- 1、基本介绍
- 2、安装 & 使用
- Install required packages
- jy: 注意, 该包在 python3 中安装后不能正常导入(仍为 python2 的格式); 但不影响后续的使用;
- 如果发现有影响, 则安装 python3 版本对应的该包: pip install mcerp3 , 安装后, 可以导
- 入: import mcerp3; (如果发现项目中代码使用到, 则将相应的 mcerp 替换为 mcerp3 即可)
- jy: 下载源代码;
- LASER will not overwrite an embedding file if it exsts, so you may
- need to run first:
- 3、参考
1、基本介绍
- 论文:【2019-11-03】Vecalign:Improved Sentence Alignment in Linear Time and Space
- Vecalign is an accurate sentence alignment algorithm which is fast even for very long documents. In conjunction with LASER, Vecalign works in about 100 languages (i.e. 100^2 language pairs), without the need for a machine translation system or lexicon.
- Vecalign uses similarity of multilingual sentence embeddings to judge the similarity of sentences.
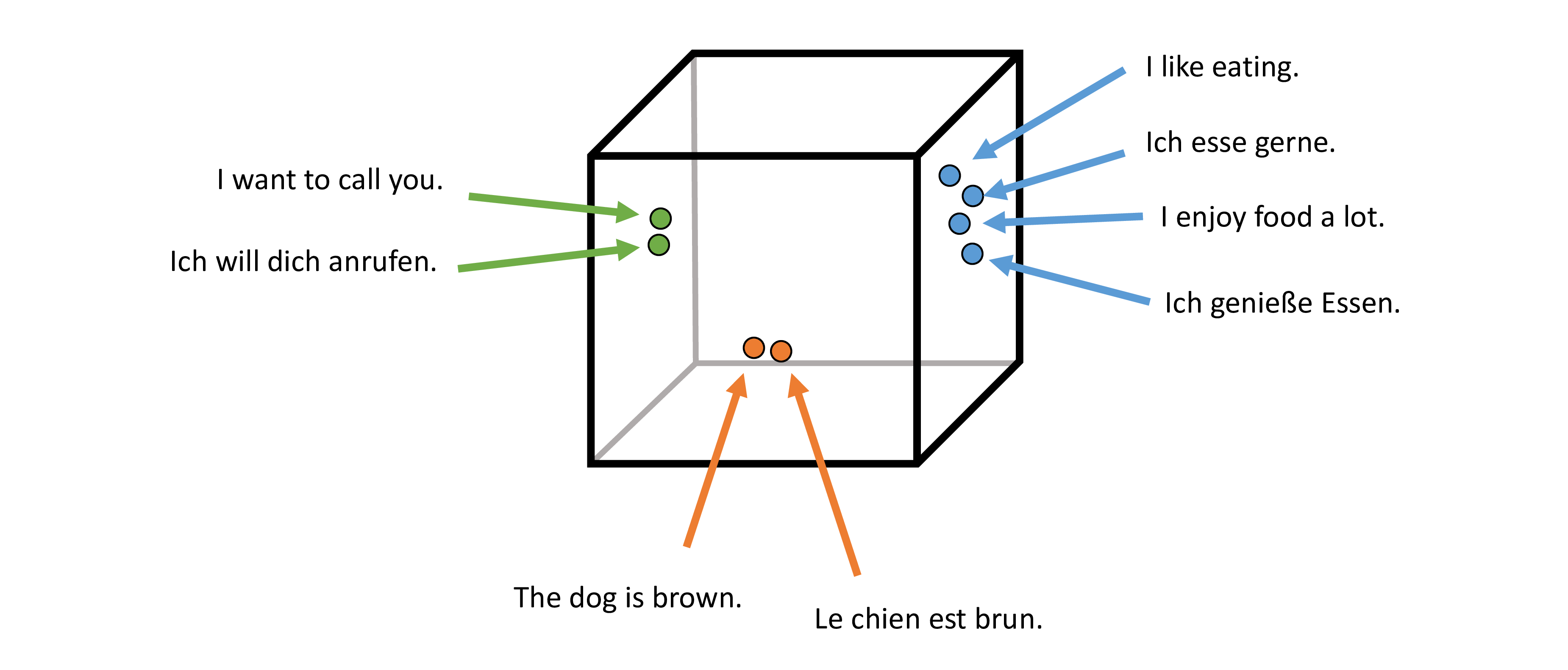
- Vecalign uses an approximation to Dynamic Programming based on Fast Dynamic Time Warping which is linear in time and space with respect to the number of sentences being aligned.
- Fast Dynamic Time Warping:【2014-07-29】FastDTW:Toward Accurate Dynamic Time Warping in Linear Time and Space

2、安装 & 使用
1)安装
- You will need python 3.6+ with numpy and cython.
- Note that Vecalign contains cython code, but there is no need to build it manually as it is compiled automatically by pyximport.
- pyximport:https://github.com/cython/cython/tree/master/pyximport ```shell conda create —force -y —name jy_vecalign python=3.7 conda activate jy_vecalign
Install required packages
conda install -y -c anaconda cython conda install -y -c anaconda numpy
jy: 注意, 该包在 python3 中安装后不能正常导入(仍为 python2 的格式); 但不影响后续的使用;
如果发现有影响, 则安装 python3 版本对应的该包: pip install mcerp3 , 安装后, 可以导
入: import mcerp3; (如果发现项目中代码使用到, 则将相应的 mcerp 替换为 mcerp3 即可)
pip install mcerp
jy: 下载源代码;
git clone https://github.com/thompsonb/vecalign.git cd vecalign
<a name="ijBhy"></a>## 2)使用<a name="kk6re"></a>### (1)Run Vecalign (using provided embeddings)```shell./vecalign.py --alignment_max_size 8 \--src bleualign_data/dev.de \--tgt bleualign_data/dev.fr \--src_embed bleualign_data/overlaps.de bleualign_data/overlaps.de.emb \--tgt_embed bleualign_data/overlaps.fr bleualign_data/overlaps.fr.emb
- Alignments are written to stdout: ```shell
[6]:[6, 7, 8]:0.507506
[8, 9]:[10, 11, 12]:0.139594
[13]:[15, 16, 17]:0.436312 [14]:[18, 19, 20, 21]:0.734142 []:[22]:0.000000 []:[23]:0.000000 []:[24]:0.000000 []:[25]:0.000000 [15]:[26, 27, 28]:0.840094 …
- The first two entries are the source and target sentence indexes for each alignment, respectively. The third entry in each line is the sentence alignment cost computed by Vecalign.
- Note that:
- This cost includes normalization but does _not_ include the penalties terms for containing more than one sentence.
- The alignment cost is set to zero for insertions/deletions.
- The results may vary slightly due to randomness in the normalization.
- To score against a gold alignment, use the `-g` flag. Flags `-s`, `-t`, and `-g` can accept multiple arguments. This is primarily useful for scoring, as the output alignments will all be concatenated together in stdout.
- For example, to align and score the bleualign test set:
```shell
./vecalign.py --alignment_max_size 8 \
--src bleualign_data/test*.de \
--tgt bleualign_data/test*.fr \
--gold bleualign_data/test*.defr \
--src_embed bleualign_data/overlaps.de bleualign_data/overlaps.de.emb \
--tgt_embed bleualign_data/overlaps.fr bleualign_data/overlaps.fr.emb > /dev/null
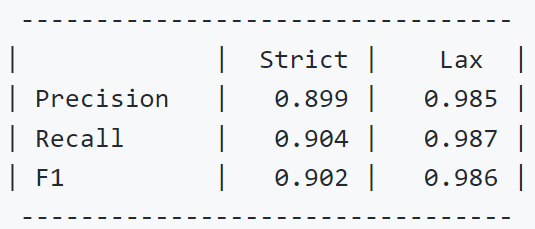
- Which should give you results that approximately match the Vecalign paper:
- Run
./vecalign.py -hfor full sentence alignment usage and options. For stand-alone scoring against a gold reference, seescore.py - vecalign.py 各参数解析(JY:个别表述不清晰): ```shell usage: Sentence alignment using sentence embeddings and FastDTW
optional arguments: -h, —help show this help message and exit -s SRC [SRC …], —src SRC [SRC …] preprocessed source file to align (default: None) -t TGT [TGT …], —tgt TGT [TGT …] preprocessed target file to align (default: None) -g GOLD_ALIGNMENT [GOLD_ALIGNMENT …], —gold_alignment GOLD_ALIGNMENT [GOLD_ALIGNMENT …] preprocessed target file to align (default: None) —src_embed SRC_EMBED SRC_EMBED Source embeddings. Requires two arguments: first is a text file, sencond is a binary embeddings file. (default: None) —tgt_embed TGT_EMBED TGT_EMBED Target embeddings. Requires two arguments: first is a text file, sencond is a binary embeddings file. (default: None) -a ALIGNMENT_MAX_SIZE, —alignment_max_size ALIGNMENT_MAX_SIZE Searches for alignments up to size N-M, where N+M <= this value. Note that the the embeddings must support the requested number of overlaps (default: 4) -d DEL_PERCENTILE_FRAC, —del_percentile_frac DEL_PERCENTILE_FRAC Deletion penalty is set to this percentile (as a fraction) of the cost matrix distribution. Should be between 0 and 1. (default: 0.2) -v, —verbose sets consle to logging.DEBUG instead of logging.WARN (default: False) —max_size_full_dp MAX_SIZE_FULL_DP Maximum size N for which is is acceptable to run full N^2 dynamic programming. (default: 300) —costs_sample_size COSTS_SAMPLE_SIZE Sample size to estimate costs distribution, used to set deletion penalty in conjunction with deletion_percentile. (default: 20000) —num_samps_for_norm NUM_SAMPS_FOR_NORM Number of samples used for normalizing embeddings (default: 100) —search_buffer_size SEARCH_BUFFER_SIZE Width (one side) of search buffer. Larger values makes search more likely to recover from errors but increases runtime. (default: 5) —debug_save_stack DEBUG_SAVE_STACK Write stack to pickle file for debug purposes (default: None)
<a name="iShFk"></a>
### (2)Embed your own documents
- The Vecalign repository contains overlap and embedding files for the Bluealign dev/test files. This section shows how those files were made, as an example for running on new data.
- Vecalign requires not only embeddings of sentences in each document, but also embeddings of _concatenations_ of consecutive sentences. The embeddings of multiple, consecutive sentences are needed to consider 1-many, many-1, and many-many alignments.
- To create a file containing all the sentence combinations in the dev and test files from Bleualign:
- Note: Run `./overlap.py -h` to see full set of embedding options.
```shell
./overlap.py -i bleualign_data/dev.fr bleualign_data/test*.fr -o bleualign_data/overlaps.fr -n 10
./overlap.py -i bleualign_data/dev.de bleualign_data/test*.de -o bleualign_data/overlaps.de -n 10
bleualign_data/overlaps.frandbleualign_data/overlaps.deare text files containing one or more sentences per line.overlap.py 参数解析
optional arguments: -h, --help show this help message and exit -i INPUTS [INPUTS ...], --inputs INPUTS [INPUTS ...] input text file(s). (default: None) -o OUTPUT, --output OUTPUT output text file containing overlapping sentneces (default: None) -n NUM_OVERLAPS, --num_overlaps NUM_OVERLAPS Maximum number of allowed overlaps. (default: 4)These files must then be embedded using a multilingual sentence embedder.
- We recommend the Language-Agnostic SEntence Representations (LASER) toolkit from Facebook, as it has strong performance and comes with a pretrained model which works well in about 100 languages. However, Vecalign should also work with other embedding methods as well. Embeddings should be provided as a binary file containing float32 values.
- To embed the Bleualign files using LASER(需安装并设置相应环境变量):
```shell
LASER will not overwrite an embedding file if it exsts, so you may
need to run first:
rm bleualign_data/overlaps.fr.emb bleualign_data/overlaps.de.emb
$LASER/tasks/embed/embed.sh \ bleualign_data/overlaps.fr bleualign_data/overlaps.fr.emb [ISO-3 lang_code] $LASER/tasks/embed/embed.sh \ bleualign_data/overlaps.de bleualign_data/overlaps.de.emb [ISO-3 lang_code] ```
(3)Document Alignment
- We propose using Vecalign to rescore document alignment candidates, in conjunction with candidate generation using a document embedding method that retains sentence order information.
- 参考论文:【2020-11-16】Exploiting Sentence Order in Document Alignment
Example code for our document embedding method:
standalone_document_embedding_demo.py3、参考
官方 github:https://github.com/thompsonb/vecalign

若有收获,就点个赞吧
0 人点赞
