类加载模型(默认 use_fast=True, 因此
- 加载得到的模型为 BertTokenizerFast), 但 BertTokenizerFast 对新增的新词不生效, 原
- 因参见第 3 和 4 章节分析;
- tokenizer = AutoTokenizer.from_pretrained(model, use_fast=True)
- jy: 如果加载的 tokenizer 模型为 BertTokenizer, 则可以读取新增的 token;
- tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False)
- 重新加载分词器
- [[‘covid’], [‘hospitalization’]]
- 3、加载 tokenizer 类的注意事项
- jy: 使用 AutoTokenizer 类的 from_pretrained 方法时, 参数 use_fast (默认为 True)
- 有实际含义: 会依据 use_fast 的结果判断返回的结果是 BertTokenizer 还是
- BertTokenizerFast
- jy: 注意: AutoTokenizer.from_pretrained() 方法更通用, 会依据传入的
- model_name_or_path 和 use_fast 参数返回相应的 tokenizer 模型(以
- 上的返回结果是假设 model_name_or_path 对应 BERT 类模型时);
- jy:
- jy:
- 4、BertTokenizer 与 BertTokenizerFast 加载 token 词表的区别
- text = “We are very happy to show you the Transformers library.”
- text = “We are very happy to show you the Transformer model.”
注意:本文是基于 transformers 模型训练 BERT,相关 tokenizer 类的加载过程均基于 transformers 包实现,因此会涉及 transformers 包中的 BERT 相关 tokenizer 的流程解析。
1、Add domain-specific vocabulary (new tokens) to a subword tokenizer
How to add a domain-specific vocabulary (new tokens) to a subword tokenizer already trained like BERT WordPiece?
- In some cases, it may be crucial to enrich the vocabulary of an already trained natural language model with vocabulary from a specialized domain (medicine, law, etc.) in order to perform new tasks (classification, NER, summary, translation, etc.).
- While the Hugging Face library allows you to easily add new tokens to the vocabulary of an existing tokenizer like BERT WordPiece, those tokens must be whole words, not subwords.
- This article explains why and how to obtain these new tokens from a specialized corpus. ```python from transformers import AutoModelForMaskedLM, AutoTokenizer
jy: Download a BERT model and its WordPiece tokenizer
model_name = “bert-base-cased”
model_name = “/path/to/bert-base-cased” tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
text = “COVID-19 affects different people in different ways. Most infected people will develop mild to moderate illness and recover without hospitalization.”
tokenization of the text
tokens = tokenizer.tokenize(text)
jy: [‘CO’, ‘##VI’, ‘##D’, ‘-‘, ‘19’, ‘affects’, ‘different’, ‘people’, ‘in’, ‘different’, ‘ways’, ‘.’, ‘Most’, ‘infected’, ‘people’, ‘will’, ‘develop’, ‘mild’, ‘to’, ‘moderate’, ‘illness’, ‘and’, ‘recover’, ‘without’, ‘hospital’, ‘##ization’, ‘.’]
print(tokens)
back to text
text_back = tokenizer.decode(tokenizer.encode(text), skip_special_tokens=True)
jy: ‘COVID - 19 affects different people in different ways. Most infected people will develop mild to moderate illness and recover without hospitalization.’
print(text_back)
jy: We can notice that the BERT WordPiece tokenizer (from the bert-base-cased model)
tokenize the words COVID and hospitalization with subwords because they do not
exist as words in the tokenizer vocabulary.
print(tokenizer.tokenize(‘COVID’)) # jy: [‘CO’, ‘##VI’, ‘##D’] print(tokenizer.tokenize(‘hospitalization’)) # jy: [‘hospital’, ‘##ization’]
Verify that the words COVID and hospitalization DO NOT belong to the tokenizer
vocabulary
vocab = [tok for tok,index in tokenizer.get_vocab().items()]
jy: (False, False)
print(“COVID” in vocab, “hospitalization” in vocab)
<a name="MhgaW"></a>## 1)Add 2 new tokens (whole words) into the tokenizer vocab```pythonfrom transformers import AutoModelForMaskedLM, AutoTokenizer# jy: Download a BERT model and its WordPiece tokenizer#model_name = "bert-base-cased"model_name = "/path/to/bert-base-cased"tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)model = AutoModelForMaskedLM.from_pretrained(model_name)new_tokens = ['COVID', 'hospitalization']# jy: [ BEFORE ] tokenizer vocab size: 28996print("[ BEFORE ] tokenizer vocab size:", len(tokenizer))added_tokens = tokenizer.add_tokens(new_tokens)# jy: [ AFTER ] tokenizer vocab size: 28998print("[ AFTER ] tokenizer vocab size:", len(tokenizer))# jy: added_tokens: 2print('added_tokens:', added_tokens)# resize the embeddings matrix of the modelresize_embedding = model.resize_token_embeddings(len(tokenizer))# jy: Embedding(28998, 768)print(resize_embedding)# Verify that the words COVID and hospitalization DO belong to the tokenizer vocabularyvocab = [tok for tok, index in tokenizer.get_vocab().items()]# jy: (True, True)print("COVID" in vocab, "hospitalization" in vocab)# jy: Let's call tokenizer_exBERT our tokenizer with the 2 new tokens.tokenizer_exBERT = tokenizer# tokenization of the texttokens = tokenizer_exBERT.tokenize(text)# jy: ['COVID', '-', '19', 'affects', 'different', 'people', 'in', 'different', 'ways', '.', 'Most', 'infected', 'people', 'will', 'develop', 'mild', 'to', 'moderate', 'illness', 'and', 'recover', 'without', 'hospitalization', '.']print(tokens)# back to texttext_back = tokenizer_exBERT.decode(tokenizer_exBERT.encode(text),skip_special_tokens=True)# jy: 'COVID - 19 affects different people in different ways. Most infected people will develop mild to moderate illness and recover without hospitalization.'print(text_back)# jy: The tokenizer with the 2 new tokens succeeded in tokenizing the words COVID and# hospitalization without subwords as they belong now to the vocabulary tokenizer.# tokenization of the words COVID and hospitalizationprint(tokenizer_exBERT.tokenize('COVID')) # jy: ['COVID']print(tokenizer_exBERT.tokenize('hospitalization')) # jy: ['hospitalization']
2)Add more new tokens (subwords and words) into the tokenizer vocab
- What if we want to detect the whole vocabulary of a specialized corpus (and not only 2 words) in order to add it to an existing corpus?
Let’s use a WordpIece tokenizer for this! (Why a WordPiece tokenizer? This is our first guess: since the BERT tokenizer is a WordPiece tokenizer, let’s use a tokenizer of the same type)
(1)Import pages about COVID from English Wikipedia
需安装
wikipedia包【undo-链接报错】pip install wikipedia```python import wikipedia
let’s choose 2 Wikipedia pages for our demonstration (we could have choosen
an infinity)
pages = [“COVID-19”, “COVID-19 pandemic”]
documents = list() for p in pages: page = wikipedia.page(p) documents.append(page.content) print(page.title, page.url) “”” COVID-19 https://en.wikipedia.org/wiki/COVID-19 COVID-19 pandemic https://en.wikipedia.org/wiki/COVID-19_pandemic “””
<a name="Qftri"></a>### (2)Train a WordPiece tokenizer on the imported Wikipedia pages- 参考:All together: a BERT tokenizer from scratch- [https://huggingface.co/docs/tokenizers/pipeline#all-together-a-bert-tokenizer-from-scratch](https://huggingface.co/docs/tokenizers/pipeline#all-together-a-bert-tokenizer-from-scratch)```python# tokenzer WordPiecefrom tokenizers import Tokenizerfrom tokenizers.models import WordPiecebert_tokenizer = Tokenizer(WordPiece(unk_token="[UNK]"))# normalizerfrom tokenizers import normalizersfrom tokenizers.normalizers import Lowercase, NFD, StripAccentsbert_tokenizer.normalizer = normalizers.Sequence([NFD()])# pre-tokenizerfrom tokenizers.pre_tokenizers import Whitespacebert_tokenizer.pre_tokenizer = Whitespace()# templatefrom tokenizers.processors import TemplateProcessingbert_tokenizer.post_processor = TemplateProcessing(single="[CLS] $A [SEP]",pair="[CLS] $A [SEP] $B:1 [SEP]:1",special_tokens=[("[CLS]", 1),("[SEP]", 2),],)# instantiate a trainerfrom tokenizers.trainers import WordPieceTrainertrainer = WordPieceTrainer(vocab_size=30522,special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])# Train【undo】files = documentsbert_tokenizer.train_from_iterator(files, trainer)
(3)Get the vocabulary that is not in the original BERT tokenizer
- This step is not necessary, as the
tokenizer.add_tokens()method will add new tokens only if they do not belong to the existing tokenizer vocabulary. However, it helps us to see what these new tokens are. ```python old_vocab = [k for k,v in tokenizer.get_vocab().items()] new_vocab = [k for k,v in bert_tokenizer.get_vocab().items()] idx_old_vocab_list = list() same_tokens_list = list() different_tokens_list = list()
for idx_new,w in enumerate(new_vocab): try: idx_old = old_vocab.index(w) except: idx_old = -1 if idx_old >= 0: idx_old_vocab_list.append(idx_old) same_tokens_list.append((w,idx_new)) else: different_tokens_list.append((w,idx_new))
jy: (4707, 3651, 8358)
print(len(same_tokens_list), len(different_tokens_list), len(same_tokens_list) + len(different_tokens_list))
jy: We found 3651 tokens (subwords or words) that are not in the vocabulary of
the original tokenizer.
get list of new tokens
new_tokens = [k for k, v in different_tokens_list] print(len(new_tokens), new_tokens[:10]) “”” (3651, [‘infusion’, ‘hotsp’, ‘pathogenic’, ‘Pf’, ‘exudation’, ‘##rolling’, ‘634’, ‘##ipp’, ‘##ffici’, ‘tripling’]) “””
<a name="RMfQk"></a>### (4)Add the new tokens (subwords and words) in the vocabulary of the original BERT tokenizer```pythonfrom transformers import AutoModelForMaskedLM, AutoTokenizermodel_name = "bert-base-cased"tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)model = AutoModelForMaskedLM.from_pretrained(model_name)# jy: [ BEFORE ] tokenizer vocab size: 28996print("[ BEFORE ] tokenizer vocab size:", len(tokenizer))added_tokens = tokenizer.add_tokens(new_tokens)# jy: [ AFTER ] tokenizer vocab size: 32647print("[ AFTER ] tokenizer vocab size:", len(tokenizer))# jy: added_tokens: 3651print('added_tokens:',added_tokens)# resize the embeddings matrix of the modelresized_embedding = model.resize_token_embeddings(len(tokenizer))# Embedding(32647, 768)print(resized_embedding)# Verify if the words COVID and hospitalization belong or not to the tokenizer# vocabularyvocab = [tok for tok, index in tokenizer.get_vocab().items()]# jy: (False, False)print("COVID" in vocab, "hospitalization" in vocab)# jy: Let's call tokenizer_exBERT our tokenizer with the new tokens.tokenizer_exBERT = tokenizer# tokenization of the texttokens = tokenizer_exBERT.tokenize(text)# jy: ['CO', '##VI', '##D', '-', '19', 'a', '##f', 'fec', 't', '##s', 'dif', 'fer', 'en', '##t', 'pe', 'o', 'ple', 'in', 'dif', 'fer', 'en', '##t', 'ways', '.', 'Mo', 'st', 'infec', 'te', '##d', 'pe', 'o', 'ple', 'will', 'd', 'ev', 'e', 'lop', 'mil', 'd', 'to', 'mod', 'e', 'ra', 'te', 'illness', 'and', 'rec', 'over', 'without', 'ho', 'sp', 'i', 'tal', 'i', '##zation', '.']print(tokens)# back to textback_text = tokenizer_exBERT.decode(tokenizer_exBERT.encode(text),skip_special_tokens=True)# jy: 'COVID - 19 af fec ts dif fer ent pe o ple in dif fer ent ways. Mo st infec ted pe o ple will d ev e lop mil d to mod e ra te illness and rec over without ho sp i tal ization.'print(back_text)# jy: As the words COVID and hospitalization do not belong to the tokenizer vocabulary,# they continue to be tokenized with subwords. That's right.# However, only the word COVID is well tokenized: the word hospitalization is# tokenized with subwords that do not start with ##. But except the first token,# all other subword tokens should have started with ##!# And we can see that many other words in the sentence are not well tokenized, too.# tokenization of the words COVID and hospitalization# jy: ['CO', '##VI', '##D']print(tokenizer_exBERT.tokenize('COVID'))# jy: ['ho', 'sp', 'i', 'tal', 'i', '##zation']print(tokenizer_exBERT.tokenize('hospitalization'))
(5)Add only the new tokens that do not start with ## in the vocabulary of the original BERT tokenizer
- We know that a subword is not just a token that starts with ##, but let’s see what happens if we remove all those subwords from the list of new tokens.
```python
get list of new tokens as whole words
new_tokens = [tok for tok in new_tokens if tok.startswith(“#”) == False] print(len(new_tokens), new_tokens[:10]) “”” (2501, [‘infusion’, ‘hotsp’, ‘pathogenic’, ‘Pf’, ‘exudation’, ‘634’, ‘tripling’, ‘produc’, ‘undernourishment’, ‘isolate’]) “””
from transformers import AutoModelForMaskedLM, AutoTokenizer
model_name = “bert-base-cased” tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True) model = AutoModelForMaskedLM.from_pretrained(model_name)
jy: [ BEFORE ] tokenizer vocab size: 28996
print(“[ BEFORE ] tokenizer vocab size:”, len(tokenizer)) added_tokens = tokenizer.add_tokens(new_tokens)
jy: [ AFTER ] tokenizer vocab size: 31497
print(“[ AFTER ] tokenizer vocab size:”, len(tokenizer))
jy: added_tokens: 2501
print(‘added_tokens:’,added_tokens)
resize the embeddings matrix of the model
resize_embedding = model.resize_token_embeddings(len(tokenizer))
jy: Embedding(31497, 768)
print(resize_embedding)
jy: Let’s call tokenizer_exBERT our tokenizer with the new tokens.
tokenizer_exBERT = tokenizer
tokenization of the text
tokens = tokenizer_exBERT.tokenize(text)
jy: [‘CO’, ‘##VI’, ‘##D’, ‘-‘, ‘19’, ‘a’, ‘##f’, ‘fec’, ‘t’, ‘##s’, ‘dif’, ‘fer’, ‘en’, ‘##t’, ‘pe’, ‘o’, ‘ple’, ‘in’, ‘dif’, ‘fer’, ‘en’, ‘##t’, ‘ways’, ‘.’, ‘Mo’, ‘st’, ‘infec’, ‘te’, ‘##d’, ‘pe’, ‘o’, ‘ple’, ‘will’, ‘d’, ‘ev’, ‘e’, ‘lop’, ‘mil’, ‘d’, ‘to’, ‘mod’, ‘e’, ‘ra’, ‘te’, ‘illness’, ‘and’, ‘rec’, ‘over’, ‘without’, ‘ho’, ‘sp’, ‘i’, ‘tal’, ‘i’, ‘##zation’, ‘.’]
print(tokens)
back to text
back_text = tokenizer_exBERT.decode(tokenizer_exBERT.encode(text), skip_special_tokens=True)
jy: ‘COVID - 19 af fec ts dif fer ent pe o ple in dif fer ent ways. Mo st infec ted pe o ple will d ev e lop mil d to mod e ra te illness and rec over without ho sp i tal ization.’
print(back_text)
tokenization of the words COVID and hospitalization
jy: [‘CO’, ‘##VI’, ‘##D’]
print(tokenizer_exBERT.tokenize(‘COVID’))
jy: [‘ho’, ‘sp’, ‘i’, ‘tal’, ‘i’, ‘##zation’]
print(tokenizer_exBERT.tokenize(‘hospitalization’))
<a name="EYpqR"></a>
## 3)Add new tokens (only words, not subwords) into the tokenizer vocab
- Let's add only the new tokens that are words, not subwords (that do not start with `##` or do not are followed by a subword with `##`) in the vocabulary of the original BERT tokenizer.
<a name="vQ0DN"></a>
### (1)Let's use a word tokenizer (spaCY) to find the most frequent words of our corpus by using scikit-learn
- **Yes but how?** Let's use a **words tokenizer like spaCY** to find the most frequent words of our corpus instead of a WordPiece tokenizer which generates subwords as well.
- **Observation**: here, the expression "most frequent words" means: the tokens present in most of the documents.
```python
import spacy
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
import matplotlib.pyplot as plt
# initialize our tokenizer with the English spaCY one
nlp = spacy.load("en_core_web_sm",
exclude=['morphologizer', 'parser', 'ner', 'attribute_ruler',
'lemmatizer'])
def spacy_tokenizer(document, nlp=nlp):
# tokenize the document with spaCY
doc = nlp(document)
# Remove stop words and punctuation symbols
tokens = [
token.text for token in doc if (
token.is_stop == False and \
token.is_punct == False and \
token.text.strip() != '' and \
token.text.find("\n") == -1)]
return tokens
def dfreq(idf, N):
return (1+N) / np.exp(idf - 1) - 1
%%time
# https://scikit-learn.org/stable/modules/feature_extraction.html#tfidf-term-weighting
tfidf_vectorizer = TfidfVectorizer(lowercase=False, tokenizer=spacy_tokenizer,
norm='l2', use_idf=True, smooth_idf=True,
sublinear_tf=False)
# parse matrix of tfidf
docs = documents
length = len(docs)
result = tfidf_vectorizer.fit_transform(docs)
# print(result.shape)
# idf
idf = tfidf_vectorizer.idf_
# sorted idf, tokens and docs frequencies
idf_sorted_indexes = sorted(range(len(idf)), key=lambda k: idf[k])
idf_sorted = idf[idf_sorted_indexes]
tokens_by_df = np.array(tfidf_vectorizer.get_feature_names())[idf_sorted_indexes]
dfreqs_sorted = dfreq(idf_sorted, length).astype(np.int32)
tokens_dfreqs = {tok:dfreq for tok, dfreq in zip(tokens_by_df,dfreqs_sorted)}
tokens_pct_list = [int(round(dfreq/length*100,2)) for token,dfreq in tokens_dfreqs.items()]
"""
CPU times: user 1.22 s, sys: 16.3 ms, total: 1.23 s
Wall time: 1.25 s
"""
# we have only 2 documents (that's why we range the intervale [1,101] with a step of 50)
number_tokens_with_DF_above_pct = list()
for pct in range(1,101,50):
index_max = len(np.array(tokens_pct_list)[np.array(tokens_pct_list)>=pct])
number_tokens_with_DF_above_pct.append(index_max)
# DF = Document Frequency
# df_docfreqs = pd.DataFrame(number_tokens_with_DF_above_pct,
# columns=['number of tokens with DF above x%'])
# df_docfreqs.index += 1
# df_docfreqs.transpose()
# plt.plot(number_tokens_with_DF_above_pct)
# plt.title(f'Document Frequency above of {pct}%')
# plt.show()
df_docfreqs = pd.DataFrame({'pct': list(range(1, 101, 50)),
'number of tokens with DF above pct%':
number_tokens_with_DF_above_pct})
df_docfreqs.transpose()
"""
0 1
pct 1 51
number of tokens with DF above pct% 4186 1058
"""
"""
There are 4186 words which appear in one or two documents from our 2 documents list, and 1058 which are in the 2 documents.
Let's consider that the 4186 words are all important and relevant to our COVID corpus.
Observation: within a corpus with more documents, we could have used another rule as for example: keeping only words which are at least in 10% of the documents list.
"""
(2)Get the vocabulary that is not in the original BERT tokenizer
- This step is not necessary, as the
tokenizer.add_tokens()method will add new tokens only if they do not belong to the existing tokenizer vocabulary. However, it helps us to see what these new tokens are. ```pythonlist of new tokens
pct = 1 index_max = len(np.array(tokens_pct_list)[np.array(tokens_pct_list) >= pct]) new_tokens = tokens_by_df[:index_max]print(len(new_tokens))
old_vocab = [k for k, v in tokenizer.get_vocab().items()] new_vocab = [token for token in new_tokens] idx_old_vocab_list = list() same_tokens_list = list() different_tokens_list = list()
for idx_new, w in enumerate(new_vocab): try: idx_old = old_vocab.index(w) except: idx_old = -1 if idx_old >= 0: idx_old_vocab_list.append(idx_old) same_tokens_list.append((w, idx_new)) else: different_tokens_list.append((w, idx_new))
jy: (3960, 226, 4186)
print(len(same_tokens_list), len(different_tokens_list), len(same_tokens_list) + len(different_tokens_list))
jy: We found 226 tokens (whole words) that are not in the vocabulary of the original
tokenizer, and the words COVID and hospitalization belong to the new tokens list.
get list of new tokens
new_tokens = [k for k, v in different_tokens_list]
jy: 226 [‘0.002’, ‘0.01’, ‘0.1’, ‘0.4’, ‘0.5’, ‘0.5–1’, ‘1.4’, ‘1.7’, ‘2.2’, ‘202012/01’, ‘4.6’, ‘50,000’, ‘6,174’, ‘B.1.1.7’, ‘COVID-19’, ‘CoV-2’, ‘CoV.’, ‘P.1’, ‘U.S.’, ‘U07.1’]
print(len(new_tokens), new_tokens[:20])
jy: (True, True)
print(“COVID” in new_tokens, “hospitalization” in new_tokens)
<a name="PWf4i"></a>
### (3)Add the new tokens (only whole words, not subwords!) in the vocabulary of the original BERT tokenizer
```python
# import model and tokenizer
from transformers import AutoModelForMaskedLM, AutoTokenizer
model_name = "bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
model = AutoModelForMaskedLM.from_pretrained(model_name)
# jy: [ BEFORE ] tokenizer vocab size: 28996
print("[ BEFORE ] tokenizer vocab size:", len(tokenizer))
added_tokens = tokenizer.add_tokens(new_tokens)
# jy: [ AFTER ] tokenizer vocab size: 29222
print("[ AFTER ] tokenizer vocab size:", len(tokenizer))
# jy: added_tokens: 226
print('added_tokens:',added_tokens)
# resize the embeddings matrix of the model
resize_embedding = model.resize_token_embeddings(len(tokenizer))
# jy: Embedding(29222, 768)
print(resize_embedding)
# jy: Let's call tokenizer_exBERT our tokenizer with the new tokens.
tokenizer_exBERT = tokenizer
# tokenization of the text
tokens = tokenizer_exBERT.tokenize(text)
# jy: ['COVID-19', 'affects', 'different', 'people', 'in', 'different', 'ways', '.', 'Most', 'infected', 'people', 'will', 'develop', 'mild', 'to', 'moderate', 'illness', 'and', 'recover', 'without', 'hospitalization', '.']
print(tokens)
# back to text
back_text = tokenizer_exBERT.decode(tokenizer_exBERT.encode(text),
skip_special_tokens=True)
# jy: 'COVID-19 affects different people in different ways. Most infected people will develop mild to moderate illness and recover without hospitalization.'
print(back_text)
"""
The tokenizer with the new tokens (only whole words!) did succeed in tokenizing the words COVID and hospitalization correctly (and not only these ones: all of them!)
It means that is fundamental to add new tokens that are only whole words to an existing subword tokenizer like WordPiece, and not subwords!
"""
# tokenization of the words COVID and hospitalization
print(tokenizer_exBERT.tokenize('COVID')) # jy: ['COVID']
print(tokenizer_exBERT.tokenize('hospitalization')) # jy: ['hospitalization']
4)Let’s check the impact of our enriched tokenizer
- Let’s use a text about COVID taken from a newspaper site (not from Wikipedia).
```python
source: https://edition.cnn.com/2021/04/05/health/us-coronavirus-monday/index.html
text = ‘Experts say Covid-19 vaccinations in the US are going extremely well — but not enough people are protected yet and the country may be at the start of another surge. \ The US reported a record over the weekend with more than 4 million Covid-19 vaccine doses administered in 24 hours, according to the Centers for Disease Control and Prevention. \ And the country now averages more than 3 million doses daily, according to CDC data. \ But only about 18.5% of Americans are fully vaccinated, CDC data shows, and Covid-19 cases in the country have recently seen concerning increases. \ “I do think we still have a few more rough weeks ahead,” Dr. Celine Gounder, an infectious diseases specialist and epidemiologist, told CNN on Sunday. \ “What we know from the past year of the pandemic is that we tend to trend about three to four weeks behind Europe in terms of our pandemic patterns.”‘
jy: Now, let’s tokenize this text both with the original BERT tokenizer and its
enriched version.
from transformers import AutoModelForMaskedLM, AutoTokenizer model_name = “bert-base-cased”
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True) model = AutoModelForMaskedLM.from_pretrained(model_name)
tokens = tokenizer.tokenize(text)
jy: number of tokens by the original BERT tokenizer: 203
print(‘number of tokens by the original BERT tokenizer:’, len(tokens))
tokens = tokenizer_exBERT.tokenize(text)
jy: number of tokens by the enriched tokenizer: 193
print(‘number of tokens by the enriched tokenizer:’, len(tokens))
- As expected, we find that the enriched tokenizer needs less tokens (here, 5%) to tokenize the text on COVID than the original BERT tokenizer.
<a name="Q6weA"></a>
## 5)To be continued
- Now that we have augmented our tokenizer vocabulary with words specific to our corpus, we need to fine-tune the natural language model it is associated with (here, the bert-base-cased model). Indeed, the addition of new words led to the increase of the matrix of embeddings of the model by the same number: **with each new word added, a new vector of embeddings with random values was added as well** thanks to the `model.resize_token_embeddings(len(tokenizer))` method. So we need to train (or fine-tune) our model on our body so that the model can learn the embeddings of these new words.
- Hugging Face provided a script and a notebook to fine tune a natural language model on a new corpus:
- _How to fine-tune a model on language modeling_: [script](https://github.com/huggingface/transformers/tree/master/examples/language-modeling) | [github](https://github.com/huggingface/notebooks/blob/master/examples/language_modeling.ipynb) | [colab](https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/language_modeling.ipynb)
- **We therefore have a ready-to-use code. However, it is possible that this code is not adapted to your situation** because if the number of new words (and therefore of new embeddings vectors) is high, it is possible that the training by this code leads to a Catastrophic Forgetting by modifying in a sensitive way the vectors of embeddings of the tokens of the initial vocabulary.
- **My advice**: do a Google search with this type of "_fine-tune a pre-trained model for a specific domain_" query. You will get all the interesting articles and documents on this topic. Good job to you!
<a name="mG7Bh"></a>
# 2、在 BERT 的 tokenizer 模型中添加新 token
- bert-base-chinese 是以字为单位的,基本上已经涵盖了现代汉语所有的常用字。而且汉字是一个比较稳定的封闭集合,生活中不会随时造出新字来。新词倒是很常见,但是在中文 BERT 里直接就被 tokenizer 切成字了,因此一般没有多大的扩充词(字)表的需要。
- 笔者在古汉语语料上调用古汉语 BERT 确实遇到很多生僻字被分词器当成`[UNK]`的情况,还没有尝试增加新字,不过理论上是一样的。
- 但是英文不一样,英文预训练 BERT(bert-base-uncased 和 bert-base-cased)以词为单位。社会生活中总是会有新词产生,而且在专业领域(如医疗、金融)有一些不常用的词语是英文预训练 BERT 没有涵盖到的。这就需要扩充词表。
- 此外,在英文模型中,添加自定义词的作用不仅是增加新词或者专业领域的词汇,而且可以防止词语被自动拆成词根词缀。
- 如果不添加自定义词汇,“COVID”和“hospitalization”虽然不会被分词器直接当成`[UNK]`,但是会被bert-base-cased 的分词器拆分成: `['co', '##vid']`、`['hospital', '##ization']`
<a name="KNwER"></a>
## (1)方式1:在 BERT 词表 vocab.txt 中替换 [unused]
- 注意:在文件中补充新词时,使用 AutoTokenizer 类加载模型(默认`use_fast=True`,加载得到 `BertTokenizerFast`) , 但`BertTokenizerFast`对于在词表文件中新增的新词可能不生效(修改use_fast=False,即加载`BertTokenizer`即可生效),原因参见第 3 和 4 章节分析(`tokenizer.json`存在、且没做同步修改造成的影响;故采用该方法时,建议删除`tokenizer.json`文件,或对其进行同步修改)。
- 找到 pytorch 版本的 bert-base-cased 的文件夹中的`vocab.txt`文件。最前面的 100 行都是`[unused]`(`[PAD]`除外),直接用需要添加的词替换进去。
- 比如需要添加一个原来词表里没有的词“anewword”(现造的),这时候就把`[unused1]`改成我们的新词“anewword”
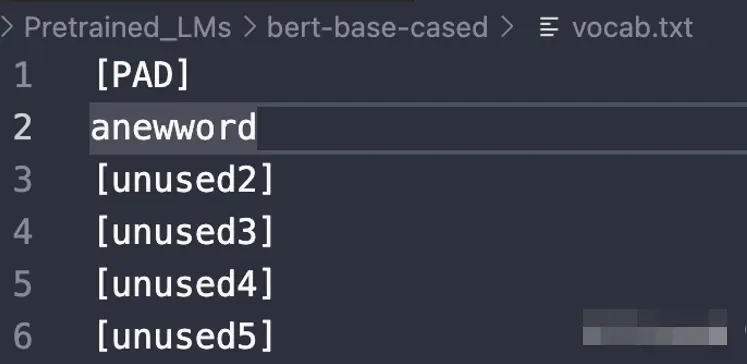
- 在未添加新词前,在 python 里面调用 BERT 模型的分词器
```python
from transformers import BertForMaskedLM, BertTokenizer
from transformers import AutoTokenizer
# 自己的 bert 模型路径
model = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-cased"
tokenizer = BertTokenizer.from_pretrained(model, use_fast=True)
#tokenizer = AutoTokenizer.from_pretrained(model, use_fast=True)
model = BertForMaskedLM.from_pretrained(model)
print(tokenizer.tokenize('anewword')) # jy: ['an', '##ew', '##word']
- 当在 vocab 中把
[unused1]改成anewword后: ```python from transformers import BertForMaskedLM, BertTokenizer from transformers import AutoTokenizer
model = “/home/huangjiayue/04_SimCSE/jy_model/bert-base-cased” tokenizer = BertTokenizer.from_pretrained(model, use_fast=True)
jy: 注意, 在文件中补充新词时, 使用 AutoTokenizer 类加载模型(默认 use_fast=True, 因此
加载得到的模型为 BertTokenizerFast), 但 BertTokenizerFast 对新增的新词不生效, 原
因参见第 3 和 4 章节分析;
tokenizer = AutoTokenizer.from_pretrained(model, use_fast=True)
jy: 如果加载的 tokenizer 模型为 BertTokenizer, 则可以读取新增的 token;
tokenizer = AutoTokenizer.from_pretrained(model, use_fast=False)
model = BertForMaskedLM.from_pretrained(model)
重新加载分词器
print(tokenizer.tokenize(‘anewword’)) # jy: [‘anewword’]
<a name="yRLW3"></a>
## (2)方法2:通过重构词汇矩阵来增加新词
- 注意:基于该方法(即`tokenizer.add_tokens(ls_new_token)` 随后`tokenizer.save_pretrained("/path/to/model/")`)添加的新 token 不能与方法 1 中直接在`vocab.txt`词表文件里添加的有重复,否则后续使用过程中碰到该相应 token 的 tokenize 时会有报错。
- 该方法对于 BertTokenizer、BertTokenizerFast、AutoTokenizer 类加载具体 tokenizer 类均有效。
```python
from transformers import BertForMaskedLM, BertTokenizer
def add_ls_new_token(model_name_or_path, ls_new_token):
# jy: use_fast 参数实际上不起作用, 其值为 True 或 False 均不影响; 该参数只会在
# AutoTokenizer.from_pretrained() 中才会起作用, 参见第 3 章节解析;
#tokenizer = BertTokenizer.from_pretrained(model, use_fast=True)
tokenizer = BertTokenizer.from_pretrained(model_name_or_path)
model = BertForMaskedLM.from_pretrained(model_name_or_path)
print("未加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[0],
tokenizer.tokenize(ls_new_token[0]))
print("未加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[1],
tokenizer.tokenize(ls_new_token[1]))
# jy: 如果想让这些词保持完整的形式,可以通过重构 BERT 初始权重矩阵的方式将他们加入词表
num_added_toks = tokenizer.add_tokens(ls_new_token)
# jy: 返回的 num_added_toks 表示加入的新词数量, 即 ls_new_token 的个数;
print("加入的新词数量: %d" % num_added_toks)
# 关键步骤, resize_token_embeddings 输入的参数是 tokenizer 的新长度; 添加后的词汇,
# 通过 model.resize_token_embeddings 方法, 随机初始化了一个权重;
model.resize_token_embeddings(len(tokenizer))
print("加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[0],
tokenizer.tokenize(ls_new_token[0]))
print("加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[1],
tokenizer.tokenize(ls_new_token[1]))
# 保存到原来的模型文件夹下, 这时文件夹下多了三个文件:
"""
added_tokens.json
special_tokens_map.json
tokenizer_config.json
"""
tokenizer.save_pretrained(model_name_or_path)
model_name_or_path = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased"
ls_new_token = ['hospitalization', 'COVID']
add_ls_new_token(model_name_or_path, ls_new_token)
"""
未加入 hospitalization 时, 对其进行 tokenize 的结果: ['hospital', '##ization']
未加入 COVID 时, 对其进行 tokenize 的结果: ['co', '##vid']
加入的新词数量: 2
加入 hospitalization 时, 对其进行 tokenize 的结果: ['hospitalization']
加入 COVID 时, 对其进行 tokenize 的结果: ['covid']
"""
- 使用
tokenizer.save_pretrained保存添加后的词汇。再次加载模型就会自动读取增加后的词汇。新建一个 python 文件查看添加词汇后的结果: ```python from transformers import BertForMaskedLM, BertTokenizer
def tokenize_test(model_name_or_path, ls_word, use_fast=True):
# jy: use_fast 参数实际上不起作用, 其值为 True 或 False 均不影响; 该参数只会在
# AutoTokenizer.from_pretrained() 中才会起作用, 参见第 3 章节解析;
#tokenizer = BertTokenizer.from_pretrained(model_name_or_path, use_fast=use_fast)
tokenizer = BertTokenizer.from_pretrained(model_name_or_path)
ls_res = []
for word in ls_word:
ls_res.append(tokenizer.tokenize(word))
return ls_res
model_path = “/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased” ls_word = [‘COVID’, ‘hospitalization’]
[[‘covid’], [‘hospitalization’]]
print(tokenize_test(model_path, ls_word))
<a name="N8utO"></a>
## (3)总结(含实例代码)
- 两种不同的方法都起到了同样的效果。 在具体使用时,如果有大量领域内专业词汇,而且已经整理成词表,建议用方法 1 直接批量替换。但方法 1 的缺点是有个数限制,cased 模型只有 99 个空位,uncased 模型有 999 个空位,因此可以在填充满空位之后再基于方法 2 进行扩充(优先考虑方法 1,如果仍有多余 token,再使用方法 2)。
- 具体代码实现如下:
```python
import json
import os.path
from transformers import BertForMaskedLM
from transformers import BertTokenizer, BertTokenizerFast
from transformers import AutoTokenizer
def get_unused_num(dir_name, f_vocab_txt, f_tokenizer_json):
"""
dir_name: 文件所在的目录路径
f_vocab_txt: vocab.txt 备份后文件名(建议对原文件进行备份, 如: vocab-origin.txt)
f_tokenizer_json: tokenizer.json 备份后的文件名(如: tokenizer-origin.json)
返回: [unusedxx] 词的个数;
"""
num_unused_txt = None
num_unused_json = None
f_txt = os.path.join(dir_name, f_vocab_txt)
f_json = os.path.join(dir_name, f_tokenizer_json)
if os.path.isfile(f_txt):
with open(f_txt, "r") as f_t:
ls_token = f_t.read().split("\n")
ls_unused_token_txt = [i for i in ls_token if "[unused" in i]
num_unused_txt = len(ls_unused_token_txt)
if os.path.isfile(f_json):
with open(f_json, "r") as f_j:
dict_ = json.load(f_j)
# jy: 可以通过如下方式查看可填充的 token (注意 if 判断 "[unused" 中的 "[" 不
# 能省略, 否则以 unused 为一个 token 的结果也会被筛选出来);
ls_unused_token = [i for i in dict_["model"]["vocab"].keys() if \
"[unused" in i]
num_unused_json = len(ls_unused_token)
if num_unused_txt and num_unused_json:
assert num_unused_txt == num_unused_json
return num_unused_txt
return num_unused_txt or num_unused_json
"""
dir_name = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased"
f_vocab_ori_txt = os.path.join(dir_name, "vocab-origin.txt")
f_tokenizer_ori_json = os.path.join(dir_name, "tokenizer-origin.json")
num_unused = get_unused_num(f_vocab_ori_txt, f_tokenizer_ori_json)
print(num_unused)
"""
def update_vocab_txt(dir_name, f_old_vocab_txt, ls_new_token):
"""
dir_name: 文件所在的目录路径
f_old_vocab_txt: 将原先的 vocab.txt 重命名, 如重命名为 old_vocab.txt,
随后更新的结果会新生成一个名为 vocab.txt 的文件;
ls_new_token: 存放待填充的新 token 列表;
"""
if f_old_vocab_txt.strip() == "vocab.txt":
raise Exception("需将原 vocab.txt 重命名, 如命名为 old_vocab.txt")
if not ls_new_token:
raise Exception("ls_new_token 不能为空")
unused_idx = 0
with open(os.path.join(dir_name, f_old_vocab_txt), "r") as f_, \
open(os.path.join(dir_name, "vocab.txt"), "w") as f_out:
for line in f_:
if "[unused" in line:
f_out.write(ls_new_token[unused_idx] + "\n")
unused_idx += 1
else:
f_out.write(line)
def update_tokenizer_json(dir_name, f_old_tokenizer_json, ls_new_token):
"""
dir_name: 文件所在的目录路径
f_old_tokenizer_json: 将原先的 tokenizer.json 重命名, 如重命名为 old_tokenizer.json,
随后更新的结果会新生成一个名为 tokenizer.json 的文件;
ls_new_token: 存放待填充的新 token 列表;
"""
if f_old_tokenizer_json.strip() == "tokenizer.json":
raise Exception("需将原 tokenizer.json 重命名, 如命名为 old_tokenizer.json")
if not ls_new_token:
raise Exception("ls_new_token 不能为空")
with open(os.path.join(dir_name, f_old_tokenizer_json), "r") as f_, \
open(os.path.join(dir_name, "tokenizer.json"), "w") as f_out:
# jy: 得到的 dict_ 字典结果包含如下 key:
# ['version', 'truncation', 'padding', 'added_tokens', 'normalizer',
# 'pre_tokenizer', 'post_processor', 'decoder', 'model']
# 其中, dict_["model"] 为一个包含如下 key 的字典:
# ['unk_token', 'continuing_subword_prefix',
# 'max_input_chars_per_word', 'vocab']
# 其中, dict_["model"]["vocab"] 为一个字典, 存储原始 token 以及其对应的 id;
dict_ = json.load(f_)
# jy: 可以通过如下方式查看可填充的 token (注意 if 判断 "[unused" 中的 "[" 不能
# 省略, 否则以 unused 为一个 token 的结果也会被筛选出来);
ls_unused_token = [i for i in dict_["model"]["vocab"].keys() if \
"[unused" in i]
#print(len(ls_unused_token))
min_len = min(len(ls_unused_token), len(ls_new_token))
for idx in range(min_len):
unused_token = ls_unused_token[idx]
new_token = ls_new_token[idx]
# jy: 将 unused token 的 id 更新到新词上, 并将相应的 unused token 记录删除;
dict_["model"]["vocab"][new_token] = \
dict_["model"]["vocab"][unused_token]
del dict_["model"]["vocab"][unused_token]
# jy: 此时的 dict_ 已经更新了新词, 将其导出到新文件中;
json.dump(dict_, f_out)
def get_ls_new_token(f_json_name):
"""
f_json_name: 存放 new_token 的 json 格式文件, 文件中的字典的 key 为 token, value
对应其出现的次数;
"""
ls_word_count = []
with open(f_json_name, "r") as f_:
dict_ = json.load(f_)
for word, count in dict_.items():
ls_word_count.append([word, count])
ls_word_count.sort(key=lambda x: x[1], reverse=True)
return ls_word_count
def add_ls_new_token(model_name_or_path, ls_new_token):
# jy: use_fast 参数实际上不起作用, 其值为 True 或 False 均不影响; 该参数只会在
# AutoTokenizer.from_pretrained() 中才会起作用, 参见第 3 章节解析;
#tokenizer = BertTokenizer.from_pretrained(model, use_fast=True)
tokenizer = BertTokenizer.from_pretrained(model_name_or_path)
model = BertForMaskedLM.from_pretrained(model_name_or_path)
print("未加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[0],
tokenizer.tokenize(ls_new_token[0]))
print("未加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[1],
tokenizer.tokenize(ls_new_token[1]))
# jy: 如果想让这些词保持完整的形式,可以通过重构 BERT 初始权重矩阵的方式将他们加入词表
num_added_toks = tokenizer.add_tokens(ls_new_token)
# jy: 返回的 num_added_toks 表示加入的新词数量, 即 ls_new_token 的个数;
print("加入的新词数量: %d" % num_added_toks)
# 关键步骤, resize_token_embeddings 输入的参数是 tokenizer 的新长度; 添加后的词汇,
# 通过 model.resize_token_embeddings 方法, 随机初始化了一个权重;
model.resize_token_embeddings(len(tokenizer))
print("加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[0],
tokenizer.tokenize(ls_new_token[0]))
print("加入 %s 时, 对其进行 tokenize 的结果: " % ls_new_token[1],
tokenizer.tokenize(ls_new_token[1]))
# 保存到原来的模型文件夹下, 这时文件夹下多了三个文件:
"""
added_tokens.json
special_tokens_map.json
tokenizer_config.json
"""
tokenizer.save_pretrained(model_name_or_path)
"""
model_name_or_path = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased"
ls_new_token = ['hospitalization', 'COVID']
add_ls_new_token(model_name_or_path, ls_new_token)
"""
dir_name = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased"
f_vocab_ori_txt_name = "vocab-origin.txt"
f_tokenizer_ori_json_name = "tokenizer-origin.json"
f_json_name = "/home/huangjiayue/00_common_knowledge/unspecified-domain-word/special_wordStem.json"
ls_new_token_count = get_ls_new_token(f_json_name)
print(ls_new_token_count[:20])
ls_new_token = [token_count[0] for token_count in ls_new_token_count]
num_unused = get_unused_num(dir_name, f_vocab_ori_txt_name, f_tokenizer_ori_json_name)
print(num_unused)
ls_new_token_txt_json = ls_new_token[: num_unused]
ls_new_token_additionalJsonFile = ls_new_token[num_unused: ]
update_vocab_txt(dir_name, f_vocab_ori_txt_name, ls_new_token_txt_json)
update_tokenizer_json(dir_name, f_tokenizer_ori_json_name, ls_new_token_txt_json)
model_name_or_path = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased"
add_ls_new_token(model_name_or_path, ls_new_token_additionalJsonFile)
def tokenize_test(model_name_or_path, ls_word, use_fast=True):
# jy: use_fast 参数实际上不起作用, 其值为 True 或 False 均不影响; 该参数只会在
# AutoTokenizer.from_pretrained() 中才会起作用, 参见第 3 章节解析;
#tokenizer = BertTokenizer.from_pretrained(model_name_or_path, use_fast=use_fast)
#tokenizer = BertTokenizer.from_pretrained(model_name_or_path)
#tokenizer = BertTokenizerFast.from_pretrained(model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
ls_res = []
for word in ls_word:
ls_res.append(tokenizer.tokenize(word))
return ls_res
model_path = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased"
ls_word = ['COVID', 'hospitalization']
print(tokenize_test(model_path, ls_word))
3、加载 tokenizer 类的注意事项
以上章节 2 中添加新 token 时使用的 tokenizer 类均为基于具体类初始化,但一般较为通用的模型架构均不会指定具体的 tokenizer 类的相应方法(如
BertTokenizer.from_pretrained()、BertTokenizerFast.from_pretrained()),而是使用 Transformers 中的AutoTokenizer.from_pretrained()进行相应的 tokenizer 类的初始化。两者的区别见如下说明。(1)基于通用 tokenizer 类(AutoTokenizer)
即基于(此时的
use_fast很关键,默认为True):AutoTokenizer.from_pretrained(model_path_or_name, use_fast)```python from transformers import AutoTokenizer
model_path_or_name = “/home/huangjiayue/04_SimCSE/jy_model/bert-base-cased”
jy: 使用 AutoTokenizer 类的 from_pretrained 方法时, 参数 use_fast (默认为 True)
有实际含义: 会依据 use_fast 的结果判断返回的结果是 BertTokenizer 还是
BertTokenizerFast
jy: 注意: AutoTokenizer.from_pretrained() 方法更通用, 会依据传入的
model_name_or_path 和 use_fast 参数返回相应的 tokenizer 模型(以
上的返回结果是假设 model_name_or_path 对应 BERT 类模型时);
tokenizer = AutoTokenizer.from_pretrained(model_path_or_name, use_fast=True)
jy:
print(type(tokenizer))
tokenizer = AutoTokenizer.from_pretrained(model_path_or_name, use_fast=False)
jy:
print(type(tokenizer))
<a name="KP3Ec"></a>
## (2)基于具体 tokenizer 类(如:BertTokenizer、BertTokenizerFast)
- 如基于(此时`use_fast`参数实际上不生效,可忽略):
- `BertTokenizer.from_pretrained(model_path_or_name, use_fast)`
- `BertTokenizerFast.from_pretrained(model_path_or_name, use_fast)`
```python
from transformers import BertTokenizer, BertTokenizerFast
model_path_or_name = "/home/huangjiayue/04_SimCSE/jy_model/bert-base-cased"
# jy: 使用具体 tokenizer 类(如 BertTokenizer、BertTokenizerFast) 的 from_pretrained
# 方法时, 传入的 use_fast 实际上不起作用(不会被代码逻辑所处理), 并不会因为传入此
# 参数为 True 就会初始化得到一个初始化的 BertTokenizerFast 类; 而是基于具体类本
# 身, 返回相应的实例化结果;
# jy: BertTokenizer.from_pretrained 结合 use_fast 参数测试 ------------------
tokenizer = BertTokenizer.from_pretrained(model_path_or_name, use_fast=True)
# jy: <class 'transformers.models.bert.tokenization_bert.BertTokenizer'>
print(type(tokenizer))
tokenizer = BertTokenizer.from_pretrained(model_path_or_name, use_fast=False)
# jy: <class 'transformers.models.bert.tokenization_bert.BertTokenizer'>
print(type(tokenizer))
# jy: BertTokenizerFast.from_pretrained 结合 use_fast 参数测试 -------------
tokenizer = BertTokenizerFast.from_pretrained(model_path_or_name, use_fast=True)
# jy: <class 'transformers.models.bert.tokenization_bert_fast.BertTokenizerFast'>
print(type(tokenizer))
tokenizer = BertTokenizerFast.from_pretrained(model_path_or_name, use_fast=False)
# jy: <class 'transformers.models.bert.tokenization_bert_fast.BertTokenizerFast'>
print(type(tokenizer))
4、BertTokenizer 与 BertTokenizerFast 加载 token 词表的区别
基于 BERT 的 fine-tune 模型中, 如果对 token 有所补充,当采用在词表
vocab.txt中替换 诸如[unused0]词的方式时,为了使替换后生效,加载 tokenizer 模型如果是基于BertTokenizerFast类,则有本章节说明中的注意事项,不注意时可能修改词表文件后新 token 不生效。(使用tokenizer.add_token的方式添加新 token 则均不受影响)。(1)BertTokenizerFast 加载 token 词表的逻辑
如果基于以下方式初始化 tokenizer 类,则会走本小节介绍的逻辑(其中
model_path_or_name对应 BERT 类型的模型路径):AutoTokenizer.from_pretrained(model_path_or_name, use_fast=True)use_fast默认即为True
BertTokenizerFast.from_pretrained(model_path_or_name)
- 加载 token 词表的代码逻辑如下(参考
/transformers/tokenization_utils_fast.py中的PreTrainedTokenizerFast类的初始化方法(__init__)中的代码逻辑):- 如果模型文件夹下的
tokenizer.json存在,会优先基于tokenizer.json获取 token 词表信息(此时的vocab.txt不起作用)。 - 如果模型文件夹下的
tokenizer.json不存在,则基于vocab.txt初始化BertTokenizer(非'Fast'类型), 再将其转换为BertTokenizerFast。
- 如果模型文件夹下的
此时,如果要实现章节 2 中的功能(向 tokenizer 模型中添加新的 token 词表),可以通过以下方式:
直接载入文件后将相应字符串替换(不推荐),因为基于字符串的替换难免替换不全,或替换出错,需确保输入的待替换的
unused_token是独一无二的形式。 ```python import re
def replace_unused_token(f_old_tokenizer_json, ls_new_token): “”” f_old_tokenizer_json: 将原先的 tokenizer.json 重命名, 如重命名为 old_tokenizer.json, 随后更新的结果会新生成一个名为 tokenizer.json 的文件; ls_new_token: 存放待填充的新 token 列表; “”” if f_old_tokenizer_json.strip() == “tokenizer.json”: raise Exception(“需将原 tokenizer.json 重命名, 如命名为 old_tokenizer.json”)
if not ls_new_token:
raise Exception("ls_new_token 不能为空")
with open(f_old_tokenizer_json, "r") as f_, \
open("tokenizer.json", "w") as f_out:
# jy: 读取全文件内容;
str_ = f_.read()
# jy: 基于正则匹配, 匹配出模式为 "[unused{number}]" 的字符串
ls_unused_token = re.findall("\[unused\d+\]", str_)
min_len = min(len(ls_unused_token), len(ls_new_token))
for idx in range(min_len):
unused_token = ls_unused_token[idx]
new_token = ls_new_token[idx]
str_ = str_.replace(unused_token, new_token)
f_out.write(str_)
<a name="v0nnQ"></a>
### (b)通过导入`tokenizer.json`文件后修改、导出
```python
import json
def update_tokenizer_json(f_old_tokenizer_json, ls_new_token):
"""
f_old_tokenizer_json: 将原先的 tokenizer.json 重命名, 如重命名为 old_tokenizer.json,
随后更新的结果会新生成一个名为 tokenizer.json 的文件;
ls_new_token: 存放待填充的新 token 列表;
"""
if f_old_tokenizer_json.strip() == "tokenizer.json":
raise Exception("需将原 tokenizer.json 重命名, 如命名为 old_tokenizer.json")
if not ls_new_token:
raise Exception("ls_new_token 不能为空")
with open(f_old_tokenizer_json, "r") as f_, \
open("tokenizer.json", "w") as f_out:
# jy: 得到的 dict_ 字典结果包含如下 key:
# ['version', 'truncation', 'padding', 'added_tokens', 'normalizer',
# 'pre_tokenizer', 'post_processor', 'decoder', 'model']
# 其中, dict_["model"] 为一个包含如下 key 的字典:
# ['unk_token', 'continuing_subword_prefix',
# 'max_input_chars_per_word', 'vocab']
# 其中, dict_["model"]["vocab"] 为一个字典, 存储原始 token 以及其对应的 id;
dict_ = json.load(f_)
# jy: 可以通过如下方式查看可填充的 token (注意 if 判断 "[unused" 中的 "[" 不能省
# 略, 否则以 unused 为一个 token 的结果也会被筛选出来);
ls_unused_token = [i for i in dict_["model"]["vocab"].keys() if "[unused" in i]
#print(len(ls_unused_token))
min_len = min(len(ls_unused_token), len(ls_new_token))
for idx in range(min_len):
unused_token = ls_unused_token[idx]
new_token = len_new_token[idx]
# jy: 将 unused token 的 id 更新到新词上, 并将相应的 unused token 记录删除;
dict_["model"]["vocab"][new_token] = dict_["model"]["vocab"][unused_token]
del dict_["model"]["vocab"][unused_token]
# jy: 此时的 dict_ 已经更新了新词, 将其导出到新文件中;
json.dump(dict_, f_out)
(2)BertTokenizer 加载 token 词表的逻辑
- 如果基于以下方式初始化 tokenizer 类,则会走本小节介绍的逻辑(其中
model_path_or_name对应 BERT 类型的模型路径):AutoTokenizer.from_pretrained(model_path_or_name, use_fast=False)BertTokenizer.from_pretrained(model_path_or_name)
- 即使模型文件夹下有
tokenizer.json和vocab.txt两个文件,最终也只会使用到vocab.txt文件,因此如果确定使用的是BertTokenizer,则补充新词时只需修改vocab.txt文件就可以。 -
(3)测试代码
可以在
vocab.txt文件中的 3 个 unused 词的位置替换为:∼、covid、anewword后执行如下代码进行测试。 ```python
from transformers import AutoTokenizer from transformers import BertTokenizer, BertTokenizerFast
def tokenize_test(model_name_or_path, text):
#tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=True)
#tokenizer = BertTokenizer.from_pretrained(model_name_or_path)
#tokenizer = BertTokenizerFast.from_pretrained(model_name_or_path)
#import pdb; pdb.set_trace()
#ls_new_tokens = ["∼", "covid", "anewword"]
#num_added_toks = tokenizer.add_tokens(ls_new_tokens)
#print(num_added_toks)
ls_token = tokenizer.tokenize(text)
return ls_token
text = “We are very happy to show you the Transformers library.”
text = “We are very happy to show you the Transformer model.”
text = “anewword COVID 2~fold, 2 ∼ fold” model_name_or_path= “/home/huangjiayue/04_SimCSE/jy_model/bert-base-uncased/“ ls_token = tokenize_test(model_name_or_path, text) print(ls_token) ```

若有收获,就点个赞吧
0 人点赞
