1、介绍、安装
(1)基本介绍
Scikit-learnis an open source machine learning library that supports supervised and unsupervised learning. It also provides various tools for model fitting, data preprocessing, model selection, model evaluation, and many other utilities.- It assumes a very basic working knowledge of machine learning practices (model fitting, predicting, cross-validation, etc.).
(2)安装
```shelljy: 创建 python-3.9.0 虚拟环境并激活(如有可用虚拟环境, 可跳过这一步)
conda create —name jy-env_py39 python==3.9.0 conda activate jy-env_py39
jy: -U / —upgrade 表示更新至最新;
pip install -U scikit-learn
jy: 查看包版本
pip show scikit-learn
jy: 查看虚拟环境下已安装的包
pip freeze
jy: 查看 sklearn 包以及相关依赖包的版本;
python -c “import sklearn; sklearn.show_versions()”
<a name="PdC5Z"></a>## (3)环境依赖说明- Scikit-learn plotting capabilities (i.e., functions start with "plot_" and classes end with "Display") require Matplotlib. The examples require Matplotlib and some examples require scikit-image, pandas, or seaborn. The minimum version of Scikit-learn dependencies are listed below along with its purpose.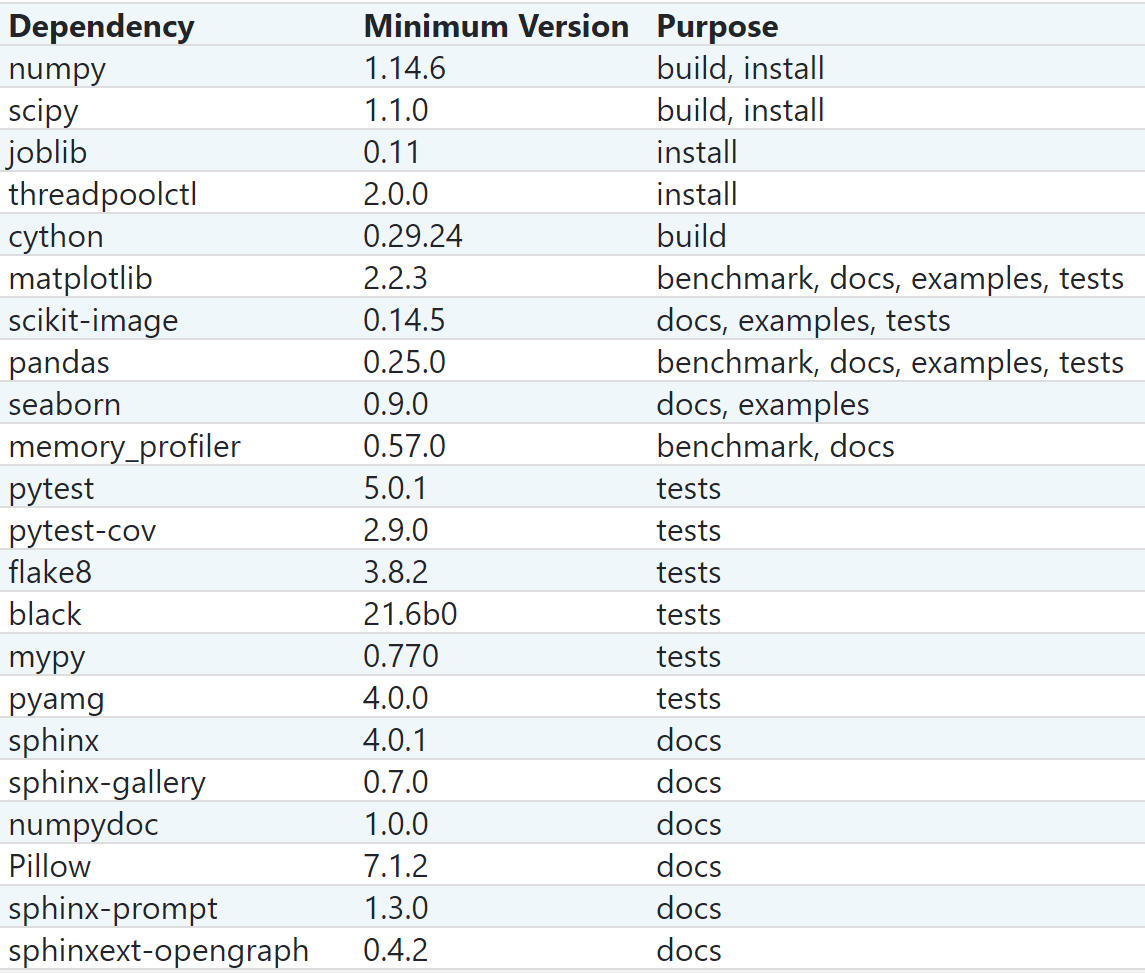- **Warning**- Scikit-learn 0.20 was the last version to support Python 2.7 and Python 3.4.- Scikit-learn 0.21 supported Python 3.5-3.7.- Scikit-learn 0.22 supported Python 3.5-3.8.- Scikit-learn 0.23 - 0.24 require Python 3.6 or newer.- Scikit-learn 1.0 and later requires Python 3.7 or newer.- **Note:**For installing on PyPy, PyPy3-v5.10+, Numpy 1.14.0+, and scipy 1.1.0+ are required.<a name="reA4C"></a># 2、使用示例- This guide should give you an overview of some of the main features of the library, including estimator fitting and predicting, pre-processing steps, pipelines, cross-validation tools and automatic hyper-parameter searches.<a name="FQs67"></a>## (1)Fitting and predicting: estimator basics- `Scikit-learn` provides dozens of built-in machine learning algorithms and models, called `estimators`. Each estimator can be fitted to some data using its `fit` method.- `estimators`- [https://scikit-learn.org/stable/glossary.html#term-estimators](https://scikit-learn.org/stable/glossary.html#term-estimators)- `fit`- [https://scikit-learn.org/stable/glossary.html#term-fit](https://scikit-learn.org/stable/glossary.html#term-fit)- The `fit` method generally accepts 2 inputs:- The samples matrix (or design matrix) `X`. The size of `X` is typically `(n_samples, n_features)`, which means that samples are represented as rows and features are represented as columns.- The target values `y` which are real numbers for regression tasks, or integers for classification (or any other discrete set of values). For unsupervized learning tasks, `y` does not need to be specified. `y` is usually 1d array where the `i-th` entry corresponds to the target of the `i-th` sample (row) of `X`.- Once the estimator is fitted, it can be used for predicting target values of new data. You don’t need to re-train the estimator.```pythonfrom sklearn.ensemble import RandomForestClassifierclf = RandomForestClassifier(random_state=0)# jy: 2 samples, 3 featuresX = [[ 1, 2, 3],[11, 12, 13]]# jy: classes of each sampley = [0, 1]clf.fit(X, y)# jy: predict classes of the training datares_1 = clf.predict(X)# jy: [0, 1]print(res_1)# jy: predict classes of new datares_2 = clf.predict([[4, 5, 6], [14, 15, 16]])# jy: [0, 1]print(res_2)
(2)Transformers and pre-processors
- Machine learning workflows are often composed of different parts. A typical pipeline consists of a pre-processing step that transforms or imputes the data, and a final predictor that predicts target values.
In
scikit-learn, pre-processors and transformers follow the same API as the estimator objects (they actually all inherit from the sameBaseEstimatorclass). The transformer objects don’t have apredictmethod but rather atransformmethod that outputs a newly transformed sample matrixX:predicttransform- https://scikit-learn.org/stable/glossary.html#term-transform
from sklearn.preprocessing import StandardScaler X = [[0, 15], [1, -10]] # scale data according to computed scaling values res = StandardScaler().fit(X).transform(X) # jy: ''' [[-1. 1.] [ 1. -1.]] ''' print(res) # jy: numpy.ndarray print(type(res))
- https://scikit-learn.org/stable/glossary.html#term-transform
Sometimes, you want to apply different transformations to different features: the
ColumnTransformeris designed for these use-cases.ColumnTransformer- https://scikit-learn.org/stable/modules/compose.html#column-transformer
(3)Pipelines: chaining pre-processors and estimators
undo
- https://scikit-learn.org/stable/modules/compose.html#column-transformer
(4)Model evaluation
(5)Automatic parameter searches
3、参考链接

若有收获,就点个赞吧
0 人点赞
