对上述提及模型指标进行公式推导细化,并举例试计算。
在此约定,公式行(1)为数学公式,公式行(2)为数值计算,若其结果不能整除,则保留小数点后4位。
如下:
5.5.1 示例模型
这里我们需要准备一个示例模型,用于后续试计算。
make_classification()创建二分类数据集;LogisticRegression()创建逻辑回归模型;
import pandas as pdfrom sklearn.datasets import make_classificationfrom sklearn.linear_model import LogisticRegressionX, Y = make_classification(n_samples=10000,n_features=1000,n_informative=5,n_redundant=5,flip_y=1)model = LogisticRegression()model.fit(X, Y)print(X.shape, Y.shape)print(pd.value_counts(Y))print(pd.value_counts(Y)/pd.value_counts(Y).sum())"""(10000, 1000) (10000,)0 50081 4992dtype: int640 0.50081 0.4992dtype: float64"""
现在,我们管这个示例模型叫。
5.5.2 变量筛选
、
对于二分类目标变量,一般用值(Information Value)以挑选变量。原理公式如下:
| Good | Bad | Good% | Bad% | |||
|---|---|---|---|---|---|---|
| … | ||||||
可解释为衡量特征包含预测变量浓度的指标。
示例如下,该变量各取值值以及总体
值:
| 非目标数 | 目标数 | 总计 | |||
|---|---|---|---|---|---|
| A61 | 386 | 217 | 603 | 0.271 | 0.047 |
| A62 | 69 | 34 | 103 | 0.140 | 0.002 |
| A63 | 52 | 11 | 63 | -0.707 | 0.027 |
| A64 | 42 | 6 | 48 | -1.099 | 0.044 |
| A65 | 151 | 32 | 183 | -0.704 | 0.077 |
| 700 | 300 | 1000 | 0.197 |
,有一定预测性。
一般认定,
5.5.3 混淆矩阵
5.5.3.1 相关指标
混淆矩阵(Confusion Matrix),以二分类为例,
| 预测\实际 | 0 | 1 |
|---|---|---|
| 0 | TN | FN |
| 1 | FP | TP |
在模型上,
| 预测\实际 | 0 | 1 |
|---|---|---|
| 0 | 3155 | 1822 |
| 1 | 1853 | 3170 |
- 准确率
原则上,准确率越大越好,但并不好量化优劣,毕竟存在模型输出均为0时准确率已达98%(若1占比仅2%)。
- 精确率
- 召回率
精确率与召回率,一般认定追求更高精准率将损失一定的召回率,反之同理。后将辅证之。
分数
鉴于精确率与召回率的关系,为能同时兼顾,引入精确率和召回率的调和平均数,定义为分数。
更一般的,我们定义分数:
%5Cfrac%7Bprecision%20%5Ctimes%20recall%7D%7B(%5Cbeta%20%5E%202%20%5Ctimes%20precision)%2Brecall%7D%0A#card=math&code=F_%5Cbeta%20%3D%20%281%2B%5Cbeta%5E2%29%5Cfrac%7Bprecision%20%5Ctimes%20recall%7D%7B%28%5Cbeta%20%5E%202%20%5Ctimes%20precision%29%2Brecall%7D%0A&id=CP1sl)
除了分数之外,
分数和
分数在统计学中也得到大量的应用:
其中,分数中,召回率的权重高于精确率,而
分数中,精确率的权重高于召回率。
分数
另外的,精确率和召回率的几何平均数定义为分数。
值
%5Ctimes(TN%2BFP)%2B(TP%2BFN)%5Ctimes(TP%2BFP)%7D%7B(TP%2BTN%2BFP%2BFN)%5E2%7D%20%5C%5C%20%26%3D%5Cfrac%7B(3155%2B1822)%5Ctimes(3155%2B1853)%20%2B%20(3170%2B1822)%5Ctimes(3170%2B1853)%7D%7B10000%5E2%7D%20%5C%5C%0A%26%5Capprox%200.5000%0A%5Cend%7Balign%7D%0A#card=math&code=%5Cbegin%7Balign%7D%0Ap_e%20%26%3D%20%5Cfrac%7B%28TN%2BFN%29%5Ctimes%28TN%2BFP%29%2B%28TP%2BFN%29%5Ctimes%28TP%2BFP%29%7D%7B%28TP%2BTN%2BFP%2BFN%29%5E2%7D%20%5C%5C%20%26%3D%5Cfrac%7B%283155%2B1822%29%5Ctimes%283155%2B1853%29%20%2B%20%283170%2B1822%29%5Ctimes%283170%2B1853%29%7D%7B10000%5E2%7D%20%5C%5C%0A%26%5Capprox%200.5000%0A%5Cend%7Balign%7D%0A&id=nrbce)
一般认定,
- 假阳性率
在所有的负样本中,分类器预测错误的比例:
- 真阳性率
在所有的正样本中,分类器预测正确的比例:
5.5.3.2 相互关系
理论上,这些公式从数学的角度可以推导相互关系,尽管有些比较复杂。
但我们可以应用“大数定律”来模拟:
import randomimport pandas as pdN = 5000result = []for _ in range(1000000):try:TP = random.randint(0, N)TN = random.randint(0, N-TP)FP = random.randint(0, N-TP-TN)FN = N-TP-TN-FPA = (TP+TN)/(N)P = TP/(TP+FP)R = TP/(TP+FN)F1 = (2*P*R)/(P+R)pe = ((TN+FN)*(TN+FP)+(TP+FN)*(TP+FP))/(N**2)K = (A-pe)/(1-pe)result.append([TP, TN, FP, FN, A, P, R, F1, pe, K])except:passcol = ["TP", "TN", "FP", "FN", "A", "P", "R", "F1", "pe", "K"]data = pd.DataFrame(result, columns=col)for icol in col:data["_"+icol] = [round(_,1) for _ in data[icol]]
如上我们可以知道:
pd.crosstab(data["_P"], data["_R"])
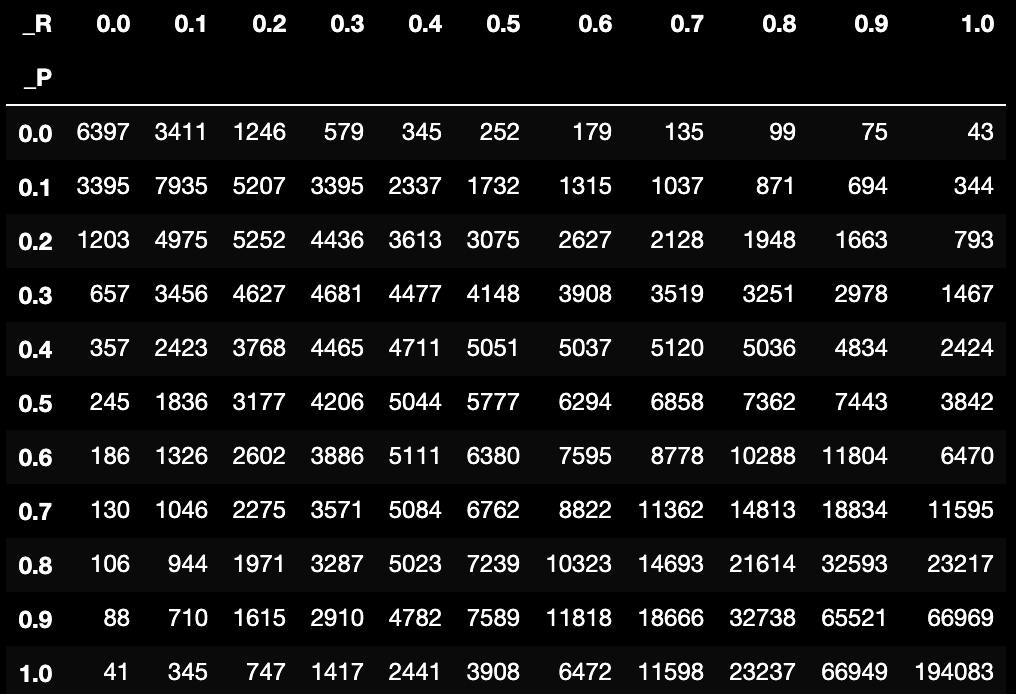
大部分情况下,追求值越高则
值越低,反之追求
值越高则
值越低。
pd.crosstab(data["_F1"], data["_K"])
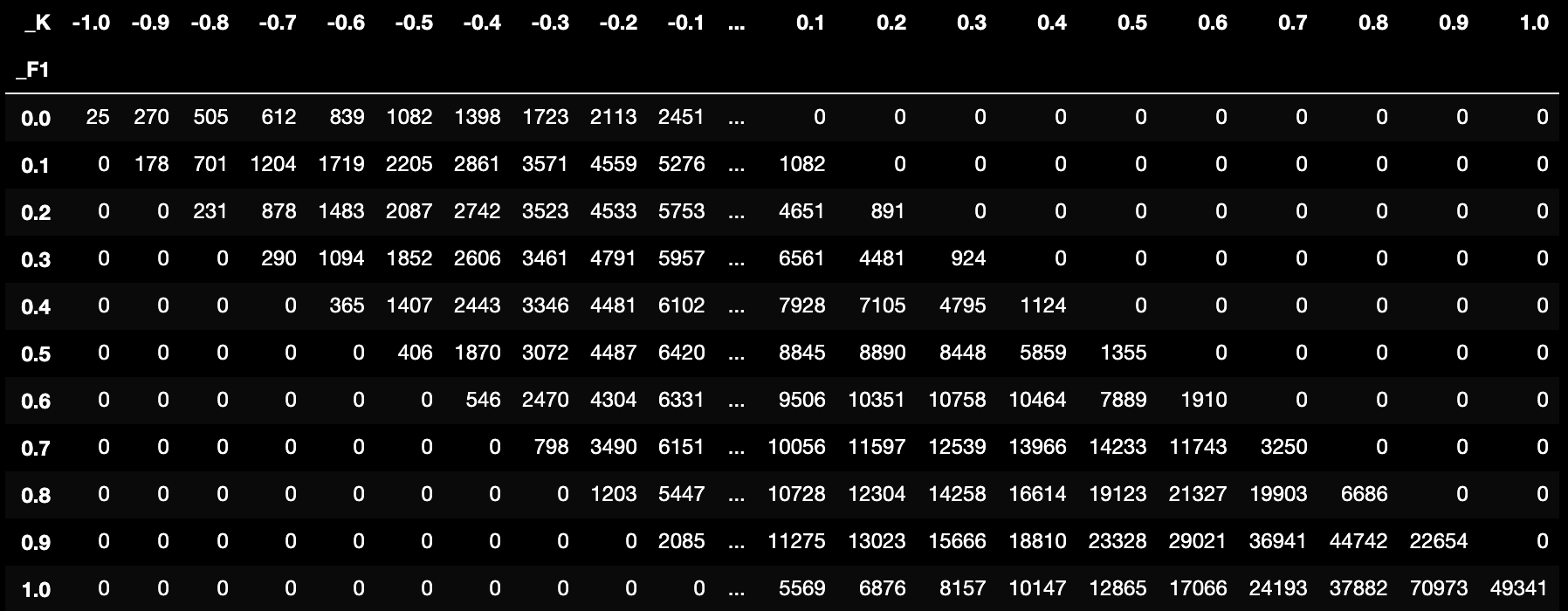
模型值越高,
越不可能为负值,更多结论可自行研究。
5.5.4 模型排序性
即排序性,常用来反映模型的排序能力。在信贷风控业务中,往往需要模型具有良好的排序性,如信用评分模型,业务希望按模型分数对客群进行划分后,分数高的客群的风险低于分数低的客群。
、
、
等指标常用来衡量模型的排序能力。
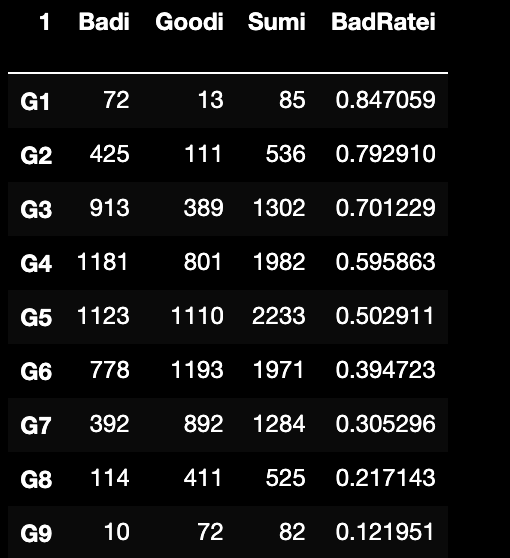
在模型上,根据模型预测概率/评分构建分组,如下:
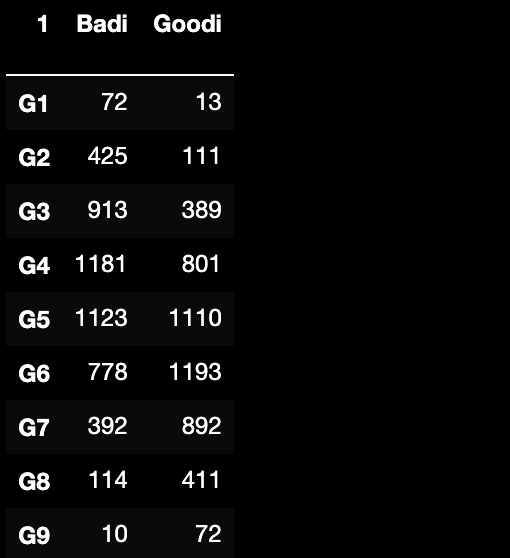
5.5.4.1 BadRate
即坏样本率,分组内坏样本数/分组内全部样本数;
且根据0 0.5008;1 0.4992;可知整体.
5.5.4.2 Odds
即好坏样本比,分组内坏样本数/分组内好样本数;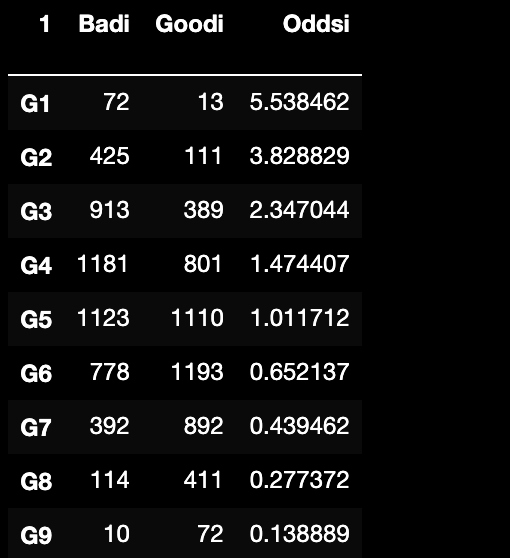
5.5.4.3 Lift
即提升度,分组内/整体样本
;
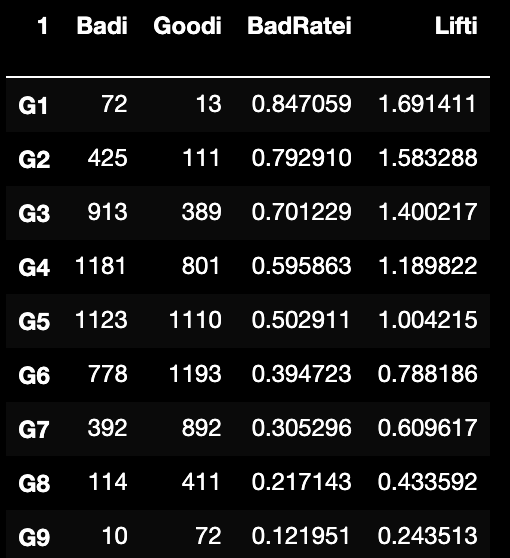
PS:这里Lift很受整体样本的影响,假设为0.25那么Lift上限不超过4
5.5.5 模型区分度
区分度即模型对好坏样本的区分能力。在信贷风控中,坏样本分数分布和好样本分布之间的区别越大,则模型对好坏样本的区分能力越强。为了进一步细化区分能力,在此介绍阈值(Cut Off)的概念。一般的,会把模型输出的预测概率如0.625,大于等于阈值0.5则定义预测结果为1,小于阈值0.5则定义预测结果为0,当然这个阈值可以被自定义修改,下面将介绍。
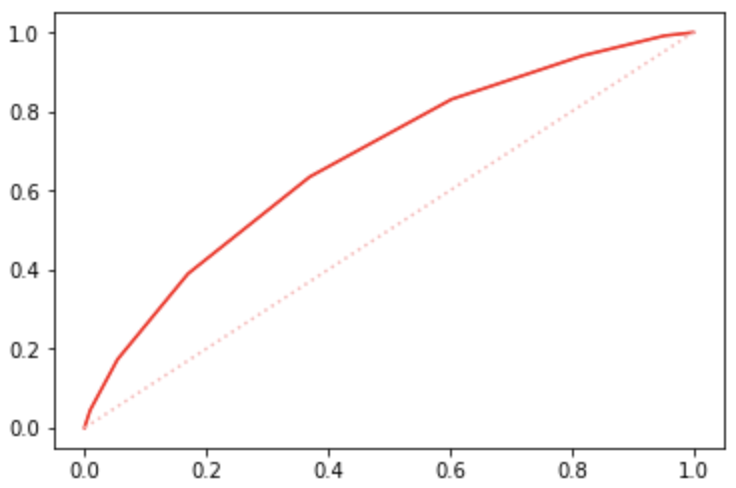
5.5.5.1 ROC曲线
曲线即
与
之间的关系曲线,其中x轴为
,y轴为
。显然
越高,也就是正样本中分类器预测正确,
越低,也就是负样本中分类器预测错误,这样的模型性能就越好。具体做法为:通过改变不同的阈值
,得到一系列混淆矩阵,进而得到一系列的
和
,绘制出
曲线。
在模型上,在每0.1一个阈值时可得到
如下:
0.0, 1.000000, 1.0000000.1, 0.998602, 0.9998000.2, 0.952476, 0.9917870.3, 0.818890, 0.9417070.4, 0.603235, 0.8313300.5, 0.370008, 0.6350160.6, 0.169928, 0.3898240.7, 0.054113, 0.1730770.8, 0.009185, 0.0448720.9, 0.000399, 0.0032051.0, 0.000000, 0.000000
进而得到曲线:
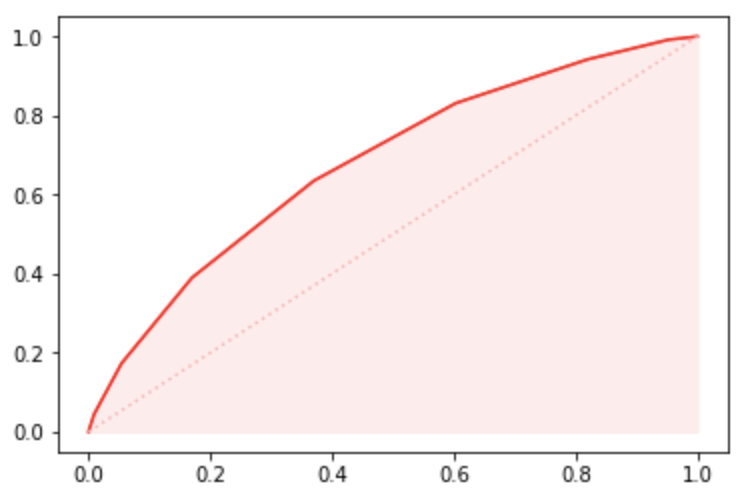
5.5.5.2 AUC
值为
曲线与坐标轴围成的区域面积。显然,
越大,则模型分类效果越好。
反映的是分类器对样本的排序能力。从物理意义上来说,
反映的是好样本的预测结果大于坏样本预测结果的概率
在模型上,
为0.6841,如下:
方法1
简单的,既然是曲线下的面积,面积可拆解为一个个小的梯形面积之和,具体计算的精度与阈值的精度有关。
方法2
在有个好样本、个坏样本的数据集中,共有对好坏样本组,(所谓一对好坏样本,即一个好样本与一个坏样本)。统计这对样本里,好样本的预测概率大于坏样本的预测概率的个数。
)%7D%7Bn_T%20%5Ctimes%20n_F%7D%0A#card=math&code=AUC%20%3D%20%5Cfrac%7B%5Csum%28I%28P_T%20%3E%20P_F%29%29%7D%7Bn_T%20%5Ctimes%20n_F%7D%0A&id=GnLSF)
#card=math&code=I%28P_T%20%3E%20P_F%29&id=Elozm)可理解为
1 if P_T > P_F else 0.
如:
| 样本 | label | 预测概率 |
|---|---|---|
| A | 0 | 0.1 |
| B | 0 | 0.4 |
| C | 1 | 0.35 |
| D | 1 | 0.8 |
有2个好样本、2个坏样本,共有4对好坏样本组#card=math&code=%28T%2CF%29&id=bCNKa),分别是:
%E3%80%81(C%2CB)%E3%80%81(D%2CA)%E3%80%81(D%2CB)%0A#card=math&code=%28C%2CA%29%E3%80%81%28C%2CB%29%E3%80%81%28D%2CA%29%E3%80%81%28D%2CB%29%0A&id=h6vzO)
那么,
)%7D%7Bn_T%20%5Ctimes%20n_F%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7BI(P_C%20%3E%20P_A)%20%2B%20I(P_C%20%3E%20P_B)%20%2B%20I(P_D%20%3E%20P_A)%20%2B%20I(P_D%20%3E%20P_B)%7D%7B4%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7BI(0.35%20%3E%200.1)%20%2B%20I(0.35%20%3E%200.4)%20%2B%20I(0.8%20%3E%200.1)%20%2B%20I(0.8%20%3E%200.4)%7D%7B4%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7B1%2B0%2B1%2B1%7D%7B4%7D%20%3D%200.75%5C%5C%0A%5Cend%7Balign%7D%0A#card=math&code=%5Cbegin%7Balign%7D%0AAUC%20%26%3D%20%5Cfrac%7B%5Csum%28I%28P_T%20%3E%20P_F%29%29%7D%7Bn_T%20%5Ctimes%20n_F%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7BI%28P_C%20%3E%20P_A%29%20%2B%20I%28P_C%20%3E%20P_B%29%20%2B%20I%28P_D%20%3E%20P_A%29%20%2B%20I%28P_D%20%3E%20P_B%29%7D%7B4%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7BI%280.35%20%3E%200.1%29%20%2B%20I%280.35%20%3E%200.4%29%20%2B%20I%280.8%20%3E%200.1%29%20%2B%20I%280.8%20%3E%200.4%29%7D%7B4%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7B1%2B0%2B1%2B1%7D%7B4%7D%20%3D%200.75%5C%5C%0A%5Cend%7Balign%7D%0A&id=DDDi5)
方法3
方法2存在重复计算的缺点,如上例时,已知%20%2B%20I(P_C%20%3E%20P_B)%20%3D2#card=math&code=I%28P_C%20%3E%20P_A%29%20%2B%20I%28P_C%20%3E%20P_B%29%20%3D2&id=NoX6v)时,如果,我们甚至都无需理会的具体值,就已经知道%20%2B%20I(P_D%20%3E%20P_B)%20%3D2#card=math&code=I%28P_D%20%3E%20P_A%29%20%2B%20I%28P_D%20%3E%20P_B%29%20%3D2&id=ryOZ8).那么,在有个好样本、个坏样本的数据集中,
(1)对预测概率从高到低排序;
(2)对每一个概率值设一个值(最高概率
,第二高概率
);
(3)把好样本的值求和再减去常数项
%7D%7B2%7D#card=math&code=%5Cfrac%7Bn_T%281%2Bn_T%29%7D%7B2%7D&id=LotSS)(有兴趣可自行推演);
这样可以计算复杂度将自#card=math&code=O%28n_T%20%5Ccdot%20n_F%29&id=Odows)降至#card=math&code=O%28n_T%2Bn_F%29&id=wWgUv),得到:
%7D%7B2%7D%2B%5Csum_i%7Brank_i%7CT%7D%7D%7Bn_T%20%5Ctimes%20n_F%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7B-%5Cfrac%7B2(1%2B2)%7D%7B2%7D%2B(4%2B2)%7D%7B4%7D%20%3D%20%5Cfrac%7B-3%2B6%7D%7B4%7D%20%3D%200.75%0A%5Cend%7Balign%7D%0A#card=math&code=%5Cbegin%7Balign%7D%0AAUC%20%26%3D%20%5Cfrac%7B-%5Cfrac%7Bn_T%281%2Bn_T%29%7D%7B2%7D%2B%5Csum_i%7Brank_i%7CT%7D%7D%7Bn_T%20%5Ctimes%20n_F%7D%20%5C%5C%0A%26%3D%20%5Cfrac%7B-%5Cfrac%7B2%281%2B2%29%7D%7B2%7D%2B%284%2B2%29%7D%7B4%7D%20%3D%20%5Cfrac%7B-3%2B6%7D%7B4%7D%20%3D%200.75%0A%5Cend%7Balign%7D%0A&id=xUMLZ)
一般认定,
5.5.5.3 洛伦兹曲线
洛伦兹曲线最先用来描述社会收入不均衡的现象,在一个总体(国家、地区)内,以“最贫穷的人口计算起一直到最富有人口”的人口百分比对应各个人口百分比的收入百分比的点组成的曲线。为了研究国民收入在国民之间的分配问题,统计学家 M.O.洛伦兹提出了著名的洛伦兹曲线。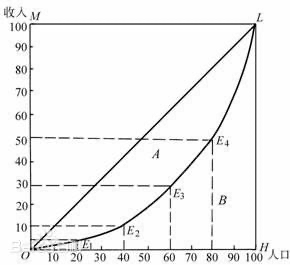
首先将全社会的人按照收入升序排序,然后计算累计前的人的收入占社会总收入的百分之几,这个数值就是对应
的
,洛伦兹曲线就是这一函数的图像。例如:假设收入最低的前1%的人其收入占比为1%,前2%的人收入占比为2%……前99%的人收入占比为99%,那么洛伦兹曲线就与收入分配绝对平等直线重合,此时全社会所有人的收入都是一样的。再如:假设收入最低的前99%的人其收入占比为50%,那就意味着剩下1%的人拿走了全社会50%的收入,此时洛伦兹曲线严重偏离收入分配绝对平等直线。显然,社会收入越平均,洛伦兹曲线越接近收入分配绝对平等直线。
将其引入模型领域,计算步骤:
(1)计算各分组内的好坏账户数;
(2)计算各分组内的累计好账户数占总好账户数比率、累计坏账户数占总坏账户数比率;
(3)按照累计好账户占比和累计坏账户占比得出洛伦兹曲线;
在模型上,在每一个评分分组可得到
如下:
G1, 0.014377, 0.002604G2, 0.099241, 0.024840G3, 0.281550, 0.102764G4, 0.517372, 0.263221G5, 0.741613, 0.485577G6, 0.896965, 0.724559G7, 0.975240, 0.903245G8, 0.998003, 0.985577G9, 1.000000, 1.000000
进而得到洛伦兹曲线: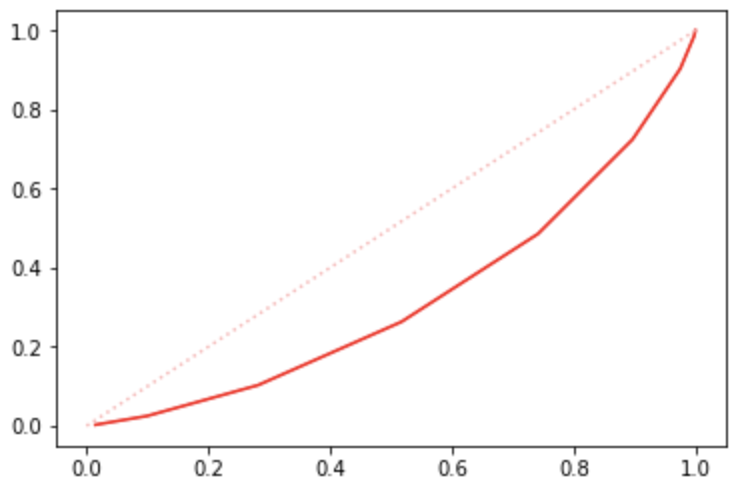
5.5.5.4 Gini
系数是指绝对公平线和洛伦兹曲线围成的面积与绝对公平线以下面积的比例。
在模型上,
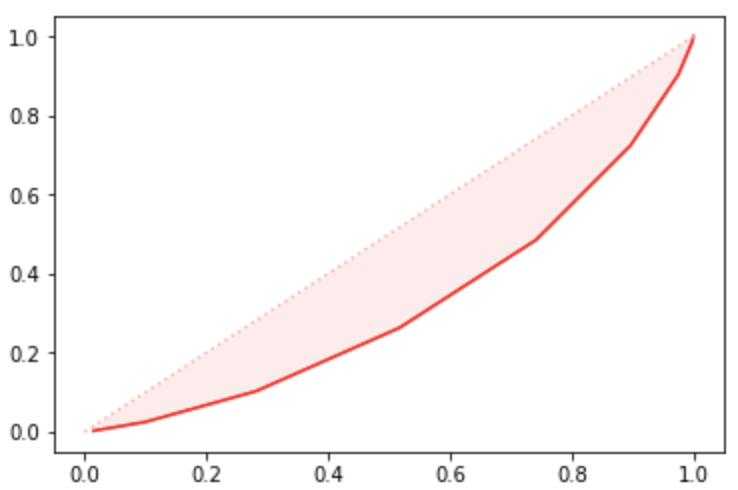
推演逻辑可参考AUC计算。
5.5.5.5 KS
(Kolmogorov-Smirnov)用于模型风险区分能力进行评估,指标衡量的是好坏样本累计分部之间的差值。好坏样本累计差异越大,
指标越大,那么模型的风险区分能力越强。
计算步骤:
(1)计算各分组内的好坏账户数;
(2)计算各分组内的累计好账户数占总好账户数比率、累计坏账户数占总坏账户数比率;
(3)计算各分组内的累计坏账户占比与累计好账户占比差的绝对值,然后对这些绝对值取最大值即KS值;
)%0A#card=math&code=KS%20%3D%20max%28abs%28%5Cfrac%7BCumBad_i%7D%7BSumBab_i%7D%20-%20%5Cfrac%7BCumBad_i%7D%7BSumBab_i%7D%29%29%0A&id=C8WjR)
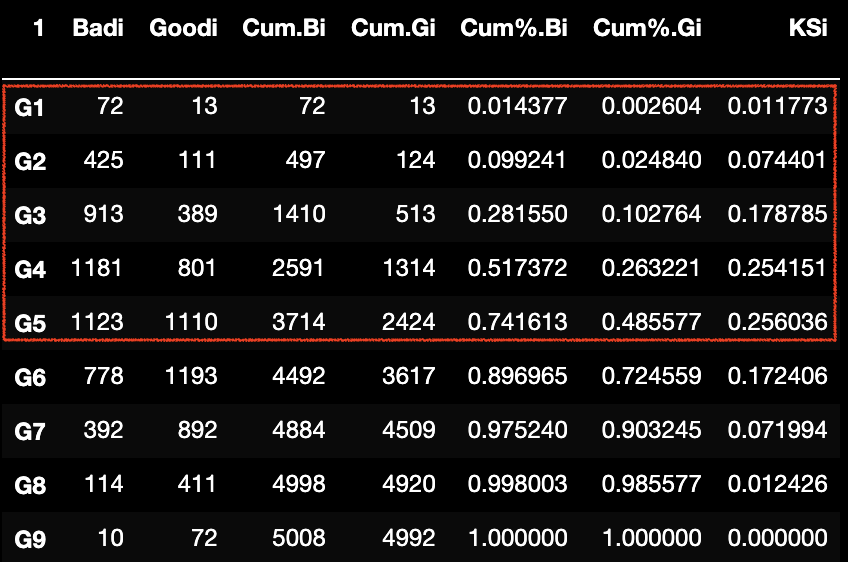
在模型上,
为0.2560,
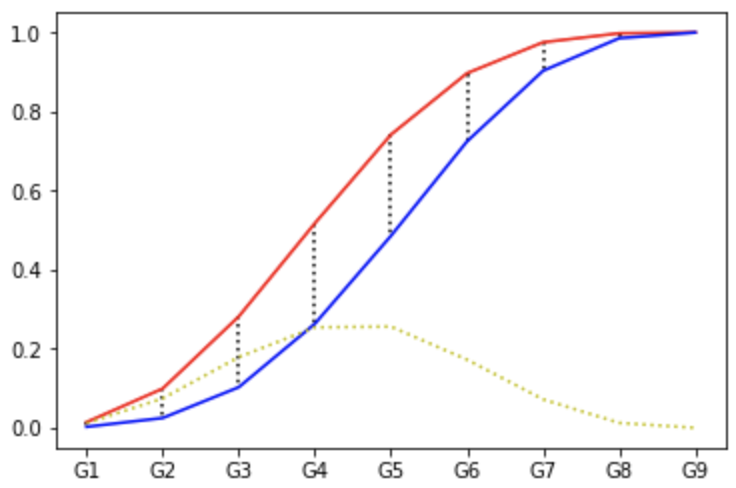
这里,我们可以做这样的理解,当模型选择拒绝
所在组
以及评分分组以下时,在拒绝74.16%坏样本作为“收益”的同时,也付出了错误拒绝48.56%好样本的“代价”。那么
就是在体现这种收益与代价差距的最大化。如果可能的话,我们希望
是64%,那么在拒绝相同的74.16%坏样本作为“收益”时,仅付出错误拒绝10.16%好样本的“代价”。
一般认定,
5.5.6 模型稳定性
5.5.6.1 PSI
指标是指群体稳定性指数(Population Stability Index),
反映了不同样本在各分数段的分布的稳定性。
计算公式:
%20%5Ctimes%20%5Cln(Ai%2FE_i)%0A#card=math&code=PSI%20%3D%20%5Csum%7Bi%3D1%7D%5En%20%28A_i%20-%20E_i%29%20%5Ctimes%20%5Cln%28A_i%2FE_i%29%0A&id=z96r9)
其中,表示实际Actual样本,
表示预期Excepted样本。
一般认定,
如下示例:
| 序号 | Score | ||||||
|---|---|---|---|---|---|---|---|
| 1 | (500, 550] | 12.0% | 5.0% | 2.4 | 0.88 | 7.0% | 0.061 |
| 2 | (550, 600] | 15.0% | 8.0% | 1.875 | 0.63 | 7.0% | 0.044 |
| 3 | (600, 650] | 33.0% | 30.0% | 1.1 | 0.10 | 3.0% | 0.003 |
| 4 | (650, 700] | 18.0% | 25.0% | 0.72 | -0.33 | -7.0% | 0.023 |
| 5 | (700, 750] | 12.0% | 14.0% | 0.857 | -0.15 | -2.0% | 0.003 |
| 6 | (750, 800] | 8.0% | 10.0% | 0.8 | -0.22 | -2.0% | 0.004 |
| 7 | (800, 850] | 1.0% | 5.0% | 0.2 | -1.61 | -4.0% | 0.064 |
| 8 | (850, 900] | 1.0% | 2.0% | 0.5 | -0.69 | -1.0% | 0.007 |
| 9 | (900, 950] | 0.0% | 1.0% | 0.01 | -4.61 | -1.0% | 0.046 |
| 10 | (950, 1000] | 0.0% | 0.0% | / | 0.00 | 0.0% | 0.000 |
| 0.256 |
5.5.6.2 CSI
指标是指特定稳定性指数(Characteristic Stability Index),用来衡量样本在特征层面上的分布变化,反映了特征对评分卡分数变化的影响。当评分卡主模型分数发生变化时,对每个特征计算
I,可以知道哪些特征分布发生变化从而导致的评分卡主模型分数偏移以及哪个特征对模型得分变化的影响最大。
计算公式:
%20Scorei%0A#card=math&code=CSI%20%3D%20%5Csum%7Bi%3D1%7D%5En%20%28A_i%20-%20E_i%29%20Score_i%0A&id=qaA6g)
其中,表示实际Actual样本,
表示预期Excepted样本,Score表示分箱分值。
| 序号 | Score | ||||||
|---|---|---|---|---|---|---|---|
| 1 | (0, 0.5] | 21.1% | 24.4% | 0.865 | 17 | -3.3% | -0.561 |
| 2 | (0.5, 1.2] | 24.0% | 24.5% | 0.980 | 19 | -0.5% | -0.095 |
| 3 | (1.2, 3.1] | 16.2% | 15.7% | 1.038 | 26 | 0.5% | 0.13 |
| 4 | (3.1, 6.0] | 21.1% | 16.9% | 1.249 | 30 | 4.2% | 1.26 |
| 5 | (6.0, +) | 17.4% | 18.4% | 0.946 | 40 | -1.0% | -0.40 |
| 0.334 |
5.5.7 代码摘要
以下摘要上述推演过程的Python代码:
import pandas as pdfrom sklearn.metrics import *import matplotlib.pyplot as pltfrom sklearn.datasets import make_classificationfrom sklearn.linear_model import LogisticRegressionX, Y = make_classification(n_samples=10000,n_features=1000,n_informative=5,n_redundant=5,flip_y=1)model = LogisticRegression()model.fit(X, Y)#print(X.shape, Y.shape)print(pd.value_counts(Y)/pd.value_counts(Y).sum())print(pd.value_counts(Y))#print("%.4f" % accuracy_score(model.predict(X), Y),"%.4f" % f1_score(model.predict(X), Y),"%.4f" % precision_score(model.predict(X), Y),"%.4f" % recall_score(model.predict(X), Y))fpr, tpr, thresholds = roc_curve(Y, model.predict_proba(X)[:,1], pos_label=1)print("AUC: %.4f" % auc(fpr, tpr))#vBadRate = pd.value_counts(Y)[0]/pd.value_counts(Y).sum()print(vBadRate)#print(pd.crosstab(model.predict(X), Y))#data = pd.DataFrame([f"G{int(round(_, 1)*10)}"for _ in model.predict_proba(X)[:,1]])data[1] = Y_rb = pd.crosstab(data[0], data[1])_rb.index.name = ""_rb.rename_axis({0:"Badi", 1:"Goodi"}, inplace=True, axis=1)print(_rb)#_r = _rb.copy()_r["Sumi"] = _r["Badi"] + _r["Goodi"]_r["BadRatei"] = _r["Badi"]/_r["Sumi"]print(_r)#_r = _rb.copy()_r["Oddsi"] = _r["Badi"]/_r["Goodi"]print(_r)#_r = _rb.copy()_r["BadRatei"] = _r["Badi"]/(_r["Badi"]+_r["Goodi"])_r["Lifti"] = _r["BadRatei"]/vBadRateprint(_r)#_r = _rb.copy()_ = 0def f(i):global __ += ireturn __r["Cum.Bi"] = _r["Badi"].apply(f)_ = 0def f(i):global __ += ireturn __r["Cum.Gi"] = _r["Goodi"].apply(f)print(max(_r["Cum.Bi"]), max(_r["Cum.Gi"]))_r["Cum%.Bi"] = _r["Cum.Bi"]/max(_r["Cum.Bi"])_r["Cum%.Gi"] = _r["Cum.Gi"]/max(_r["Cum.Gi"])_r["KSi"] = _r["Cum%.Bi"] - _r["Cum%.Gi"]_r["KSi"] = [abs(_) for _ in _r["KSi"]]print(_r)#plt.plot(_r.index, _r["Cum%.Bi"], color="r")plt.plot(_r.index, _r["Cum%.Gi"], color="b")plt.plot(_r.index, _r["Cum%.Bi"]-_r["Cum%.Gi"], color="y", linestyle=":")for i, j1, j2 in zip(_r.index, _r["Cum%.Bi"], _r["Cum%.Gi"]):plt.vlines(i, ymin=j1, ymax=j2, colors="k", linestyle=":")plt.show()#print(_r[["Cum%.Bi", "Cum%.Gi"]])plt.plot(_r["Cum%.Bi"], _r["Cum%.Gi"], color="r")plt.plot([0, 1.0], [0, 1.0], color="#FFB5B5", linestyle=":")plt.fill_between([_ for _ in _r["Cum%.Bi"]], [_ for _ in _r["Cum%.Gi"]], [_ for _ in _r["Cum%.Bi"]],color="#FFECEC")plt.show()#print(_r[["Cum%.Bi", "Cum%.Gi"]])plt.plot(_r["Cum%.Bi"], _r["Cum%.Gi"], color="r")plt.plot([0, 1.0], [0, 1.0], color="#FFB5B5", linestyle=":")plt.show()#data = pd.DataFrame(model.predict_proba(X)[:,1])data[1] = Y_rP1, _rP2 = [], []for icut in range(0, 101, 10):try:icut = icut/100data[2] = [1 if _ >= icut else 0 for _ in data[0]]_rC = pd.crosstab(data[2], data[1])TN, FP, FN, TP = _rC[0][0], _rC[0][1], _rC[1][0], _rC[1][1]FPR = FP/(FP + TN)TPR = TP/(TP + FN)_rP1.append([FPR, TPR])_rP2.append([icut, icut])except:FPR, TPR = 1-icut, 1-icut_rP1.append([FPR, TPR])_rP2.append([icut, icut])print("%.1f, %.6f, %.6f" % (icut, FPR, TPR))plt.plot([_[0] for _ in _rP1], [_[1] for _ in _rP1], color="r")plt.plot([_[0] for _ in _rP2], [_[1] for _ in _rP2], color="#FFB5B5", linestyle=":")plt.show()#data = pd.DataFrame(model.predict_proba(X)[:,1])data[1] = Y_rP1, _rP2 = [], []for icut in range(0, 101, 10):try:icut = icut/100data[2] = [1 if _ >= icut else 0 for _ in data[0]]_rC = pd.crosstab(data[2], data[1])TN, FP, FN, TP = _rC[0][0], _rC[0][1], _rC[1][0], _rC[1][1]FPR = FP/(FP + TN)TPR = TP/(TP + FN)_rP1.append([FPR, TPR])_rP2.append([icut, icut])except:FPR, TPR = 1-icut, 1-icut_rP1.append([FPR, TPR])_rP2.append([icut, icut])print("%.2f, %.6f, %.6f" % (icut, FPR, TPR))plt.plot([_[0] for _ in _rP1], [_[1] for _ in _rP1], color="r")plt.plot([_[0] for _ in _rP2], [_[1] for _ in _rP2], color="#FFB5B5", linestyle=":")plt.fill_between([_[0] for _ in _rP1], [_[1] for _ in _rP1], [0 for _ in _rP1],color="#FFECEC")plt.show()

若有收获,就点个赞吧
0 人点赞
