5.3.1 SAS EM
5.3.1.1 评分卡
信用评分模块包含信用交换、交互式分组、拒绝推断、计分卡。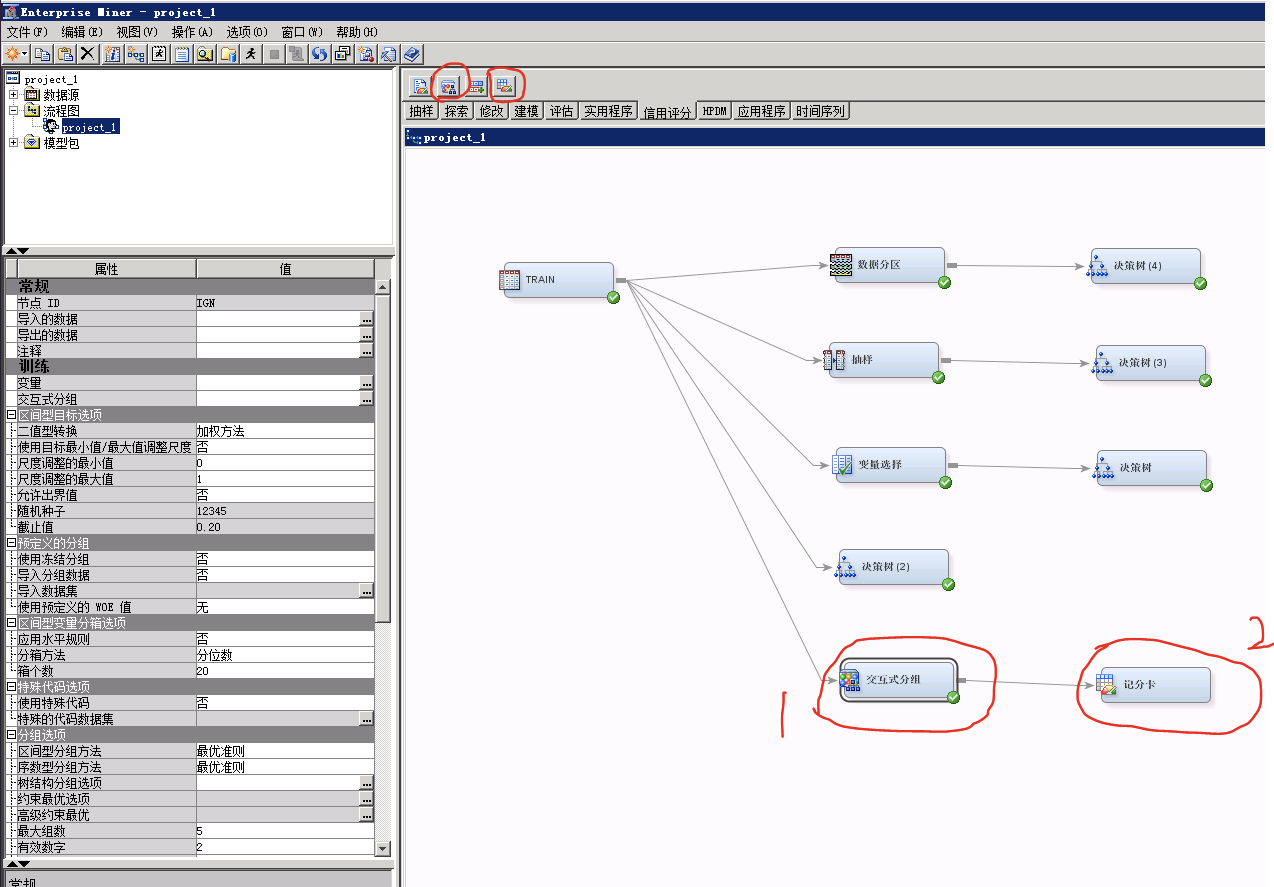
1、交互式分组
对变量进行分箱,并计算每个变量的IV、GINI等信息,针对每一段计算目标率、WOE等值。
查看变量的分箱代码:
(1)点击“交互式分组”,右键选择“结果”选项;
(2)点击“查看”;
(3)选择“评分”,选择“sas代码”。
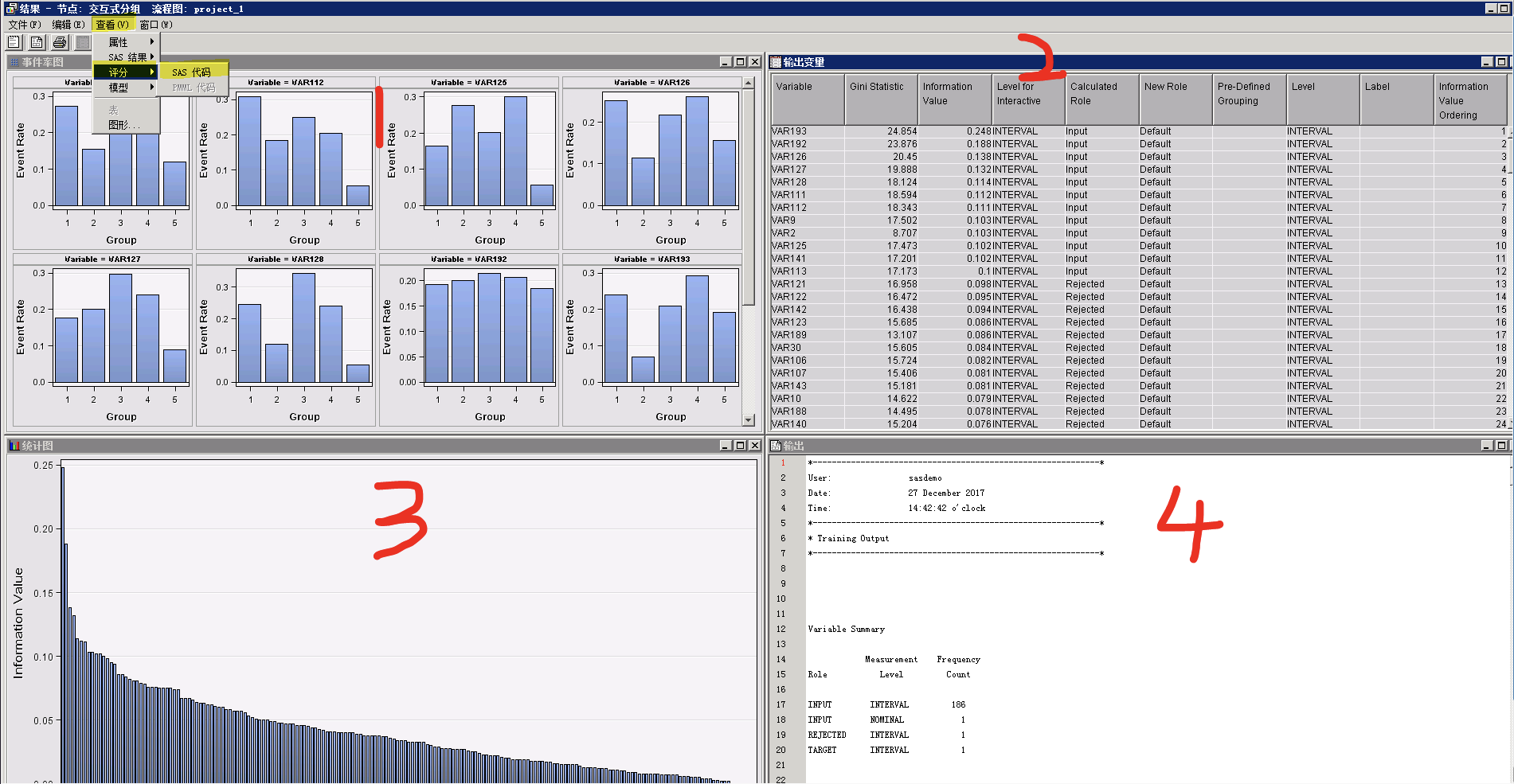
序号1:各变量的分组情况,以及每一组的目标率;
序号2:每个变量的IV、GINI、是否通过筛选等信息;
序号3:所有变量按照IV值的排序;
序号4:输出窗口;
2、人工分组
评分卡分组的结果可能会出现变量分数不单调的情况,可以通过人工调整分组使变量单调。调整的步骤如下:
步骤一:点击“交互式分组”模块(序号1)-> “交互式分组”(序号2),进入人工分组界面;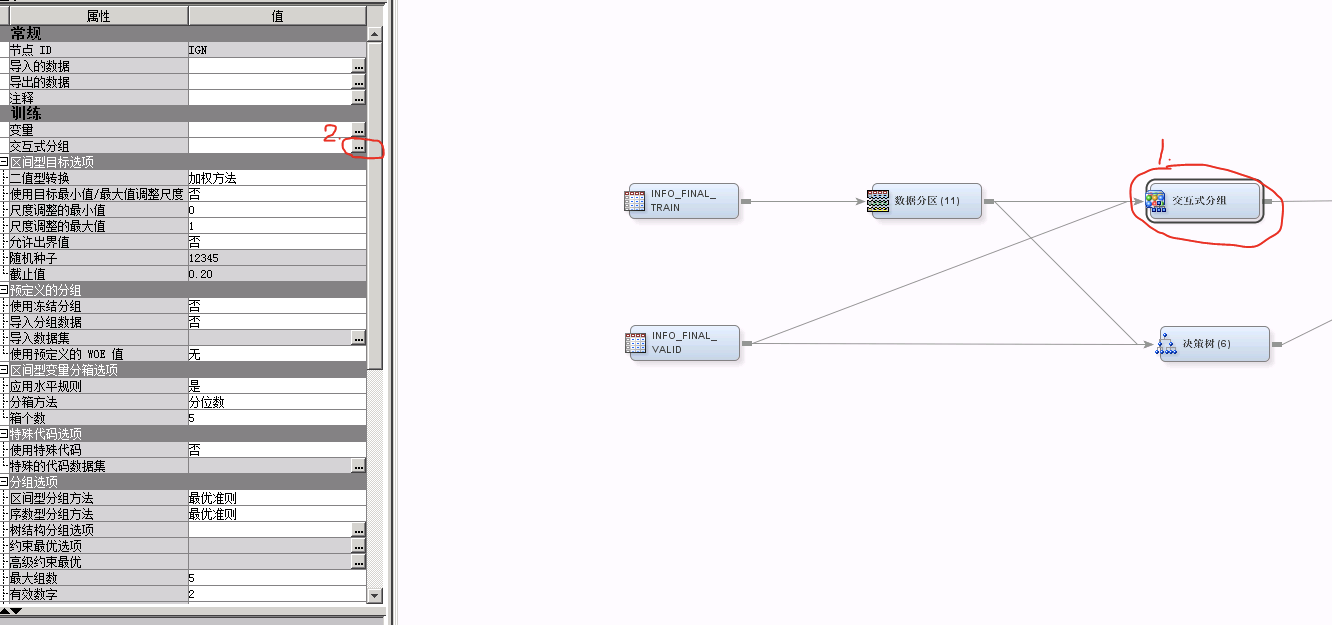
步骤二:选择需要进行调整的变量(序号1)->“分组”(序号2);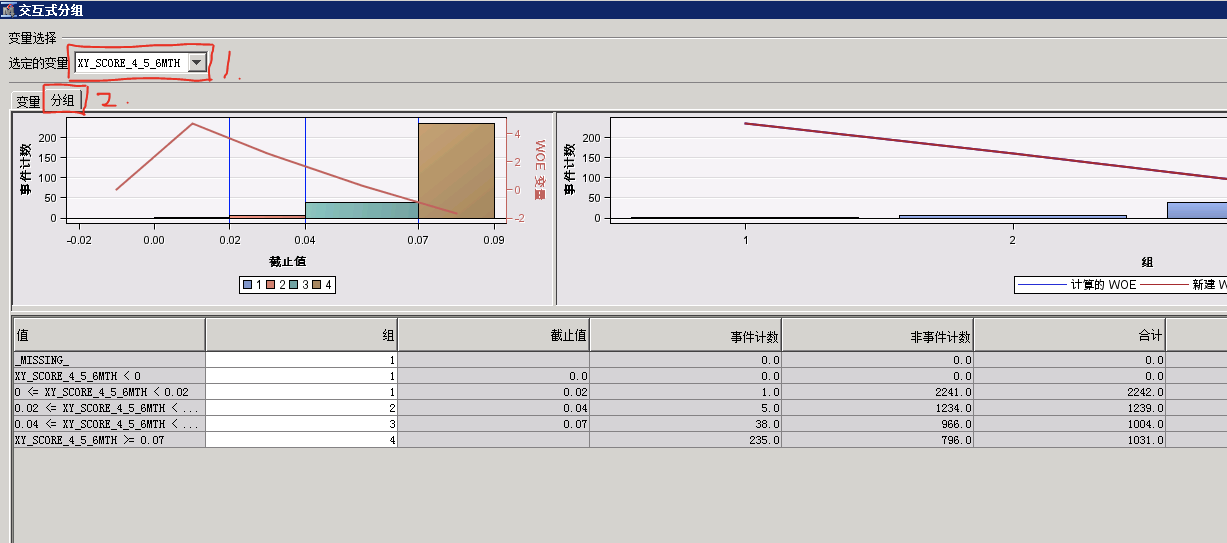
步骤三:对变量进行分组,选择需要合并的组->右键选择“合并箱”;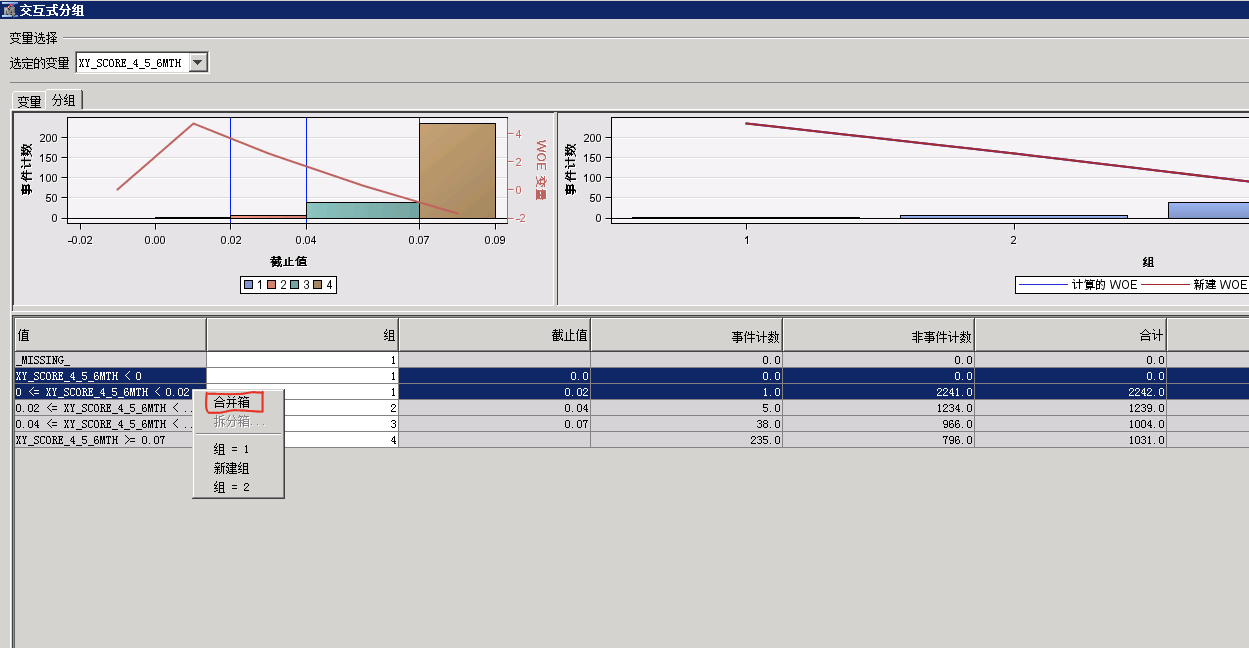
步骤四:点击“应用”->“关闭”->“保存结果”,结束;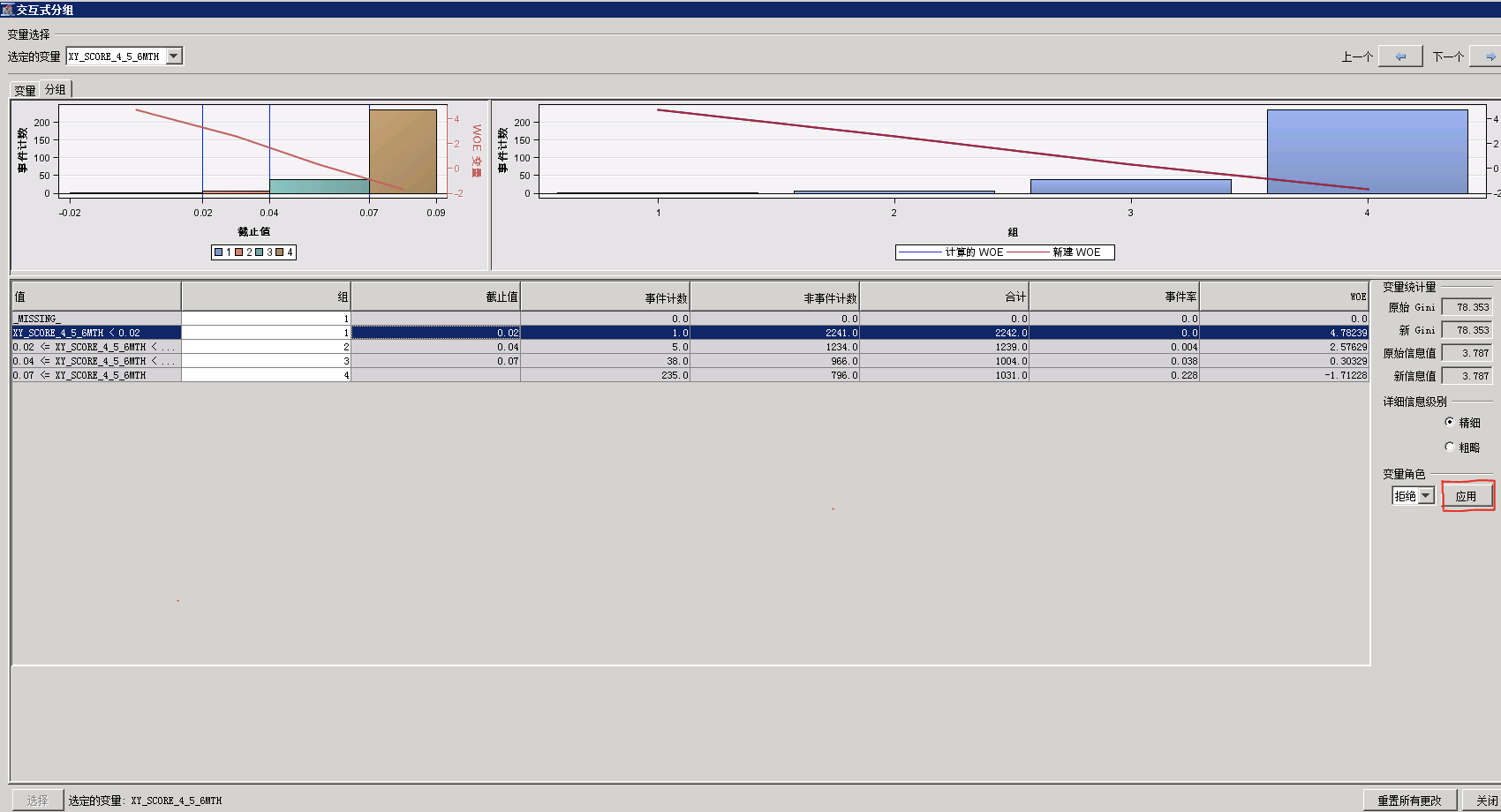
步骤五:重跑模型,重跑过程中会应用新调整的分组;
3、评分卡
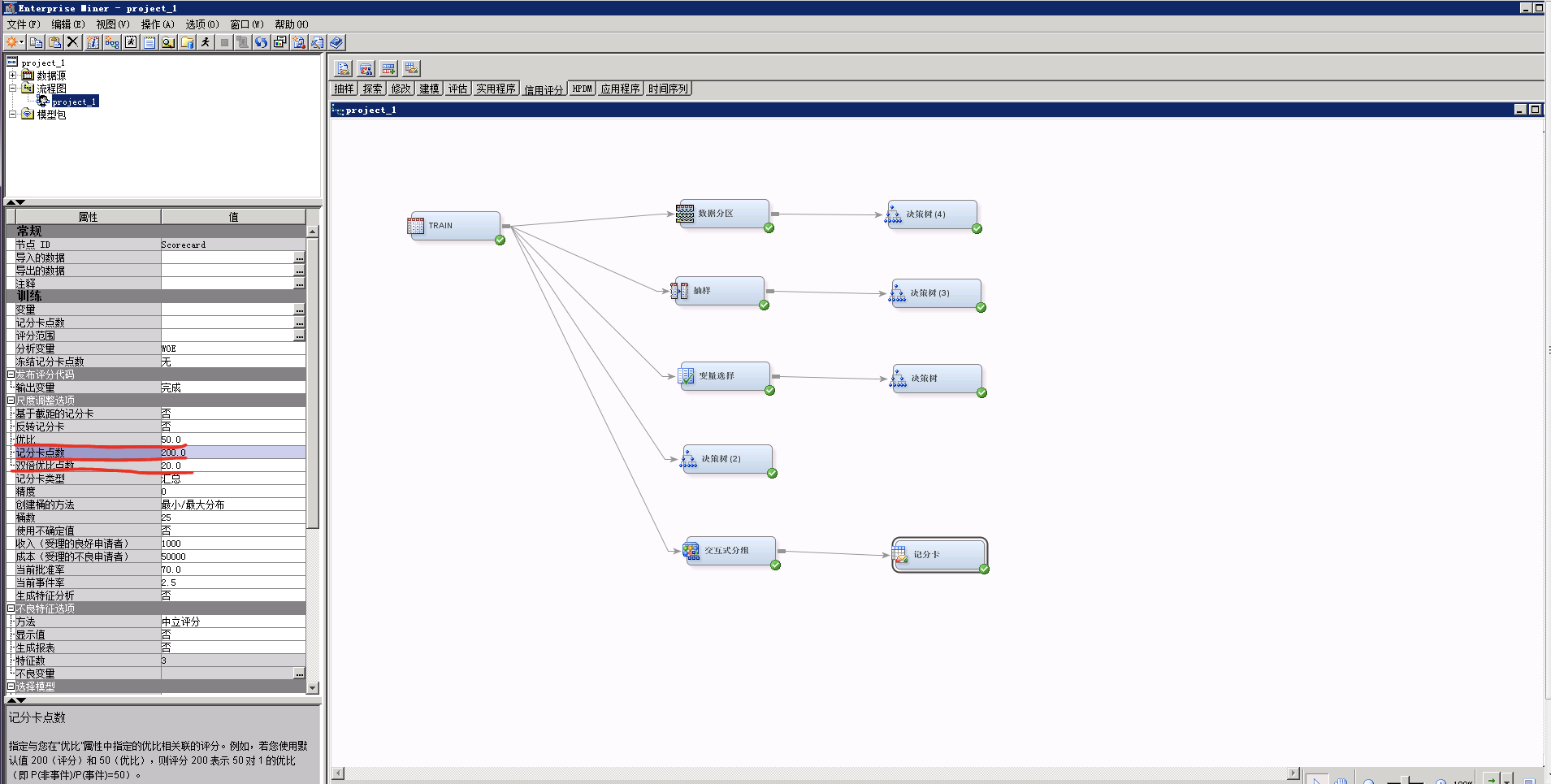
(1)评分卡参数设置,评分卡的参数设置主要有3个:
记分卡点数:指定与您在“优比”属性中指定的优比相关联的评分。例如,若您使用默认值 200(评分)和 50(优比),则评分 200 表示 50:1 的优比(即 P(非事件)/P(事件)=50)
优比:指定与您在“记分卡点数”属性中指定的评分值对应的非事件/事件优比。默认值为 50
双倍优比点数(pdo):增加评分点数,生成与双倍优比对应的评分。“双倍优比点数”属性接受大于等于 1 的整数。默认值为 20。 表示ln(odds)中的odds翻倍的时候,评分增加的分数值。odds表示0:1的比率,申请评分卡中odds表示好客户数量:坏客户数量
(2)评分卡结果说明
评分卡结果图如下图所示,其中
序号1:累计lift值;
序号2:分数与odds的线性关系;
序号5:评分卡;
序号6:各变量的系数、p值、统计检验结果、累计提升度等各项结果汇总;
评分代码可以有“查看-评分-SAS代码”得到。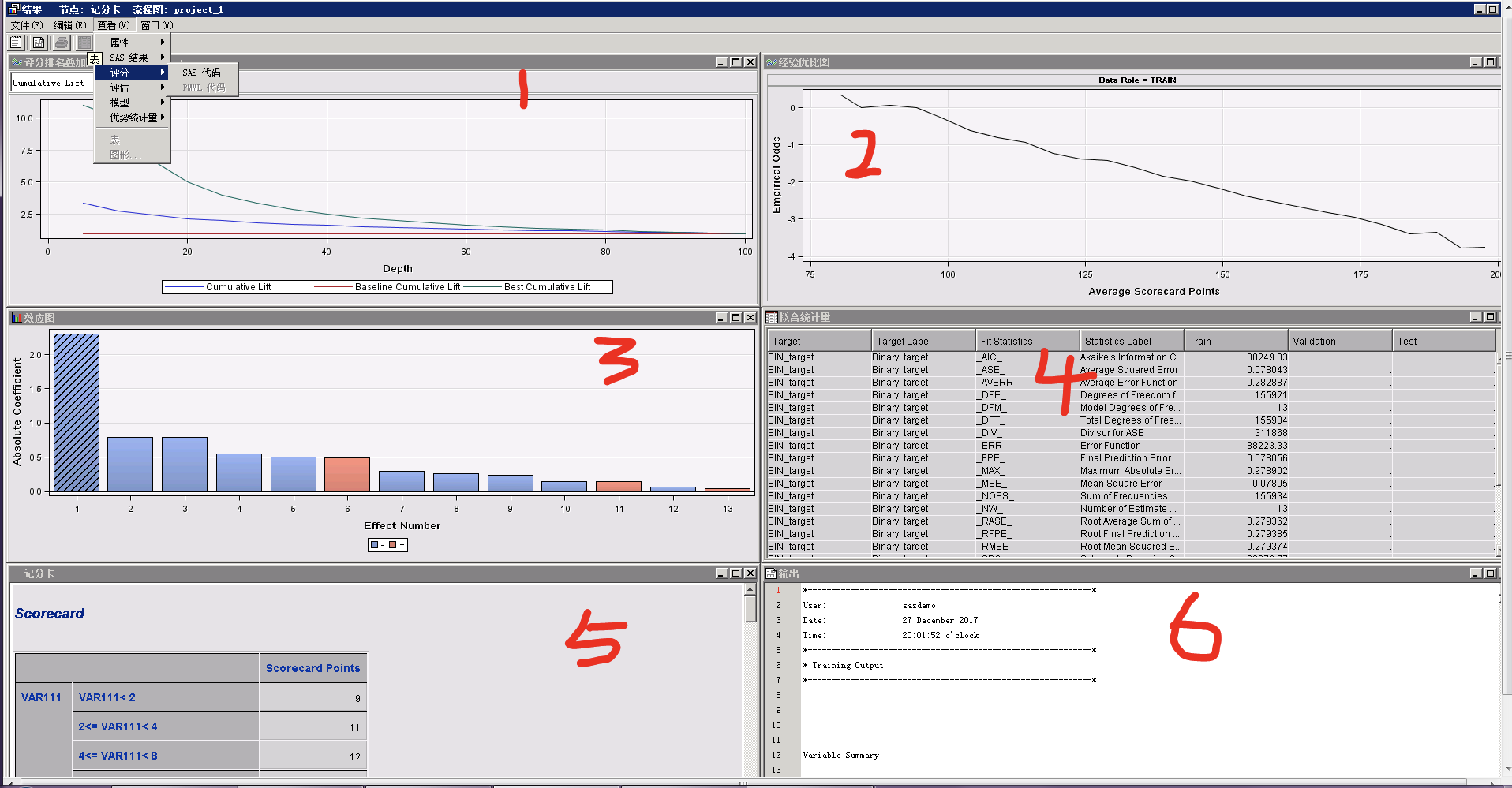
4、模型比较
模型比较用于查看各模型的评估效果(包括训练、测试和验证集)。本节操作同样适用于决策树及其他模型。
点击“评估”(序号1)->选择“模型比较”(序号2)
例:设置两个模型,决策树和评分卡,设置单独的训练集和验证集。
点击“模型比较”模块,右键选择“结果”。出现两个模型的评估结果。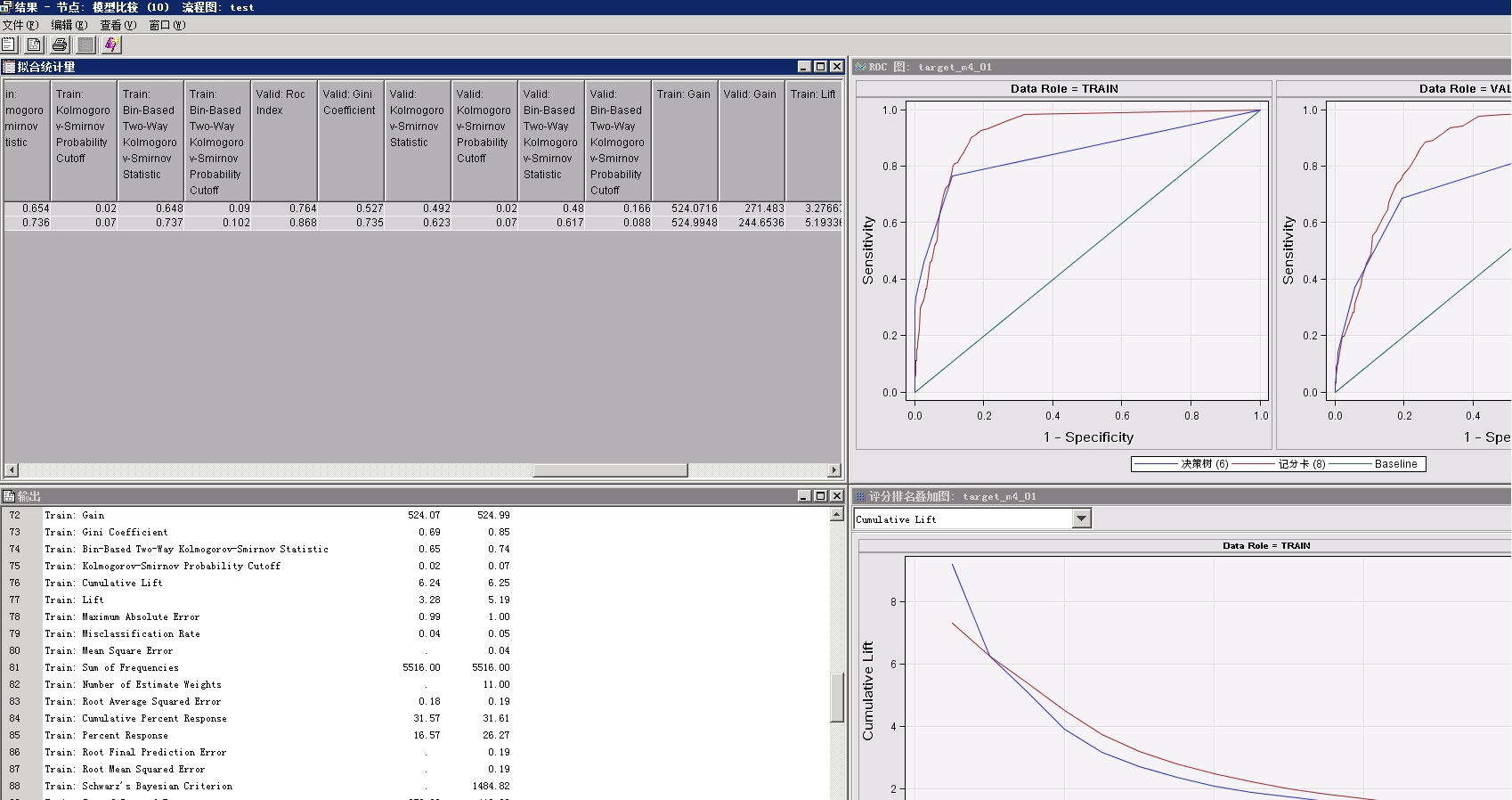
主要的评估效果包括:
(1)训练集、验证集、测试集的ks值和AUC(KS和AUC的值越高,分类的效果越好)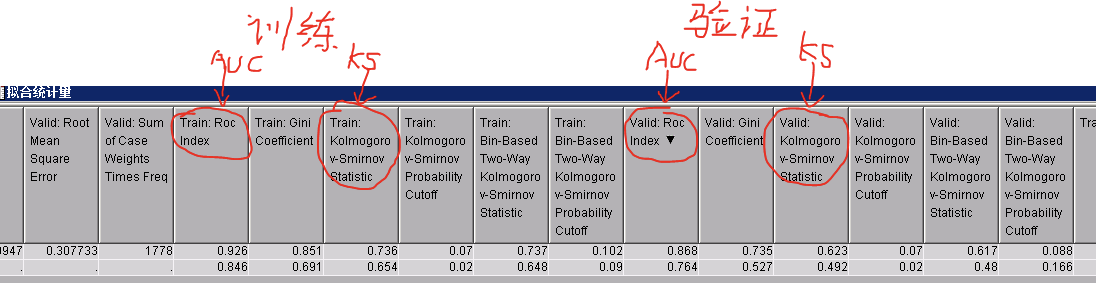
(2)ROC图:
样本分为两类,1为正样本和0为负样本。roc图横坐标为FP,即0中错误识别为1的概率,纵坐标为TP,即1中正确识别为1的概率。因此,roc曲线越“陡”,分类的效果就越好。
ROC曲线的面积成为AUC,AUC越大,分类的效果越好。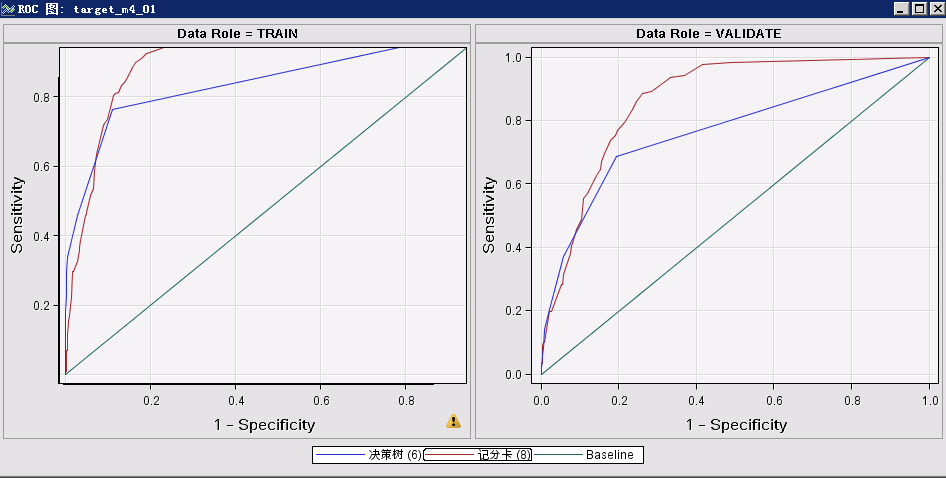
(3)分类的效果,包括各模型各类别的分类结果:
横坐标表示各个类别,纵坐标表示数量的占比。如图所示,数据分成两类0和1。两类的占比之和为100%,每一个类别中,蓝色的部分表示预测正确的样本占比,橘黄色部分表示预测错误的样本占比。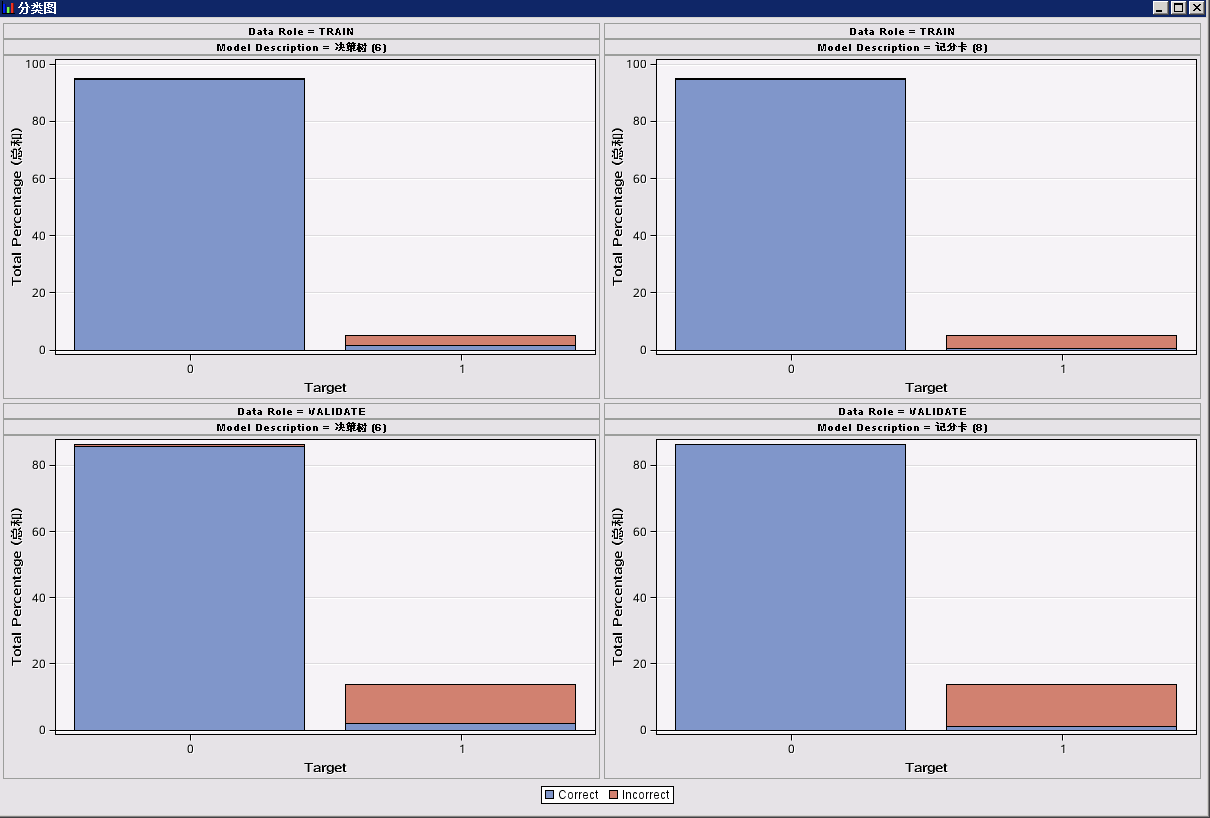
5.3.1.2 决策树
1、数据抽样
“数据分区”和“抽样”是“抽样”模块下的子模块。如下图所示:
序号1为一级菜单,序号2和序号3是序号1下的二级菜单,点击序号1之后才会显示序号2和序号3.
序号1:“抽样”模块,包含多个抽样类功能;
序号2:“数据分区”子模块,用于生成训练集、验证集、测试集 三个数据集;
序号3:“抽样”子模块,随机抽样,随机生成数据集的子集,生成一个数据集。(原数据集可能比较大,抽出小样本分析或测试)

(1)数据分区
“数据分区”模块的参数说明,点击图中“数据分区”模块,左侧会显示参数区域(蓝色方框,如下图所示):
序号4、序号5、序号6分别是训练集(默认40%)、验证集(默认30%)、测试集(默认30%)的比例,三个数相加的和为100.
其中:
- 训练集:用来训练决策树的数据集;
- 验证集:在训练过程中会考虑验证集的效果;
- 测试集:与训练过程无关,用于测试决策树的效果;
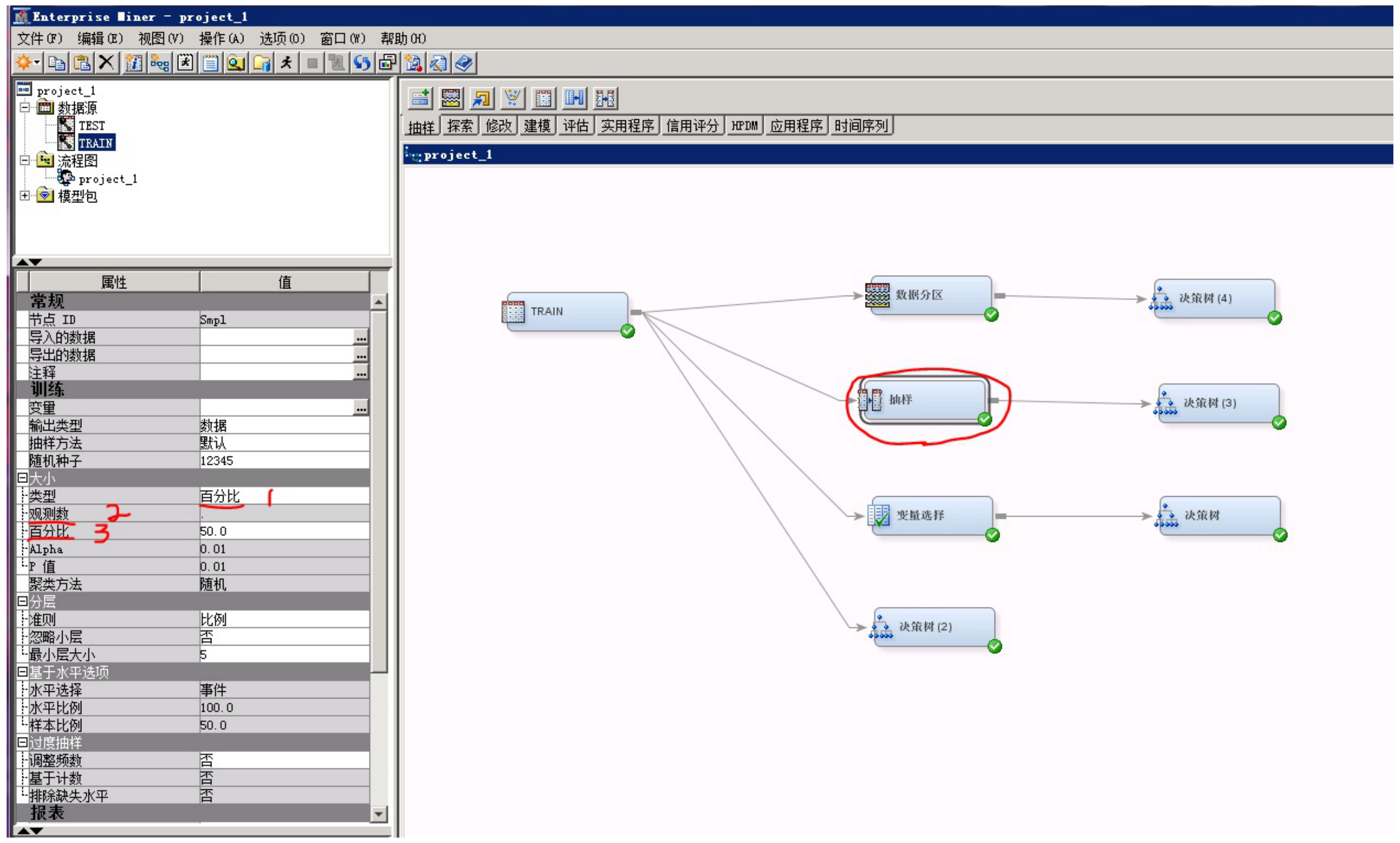
(2)抽样
“抽样”模块的参数说明,如下图所示:
序号1:抽样“类型”,取值有三种“计算”、“观测数”、“百分比”。指定用于确定“样本大小”的方法。可以是总体的百分比,也可以是离散的观测数或计算值。若选择“计算”,则节点会计算捕获稀有事件所必需的样本大小,这些稀有事件具有您在“P 值”字段中所输入的概率。
序号2:当抽样类型为“观测数”时才能更改使用,抽样的样本数量。
序号3:当抽样类型为“百分比”时才能更改使用,抽样的样本数量占原样本数量比例。
2、决策树参数设置
(1)决策树基本结构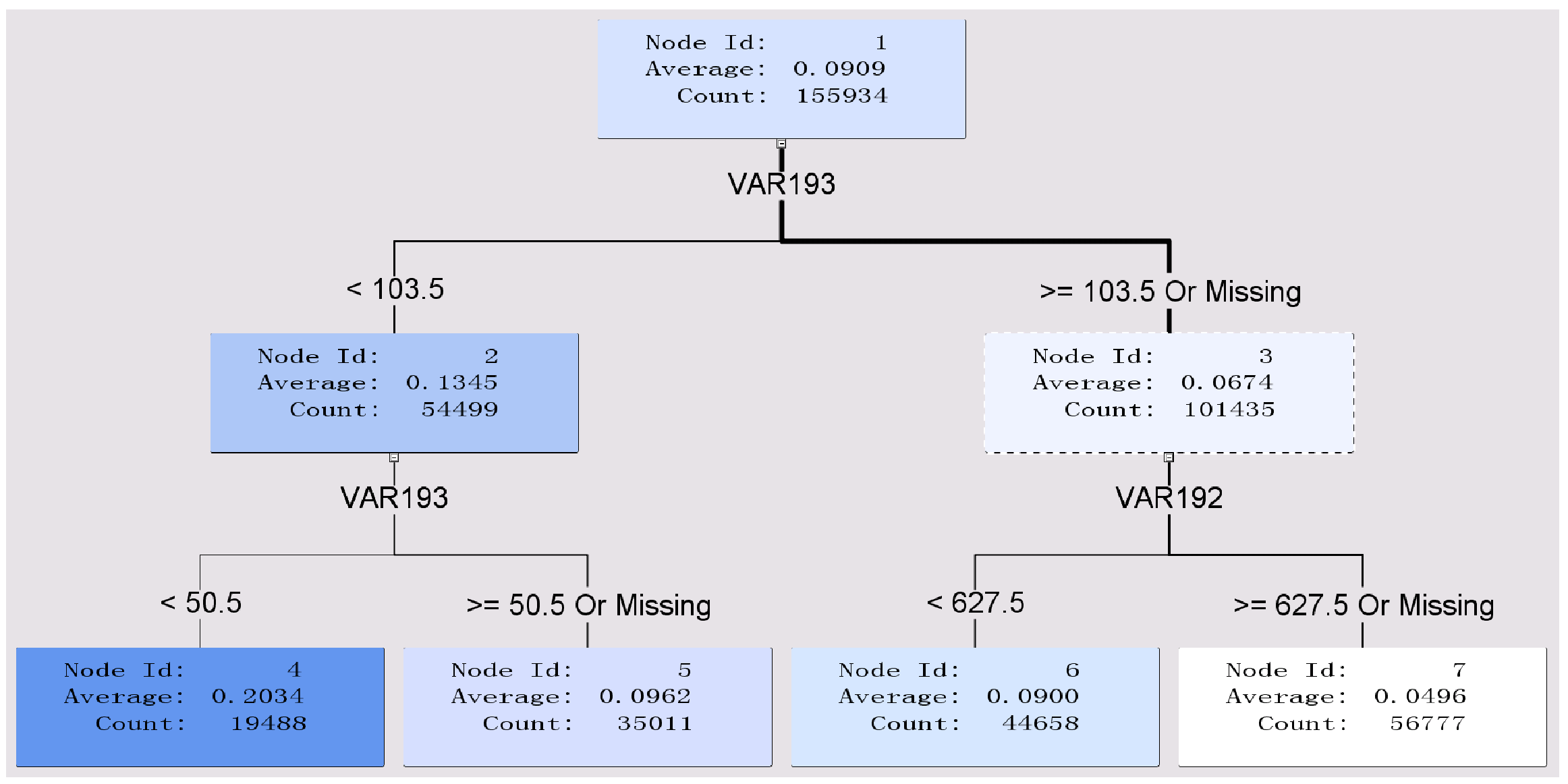
Node ID:
1、2、3为根节点,根节点下面还有分叉。
4、5、6、7为叶子节点,叶子节点下面没有分叉。
(2)决策树参数说明
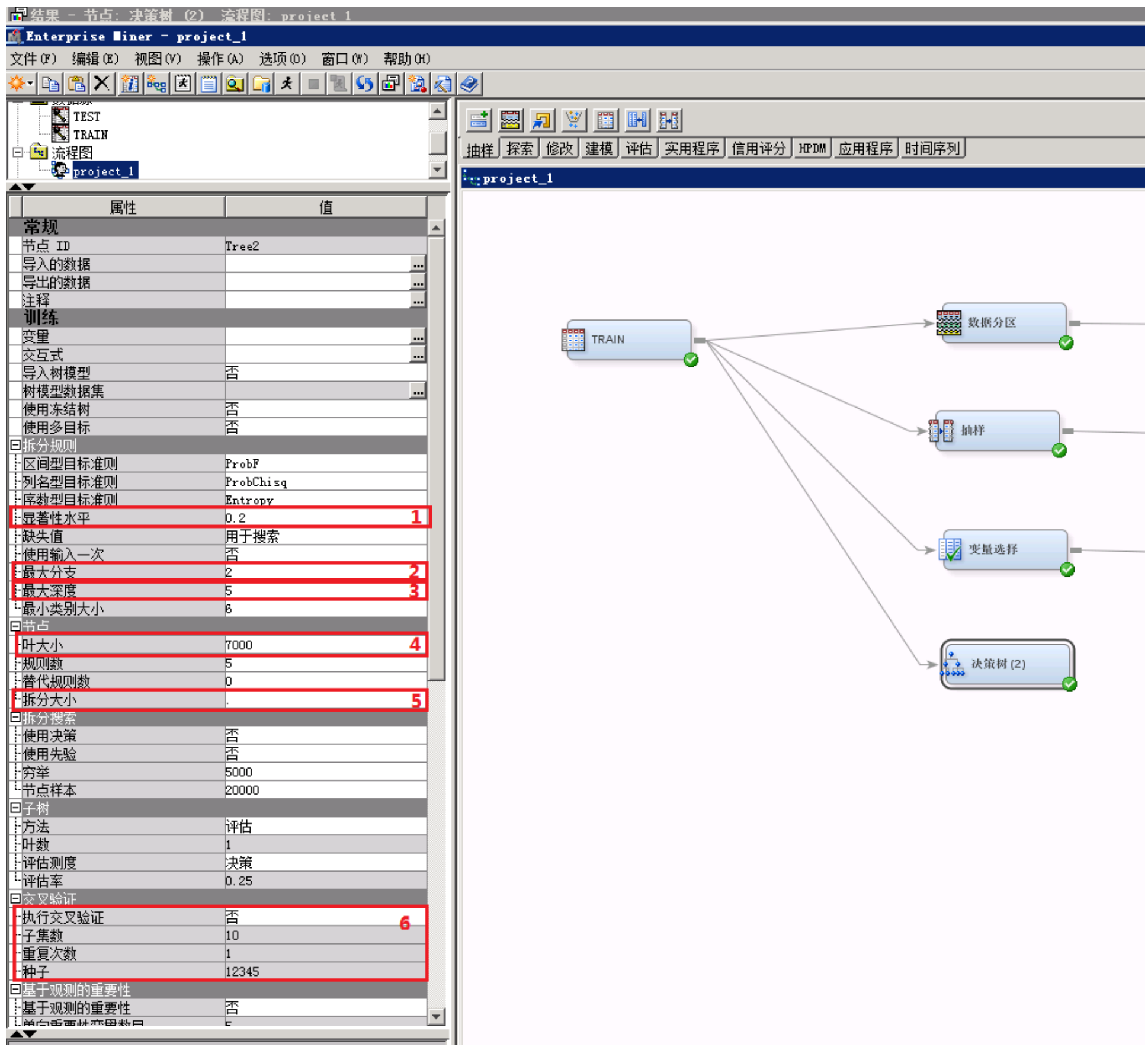
参见下图的决策树参数。
序号1:“显著性水平”越小表示决策树的拆分条件越严格,树的分叉也会越少。
序号2:“最大分支”表示一个节点能分出的最大分支数,2表示二叉树,3表示三叉树,n表示n叉树
序号3:“最大深度”表示一棵树的层数,比如一层二叉树最多有2个叶子节点,两层二叉树最多有4个叶子节点,n层二叉树最多有2^n个叶子节点。
序号4:“叶大小”表示每个叶子至少需要的样本量。
序号5:“拆分大小”:为使训练过程能够拆分某节点,该节点所必须具有的最小训练观测数。
序号6:“交叉验证”模块、“执行交叉验证”:(“是”,“否”两个选项)、“子集数”:用于交叉验证的子集的数量(随机等分生成),如果值为10,表示从训练数据随机等分生成10份子集。
3、变量设置
设置好决策树的参数之后,对变量进行选择编辑,将需要做决策树的X自变量的角色设定为“输入”,Y目标变量的角色设定为“目标”,其他与决策树无关的变量设定为“拒绝”,变量角色还有“ID”,“标签”,“频数”等多种,可根据自身需要设定。右键进入变量编辑界面的方式如下图所示:
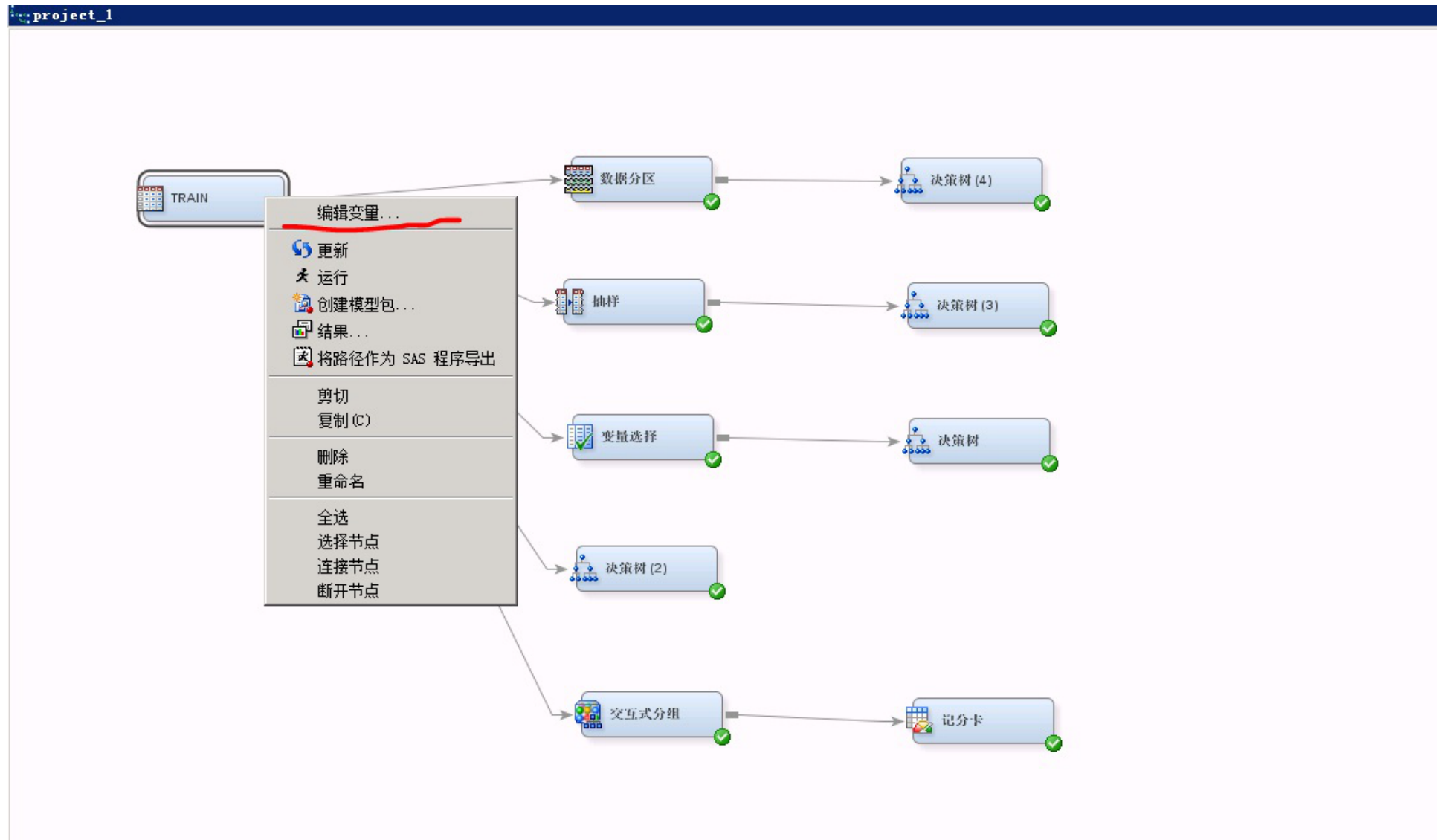
点击进入“编辑变量”界面之后: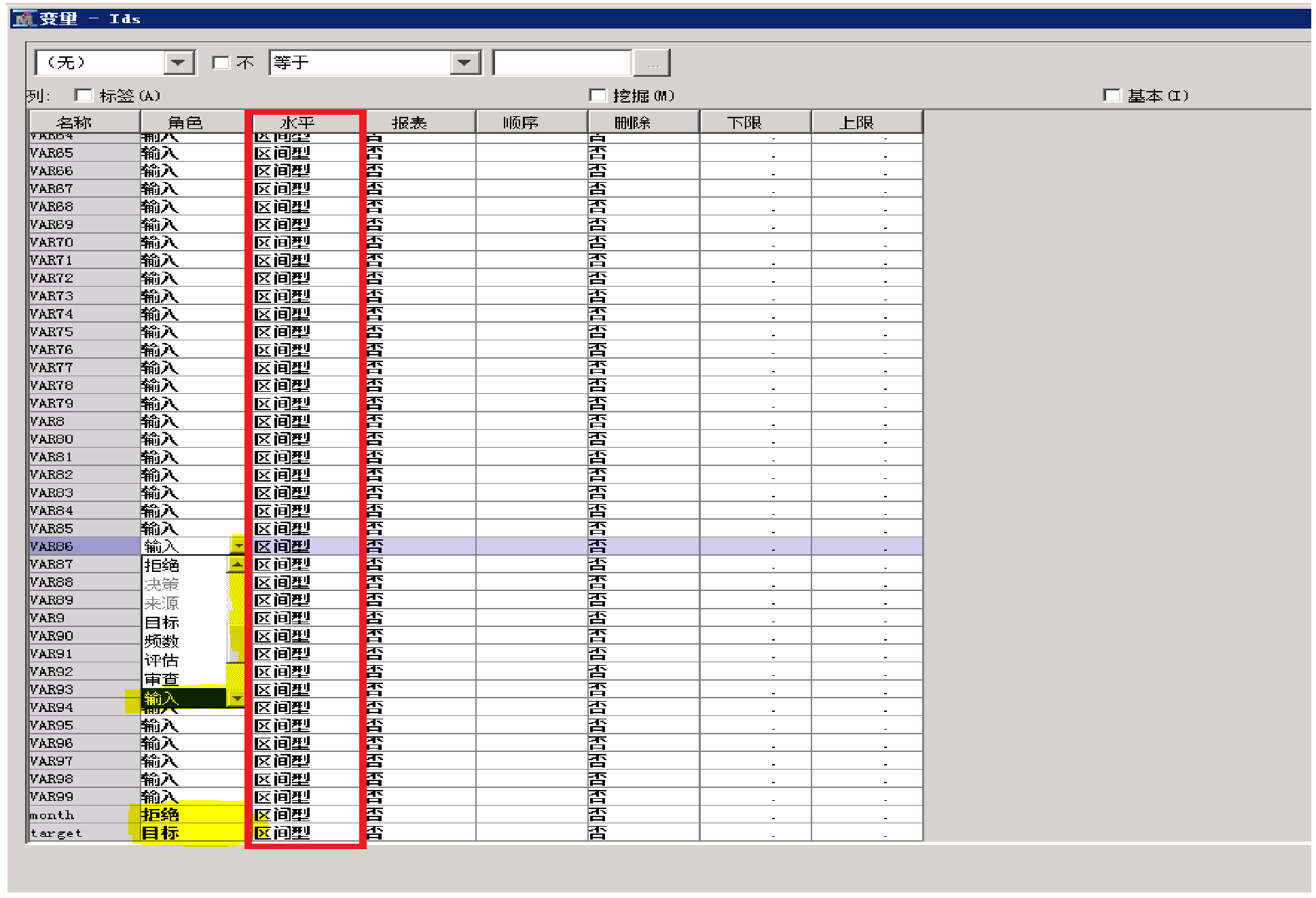
编辑变量时,点击每个变量的“角色”框,点击后会像图中出现箭头按钮,点击箭头按钮会出现下拉选项,然后就可以对变量进行角色编辑。红色框中的值用于变量的类型编辑,类似于角色编辑,点击后会有箭头按钮和下拉选项,选项包含“序数型”、“区间型”、“二值型”等多个选项,可根据自身需要设置。
如图,变量target角色为“目标”,month角色为“拒绝”,其他变量为“输入”。
4、决策树结果解读
(1)结果结构
主要看结果2和结果3。
结果2:决策树的树状结构。
结果3:决策树最终分类比较,各类的目标占比排序图。
注:通过 查看—评分—SAS代码 可以得到决策树的分群代码。利用该代码可以在样本外数据上进行分类。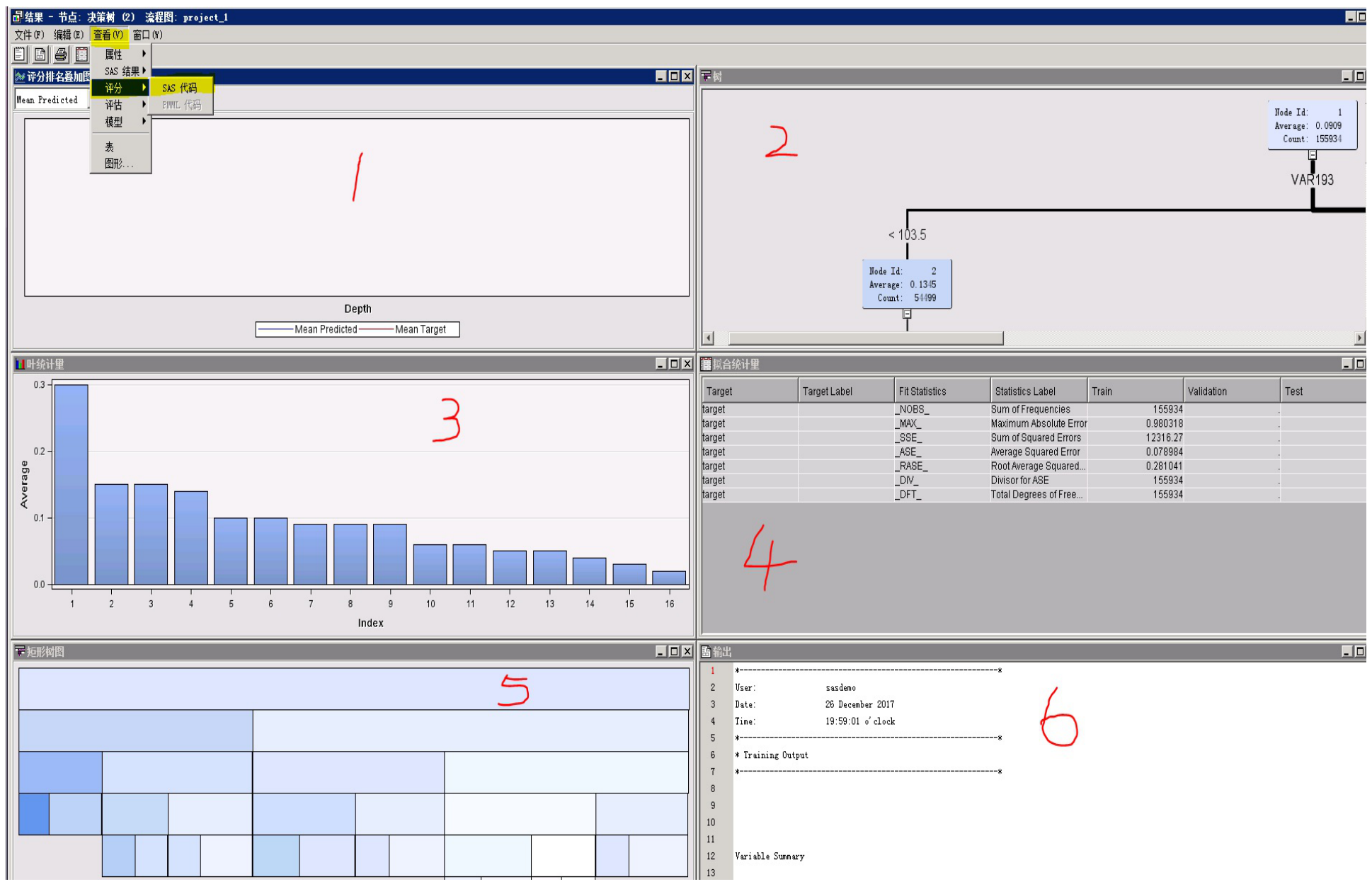
(2)决策树结构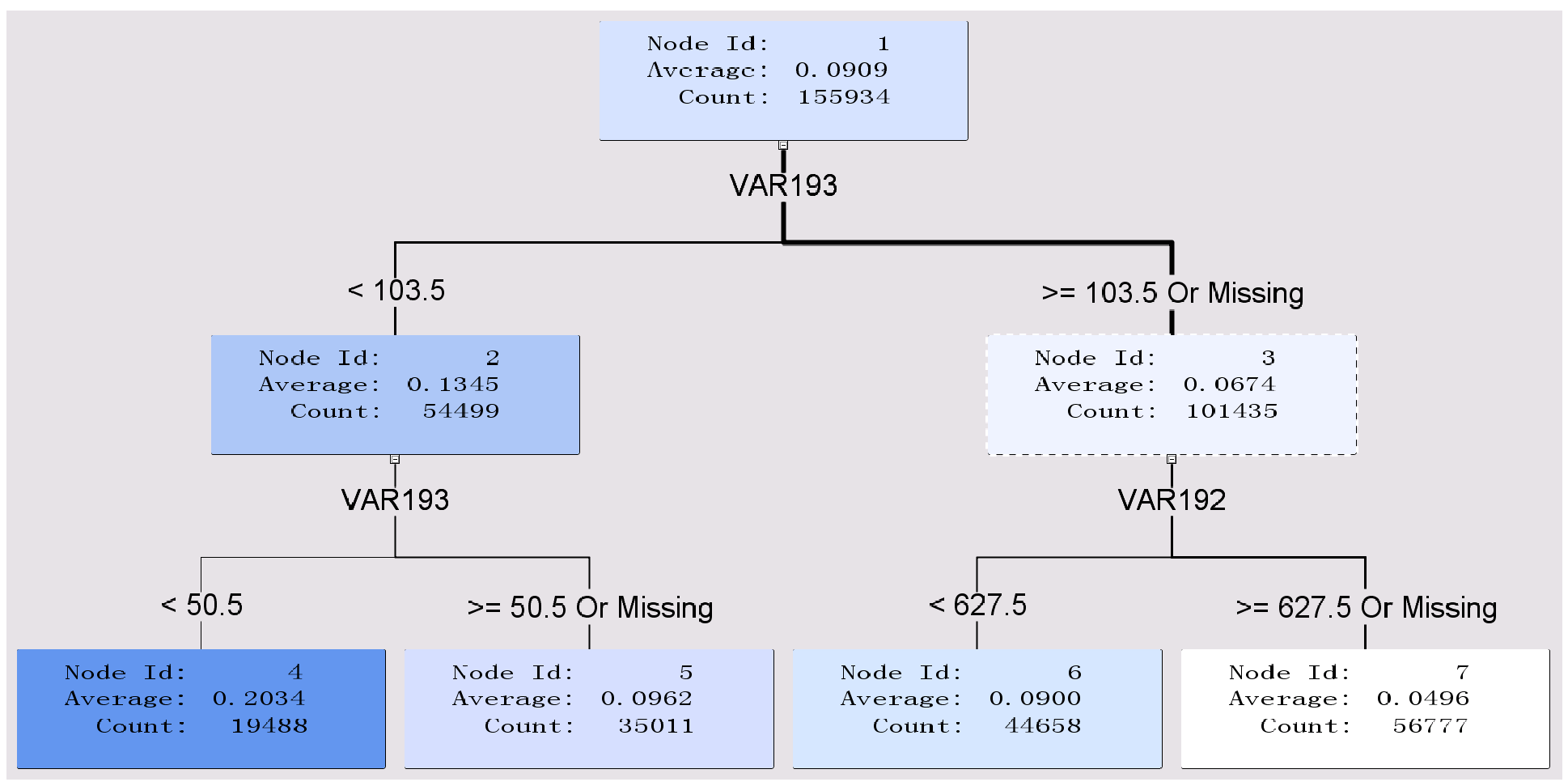
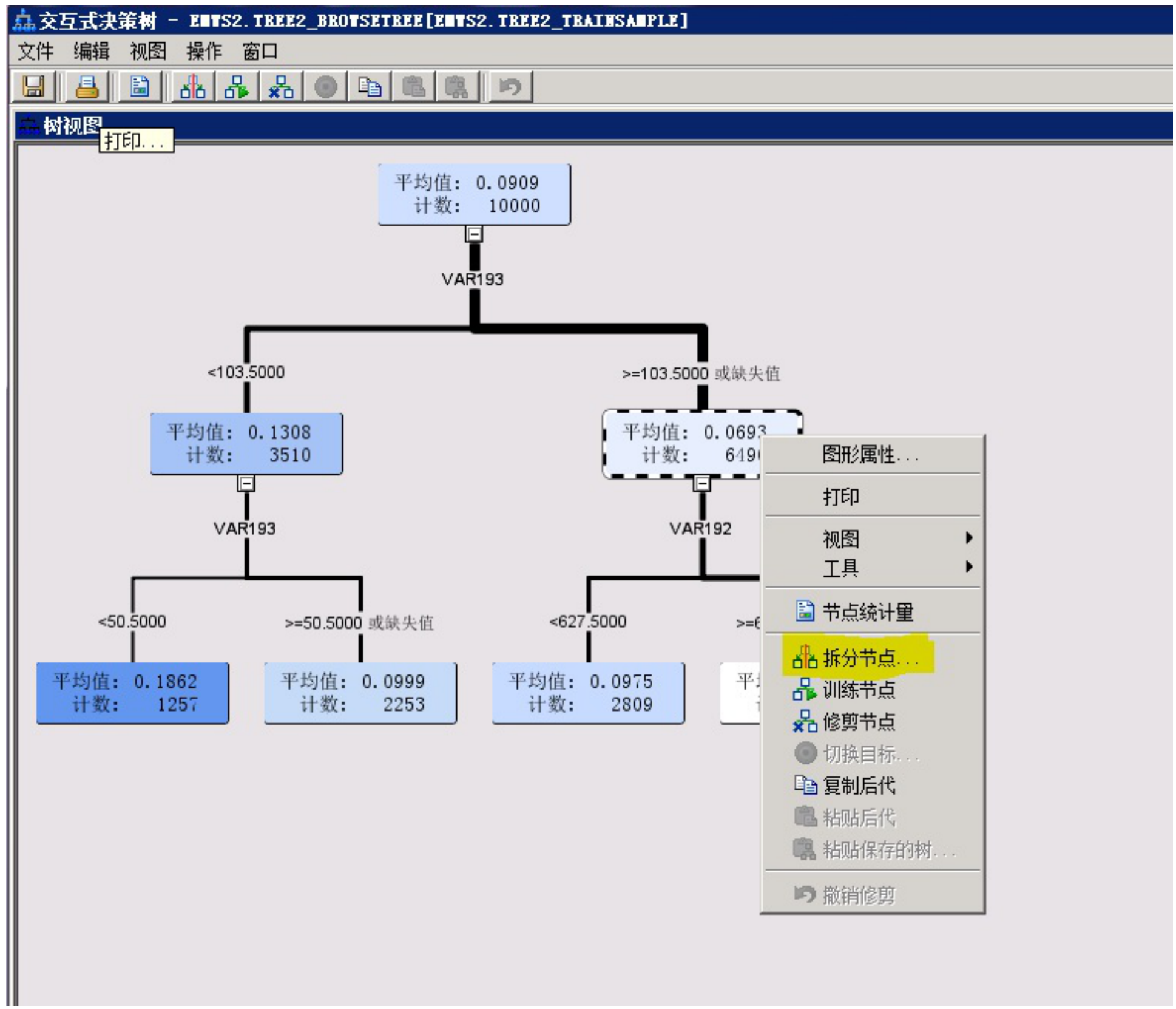
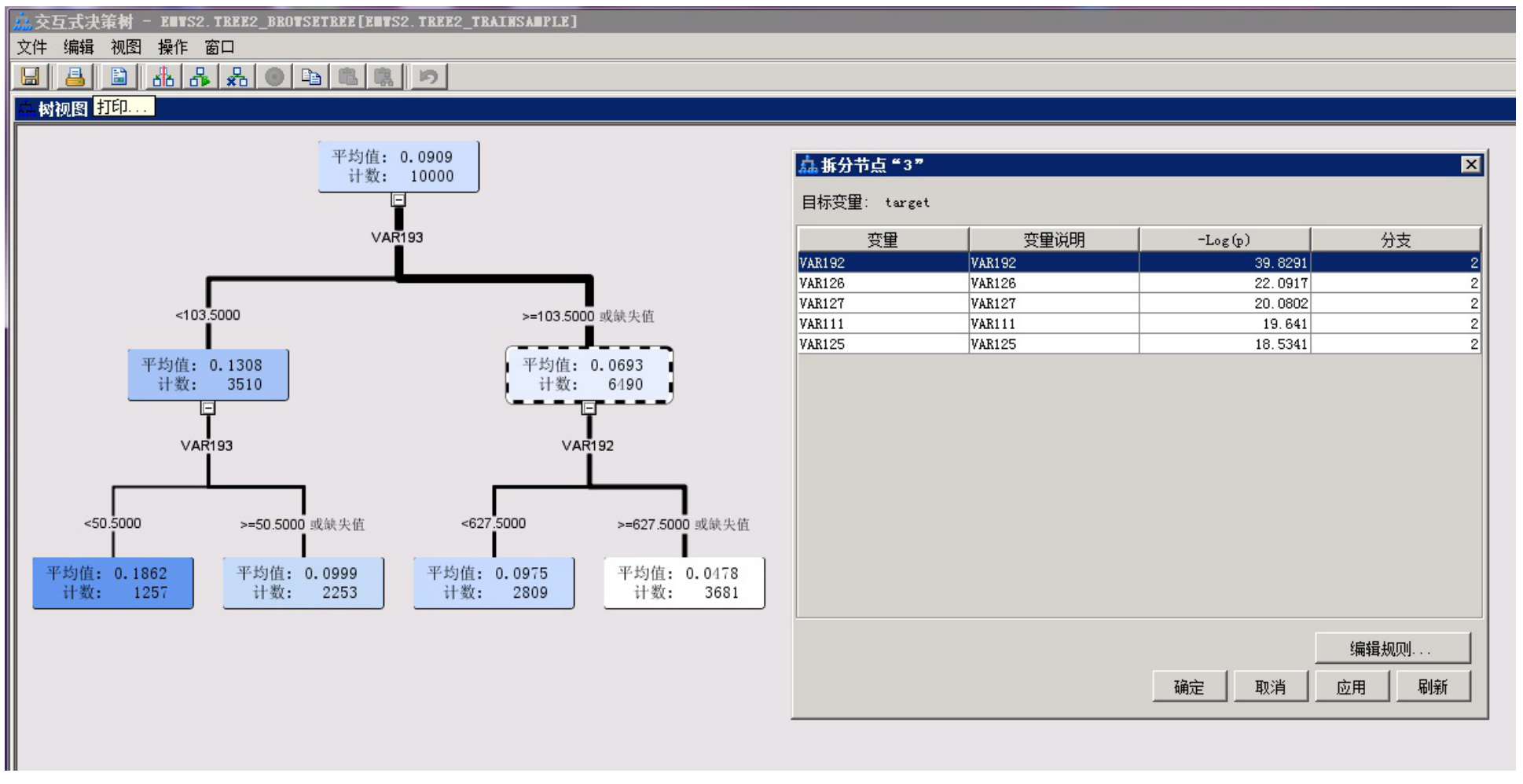
5、交互式决策树介绍
在决策树的交互式中使用者可以手动剪支、自主选择拆分的节点、自主选择变量,树的构造更加自主化,可以建立一个更符合用户需求的决策树。
5.3.2 FICO Model Builder
以下简介之:

5.3.3 Python建模
5.3.3.1 示例1
from sklearn.metrics import f1_scorefrom sklearn.datasets import make_classificationfrom sklearn.tree.tree import DecisionTreeClassifierfrom sklearn.linear_model import LogisticRegressionfrom sklearn.model_selection import train_test_splitX, Y = make_classification(n_samples=10000,n_features=1000,n_informative=10)trai_x, test_x, trai_y, test_y = train_test_split(X, Y, train_size=0.8)#clf = DecisionTreeClassifier()model = clf.fit(trai_x, trai_y)trai_yp = model.predict(trai_x)test_yp = model.predict(test_x)print(model,"F1, Trai:%.6f, Test:%.6f" %(f1_score(trai_y, trai_yp), f1_score(test_y, test_yp)))#clf = LogisticRegression()model = clf.fit(trai_x, trai_y)trai_yp = model.predict(trai_x)test_yp = model.predict(test_x)print(model,"F1, Trai:%.6f, Test:%.6f" %(f1_score(trai_y, trai_yp), f1_score(test_y, test_yp)))"""DecisionTreeClassifier() F1, Trai:1.000000, Test:0.825229LogisticRegression() F1, Trai:0.870911, Test:0.818482"""
更多代码可见笔者 https://github.com/IvanaXu/MLTools
5.3.3.2 示例2
import xgboost as xgbfrom sklearn.metrics import f1_scorefrom sklearn.datasets import make_classificationfrom sklearn.model_selection import train_test_splitX, Y = make_classification(n_samples=10000,n_features=1000,n_informative=10)trai_x, test_x, trai_y, test_y = train_test_split(X, Y, train_size=0.8)d_trai = xgb.DMatrix(trai_x, label=trai_y)d_test = xgb.DMatrix(test_x, label=test_y)params = {'booster': 'gbtree','objective': 'binary:logistic','eval_metric': 'auc','max_depth': 4,'lambda': 10,'subsample': 0.75,'colsample_bytree': 0.75,'min_child_weight': 2,'eta': 0.1,'seed': 0,'nthread': 8,'silent': 1}watchlist = [(d_trai, 'trai'), (d_test, 'test')]bst = xgb.train(params, d_trai, num_boost_round=10, evals=watchlist)trai_yp = [1 if _ > 0.5 else 0 for _ in bst.predict(xgb.DMatrix(trai_x))]test_yp = [1 if _ > 0.5 else 0 for _ in bst.predict(xgb.DMatrix(test_x))]print("> F1, Trai:%.6f, Test:%.6f" %(f1_score(trai_y, trai_yp), f1_score(test_y, test_yp)))"""[0] trai-auc:0.91909 test-auc:0.90353[1] trai-auc:0.93910 test-auc:0.92752[2] trai-auc:0.94048 test-auc:0.93123[3] trai-auc:0.94707 test-auc:0.93658[4] trai-auc:0.95164 test-auc:0.93956[5] trai-auc:0.95954 test-auc:0.94766[6] trai-auc:0.96100 test-auc:0.94903[7] trai-auc:0.96644 test-auc:0.95423[8] trai-auc:0.96803 test-auc:0.95668[9] trai-auc:0.96818 test-auc:0.95642> F1, Trai:0.913492, Test:0.893340"""
Xgboost建模示例。

若有收获,就点个赞吧
0 人点赞
