【2021-09-09】SimCSE:Simple Contrastive Learning of Sentence Embeddings
Contrastive learning aims to learn effective representation by pulling semantically close neighbors together and pushing apart non-neighbors。
- 数据集:
 ,其中
,其中 and
and are semantically related.
are semantically related. - 本论文:follow the contrastive framework in 【2020-00-00】A Simple Framework for Contrastive Learning of Visual Representations and take a cross-entropy objective with in-batch negatives.
- training objective for
 with a mini-batch of _N _pairs is:
with a mini-batch of _N _pairs is:

- 参数解析:
 和
和 :the representations of
:the representations of and
and
 :temperature hyperparameter(for softmax),SimCSE 中设置默认 0.05
:temperature hyperparameter(for softmax),SimCSE 中设置默认 0.05 :
: 和
和 的 cosine 相似度:
的 cosine 相似度:
公式解读
In visual representations
- take two random transformations of the _same _image (e.g., cropping, flflipping, distortion and rotation)
- in language representations
- similar approach has been recently adopted:apply augmentation techniques such as word deletion, reordering, and substitution
- However, data augmentation in NLP is inherently difficult because of its discrete nature.
- 同时本文表明:simply using standard dropout on intermediate representations outperforms these discrete operators.
- NLP 中
- similar contrastive learning objective has been explored in different contexts:
 are collected from supervised datasets such as question-passage pairs.
are collected from supervised datasets such as question-passage pairs.- Because of the distinct nature of
 and
and , these approaches always use a dual-encoder framework(即分别使用两个不同的编码器)
, these approaches always use a dual-encoder framework(即分别使用两个不同的编码器)
- Because of the distinct nature of
- 【2018-00-00】An efficient framework for learning sentence representations中:use contrastive learning with a dual-encoder approach, by forming current sentence and next sentence as

- similar contrastive learning objective has been explored in different contexts:
本论文中使用 pre-trained language models(BERT or RoBERTa)进行句子向量化,然后基于以上目标函数进行 fine-tune。
(该论文以此为基础进行效果分析)
- 【2020-00-00】Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere(即分析工具:alignuniform)中提到:identify two key properties related to contrastive learning:_alignment _and _uniformity,and propose to use them to measure the quality of representations.
- takes alignment between semantically-related positive pairs and uniformity of the whole representation space to measure the quality of learned embeddings.
- Given a distribution of positive pairs

- alignment calculates expected distance between embeddings of the paired instances (assuming representations are already normalized):
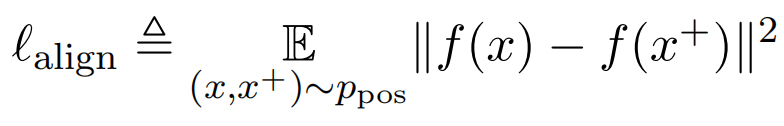
- uniformity measures how well the embeddings are uniformly distributed(
 denotes the data distribution):
denotes the data distribution):
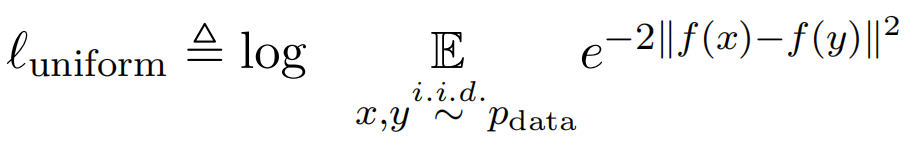
- For both
 and
and  ,lower numbers are better.
,lower numbers are better. 越小,表明相似的句子之间的距离越小。
越小,表明相似的句子之间的距离越小。 越小,即 e^(-x) 中 x 越大,即不相似(假设 uniformly distributed 中任选两个句子组成的 pair 是不相似的,这也是大概率事件)的句子之间的距离越大。
越小,即 e^(-x) 中 x 越大,即不相似(假设 uniformly distributed 中任选两个句子组成的 pair 是不相似的,这也是大概率事件)的句子之间的距离越大。
- These two metrics are well aligned with the objective of contrastive learning: positive instances should stay close and embeddings for random instances should scatter on the hypersphere.
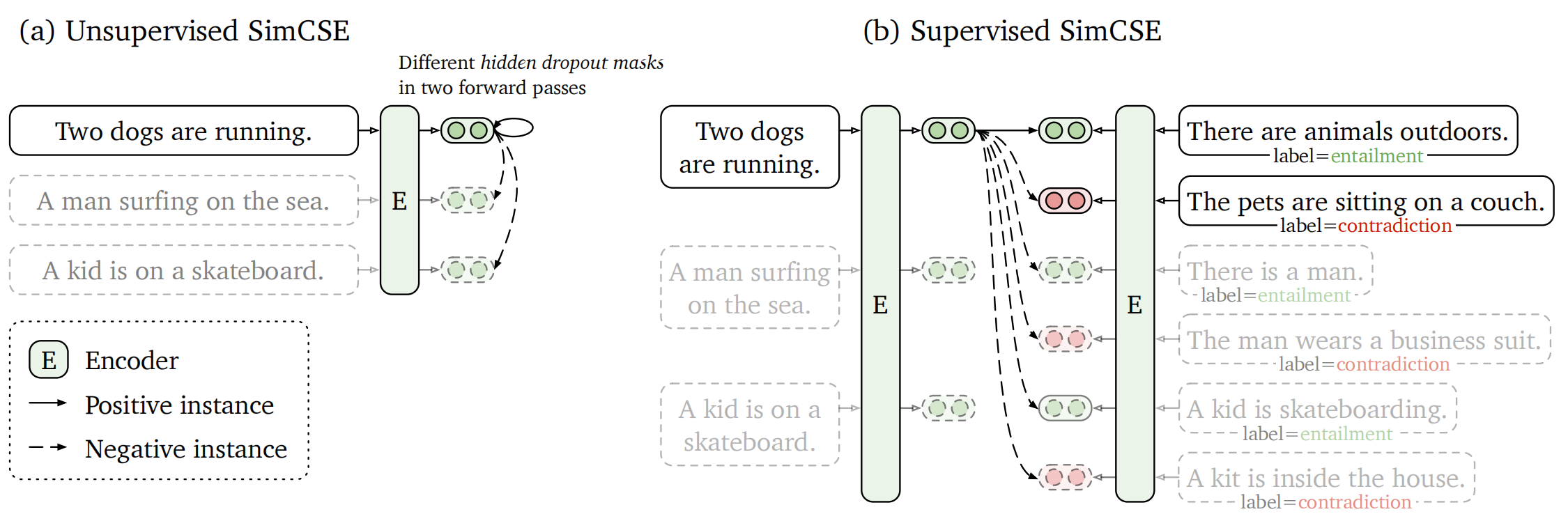
1、Approach
- 其中,Supervised SimCSE 中的红色部分代表 hard negatives(参见 “(2)Supervised SimCSE”中的“(b)”)
关于 positive pairs 与 negative pairs 的比例
- We use in-batch negatives, which means for every positive pairs all the rest sentences in the batch are negatives. So the ratio depends on the batch size.
- We found that in SimCSE batch size doesn’t matter that much (we tried further increasing batch sizes but no significant difference). The common belief though, when it comes to the InfoNCE loss, is that the more negative the better (because here the negatives are on the denominator so there is no need to balance).
- 参考:https://github.com/princeton-nlp/SimCSE/issues/176
(1)Unsupervised SimCSE
- 参考:https://github.com/princeton-nlp/SimCSE/issues/176
Takes an input sentence and predicts itself_ _in a contrastive objective, with only standard dropout used as noise.
- predicts the input sentence itself from in-batch negatives, with different hidden dropout masks applied.
- In other words:
- positive pairs:we pass the same sentence to the pre-trained encoder twice(by applying the standard dropout twice)and obtain two different embeddings
- In standard training of Transformers, there are dropout masks placed on fully-connected layers as well as attention probabilities (default p = 0_._1).
- We denote
 where
where  _ _is a random mask for dropout.
_ _is a random mask for dropout. - We simply feed the same input to the encoder _twice _and get two embeddings with different dropout masks
 、
、 and the training objective is(与第 0 章节的公式相同,只是将句向量换为经过 dropout 后的结果):
and the training objective is(与第 0 章节的公式相同,只是将句向量换为经过 dropout 后的结果):
- Note that
 is just the standard _dropout mask in Transformers(dropout probability _p = 0_._1)and we do not add any additional dropout.
is just the standard _dropout mask in Transformers(dropout probability _p = 0_._1)and we do not add any additional dropout.
- negative pairs:take other sentences in the same mini-batch.
- objectivity:predicts the positive one among negatives.
(2)Supervised SimCSE
- positive pairs:we pass the same sentence to the pre-trained encoder twice(by applying the standard dropout twice)and obtain two different embeddings
Incorporates annotated pairs from NLI(natural language inference) datasets into contrastive learning framework by using “entailment”(premise-hypothesis)pairs as positives and “contradiction” pairs as well as other in-batch instances as hard negatives.(实验结果表明将 “contradiction” pairs 作为 hard negatives 可进一步提高实验效果)
- builds upon the success of using NLI datasets for sentence embeddings (鉴于先前 NLI 数据集在 sentence embedding 上的成功应用),by predicting whether the relationship between two sentences is entailment, neutral _or _contradiction(3-way classifification task).
- 【2017-09-07】Supervised Learning of Universal Sentence Representations from Natural Language Inference Data
- 【2019-08-27】Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks
- Unlike previous work that casts it as a 3-way classifification task, we leverage the fact that:
- entailment pairs can be naturally used as positive instances.
- directly take
 pairs from supervised datasets
pairs from supervised datasets
- directly take
- adding corresponding contradiction pairs as hard negatives further improves performance.
- entailment pairs can be naturally used as positive instances.
- builds upon the success of using NLI datasets for sentence embeddings (鉴于先前 NLI 数据集在 sentence embedding 上的成功应用),by predicting whether the relationship between two sentences is entailment, neutral _or _contradiction(3-way classifification task).
在没使用 hard negatives 时,目标函数与 unsupervised 时的相同,使用了 hard negatives 时的目标函数参见 “(b)hard negatives”中的说明。
(a)supervised datasets 的选择
compare to other labeled sentence-pair datasets and find that NLI datasets are especially effective for learning sentence embeddings.
- We experiment with a number of datasets with sentence-pair examples:
- QQP(Quora question pairs)
- Flickr30k
- each image is annotated with 5 human-written captions and we consider any two captions of the same image as a positive pair.
- ParaNMT
- a large-scale back-translation paraphrase dataset(automatically constructed by machine translation systems)
- Strictly speaking, we should not call it “supervised”. It underperforms our unsupervised SimCSE though.
- NLI datasets(SNLI + MNLI)
- 注意,不包括 ANLI,因为实验结果表明不能改善效果
- consist of high-quality and crowd-sourced pairs.
- In NLI datasets, given one premise, annotators are required to manually write one sentence that is absolutely true (entailment), one that might be true (neutral), and one that is definitely false (contradiction).
- 即给定 premise,标注员要给出三种句子
- human annotators are expected to write the hypotheses manually based on the premises and two sentences tend to have less lexical overlap.
- lexical overlap (F1 measured between two bags of words) 分析:
- entailment pairs (SNLI + MNLI):39%
- QQP:60%
- ParaNMT:55%
- lexical overlap (F1 measured between two bags of words) 分析:
不同 supervised 数据集的实验结果参见章节 2 中的“(2)”小节。
(b)融入 hard negatives、目标函数
further take the advantage of the NLI datasets by using its contradiction pairs as hard negatives
- 数据集也由原先的
 变为
变为
 :the premise
:the premise :entailment
:entailment :contradiction
:contradiction
- 目标函数:

2、评测任务:STS
在 STS-B数据集(衡量指标:Spearman’s correlation)上的评测分析。
We find that dropout acts as minimal data augmentation of hidden representations and removing it leads to a representation collapse.
- the positive pair takes exactly the same sentence, and their embeddings only differ in dropout masks.
- 不同 data augmentations 方法(将其视作数据增强,因此与其他数据增强实验进行对比)
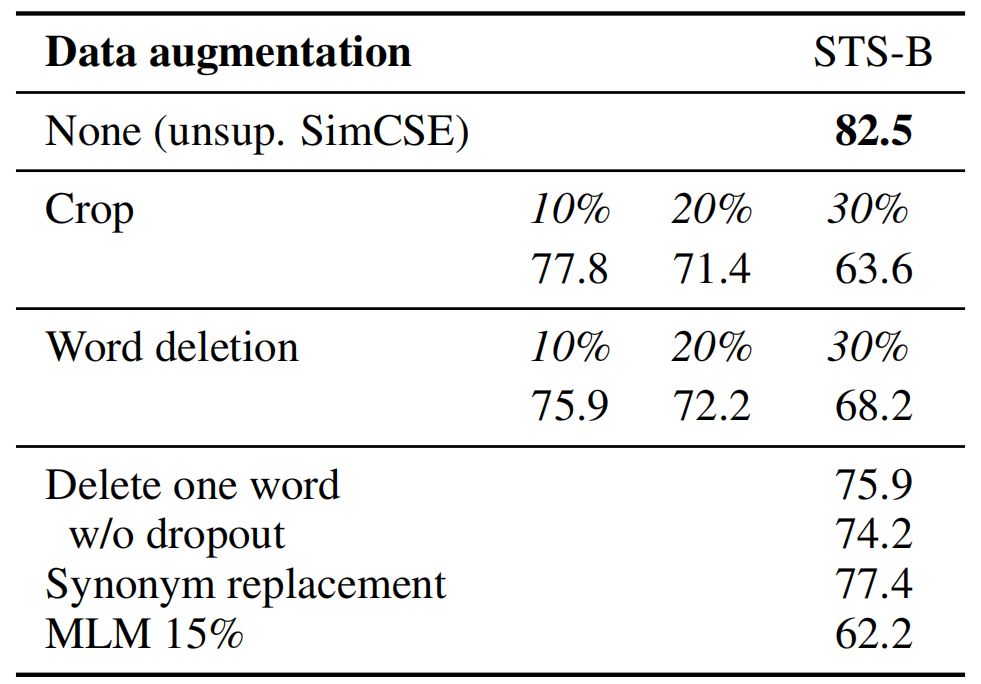
- _Crop k%_:keep (100-k)% of the length- _word deletion k%_:delete _k_% words- _Synonym replacement_: use `nlpaug` to randomly replace one word with its synonym- _MLM k%_:use BERT_base to replace _k_% of words.
- compare this self-prediction training objective(同一句子两次 dropout 视为 positive pair)to the next-sentence objective(将
(当前句,下一句)视为 positive pair)used in 【2018-00-00】An efficient framework for learning sentence representations(参见 ”0、背景介绍”), taking either one encoder or two independent encoders.
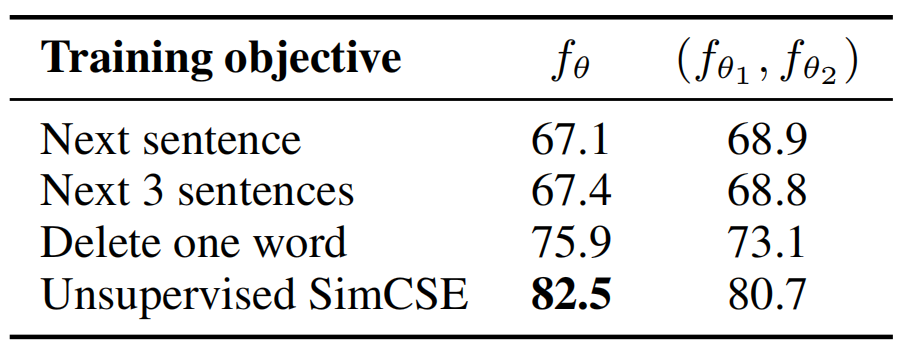
- The two columns denote whether we use one encoder or two independent encoders.
- _Next 3 sentences_:randomly sample one from the next 3 sentences.
- _Delete one word_:delete one word randomly
小结:Unsupervised SimCSE approach outperforms training objectives such as predicting next sentences and discrete data augmentation (e.g., word deletion and replacement) by a large margin, and even matches previous supervised methods.
(2)supervised SimCSE
不同 supervised datasets 的实验结果
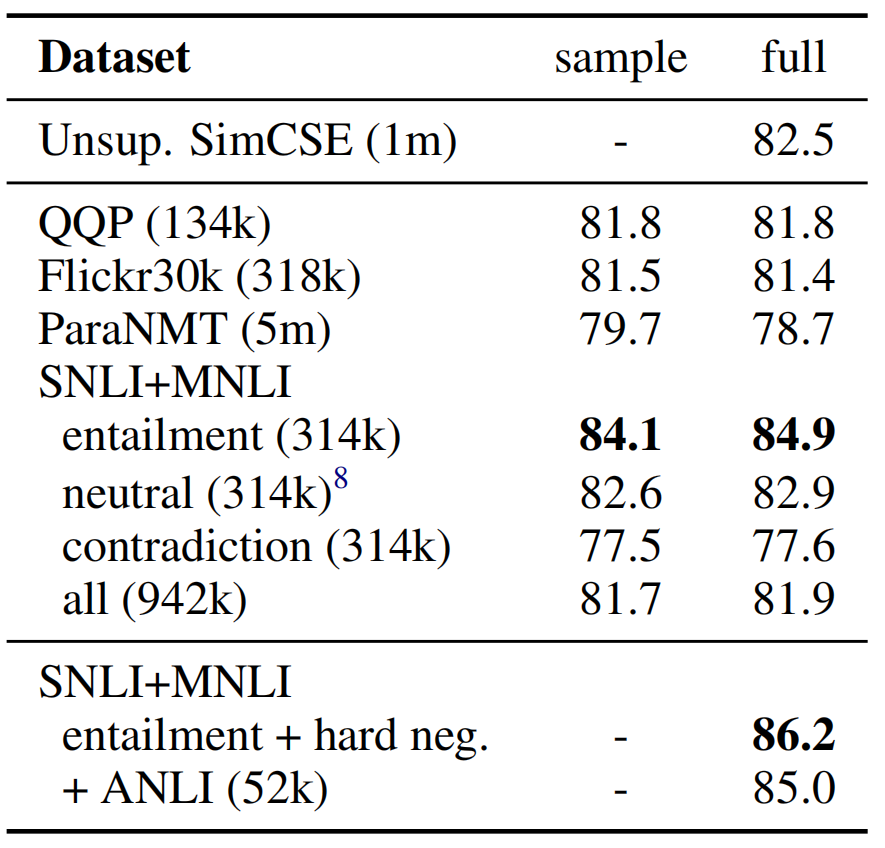
- Numbers in brackets denote the # of pairs.
- Sample:subsampling 134k positive pairs for a fair comparison among datasets
- full:using the full dataset.
- In the last block, we use entailment pairs as positives and contradiction pairs as hard negatives (our final model)
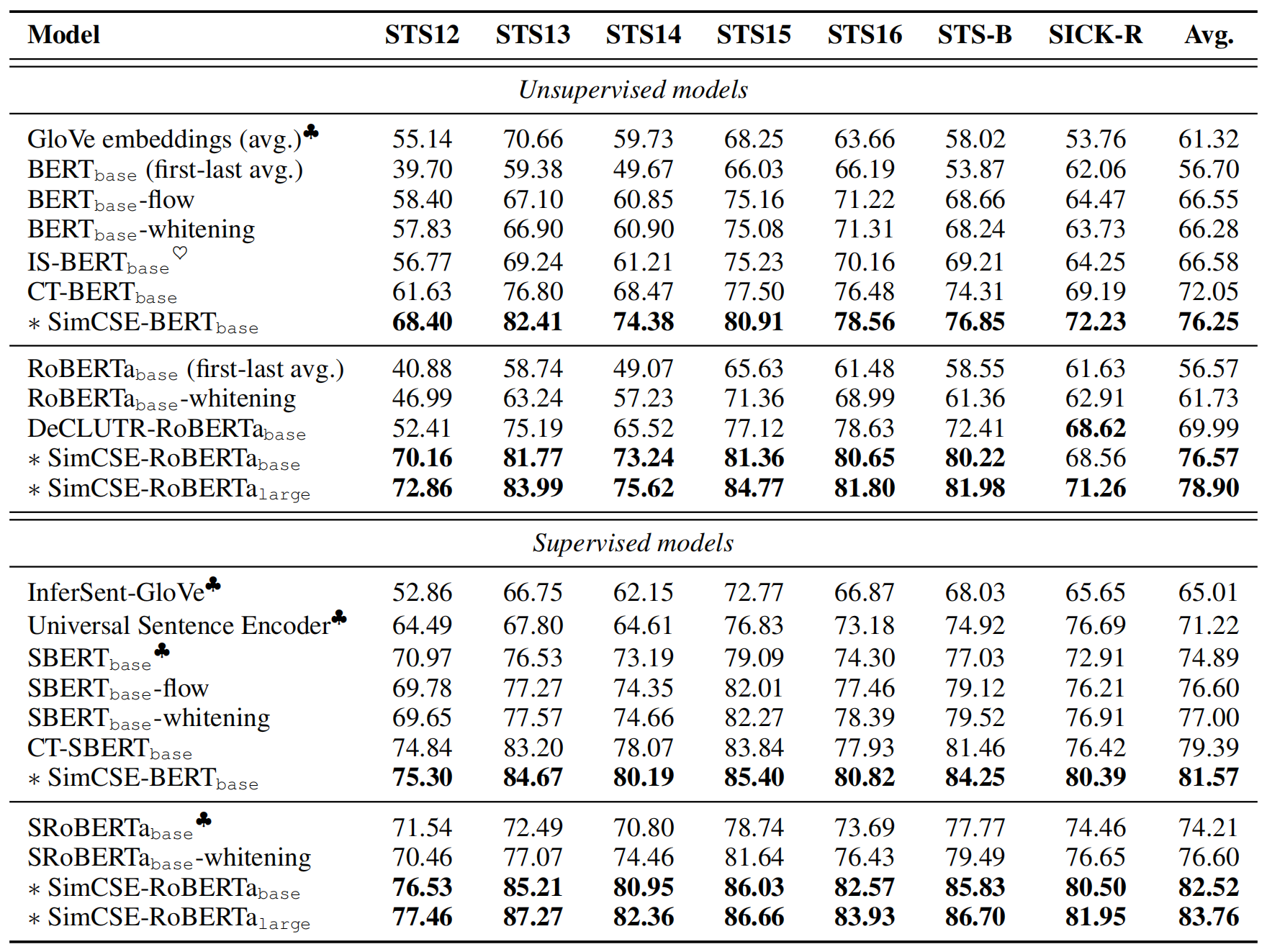
- ♣:【2019-11-03】Sentence-BERT:Sentence Embeddings using Siamese BERT-Networks
- ♥:【2020-11-16】An Unsupervised Sentence Embedding Method by Mutual Information Maximization
- post-processing methods
- BERT-flow:【2020-11-16】On the Sentence Embeddings from Pre-trained Language Models
- BERT-whitening:【2021-03-29】Whitening Sentence Representations for Better Semantics and Faster Retrieval
- recent methods using a contrastive objective
- IS-BERT(maximizes the agreement between global and local features)
- 【2020-11-16】An Unsupervised Sentence Embedding Method by Mutual Information Maximization
- DeCLUTR(takes different spans from the same document as positive pairs)
- 【2021-00-00】Semantic Re-tuning with Contrastive Tension
- CT(aligns embeddings of the same sentence from two different encoders)
- 【2021-00-00】Semantic Re-tuning with Contrastive Tension
- IS-BERT(maximizes the agreement between global and local features)
supervised
seven standard semantic textual similarity (STS) tasks(衡量指标:Spearman’s correlation):
- unsupervised:76.3%(+ 4.2%,compared to previous best results)
- supervised:81.6%(+ 2.2%,compared to previous best results)
transfer tasks(参见论文 Appendix E)
To further understand the role of dropout noise in unsupervised SimCSE, we try out different dropout rates and observe that all the variants underperform the default dropout probability p = 0_._1 from Transformers.
- Effects of different dropout probabilities _p _on the STS-B development set (Spearman’s correlation, BERT_base)
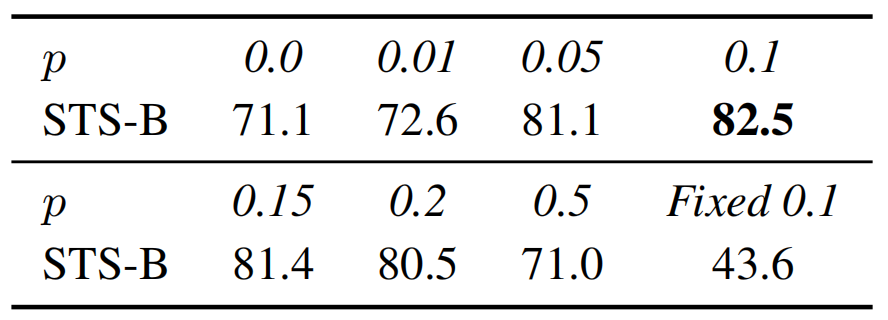
- Fixed 0.1: default 0.1 dropout rate but apply the same dropout mask on both
 and
and  .
. - two extreme cases particularly interesting:

For [CLS] representation, the original BERT implementation takes an extra MLP layer on top of it.
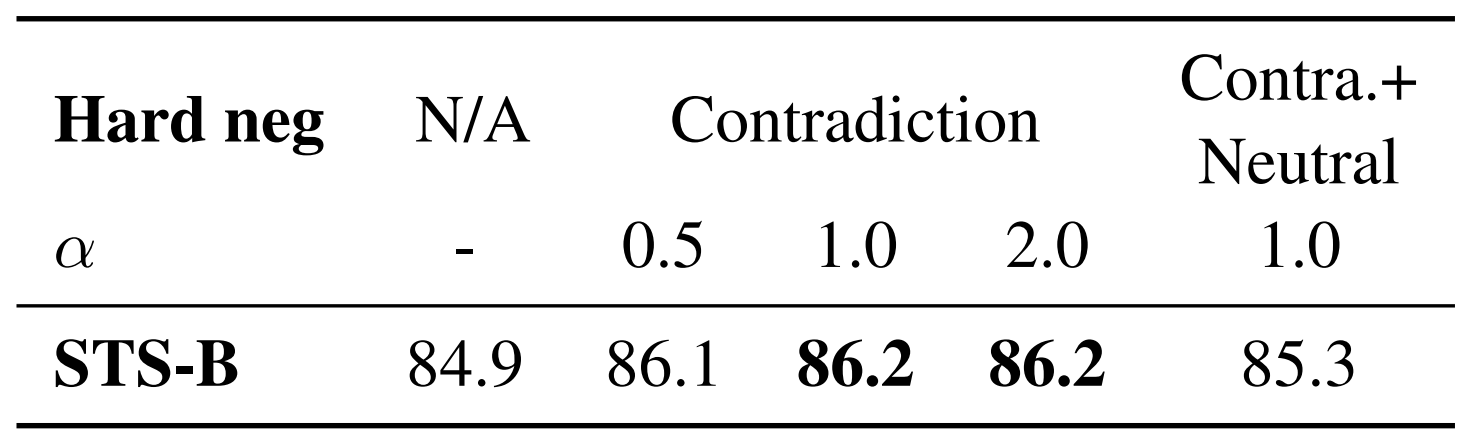
适当修改目标函数,设置 hard negatives 可考虑权重信息
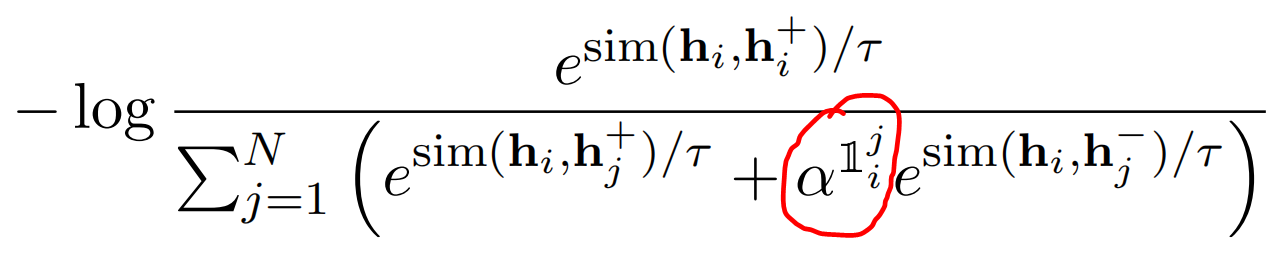
- 其中,红色圈中
 的上标为:an indicator that equals 1 if and only if
的上标为:an indicator that equals 1 if and only if  (即为 NLI 中的反例时才赋予相应的权重
(即为 NLI 中的反例时才赋予相应的权重 ),对权重取不同值进行实验,结果如下(权重为 1 时最佳,即等同于原目标函数);同时表明融入 NLI 中的 Neutral 样例并不能改善结果:
),对权重取不同值进行实验,结果如下(权重为 1 时最佳,即等同于原目标函数);同时表明融入 NLI 中的 Neutral 样例并不能改善结果:
(4)对 alignment 和 uniformity 指标进行可视化分析
- 对不同 dropout 策略的可视化结果进行分析(visualize checkpoints every 10 training steps and the arrows indicate the training direction)
- 下图中,两个维度上的结果,均为值越小越好(参见 “0、背景介绍”中的第 (3) 小结说明)
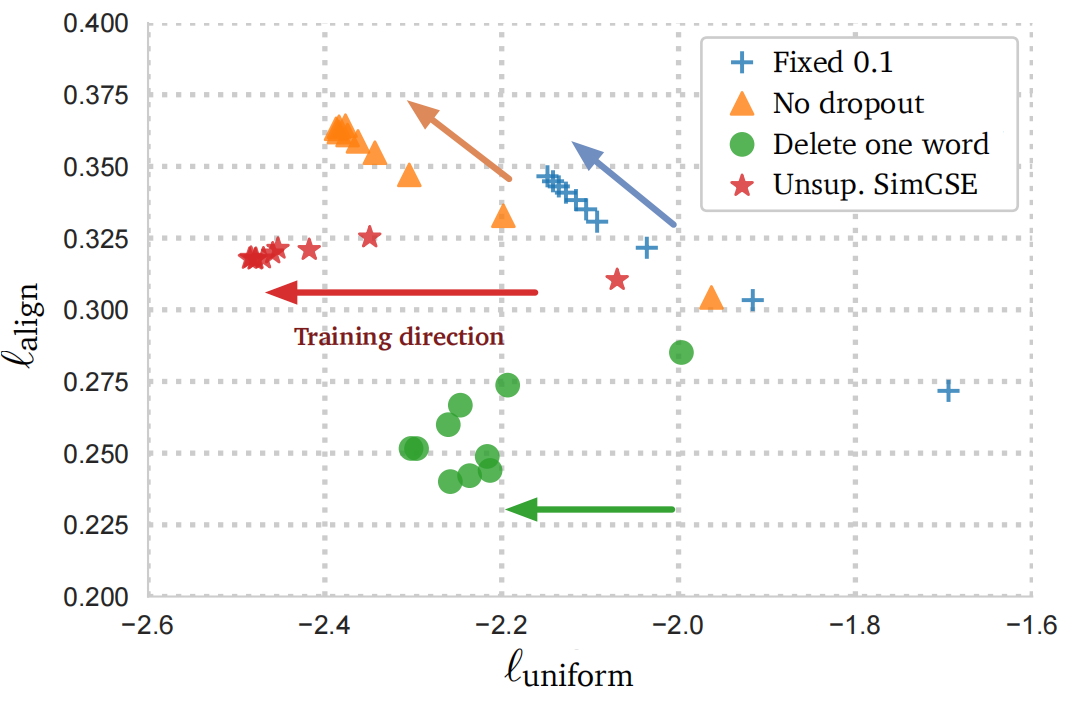
- 结果表明:
- starting from pre-trained checkpoints, all models greatly improve uniformity
- the alignment of the two special variants also degrades drastically, while our unsupervised SimCSE keeps a steady alignment(thanks to the use of dropout noise)
- “delete one word” improves the alignment yet achieves a smaller gain on the uniformity metric(即相似的句子相似度得分高,但与不相似的句子的区分度没那么大), and eventually underperforms unsupervised SimCSE.
(5)Anisotropy 分析
- 以下论文提出 language representations 中存在 anisotropy(各向异性_)_problem:the learned embeddings occupy a narrow cone in the vector space, which severely limits their expressiveness.
- 【2019-11-03】How Contextual are Contextualized Word Representations?Comparing the Geometry of BERT, ELMo, and GPT-2 Embeddings
- 【2020-11-16】On the Sentence Embeddings from Pre-trained Language Models
- Ways to alleviate the problem:
- postprocessing(BERT-flow、BERT-whitening)
- eliminate the dominant principal components
- map embeddings to an isotropic distribution
- add regularization during training
- postprocessing(BERT-flow、BERT-whitening)
- we show that(both theoretically and empirically)the contrastive objective can also alleviate the anisotropy problem.
- 【2020-00-00】Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere 中提到:The anisotropy problem is naturally connected to uniformity , both highlighting that embeddings should be evenly distributed in the space.
- Intuitively, optimizing the contrastive learning objective can improve uniformity (or ease the anisotropy problem), as the objective pushes negative instances apart.
we take a singular spectrum perspective(a common practice in analyzing word embeddings)and show that the contrastive objective can “flatten” the singular value distribution of sentence embeddings and make the representations more isotropic.
(4)小结
Find(theoretically and empirically)that:
- contrastive learning objective regularizes pre-trained embeddings’ anisotropic(相异性的)space to be more uniform,and it better aligns positive pairs when supervised signals are available.
- unsupervised SimCSE essentially improves uniformity while avoiding degenerated alignment via dropout noise, thus improving the expressiveness(表达能力)of the representations.
- the NLI training signal can further improve alignment between positive pairs and produce better sentence embeddings.
We also draw a connection to the recent findings that pre-trained word embeddings suffer from anisotropy and prove that(through a spectrum perspective):
- the contrastive learning objective “flattens” the singular value distribution of the sentence embedding space, hence improving uniformity.
- pre-trained word embeddings suffer from anisotropy 可参考以下两篇论文:
we identify an incoherent evaluation issue(参见论文 6.1 章节、Appendix B)in the literature and consolidate results of different settings for future work in evaluation of sentence embeddings.

若有收获,就点个赞吧
0 人点赞
