0、背景介绍
- Sentence alignment is the task of taking parallel documents(which have been split into sentences)and finding a bipartite graph(二分图)which matches minimal groups of sentences that are translations of each other.
- Sentence alignment takes sentences
 and
and and locates minimal groups of sentences which are translations of each other, in this case:
and locates minimal groups of sentences which are translations of each other, in this case:




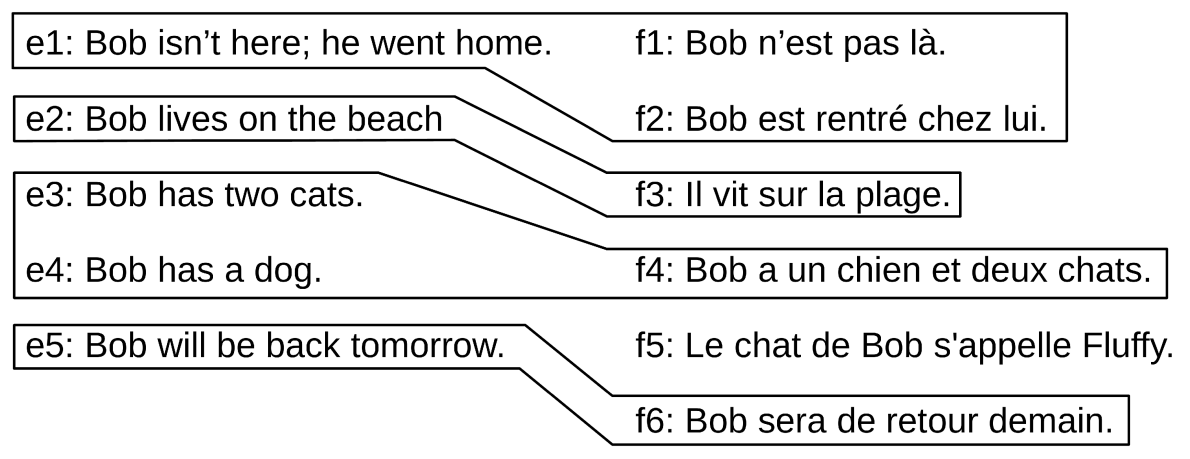
- Sentence-aligned bitext is used to train nearly all machine translation (MT) systems. Alignment errors have been noted to have a small effect on statistical MT performance(【2012-00-00】The impact of sentence alignment errors on phrase-based machine translation performance), However, misaligned sentences have been shown to be much more detrimental to neural MT (NMT)(【2018-07-20】On the Impact of Various Types of Noise on Neural Machine Translation)
- Automatic sentence alignment can be roughly decomposed into two parts:
- A score function which takes one or more adjacent source sentences and one or more adjacent target sentences and returns a score indicating the likelihood that they are translations of each other.
- An alignment algorithm which, using the score function above, takes in two documents and returns a hypothesis alignment.
We improve both parts, presenting:
- A novel scoring function based on normalized cosine distance between multilingual sentence embeddings.
- A novel application of a dynamic programming approximation which makes our algorithm linear in time and space complexity with respect to the number of sentences being aligned.
Early sentence aligners use scoring functions based only on the number of words or characters in each sentence and alignment algorithms based on dynamic programming(DP).
- DP is
 time complexity, where
time complexity, where and
and are the number of sentences in the source and target documents.
are the number of sentences in the source and target documents.
- DP is
- Later work added lexical features and heuristics to speed up search, such as limiting the search space to be near the diagonal.
More recent work introduced scoring methods that use MT to get both documents into the same language (Bleualign) or use pruned phrase tables from a statistical MT system (Coverage-Based). Both methods “anchor” high-probability 1–1 alignments in the search space and then fill in and refine alignments. Locating anchors is
 time complexity.
time complexity.
1、方法介绍
Assume non-crossing alignments but allow local sentence reordering within an alignment.
Vecalign:a novel bilingual sentence alignment method which is linear in time and space with respect to the number of sentences being aligned and which requires only bilingual sentence embeddings.
- based on similarity of sentence embeddings and a DP approximation which is fast even for long documents.
- A distinct but non-obvious advantage of sentence embeddings is that blocks of sentences can be represented as the average of their sentence embeddings.
- The size of the resulting vector is not dependent on the number of sentence embeddings being averaged, thus the time/space cost of comparing the similarity of blocks of sentences does not depend on the number of sentences being compared.
- We show empirically that average embeddings for blocks of sentences are sufficient to produce approximate alignments, even in low-resource languages. This enables us to approximate DP in
 in time and space.
in time and space.
(1)Bilingual Sentence Embeddings
Use the publicly available LASER multilingual sentence embedding method and model(which is pretrained on 93 languages)
Cosine similarity is an obvious choice for comparing embeddings but has been noted to be globally inconsistent due to “hubness”. 参考:
- 【2010-10-09】Hubs in Space:Popular Nearest Neighbors in High-Dimensional Data
- 【2015-00-00】Hubness and Pollution:Delving into Cross-Space Mapping for Zero-Shot Learning
- 解决 hubness 的方案:
- supervised training approach for calibration
- 【2018-11-01】Effective Parallel Corpus Mining using Bilingual Sentence Embeddings
- normalization using nearest neighbors
- 【2019-08-07】Margin-based Parallel Corpus Mining with Multilingual Sentence Embeddings
- 本文提出:normalizing instead with randomly_ _selected embeddings as it has linear complexity.
- supervised training approach for calibration
- Sentence alignment seeks minimal_ _parallel units, but we find that DP with cosine similarity favors many-to-many alignments (e.g. reporting a 3–3 alignment when it should report three 1–1 alignments).
- To remedy this issue, we scale the cost by the number of source and target sentences being considered in a given alignment.
- Our resulting scoring cost function is:

 denote one or more sequential sentences from the source/target document.
denote one or more sequential sentences from the source/target document. :cosine similarity between embeddings of
:cosine similarity between embeddings of
 和
和 :the number of sentences in
:the number of sentences in
 和
和 :sampled uniformly from the given document
:sampled uniformly from the given document
Following standard practice, we model insertions and deletions in DP using a skip cost:

- The raw value of
 is only meaningful when compared to other costs, thus we do not expect it to generalize across different languages, normalizations, or resolutions.
is only meaningful when compared to other costs, thus we do not expect it to generalize across different languages, normalizations, or resolutions. - We propose specifying instead a parameter
 which defines the skip cost in terms of the distribution of 1–1 alignment costs at alignment time:
which defines the skip cost in terms of the distribution of 1–1 alignment costs at alignment time:
- The raw value of
Instead of searching all possible sentence alignments via DP, consider first averaging adjacent pairs of sentence embeddings in both the source and target documents, halving the number of embeddings for each document.
- Aligning these vectors via DP (each of which are averages of 2 sentence embeddings) produces an _approximate _sentence alignment, at a cost of
 comparisons.
comparisons. - We can then refine this approximate alignment using the original sentence vectors, constraining ourselves to a small window around the approximate alignment.
- At a minimum, we must search a window size
 (默认为 10)large enough to consider all paths covered by the lower-resolution alignment path, but
(默认为 10)large enough to consider all paths covered by the lower-resolution alignment path, but can also be increased to allow recovery from small errors in the approximate alignment.
can also be increased to allow recovery from small errors in the approximate alignment.- The length of the refinement path to search is at most
 (all deletions/insertions), so re-fining the path requires at most
(all deletions/insertions), so re-fining the path requires at most comparisons.
comparisons. - Thus the full
 comparisons can be approximated by
comparisons can be approximated by
- Applied recursively, we can approximate our quadratic
 cost with a sum of linear costs:
cost with a sum of linear costs:
- The length of the refinement path to search is at most


- In practice, we compute the full DP alignment once the down sampled sizes are below an acceptably small constant. We also find vectors for large blocks of sentences become correlated with each other, so we center them around **0**.
- Illustration of this method:1–1 alignment costs (darker = lower) for the first 88 De lines (x-axis) and 128 Fr lines (y-axis) at 4 different resolutions(Window size is increased for visualization purposes):
- The red highlight denotes alignment found by DP.
- The algorithm only searches near the path found at previous resolutions, light blue regions are excluded.
- The vertical part of the path in the top left of each plot is due to 36 extra lines being present in the Fr document.
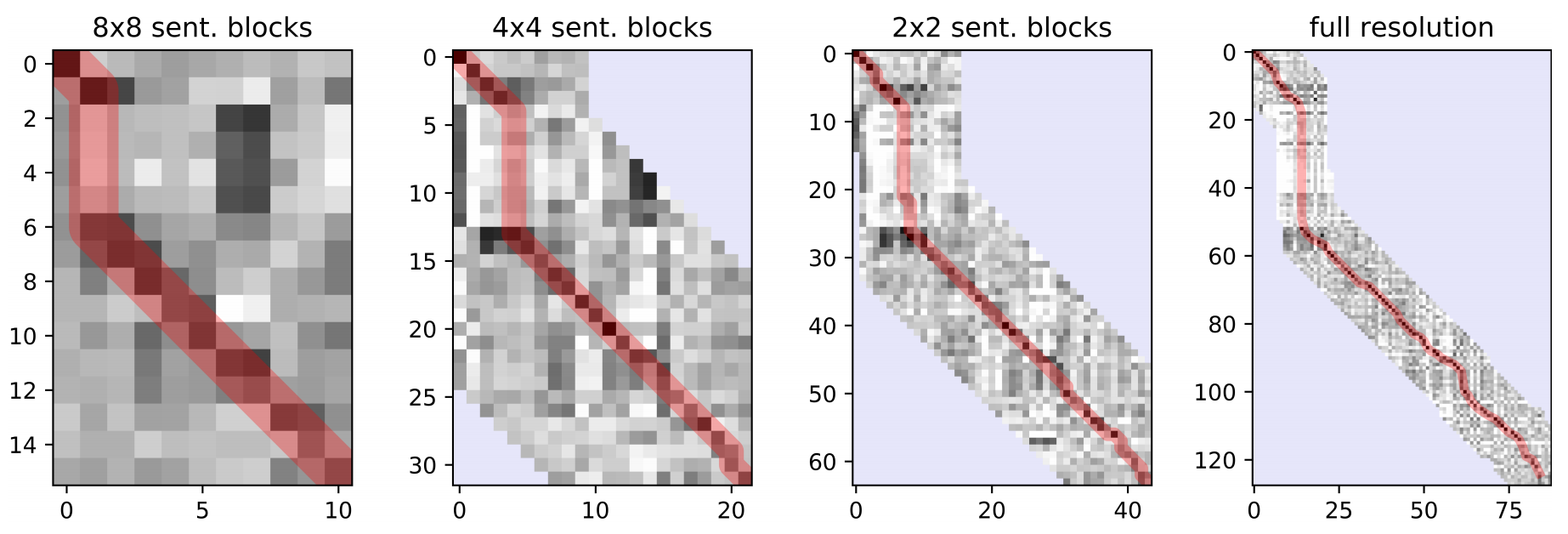
- We consider only insertions, deletions, and 1–1 alignments in all but the final search.
Recursive down sampling and refining of DP was proposed for dynamic time warping in (【2007-00-00】Toward accurate dynamic time warping in linear time and space), but has not previously been applied to sentence alignment. We direct the reader to that work for a more formal analysis showing the time/space complexity is linear.
2、实验结果
On a standard German–French test set, Vecalign outperforms the previous state-of-the-art method(which has quadratic time complexity and requires a machine translation system)by 5 F1 points.
- Indicating that our proposed score function outperforms prior work and the approximations we make in alignment are sufficiently accurate.
- It substantially outperforms the popular Hunalign toolkit at recovering Bible verse alignments in medium- to low-resource language pairs, and it improves downstream MT quality by 1.7 and 1.6 BLEU in Sinhala→_English and Nepali→_English, respectively, compared to the Hunalign-based Paracrawl pipeline.
- Our method has state-of-the-art accuracy in high and low resource settings and improves downstream MT quality.
- 【2019-11-03】Vecalign:Improved Sentence Alignment in Linear Time and Space
- 【2020-11-16】Exploiting Sentence Order in Document Alignment

若有收获,就点个赞吧
0 人点赞
