7.2.1 联邦学习
7.2.1.1 京东联合建模
在与京东合作发卡过程中,联合建模场景下,可获取客户如下京东数据字段:
- 收入等级
1:低, 2.中低, 3.中,4.中上,5,高,-9999:无法预测;N:未查得 - 职业预测
1:公务员,2:医院,3:教育,4:服务业,5:白领,6:蓝领,7:金融,-1:无数据 - 伪冒风险
1:是,0:否;N:未查得 - 网购网龄
1-4 值越大网龄越长,-1-无 - 网购付费意愿
1:是,0:否;N:未查得 - 有车指数
1:高;2:中高;3:中等;4:中低;5:低;-9999:无法预测 ;N:未查得 - 有房指数
1:高;2:中高;3:中等;4:中低;5:低;-9999:无法预测;N:未查得 - 有孩概率
1:有小孩 ;-9999:未知 ;N:未查得 - 综合购买力
1 高;2 中;3 低;-9999:无法预测 ;N:未查得 - 促销敏感度
0-6,值越大,越容易被促销活动吸引 N:未差得 - 消费偏好
1.服饰内衣,2:家电厨房,3:3C产品,4:生活用品,5:个护化妆,6:户外运动,7:母婴用品,8:图书音像,9:汽车相关,10:旅游出行,11:宠物饲养,12:珠宝首饰,13:其他品类, - 网购消费偏好指数-长期
0~10,数值越高,消费能力越强,长期期网购频次越高 - 网购消费能力指数-长期
0~10,数值越高,消费能力越强,长期期网购金额越高 - 网购消费偏好指数-中长期
0~10,数值越高,消费意愿越强,中长期网购频次越高 - 网购消费偏好指数-中期
0~10,数值越高,消费意愿越强,中期网购频次越高 - 常用地址稳定性
1:非常稳定;2:比较稳定;3:不稳定;-9999:无法判断 ;N:未查得 - 常用手机稳定性
1:非常稳定;2:比较稳定;3:不稳定;-9999:无法判断;N:未查得 - 菁卡综合评分
300~1000 ; N:未查得 - 白条逾期指数
1-7,数值越高,逾期越严重;N:未查得 - 白条账龄
1-6,数值越大账龄越长,N:未查得; - 白条分期指数
0-11,数值越大分期频率越高,N:未差得 - 财富等级
1:高;2:中,3:低;-1:无数据 - 信用消费偏好指数-长期
0~10,数值越高,信用消费意愿越强,长期信用消费频次越高 - 信用消费能力指数-长期
0~10,数值越高,信用消费能力越强,长期期信用消费金额越高 - 信用消费偏好指数-中长期
0~10,数值越高,信用消费意愿越强,中长期信用消费频次越高 - 信用消费偏好指数-中期
0~10,数值越高,信用消费意愿越强,中期信用消费频次越高 - 风险等级
1:低, 2.中低, 3.中,4.中上,5,高, -1:无数据 - 多头等级
1:非多头, 2:轻微多头, 3:一般多头,4:较严重多头,5:严重多头, -1:无数据 - 支付偏好指数
0~10,数值越高,信用卡支付频次越高 - 常驻城市等级
1:1线城市,2:新一线城市,3:二线城市,4:三线及其他,-1:无数据 - 网购等级
1:高;2:中,3:低;-1:无数据 - 信用卡支付指数
0~10,数值越高,信用卡支付金额越高 - 付费分期指数
0~10,数值越高,近半年操作白条付费分期的金额越多 - 付费分期偏好度
0~10,数值越高,近半年使用白条付费分期的次数越多 - 信用分期月度指数
0~10,数值越高,近半年使用白条分期的次数越多 - 网购消费能力指数-中期
0~10,数值越高,消费能力越强,中期网购金额越高 - 网购消费能力指数-中长期
0~10,数值越高,消费能力越强,中长期网购金额越高 - 网购消费能力指数-长期
0~10,数值越高,消费能力越强,长期期网购金额越高 - 网购消费偏好指数-短期
0~10,数值越高,消费意愿越强,短期网购频次越高 - 网购消费能力指数-短期
0~10,数值越高,消费能力越强,短期网购金额越高 - 微信支付偏好指数
0~10,数值越高,微信支付频次越高 - 微信支付指数
0~10,数值越高,微信支付金额越高 - 信用分期偏好度
0~10,数值越高,近半年操作白条分期的金额越多 - 信用消费月度指数
0~6,数值越高,近半年使用白条的月份数越多 - 信用消费能力指数-长期
0~10,数值越高,信用消费能力越强,长期期信用消费金额越高 - 信用消费能力指数-短期
0~10,数值越高,信用消费能力越强,短期信用消费金额越高 - 信用消费能力指数-中期
0~10,数值越高,信用消费能力越强,中期信用消费金额越高 - 信用消费能力指数-中长期
0~10,数值越高,信用消费能力越强,中长期信用消费金额越高 - 全部有过还款的用户
1:是;0:否 - 移动设备稳定性
1:低,2:中, 3:高,-1:无数据 ,数值越高,稳定性越差 - 移动设备等级
1:低,2:中, 3:中高,4:高-1:无数据 ,等级越高,设备的价格越高 - 交易活跃度
0:不活跃,1:低活跃, 2:中等活跃, 3:较活跃,4:活跃 -1:无数据 - 交易多样性
1:低, 2:中, 3:偏高,4:高,-1:没有数据 - 虚拟交易指数
1:无, 2:少, 3:多,-1:没有数据 - 彩票游戏类交易指数
1:无, 2:少, 3:多,-1:没有数据 - 凌晨消费指数
1:无, 2:少, 3:多,-1:没有数据 - 退换货指数
1:无, 2:少, 3:多,-1:没有数据 - 恶意订单指数
1:无, 2:少, 3:多,-1:没有数据 - 用券交易指数
1:无, 2:少, 3:多,-1:没有数据
据此与行内客户行为进行匹配,针对不同客群展开特征分析。
7.2.2 时间序列
我们在违约金测算过程中,对时间序列场景进行过探索和尝试,构建示例有二:
7.2.2.1 代码示例1
数学公式描述该示例金额:
%0A#card=math&code=AMT%20%3D%2050000%20%2B%205000i%20%2B%20i%2C%20%28i%20%5Cin%20%5B1%2C%20107%5D%29%0A&id=aakQv)
根据前100天数据预测后7天数据。
- 数据准备
DATA TDEMO;FORMAT DT DATE9.;DO I = 1 TO 107;DT = "01JAN2000"D + I;LAMT = 50000 + 5000 * I + I;AMT = LOG(LAMT);OUTPUT;END;RUN;DATA TDEMO_TEST(KEEP = DT AMT);SET TDEMO(OBS = 100);RUN;
- ARIMA模型
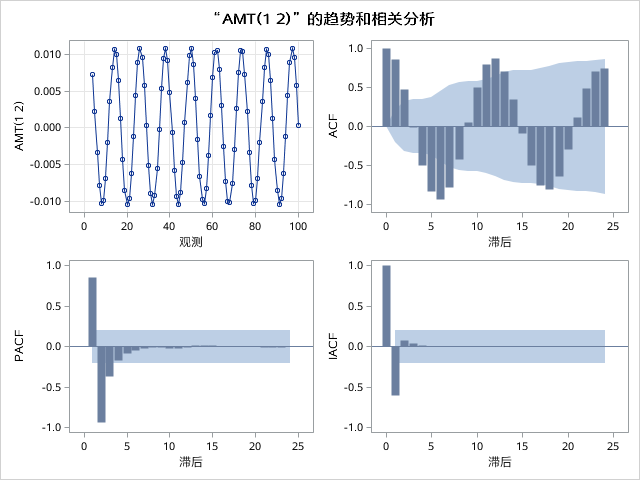
PROC SORTDATA = TDEMO_TEST(KEEP = AMT DT)OUT = TEMP;BY DT;RUN;PROC ARIMA DATA = TEMP PLOTS = FORECAST(FORECAST);IDENTIFYVAR = AMT(1, 2);ESTIMATEP = (1,2,3,4,5,6,7)Q = (4)METHOD = MLMAXITER = 50NOINT;FORECASTID = DTINTERVAL = DAYLEAD = 7ALPHA = 0.05OUT = RESULT(LABEL="FORECASTS FOR RESULT");RUN;QUIT;

- 结果验证
PROC SORTDATA = TDEMO(KEEP = DT AMT RENAME = (AMT = RAMT))OUT = TDEMOR;BY DT;RUN;PROC SORT DATA = RESULT;BY DT;RUN;DATA TDEMOR_(KEEP = DT RAMT FORECAST IMAPE);MERGE TDEMOR(WHERE = (DT > "10APR2000"D) IN=A) RESULT(IN=B);BY DT;IF A AND B;RAMT = EXP(RAMT);FORECAST = EXP(FORECAST);IMAPE = ABS(RAMT - FORECAST)/RAMT;RUN;PROC PRINT DATA = TDEMOR_;RUN;PROC SQL;SELECTSUM(IMAPE)*100/SUM(1) AS MAPEFROM TDEMOR_;QUIT;
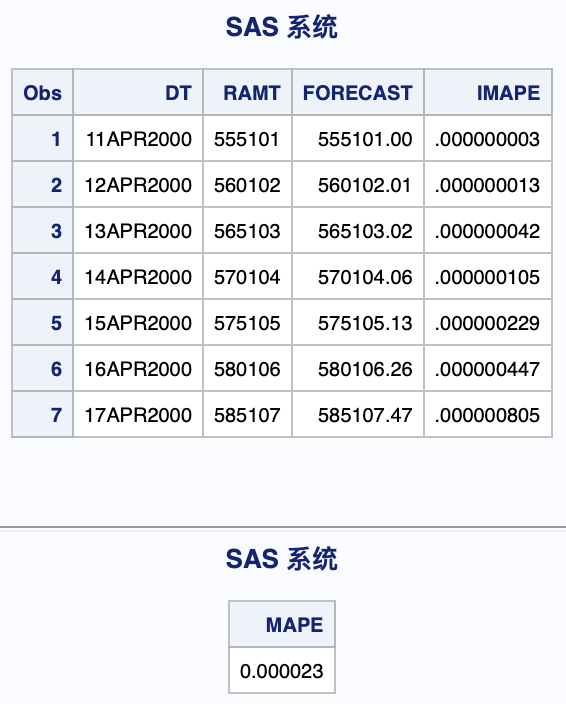
结果可精确至小数点后,MAPE仅为0.000023.
7.2.2.2 代码示例2
数学公式描述该示例金额:
%20%2B%205000%2C%20(i%20%5Cin%20%5B1%2C%20107%5D)%0A#card=math&code=AMT%20%3D%20100%5Csin%28100i%20%2B%20200%29%20%2B%205000%2C%20%28i%20%5Cin%20%5B1%2C%20107%5D%29%0A&id=Kw15Y)
根据前100天数据预测后7天数据。
- 数据准备
DATA TDEMO;FORMAT DT DATE9.;DO I = 1 TO 107;DT = "01JAN2000"D + I;LAMT = 100 * SIN(I * 100 + 200) + 5000;AMT = LOG(LAMT);OUTPUT;END;RUN;DATA TDEMO_TEST(KEEP = DT AMT);SET TDEMO(OBS = 100);RUN;
- ARIMA模型
PROC SORTDATA = TDEMO_TEST(KEEP = AMT DT)OUT = TEMP;BY DT;RUN;PROC ARIMA DATA = TEMP PLOTS = FORECAST(FORECAST);IDENTIFYVAR = AMT(1, 2);ESTIMATEP = (1,2,3,4,5,6,7)METHOD = MLMAXITER = 50NOINT;FORECASTID = DTINTERVAL = DAYLEAD = 7ALPHA = 0.05OUT = RESULT(LABEL="FORECASTS FOR RESULT");RUN;QUIT;
- 结果验证
PROC SORTDATA = TDEMO(KEEP = DT AMT RENAME = (AMT = RAMT))OUT = TDEMOR;BY DT;RUN;PROC SORT DATA = RESULT;BY DT;RUN;DATA TDEMOR_(KEEP = DT RAMT FORECAST IMAPE);MERGE TDEMOR(WHERE = (DT > "10APR2000"D) IN=A) RESULT(IN=B);BY DT;IF A AND B;RAMT = EXP(RAMT);FORECAST = EXP(FORECAST);IMAPE = ABS(RAMT - FORECAST)/RAMT;RUN;PROC PRINT DATA = TDEMOR_;RUN;PROC SQL;SELECTSUM(IMAPE)*100/SUM(1) AS MAPEFROM TDEMOR_;QUIT;
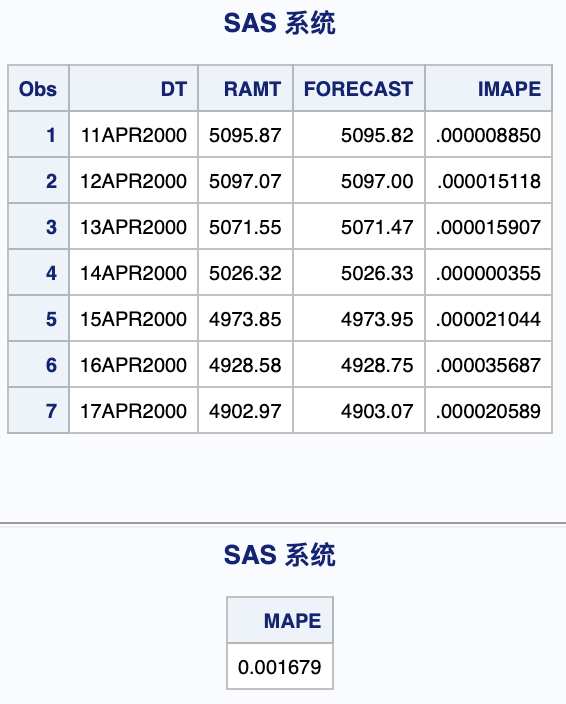
结果可精确至小数点后,MAPE仅为0.001679.
7.2.3 生存分析
7.2.3.1 探索代码
DATA ACCT;SET ODS.S_CCS_ACCT;WHERE CATEGORY = "0010" AND (CLOSE_CODE = "Q" OR NOT CLOSE_CODE) AND END_DT = "31DEC2999"D;FORMAT LIVE 8.;IF CLOSE_CODE = "" THEN CLOSE_CHDY = PUT(TODAY(), YYMMDDN8.);LIVE = INTCK("MONTH", INPUT(DAY_OPENED, YYMMDD8.), INPUT(CLOSE_CHDY, YYMMDD8.));IF LIVE > 0 AND LENGTH(CUSTR_NBR) = 18;T = CLOSE_CODE = "Q";T_1 = TEMP_LIMIT > 0;T_2 = HI_PURCHSE > 0;T_3 = PROD_LEVEL = "10";T_4 = SUBSTR(CUSTR_NBR, 17, 1) IN (1,3,5,7,9);T_5 = INTCK("YEAR", INPUT(SUBSTR(CUSTR_NBR,7,8), YYMMDD8.), INPUT(CLOSE_CHDY, YYMMDD8.)) > 30;T_6 = DAY_OPENED >= "20170101";KEEP XACCOUNT LIVE T T_:;RUN;PROC FREQ DATA = ACCT;TABLE (T_:) * T/NOCOL NOFREQ NOPERCENT;RUN;%MACRO R();%DO I = 1 %TO 6;PROC LIFETEST PLOTS = (S, LS, LLS) DATA = ACCT NOPRINT;TIME LIVE * T(0);STRATA T_&I.;RUN;%END;%MEND R;%R();PROC PHREQ DATA = ACCT OUTTEST = ACCT_T;MODEL LIVE * T(0) = T_:/RISKLIMITS;RUN;PROC PHREQ DATA = ACCT OUTTEST = ACCT_T;MODEL LIVE * T(0) = T_1 T_2 T_3 T_5/RISKLIMITS;RUN;
示例中,目标变量Y为T = CLOSE_CODE = "Q",即是否销户。
构建变量T_1-T_6:
- T_1,随机变量,历史是否临调;
- T_2,关键变量,历史是否有过消费;
- T_3,随机变量,PROD_LEVEL = “10”;
- T_4,伪造变量,SUBSTR(CUSTR_NBR, 17, 1) IN (1,3,5,7,9),即男性;
- T_5,随机变量,销户时客户年龄;
- T_6,伪造变量,开始时间是否遭遇20170101;
其中,T_2为关键变量,基于经验来说,历史是否有过消费与是否销户有一定关系;而T_4、T_6为伪造变量,因为我们知道,正常情况下性别与是否销户关系不相关,而开户时间早于20170101由于账龄(表现期)影响,销户比例会有较大差异,但我们不能得出“账龄与是否销户强相关”的结论。这里用于“迷惑”模型。
一般地,会通过PROC FREQ查看各变量与目标变量Y关系。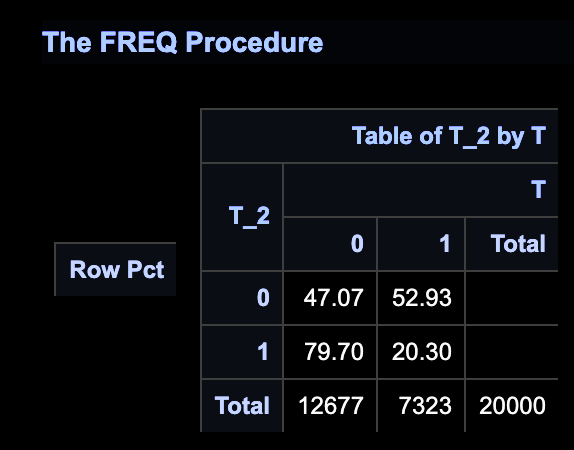

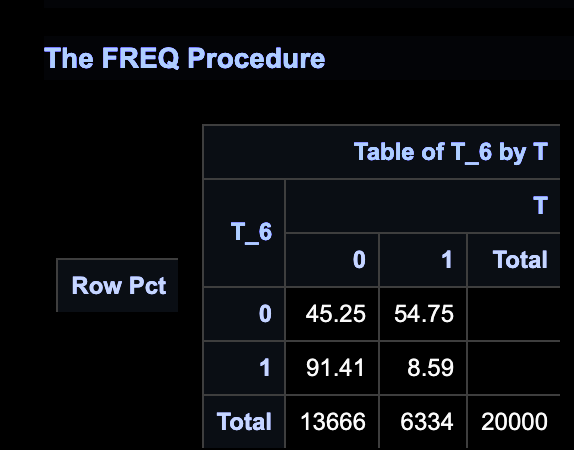
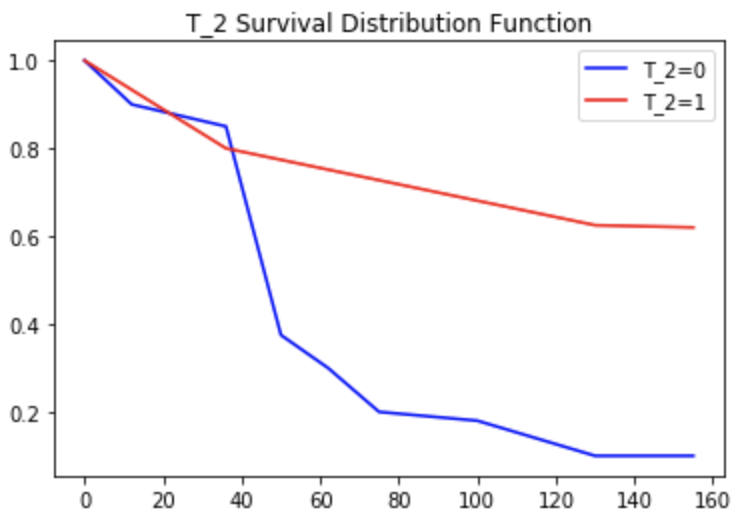
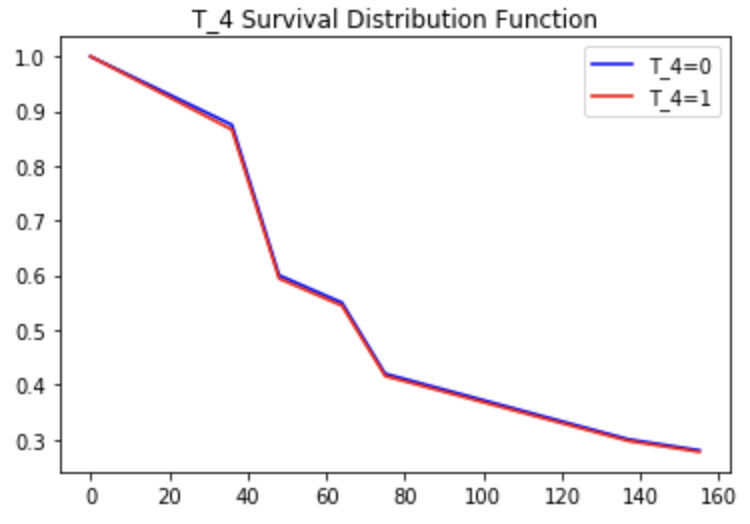
如事先构想,T_2与目标强相关,T_4几乎随机分布,T_6看似与目标强相关。
- T_2
- T_4
- T_6
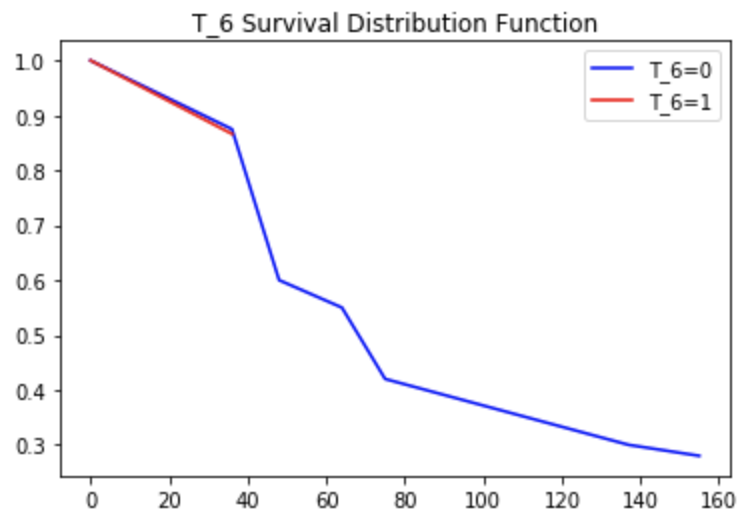
曲线上很明显透露了T_2与目标强相关,且账龄0-25销户属于自然现象,账龄25+起,历史无消费群体销户趋势逐渐出现;T_4随机分布,故而呈现销户趋势的红线和蓝线几乎完全贴合;T_6可以看到账龄0-50(即对应20170101后开户),呈现销户趋势的红线和蓝线也几乎完全贴合,之后蓝线开始有大幅下降趋势,而红线戛然而止,这是因为20170101后开户群体账龄不足50+,后续无表现。如上,显然加入了时间维度后模型未受变量销户率“迷惑”。
当然,这里的伪造变量是我们预先设计好的,而实际建模时有很多变量的实际业务关系较缕清,相信生存分析方法能发挥一定作用。
7.2.3.2 建模实践
建模实践可见《电信宽带客户流失问题研究——基于生存分析方法》
文章摘要:
随着宽带市场日趋饱和,竞争愈发激烈,客户流失现象也日益严重,如何减少客户流失成为电信运营商们关注的焦点问题。文章基于生存分析理论,提出电信宽带客户生存分析模型的客户流失预测方法,利用某电信公司宽带客户 5525 个真实数据,分析宽带客户的生存时间,研究影响宽带客户流失的因素,进而提出有效的防止客户流失的对策。
更多细节:
罗晟老师在上述示例中提出了特征时间周期的疑问,笔者拟解决之。 并推荐《Survival Analysis Using SAS A Practical Guide》
7.2.4 异常检测
7.2.4.1 孤立森林
- 基本概念
现有的异常检测方法主要是通过对正常样本的描述,给出一个正常样本在特征空间中的区域,对于不在这个区域中的样本,视为异常。这些方法的主要缺点是,异常检测器只会对正常样本的描述做优化,而不会对异常样本的描述做优化,这样就有可能造成大量的误报,或者只检测到少量的异常。
异常的两个特点:异常数据只占很少量、异常数据特征值和正常数据差别很大。
孤立森林算法是一种适用于连续数据的无监督异常检测方法,由南京大学周志华教授等人于2008年首次提出,之后又于2012年提出了改进版本。与其他异常检测算法通过距离,密度等量化指标来刻画样本间的疏离程度不同,孤立森林算法通过对样本点的孤立来检测异常值。具体来说,该算法利用一种名为孤立树iTree的二叉搜索树结构来孤立样本。由于异常值的数量较少且与大部分样本的疏离性,因此,异常值会被更早的孤立出来,也即异常值会距离iTree的根节点更近,而正常值则会距离根节点有更远的距离。此外,相较于LOF,K-means等传统算法,孤立森林算法对高纬数据有较好的鲁棒性。
加强理解
可以用一个简单的例子来理解 Isolation Forest 的基本想法。假设现在有一组一维数据,我们要对这组数据进行随机切分,希望可以把点 A 和点 B 单独切分出来。具体的,我们先在最大值和最小值之间随机选择一个值 x,然后按照 
同样,推演上述逻辑至二维。
- 代码示例
7.2.4.2 行业策略
| 同业 | 积分规则调整 |
|---|---|
| 光大银行 | 自2020年1月1日起,针对信用卡可计积分交易所获的积分奖励增加月封顶规则: 1、客户永久额度大于5000元,单个自然月内积分封顶值为永久额度的3倍; 2、客户永久额度小于等于5000元,单个自然月内可计积分交易所获的积分奖励最高1.5万份封顶; 3、单个自然月内,标准白金卡及以上卡种积分封顶值为永久额度的4倍; |
| 平安银行 | 1、自2020年4月10日起,不再以MCC作为累计积分依据; 2、全部网络消费(含线上消费及手机支付)累计积分; 3、特殊快捷支付需单笔人民币1000元(不含)以上累计积分,特殊快捷支付方式包括云闪付APP支付、银联二维码支付、银联手机闪付支付; |
| 中信银行 | 1、自2019年8月1日起,网络交易积分取消原有规定,调整为支付宝、财付通、京东支付等等交易计积分。其中,普卡、金卡为1倍积分;白金卡及以上为2倍积分。网络交易积分部分,每位客户每个自然月的累计上限为客户永久额度的2倍; 2、2020年7月2日,《关于进一步加强信用卡规范使用的提示》,对疑似套取积分行为,有权不予累计相关交易积分并采取冻结积分、撤销积分、冻结卡片、销卡等,而无须事先通知持卡人、说明理由或征得对持卡人同意。同时,可要求持卡人提供消费交易发票、购买凭证等。 |
| 广发银行 | 2019年对部分信用卡产品多倍积分特色功能上限进行调整。 1、广发真情卡、广发DIY卡、广发欢乐卡、广发One卡、广发唯品会卡、广发万宁卡,多倍积分累计奖励上限,10万积分/每自然月; 2、广发臻享白金卡、广发真情白金卡、国寿广发白金卡,多倍积分累计奖励上限:20万积分/每自然月。 |
7.2.4.3 分析结果
根据孤立森林算法识别异常积分行为客户,入模变量:
| 序号 | 变量中文名 | 变量描述 |
|---|---|---|
| 1 | 当前账单月还款比例 | 当前账单月还款金额/上一个账单月账单金额 |
| 2 | 消费还款比 | 当前账单月消费金额/当前账单月还款金额 |
| 3 | 3倍积分消费金额占比 | 单笔积分为金额3倍的消费金额/有积分的消费金额和 |
| 4 | 日均余额占账单余额比例 | 账单月内日均余额/当前账单月账单余额 |
| 5 | 消费额度比 | 当前账单月消费金额/当前额度 |
| 6 | 还款额度比 | 当前账单月还款金额/当前额度 |
| 7 | POS对应交易描述最大数量 | 当前账单月内账户内,单一pos号对应不同交易描述的最大数量 |
| 8 | 消费积分倍数 | 消费积分/有积分消费金额和 |
参考同业积分规则调整,应用策略方向:
(1)对获取奖励积分设置上限,上限参考客户授信;
(2)对线上交易部分开放积分计算,鼓励线上交易,也符合目前线上交易趋势。
策略细节:略。
7.2.5 模糊匹配
我们在人行标签加工过程中,需计算同一报告编号下,客户所填5个单位/地址共有几个不同的单位/地址。
7.2.5.1 核心思路
- 数据示例:
D1-广东省广州市天海区新华街宝华路美雅苑A幢507 D2-广州市天海区宝华路美雅直街美雅苑A幢507房 D3-广东省广州市天海区新华街宝华路美雅镇街美雅苑A幢5 0 7房 D4-广州市天海区新华镇镜湖大道2号云峰花园之三4栋606房 D5-中国广东省广州市天海区宝华路美雅直街美雅苑A507
人工判别可知D1、D2、D3、D5为同一单位/地址,D4与之不一致,合计2个不同的单位/地址。
- 判断标准:
%2FMAX(LENGTH(COL1)%2CLENGTH(COL2))%20%3E%20CUT%20%5C%5C%0A(%E5%8D%95%E4%BD%8D%2F%E5%9C%B0%E5%9D%80%EF%BC%9ACOL1%E3%80%81COL2%EF%BC%8CCUT%E5%8D%B3%E9%98%88%E5%80%BC)%0A#card=math&code=COMPLEV%28COL1%2CCOL2%29%2FMAX%28LENGTH%28COL1%29%2CLENGTH%28COL2%29%29%20%3E%20CUT%20%5C%5C%0A%28%E5%8D%95%E4%BD%8D%2F%E5%9C%B0%E5%9D%80%EF%BC%9ACOL1%E3%80%81COL2%EF%BC%8CCUT%E5%8D%B3%E9%98%88%E5%80%BC%29%0A&id=TTGq7)
然而,当单位/地址D1=单位/地址D2,单位/地址D1=单位/地址D3时,将直接认定单位/地址D1=单位/地址D2=单位/地址D3.但当单位/地址D1!=单位/地址D2,单位/地址D1!=单位/地址D3时,无法直接认定单位/地址D2、单位/地址D3是否一致。
这里设计排列组合关系,代码较为复杂,我们采用排列组合模拟造FMT格式化来简化代码。
7.2.5.2 完整代码
OPTIONS COMPRESS = YES;%LET CUT = 0.55;DATA _K;INFILE DATALINES DELIMITER = ",";INPUT _K $ _COL $;DATALINES;_,A_,B_,C_,E;PROC SQL;CREATE TABLE _K1(DROP = _K) ASSELECT*,COMPRESS(COL1||COL2||COL3||COL4||COL5) AS COL15,INDEX(CALCULATED COL15, "A") > 0 AS KCOL1,INDEX(CALCULATED COL15, "B") > 0 AS KCOL2,INDEX(CALCULATED COL15, "C") > 0 AS KCOL3,INDEX(CALCULATED COL15, "D") > 0 AS KCOL4,INDEX(CALCULATED COL15, "E") > 0 AS KCOL5,CALCULATED KCOL1+CALCULATED KCOL2+CALCULATED KCOL3+CALCULATED KCOL4+CALCULATED KCOL5 AS KCOLSFROM(SELECTTTTT1.*,TTTT2._COL AS COL5FROM (SELECTTTT1.*,TTT2._COL AS COL4FROM (SELECTTT1.*,TT2._COL AS COL3FROM (SELECTT1._K AS _K,T1._COL AS COL1,T2._COL AS COL2FROM _K AS T1 JOIN _K AS T2ON T1._K = T2._K) AS TT1 JOIN _K AS TT2ON TT1._K = TT2._K) AS TTT1 JOIN _K AS TTT2ON TTT1._K = TTT2._K) AS TTTT1 JOIN _K AS TTTT2ON TTTT1._K = TTTT2._K)ORDER BY COL1, COL2, COL3, COL4, COL5;QUIT;DATA _K2;SET _K1;/* CLEV_11 = COMPLEV(COL1, COL1)/MAX(LENGTH(COL1), LENGTH(COL1)) > &CUT.; */CLEV_12 = COMPLEV(COL1, COL2)/MAX(LENGTH(COL1), LENGTH(COL2)) > &CUT.;CLEV_13 = COMPLEV(COL1, COL3)/MAX(LENGTH(COL1), LENGTH(COL3)) > &CUT.;CLEV_14 = COMPLEV(COL1, COL4)/MAX(LENGTH(COL1), LENGTH(COL4)) > &CUT.;CLEV_15 = COMPLEV(COL1, COL5)/MAX(LENGTH(COL1), LENGTH(COL5)) > &CUT.;/* CLEV_21 = COMPLEV(COL2, COL1)/MAX(LENGTH(COL2), LENGTH(COL1)) > &CUT.; *//* CLEV_22 = COMPLEV(COL2, COL2)/MAX(LENGTH(COL2), LENGTH(COL2)) > &CUT.; */CLEV_23 = COMPLEV(COL2, COL3)/MAX(LENGTH(COL2), LENGTH(COL3)) > &CUT.;CLEV_24 = COMPLEV(COL2, COL4)/MAX(LENGTH(COL2), LENGTH(COL4)) > &CUT.;CLEV_25 = COMPLEV(COL2, COL5)/MAX(LENGTH(COL2), LENGTH(COL5)) > &CUT.;/* CLEV_31 = COMPLEV(COL3, COL1)/MAX(LENGTH(COL3), LENGTH(COL1)) > &CUT.; *//* CLEV_32 = COMPLEV(COL3, COL2)/MAX(LENGTH(COL3), LENGTH(COL2)) > &CUT.; *//* CLEV_33 = COMPLEV(COL3, COL3)/MAX(LENGTH(COL3), LENGTH(COL3)) > &CUT.; */CLEV_34 = COMPLEV(COL3, COL4)/MAX(LENGTH(COL3), LENGTH(COL4)) > &CUT.;CLEV_35 = COMPLEV(COL3, COL5)/MAX(LENGTH(COL3), LENGTH(COL5)) > &CUT.;/* CLEV_41 = COMPLEV(COL4, COL1)/MAX(LENGTH(COL4), LENGTH(COL1)) > &CUT.; *//* CLEV_42 = COMPLEV(COL4, COL2)/MAX(LENGTH(COL4), LENGTH(COL2)) > &CUT.; *//* CLEV_43 = COMPLEV(COL4, COL3)/MAX(LENGTH(COL4), LENGTH(COL3)) > &CUT.; *//* CLEV_44 = COMPLEV(COL4, COL4)/MAX(LENGTH(COL4), LENGTH(COL4)) > &CUT.; */CLEV_45 = COMPLEV(COL4, COL5)/MAX(LENGTH(COL4), LENGTH(COL5)) > &CUT.;ACLEV = CAT(OF CLEV_:);RUN;PROC SORT DATA = _K2(KEEP = ACLEV KCOLS) OUT= _K3 NODUPKEY;BY KCOLS ACLEV;RUN;%MACRO FMT(TB=, KEY=, DESC=, FMT_NAME=);PROC SORT DATA = &TB. NODUPKEY OUT = INDATA;BY &KEY. &DESC.;QUIT;PROC CONTENTS DATA = INDATA OUT = CONT NOPRINT;RUN;PROC SQL NOPRINT;SELECT TYPE INTO: KEY_TYPE FROM CONTWHERE UPCASE(NAME) = UPCASE("&KEY.");QUIT;%PUT &KEY_TYPE.;DATA &FMT_NAME.;LENGTH LABEL $200.;SET INDATA END = LAST;START = COMPRESS(&KEY.);LABEL = COMPRESS(&DESC.);RETAIN FMTNAME "&FMT_NAME.";%IF &KEY_TYPE. = 2 %THEN TYPE = "C";%ELSE TYPE = "N";;OUTPUT;IF LAST THEN DO;START = "**OTHER**";LABEL = "UNKNOWN";HLO = "O";OUTPUT;END;RUN;PROC FORMAT CNTLIN = &FMT_NAME.;RUN;%MEND FMT;%FMT(TB=_K3, KEY=ACLEV, DESC=KCOLS, FMT_NAME=FMT_KCOLS);DATA _1;INFILE DATALINES DELIMITER = ",";FORMAT REPORT $32. ADDR $1000.;INPUT REPORT $ ADDR $;DATALINES;6412121CBB2DC2CB9E460CFEE7046BE2, 中国电信股份有限公司广州天海区分公司6412121CBB2DC2CB9E460CFEE7046BE2, 中国电信公司广州天海区分公司6412121CBB2DC2CB9E460CFEE7046BE2, 中国电信股份有限公司广州天海区分6412121CBB2DC2CB9E460CFEE7046BE2, 中国电信股份有限公司广州天海分公司6412121CBB2DC2CB9E460CFEE7046BE2, 天海电信局账务中心D3952BB5DFE9E8B389C453532BEB7208, 广东省广州市天海区新华街宝华路美雅苑A幢507D3952BB5DFE9E8B389C453532BEB7208, 广州市天海区宝华路美雅直街美雅苑A幢507房D3952BB5DFE9E8B389C453532BEB7208, 广东省广州市天海区新华街宝华路美雅镇街美雅苑A幢507房D3952BB5DFE9E8B389C453532BEB7208, 广州市天海区新华镇镜湖大道2号云峰花园之三4栋605房D3952BB5DFE9E8B389C453532BEB7208, 中国广东省广州市天海区宝华路美雅直街美雅苑A5070BECFCBBDB6BEE210A1D5DC5989632E1, 广州市天海区新华镇镜湖大道2号云峰花园之三4栋606房0BECFCBBDB6BEE210A1D5DC5989632E1, 广东省广州市新华街宝华路美雅苑A幢5070BECFCBBDB6BEE210A1D5DC5989632E1, 广州市天海区新华镇镜湖大道2号云峰花园之三4栋606房0BECFCBBDB6BEE210A1D5DC5989632E1, 广东省广州市天海区新华街宝华路美雅苑A幢500BECFCBBDB6BEE210A1D5DC5989632E1, 广东省广州市天海区新华街宝华路美雅苑A幢5086F0E79294E9ECBE5A38727B06FBFA4, 广东省广州市天海区新华街宝华路美雅苑A幢5077086F0E79294E9ECBE5A38727B06FBFA4, 广东省广州市天海区新华街宝葫芦美雅苑A幢507086F0E79294E9ECBE5A38727B06FBFA4, 广东省广州市天海区新华街宝华路美雅苑A幢50086F0E79294E9ECBE5A38727B06FBFA4, 广东省广州市天海区新华街宝华路美雅苑A幢5086F0E79294E9ECBE5A38727B06FBFA4, 广东省广州市天海区新华街宝华路美雅苑A幢;PROC SORT DATA = _1;BY REPORT;RUN;PROC TRANSPOSE DATA = _1 OUT = _2;VAR ADDR;BY REPORT;RUN;DATA _3;SET _2;CLEV_12 = COMPLEV(COL1, COL2)/MAX(LENGTH(COL1), LENGTH(COL2)) > &CUT.;CLEV_13 = COMPLEV(COL1, COL3)/MAX(LENGTH(COL1), LENGTH(COL3)) > &CUT.;CLEV_14 = COMPLEV(COL1, COL4)/MAX(LENGTH(COL1), LENGTH(COL4)) > &CUT.;CLEV_15 = COMPLEV(COL1, COL5)/MAX(LENGTH(COL1), LENGTH(COL5)) > &CUT.;CLEV_23 = COMPLEV(COL2, COL3)/MAX(LENGTH(COL2), LENGTH(COL3)) > &CUT.;CLEV_24 = COMPLEV(COL2, COL4)/MAX(LENGTH(COL2), LENGTH(COL4)) > &CUT.;CLEV_25 = COMPLEV(COL2, COL5)/MAX(LENGTH(COL2), LENGTH(COL5)) > &CUT.;CLEV_34 = COMPLEV(COL3, COL4)/MAX(LENGTH(COL3), LENGTH(COL4)) > &CUT.;CLEV_35 = COMPLEV(COL3, COL5)/MAX(LENGTH(COL3), LENGTH(COL5)) > &CUT.;CLEV_45 = COMPLEV(COL4, COL5)/MAX(LENGTH(COL4), LENGTH(COL5)) > &CUT.;ACLEV = CAT(OF CLEV_:);KCOLS = PUT(ACLEV, FMT_KCOLS.);RUN;PROC PRINT DATA = _3(KEEP = REPORT ACLEV KCOLS);RUN;
输出结果: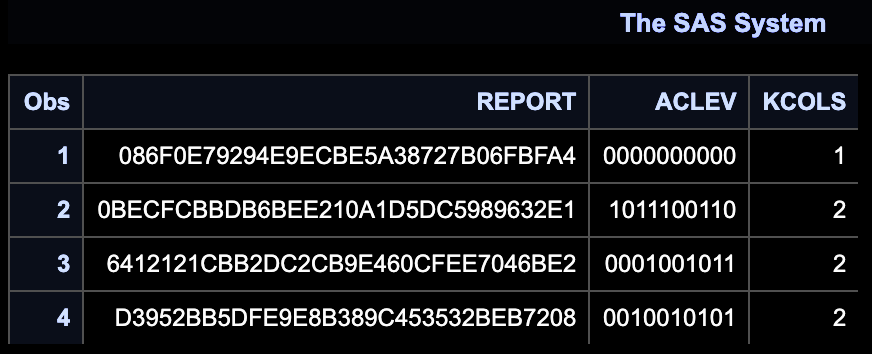
7.2.6 NLP
7.2.6.1 核心代码
如上智能金融中示例,我们在流失预警挽留模型的客群探索工作中,引入NLP模型,作为SAS传统模型的挑战。
- SAS数据处理
/* 伪代码 */DATA X;SET ODS.S_CCS_EVENT;STM_MTH = PUT(INTNX("MONTH", "01JAN2016"D, (MONTH_NBR-313), "B"), YYMMN6.);DES_LINE2 = KCOMPRESS(DES_LINE1, "1234567890 ");IF STM_MTH IN ("201911", "201912", ...);KEEP ...;RUN;PROC SORT DATA = X;BY DES_LINE2;RUN;PROC SORTDATA = X(KEEP = DES_LINE2)OUT = DES NODUPKEY;BY DES_LINE2;RUN;DATA DES;SET DES;/* DES_LINE3 即至少2位长度的编码 */DES_LINE3 = _N_ + 10;RUN;DATA XDES;MERGE X(IN=A) DES(IN=B);BY DES_LINE2;IF A;RUN;/* 按消费时间 */PROC SORT DATA = XDES;BY XACCOUNT INP_DATE INP_TIME;RUN;/* 转置 */PROC TRANSPOSE DATA = XDES OUT = XDEST(DROP = _NAME_);VAR DES_LINE3;BY XACCOUNT;RUN;PROC SORTDATA = MODELOUT = Y NODUPKEY;BY XACCOUNT;RUN;DATA XY;MERGE MODEL(IN=A) XDEST(IN=B);BY XACCOUNT;IF A;RUN;...
待优化,可进一步限制交易类型、清洗交易描述等数据处理。
- Python建模
https://github.com/IvanaXu/PyTools, 069.Test_scipy_sparse
以NLP文本处理中TFIDF为例,依托稀疏矩阵库代码化,过程如下:
"""稀疏矩阵库scipy.sparsehttps://blog.csdn.net/pipisorry/article/details/41762945http://www.bu.edu/pasi/files/2011/01/NathanBell1-10-1000.pdf"""import randomimport numpy as npimport pandas as pdfrom sklearn import metricsfrom scipy import sparse as spfrom sklearn.linear_model import LogisticRegressionfrom sklearn.feature_extraction.text import TfidfVectorizer# 文本数据 data(100*1000)为变量,但1000大多缺失; target(100*2)为目标与概率,不缺失;data = [[np.nan if random.random() > 0.01 else str(random.randint(0, 10))for _2 in range(1000)] for _1 in range(100)]data = pd.DataFrame(data)data.to_csv("069.Test_scipy_sparseX.csv", index=None, header=None)# print(data)target = pd.DataFrame([round(random.random(), 4) for _1 in range(100)])target[1] = target[0].apply(lambda x: 1 if x < 0.618 else 0)target.to_csv("069.Test_scipy_sparseY.csv", index=None, header=None)# 读取数据mat = sp.lil_matrix((99999, 99999))with open("069.Test_scipy_sparseX.csv", "r") as f:for n, i in enumerate(f):for _i in i.strip("\n").split(","):if _i:mat.data[n].append(_i)corpus = [" ".join(_) for _ in mat.data if _]print(corpus)# ['8 0 2 6 8 6 10 10 2 10', '2 3 1 3 6 8 10 6 5 9 8 9', '9 1 0 3 9 2 5 10 3 1 7 1 7',_ = pd.read_csv("069.Test_scipy_sparseY.csv", header=None)Y = _[1].tolist()P = _[0].tolist()# TF-IDFtfidf = TfidfVectorizer(sublinear_tf=True, min_df=2, max_df=0.95)tfidf.fit(corpus)X = tfidf.transform(corpus)# 返回即稀疏矩阵print(X)# (0, 0) 1.0# (1, 0) 1.0# (2, 0) 1.0# 构建模型model1 = LogisticRegression()model1.fit(X, Y)print(metrics.f1_score(Y, model1.predict(X)))# 0.7341772151898733model2 = LogisticRegression()_X = sp.hstack((X, sp.csr_matrix(np.array(P)).T))model2.fit(_X, Y)print(metrics.f1_score(Y, model2.predict(_X)))# 0.9666666666666666
7.2.6.2 稀疏矩阵
在矩阵中,若数值为0的元素数目远远多于非0元素的数目,并且非0元素分布没有规律时,则称该矩阵为稀疏矩阵;与之相反,若非0元素数目占大多数时,则称该矩阵为稠密矩阵。定义非零元素的总数比上矩阵所有元素的总数为矩阵的稠密度。
简单来说,如下稀疏矩阵转换后,仅对有效值进行保存和计算,将减少0元素消耗的不必要资源。
应用稀疏矩阵,包含如下:
(1)矩阵赋值
mat = sp.lil_matrix((99999, 99999))with open("069.Test_scipy_sparseX.csv", "r") as f:for n, i in enumerate(f):for _i in i.strip("\n").split(","):if _i:mat.data[n].append(_i)
(2)array转换
sp.csr_matrix(np.array(P))
(3)stack-methods
_X = sp.hstack((X, sp.csr_matrix(np.array(P)).T))
(4)TDIDF计算
tfidf = TfidfVectorizer(sublinear_tf=True, min_df=2, max_df=0.95)tfidf.fit(corpus)X = tfidf.transform(corpus)# 返回即稀疏矩阵
(5)模型构建
model1 = LogisticRegression()model1.fit(X, Y)# 模型支持输入稀疏矩阵格式的X
(6)代码评估
有兴趣的同学可以使用传统方法与上述方法对比,引入稀疏矩阵计算将大幅节省内存和时间!

若有收获,就点个赞吧
0 人点赞
