1、Fine-tuning with Cloud TPUs
- Important: All results on the paper were fine-tuned on a single Cloud TPU, which has 64GB of RAM. It is currently not possible to re-produce most of the
BERT-Largeresults on the paper using a GPU with 12GB - 16GB of RAM, because the maximum batch size that can fit in memory is too small.- allows for much larger effective batch size on the GPU:
- 参考第 5 章节:Out-of-memory issues
- allows for much larger effective batch size on the GPU:
- This code was tested with TensorFlow 1.11.0. It was tested with Python2 and Python3 (but more thoroughly with Python2, since this is what’s used internally in Google).
- The fine-tuning examples which use
BERT-Baseshould be able to run on a GPU that has at least 12GB of RAM using the hyperparameters given. Most of the examples below assumes that you will be running training/evaluation on your local machine, using a GPU like a Titan X or GTX 1080. However, if you have access to a Cloud TPU that you want to train on, just add the following flags to
run_classifier.pyorrun_squad.py:--use_tpu=True --tpu_name=$TPU_NAME
Please see the Google Cloud TPU tutorial for how to use Cloud TPUs. Alternatively, you can use the Google Colab notebook “BERT FineTuning with Cloud TPUs”.
- Google Cloud TPU tutorial
- BERT FineTuning with Cloud TPUs
On Cloud TPUs, the pretrained model and the output directory will need to be on Google Cloud Storage. For example, if you have a bucket named
some_bucket, you might use the following flags instead:--output_dir=gs://some_bucket/my_output_dir/The unzipped pre-trained model files can also be found in the Google Cloud Storage folder
gs://bert_models/2018_10_18. For example:export BERT_BASE_DIR=gs://bert_models/2018_10_18/uncased_L-12_H-768_A-122、Sentence (and sentence-pair) classification tasks
(1)data preparation
Before running this example you must download the GLUE data by running the script below:
- GLUE data:https://gluebenchmark.com/tasks
- script:https://gist.github.com/W4ngatang/60c2bdb54d156a41194446737ce03e2e ```python ‘’’ Script for downloading all GLUE data. Note: for legal reasons, we are unable to host MRPC. You can either use the version hosted by the SentEval team, which is already tokenized, or you can download the original data from (https://download.microsoft.com/download/D/4/6/D46FF87A-F6B9-4252-AA8B-3604ED519838/MSRParaphraseCorpus.msi) and extract the data from it manually. For Windows users, you can run the .msi file. For Mac and Linux users, consider an external library such as ‘cabextract’ (see below for an example). You should then rename and place specific files in a folder (see below for an example). mkdir MRPC cabextract MSRParaphraseCorpus.msi -d MRPC cat MRPC/2DEC3DBE877E4DB192D17C0256E90F1D | tr -d $’\r’ > MRPC/msr_paraphrase_train.txt cat MRPC/_D7B391F9EAFF4B1B8BCE8F21B20B1B61 | tr -d $’\r’ > MRPC/msr_paraphrase_test.txt rm MRPC/ rm MSRParaphraseCorpus.msi 1/30/19: It looks like SentEval is no longer hosting their extracted and tokenized MRPC data, so you’ll need to download the data from the original source for now. 2/11/19: It looks like SentEval actually is* hosting the extracted data. Hooray! ‘’’
import os import sys import shutil import argparse import tempfile import urllib.request import zipfile
TASKS = [“CoLA”, “SST”, “MRPC”, “QQP”, “STS”, “MNLI”, “QNLI”, “RTE”, “WNLI”, “diagnostic”] TASK2PATH = {“CoLA”:’https://dl.fbaipublicfiles.com/glue/data/CoLA.zip‘, “SST”:’https://dl.fbaipublicfiles.com/glue/data/SST-2.zip‘, “QQP”:’https://dl.fbaipublicfiles.com/glue/data/STS-B.zip‘, “STS”:’https://dl.fbaipublicfiles.com/glue/data/QQP-clean.zip‘, “MNLI”:’https://dl.fbaipublicfiles.com/glue/data/MNLI.zip‘, “QNLI”:’https://dl.fbaipublicfiles.com/glue/data/QNLIv2.zip‘, “RTE”:’https://dl.fbaipublicfiles.com/glue/data/RTE.zip‘, “WNLI”:’https://dl.fbaipublicfiles.com/glue/data/WNLI.zip‘, “diagnostic”:’https://dl.fbaipublicfiles.com/glue/data/AX.tsv'}
MRPC_TRAIN = ‘https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_train.txt‘ MRPC_TEST = ‘https://dl.fbaipublicfiles.com/senteval/senteval_data/msr_paraphrase_test.txt‘
def download_and_extract(task, data_dir): print(“Downloading and extracting %s…” % task) if task == “MNLI”: print(“\tNote (12/10/20): This script no longer downloads SNLI. You will need to manually download and format the data to use SNLI.”) data_file = “%s.zip” % task urllib.request.urlretrieve(TASK2PATH[task], data_file) with zipfile.ZipFile(data_file) as zip_ref: zip_ref.extractall(data_dir) os.remove(data_file) print(“\tCompleted!”)
def format_mrpc(data_dir, path_to_data): print(“Processing MRPC…”) mrpc_dir = os.path.join(data_dir, “MRPC”) if not os.path.isdir(mrpc_dir): os.mkdir(mrpc_dir) if path_to_data: mrpc_train_file = os.path.join(path_to_data, “msr_paraphrase_train.txt”) mrpc_test_file = os.path.join(path_to_data, “msr_paraphrase_test.txt”) else: try: mrpc_train_file = os.path.join(mrpc_dir, “msr_paraphrase_train.txt”) mrpc_test_file = os.path.join(mrpc_dir, “msr_paraphrase_test.txt”) URLLIB.urlretrieve(MRPC_TRAIN, mrpc_train_file) URLLIB.urlretrieve(MRPC_TEST, mrpc_test_file) except urllib.error.HTTPError: print(“Error downloading MRPC”) return assert os.path.isfile(mrpc_train_file), “Train data not found at %s” % mrpc_train_file assert os.path.isfile(mrpc_test_file), “Test data not found at %s” % mrpc_test_file
with io.open(mrpc_test_file, encoding='utf-8') as data_fh, \
io.open(os.path.join(mrpc_dir, "test.tsv"), 'w', encoding='utf-8') as test_fh:
header = data_fh.readline()
test_fh.write("index\t#1 ID\t#2 ID\t#1 String\t#2 String\n")
for idx, row in enumerate(data_fh):
label, id1, id2, s1, s2 = row.strip().split('\t')
test_fh.write("%d\t%s\t%s\t%s\t%s\n" % (idx, id1, id2, s1, s2))
try:
URLLIB.urlretrieve(TASK2PATH["MRPC"], os.path.join(mrpc_dir, "dev_ids.tsv"))
except KeyError or urllib.error.HTTPError:
print("\tError downloading standard development IDs for MRPC. You will need to manually split your data.")
return
dev_ids = []
with io.open(os.path.join(mrpc_dir, "dev_ids.tsv"), encoding='utf-8') as ids_fh:
for row in ids_fh:
dev_ids.append(row.strip().split('\t'))
with io.open(mrpc_train_file, encoding='utf-8') as data_fh, \
io.open(os.path.join(mrpc_dir, "train.tsv"), 'w', encoding='utf-8') as train_fh, \
io.open(os.path.join(mrpc_dir, "dev.tsv"), 'w', encoding='utf-8') as dev_fh:
header = data_fh.readline()
train_fh.write(header)
dev_fh.write(header)
for row in data_fh:
label, id1, id2, s1, s2 = row.strip().split('\t')
if [id1, id2] in dev_ids:
dev_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))
else:
train_fh.write("%s\t%s\t%s\t%s\t%s\n" % (label, id1, id2, s1, s2))
print("\tCompleted!")
def download_diagnostic(data_dir): print(“Downloading and extracting diagnostic…”) if not os.path.isdir(os.path.join(data_dir, “diagnostic”)): os.mkdir(os.path.join(data_dir, “diagnostic”)) data_file = os.path.join(data_dir, “diagnostic”, “diagnostic.tsv”) urllib.request.urlretrieve(TASK2PATH[“diagnostic”], data_file) print(“\tCompleted!”) return
def get_tasks(task_names): task_names = task_names.split(‘,’) if “all” in task_names: tasks = TASKS else: tasks = [] for task_name in task_names: assert task_name in TASKS, “Task %s not found!” % task_name tasks.append(task_name) return tasks
def main(arguments): parser = argparse.ArgumentParser() parser.add_argument(‘—data_dir’, help=’directory to save data to’, type=str, default=’glue_data’) parser.add_argument(‘—tasks’, help=’tasks to download data for as a comma separated string’, type=str, default=’all’) parser.add_argument(‘—path_to_mrpc’, help=’path to directory containing extracted MRPC data, msr_paraphrase_train.txt and msr_paraphrase_text.txt’, type=str, default=’’) args = parser.parse_args(arguments)
if not os.path.isdir(args.data_dir):
os.mkdir(args.data_dir)
tasks = get_tasks(args.tasks)
for task in tasks:
if task == 'MRPC':
format_mrpc(args.data_dir, args.path_to_mrpc)
elif task == 'diagnostic':
download_diagnostic(args.data_dir)
else:
download_and_extract(task, args.data_dir)
if name == ‘main‘: sys.exit(main(sys.argv[1:]))
- and unpack it to some directory `$GLUE_DIR`. Next, download the `BERT-Base` checkpoint and unzip it to some directory `$BERT_BASE_DIR`.
<a name="bRcJ4"></a>
## (2)train the classifier
- This example code fine-tunes `BERT-Base` on the Microsoft Research Paraphrase Corpus (MRPC) corpus, which only contains 3,600 examples and can fine-tune in a few minutes on most GPUs.
```shell
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
python run_classifier.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/mrpc_output/
You should see output like this:
***** Eval results ***** eval_accuracy = 0.845588 eval_loss = 0.505248 global_step = 343 loss = 0.505248This means that the Dev set accuracy was 84.55%. Small sets like MRPC have a high variance in the Dev set accuracy, even when starting from the same pre-training checkpoint. If you re-run multiple times (making sure to point to different
output_dir), you should see results between 84% and 88%.- A few other pre-trained models are implemented off-the-shelf(现成的; 成品的;现成(用)的;流行的;畅销的;已准备好的;准军用的)in
run_classifier.py, so it should be straightforward to follow those examples to use BERT for any single-sentence or sentence-pair classification task. Note: You might see a message
Running train on CPU. This really just means that it’s running on something other than a Cloud TPU, which includes a GPU.(3)Prediction from classifier
Once you have trained your classifier you can use it in inference mode by using the
--do_predict=truecommand. You need to have a file namedtest.tsvin the input folder. Output will be created in file calledtest_results.tsvin the output folder. Each line will contain output for each sample, columns are the class probabilities. ```shell export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12 export GLUE_DIR=/path/to/glue export TRAINED_CLASSIFIER=/path/to/fine/tuned/classifier
python run_classifier.py \ —task_name=MRPC \ —do_predict=true \ —data_dir=$GLUE_DIR/MRPC \ —vocab_file=$BERT_BASE_DIR/vocab.txt \ —bert_config_file=$BERT_BASE_DIR/bert_config.json \ —init_checkpoint=$TRAINED_CLASSIFIER \ —max_seq_length=128 \ —output_dir=/tmp/mrpc_output/
<a name="e9fNP"></a>
# 3、SQuAD 1.1
- The Stanford Question Answering Dataset (SQuAD) is a popular question answering benchmark dataset. BERT (at the time of the release) obtains state-of-the-art results on SQuAD with almost no task-specific network architecture modifications or data augmentation. However, it does require semi-complex data pre-processing and post-processing to deal with(This processing is implemented and documented in `run_squad.py`):
- (a) the variable-length nature of SQuAD context paragraphs
- (b) the character-level answer annotations which are used for SQuAD training.
- To run on SQuAD, you will first need to download the dataset. The SQuAD website does not seem to link to the v1.1 datasets any longer, but the necessary files can be found here:
- SQuAD website :[https://rajpurkar.github.io/SQuAD-explorer/](https://rajpurkar.github.io/SQuAD-explorer/)
- `train-v1.1.json`:[https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v1.1.json)
- `dev-v1.1.json`:[https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json](https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v1.1.json)
- `evaluate-v1.1.py`:[https://github.com/allenai/bi-att-flow/blob/master/squad/evaluate-v1.1.py](https://github.com/allenai/bi-att-flow/blob/master/squad/evaluate-v1.1.py)
- Download these to some directory `$SQUAD_DIR`.
- The state-of-the-art SQuAD results from the paper currently cannot be reproduced on a 12GB-16GB GPU due to memory constraints (in fact, even batch size 1 does not seem to fit on a 12GB GPU using `BERT-Large`). However, a reasonably strong `BERT-Base` model can be trained on the GPU with these hyperparameters:
```shell
python run_squad.py \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v1.1.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v1.1.json \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=/tmp/squad_base/
The dev set predictions will be saved into a file called
predictions.jsonin theoutput_dir:python $SQUAD_DIR/evaluate-v1.1.py $SQUAD_DIR/dev-v1.1.json ./squad/predictions.jsonWhich should produce an output like this:
{"f1": 88.41249612335034, "exact_match": 81.2488174077578}You should see a result similar to the 88.5% reported in the paper for
BERT-Base.If you have access to a Cloud TPU, you can train with
BERT-Large. Here is a set of hyperparameters (slightly different than the paper) which consistently obtain around 90.5%-91.0% F1 single-system trained only on SQuAD:python run_squad.py \ --vocab_file=$BERT_LARGE_DIR/vocab.txt \ --bert_config_file=$BERT_LARGE_DIR/bert_config.json \ --init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \ --do_train=True \ --train_file=$SQUAD_DIR/train-v1.1.json \ --do_predict=True \ --predict_file=$SQUAD_DIR/dev-v1.1.json \ --train_batch_size=24 \ --learning_rate=3e-5 \ --num_train_epochs=2.0 \ --max_seq_length=384 \ --doc_stride=128 \ --output_dir=gs://some_bucket/squad_large/ \ --use_tpu=True \ --tpu_name=$TPU_NAMEFor example, one random run with these parameters produces the following Dev scores:
{"f1": 90.87081895814865, "exact_match": 84.38978240302744}If you fine-tune for one epoch on TriviaQA before this the results will be even better, but you will need to convert TriviaQA into the SQuAD json format.
- TriviaQA:http://nlp.cs.washington.edu/triviaqa/
4、SQuAD 2.0
- TriviaQA:http://nlp.cs.washington.edu/triviaqa/
This model is also implemented and documented in
run_squad.py.- To run on SQuAD 2.0, you will first need to download the dataset. The necessary files can be found here:
- Download these to some directory
$SQUAD_DIR. On Cloud TPU you can run with BERT-Large as follows:
python run_squad.py \ --vocab_file=$BERT_LARGE_DIR/vocab.txt \ --bert_config_file=$BERT_LARGE_DIR/bert_config.json \ --init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \ --do_train=True \ --train_file=$SQUAD_DIR/train-v2.0.json \ --do_predict=True \ --predict_file=$SQUAD_DIR/dev-v2.0.json \ --train_batch_size=24 \ --learning_rate=3e-5 \ --num_train_epochs=2.0 \ --max_seq_length=384 \ --doc_stride=128 \ --output_dir=gs://some_bucket/squad_large/ \ --use_tpu=True \ --tpu_name=$TPU_NAME \ --version_2_with_negative=TrueWe assume you have copied everything from the output directory to a local directory called
./squad/. The initial dev set predictions will be at./squad/predictions.jsonand the differences between the score of no answer (“”) and the best non-null answer for each question will be in the file./squad/null_odds.jsonRun this script to tune a threshold for predicting null versus non-null answers:
python $SQUAD_DIR/evaluate-v2.0.py $SQUAD_DIR/dev-v2.0.json ./squad/predictions.json --na-prob-file ./squad/null_odds.jsonAssume the script outputs “best_f1_thresh” THRESH. (Typical values are between -1.0 and -5.0). You can now re-run the model to generate predictions with the derived threshold or alternatively you can extract the appropriate answers from
./squad/nbest_predictions.json.python run_squad.py \ --vocab_file=$BERT_LARGE_DIR/vocab.txt \ --bert_config_file=$BERT_LARGE_DIR/bert_config.json \ --init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \ --do_train=False \ --train_file=$SQUAD_DIR/train-v2.0.json \ --do_predict=True \ --predict_file=$SQUAD_DIR/dev-v2.0.json \ --train_batch_size=24 \ --learning_rate=3e-5 \ --num_train_epochs=2.0 \ --max_seq_length=384 \ --doc_stride=128 \ --output_dir=gs://some_bucket/squad_large/ \ --use_tpu=True \ --tpu_name=$TPU_NAME \ --version_2_with_negative=True \ --null_score_diff_threshold=$THRESH5、Out-of-memory issues
All experiments in the paper were fine-tuned on a Cloud TPU, which has 64GB of device RAM. Therefore, when using a GPU with 12GB - 16GB of RAM, you are likely to encounter out-of-memory issues if you use the same hyperparameters described in the paper.
- The factors that affect memory usage are:
**max_seq_length**:- The released models were trained with sequence lengths up to 512, but you can fine-tune with a shorter max sequence length to save substantial memory. This is controlled by the
max_seq_lengthflag in our example code.
- The released models were trained with sequence lengths up to 512, but you can fine-tune with a shorter max sequence length to save substantial memory. This is controlled by the
**train_batch_size**:- The memory usage is also directly proportional to the batch size.
- Model type(
**BERT-Base**vs.**BERT-Large**)- The
BERT-Largemodel requires significantly more memory thanBERT-Base.
- The
- Optimizer
- The default optimizer for BERT is Adam, which requires a lot of extra memory to store the
mandvvectors. Switching to a more memory efficient optimizer can reduce memory usage, but can also affect the results. We have not experimented with other optimizers for fine-tuning.
- The default optimizer for BERT is Adam, which requires a lot of extra memory to store the
Using the default training scripts (
run_classifier.pyandrun_squad.py), we benchmarked the maximum batch size on single Titan X GPU (12GB RAM) with TensorFlow 1.11.0: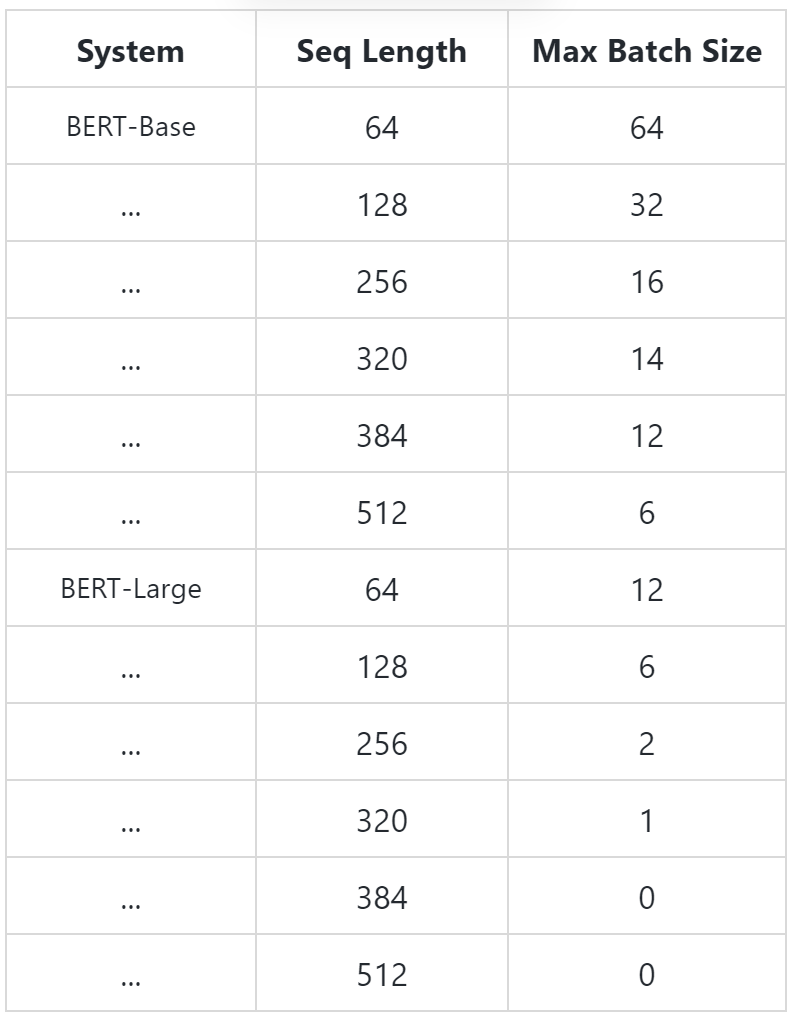Unfortunately, these max batch sizes for
BERT-Largeare so small that they will actually harm the model accuracy, regardless of the learning rate used. We are working on adding code to this repository which will allow much larger effective batch sizes to be used on the GPU. The code will be based on one (or both) of the following techniques(However, this is not implemented in the current release.):- Gradient accumulation: The samples in a minibatch are typically independent with respect to gradient computation (excluding batch normalization, which is not used here). This means that the gradients of multiple smaller minibatches can be accumulated before performing the weight update, and this will be exactly equivalent to a single larger update.
- Gradient checkpointing: The major use of GPU/TPU memory during DNN training is caching the intermediate activations in the forward pass that are necessary for efficient computation in the backward pass. “Gradient checkpointing” trades memory for compute time by re-computing the activations in an intelligent way.

若有收获,就点个赞吧
0 人点赞
