站在智能金融的最前沿:人工智能在金融领域的最新应用(杨青,度小满金融)回放链接
笔者对此展开如下思考:
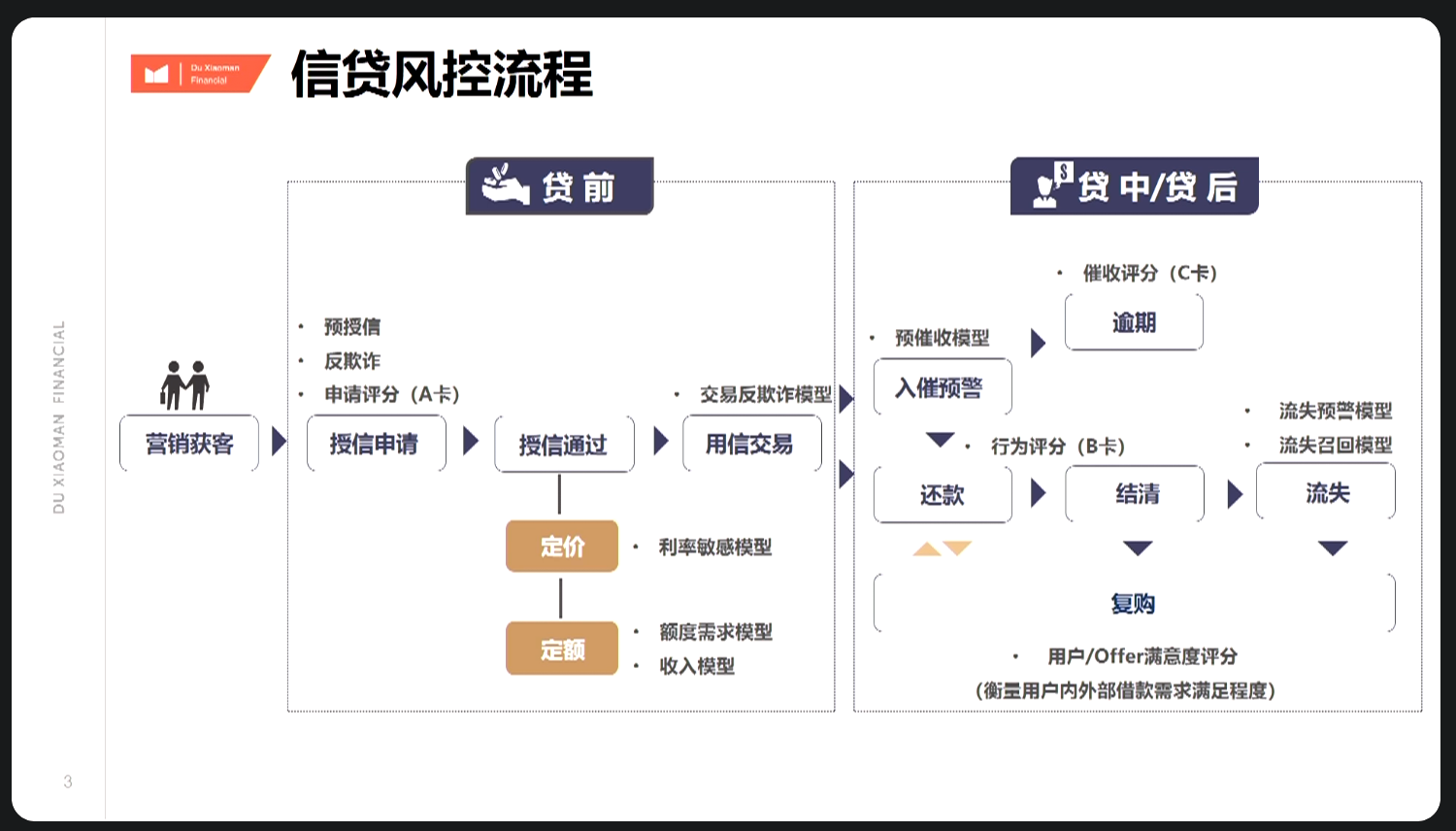
7.1.1 信贷风控流程
7.1.2 风险画像体系
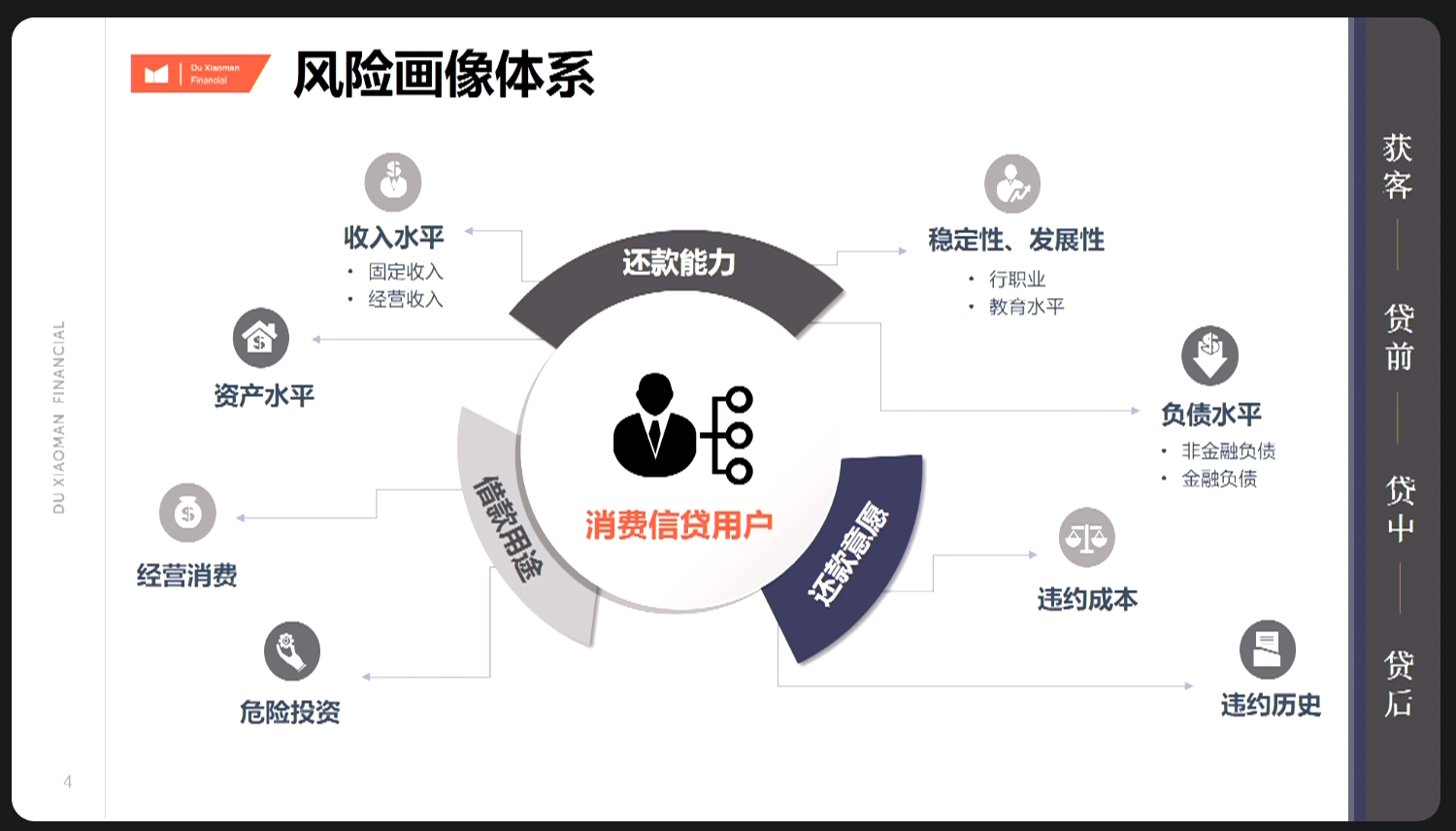
业务点:收入、负债模型优化
7.1.3 传统风控模型
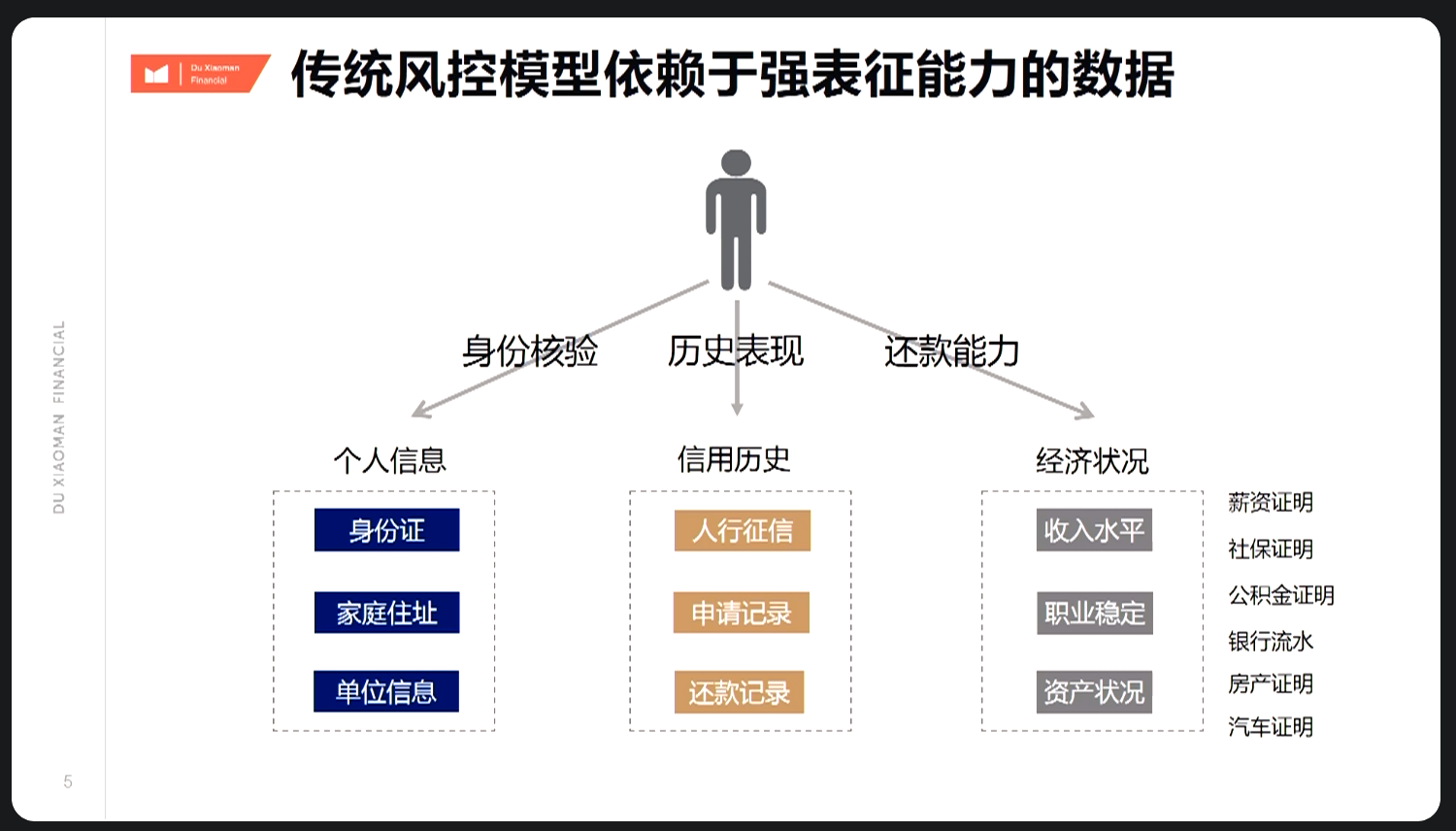

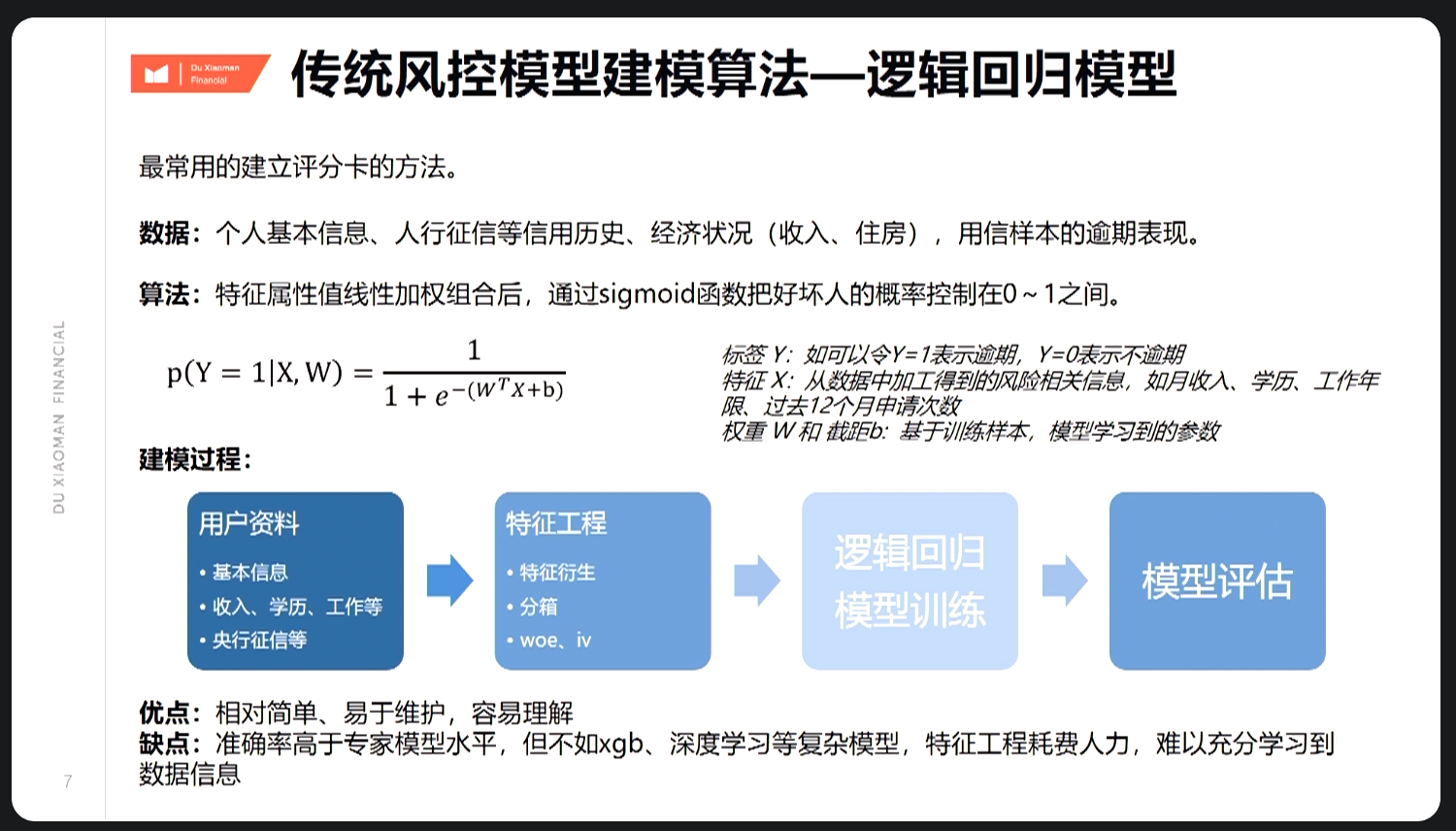
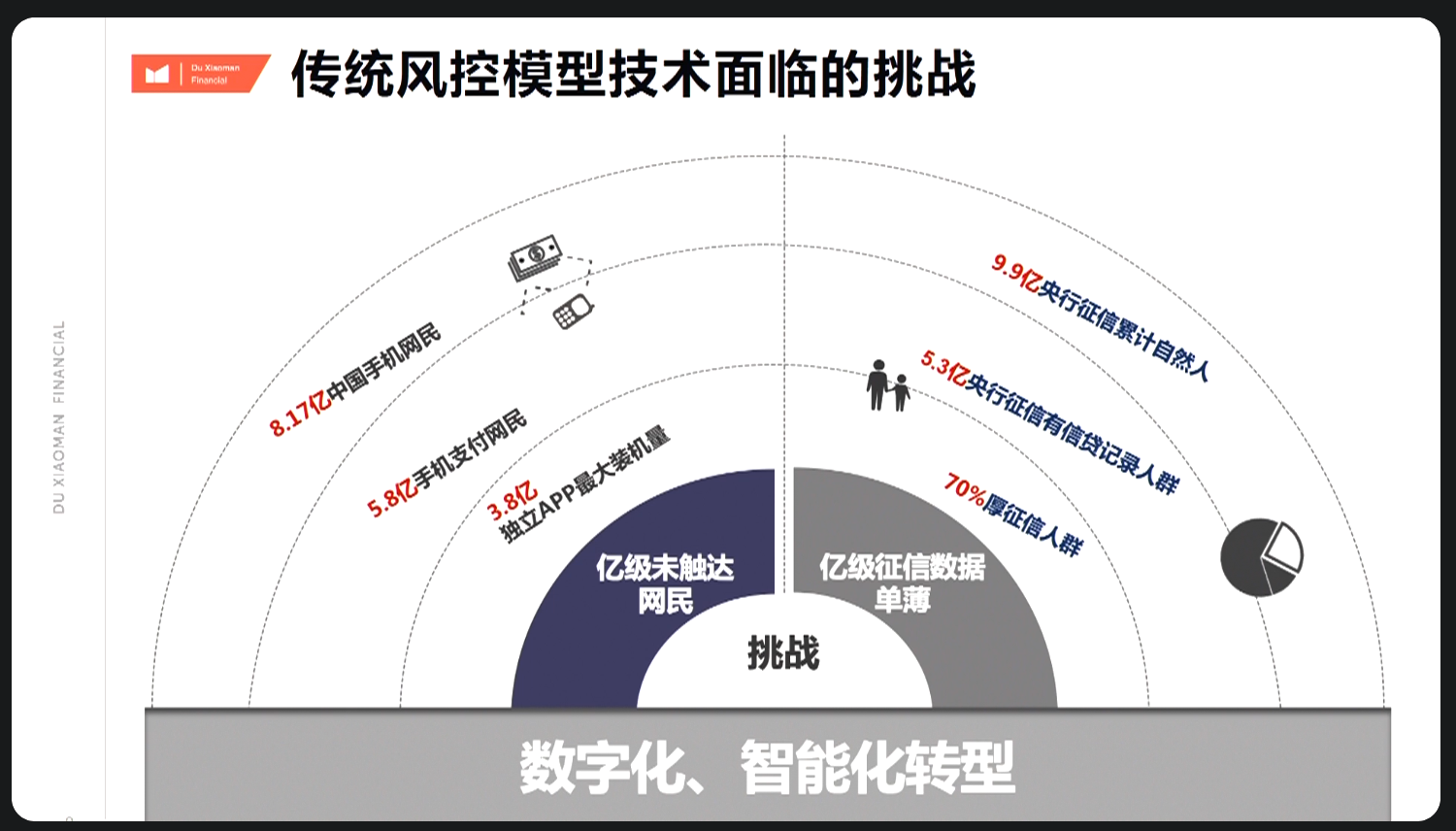
传统风控模型强依赖人行数据,其中无人行客群主要参考物理属性,属于
优化点。 思考:可引入 (1)行内数据 零售、对公、代发客户相关行为数据; (2)其他信用查询
同盾、鹏元、百融、芝麻等; (3)身份核验 如公安联网核查、手机号三要素核验、设备指纹等;待解决基于稀疏数据模型的稳定性
7.1.4 智能金融风控

7.1.4.1 数据孤岛

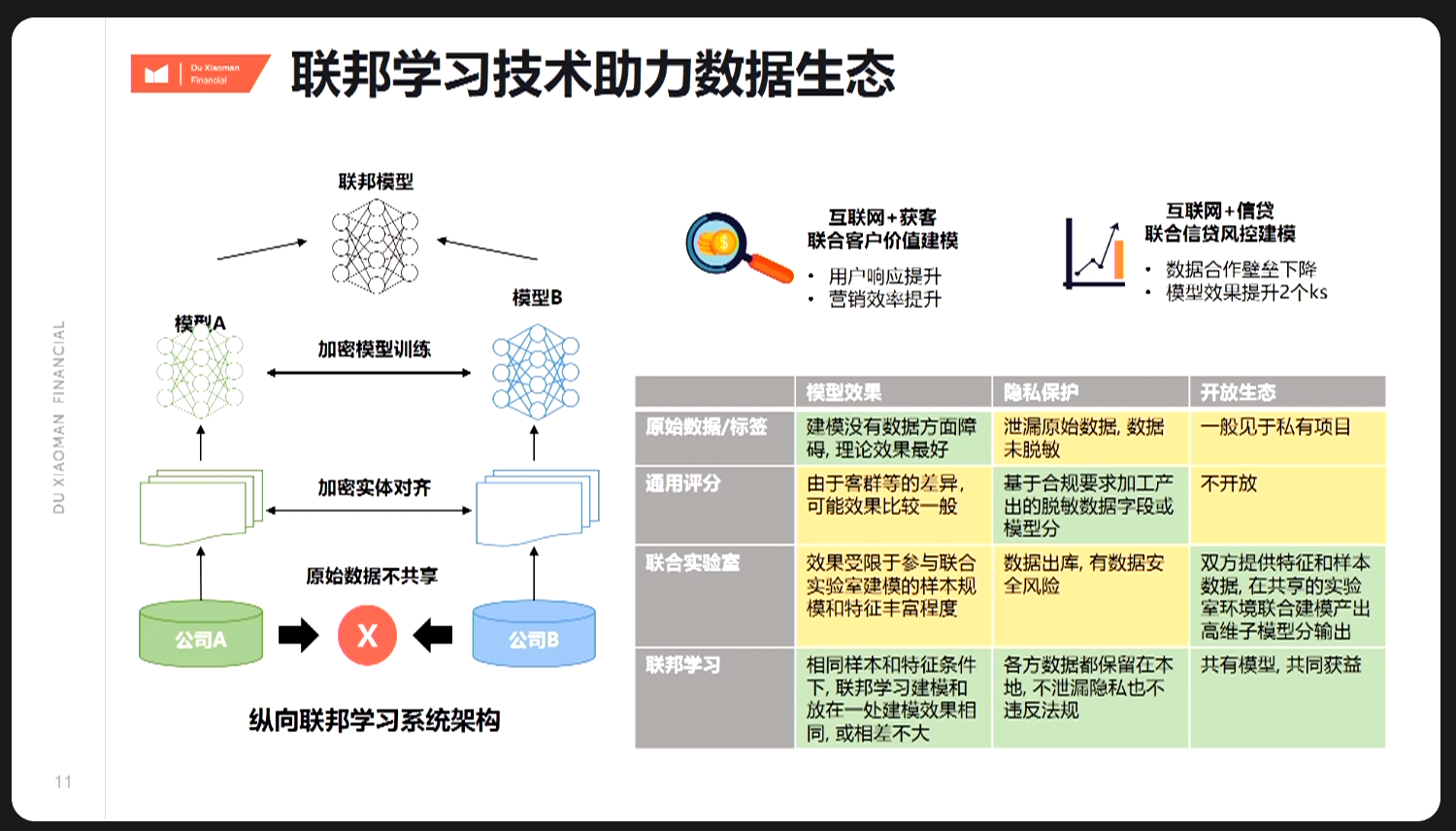
关于联合建模 根据广州银行、中原银行、北京银行等与腾讯、京东联合建模经验,业务背景主要为联名卡发卡, (1)腾讯联合建模: 2017年广州银行与腾讯合作腾讯联名卡,初期发现腾讯征信分对行内客户风险区分能力有限,KS仅30-35,故展开联合建模。 提供数据如: 各类基本信息(如绑卡信息,余额信息),近3个月变更次数,近6个月变更次数; 各类交易信息(包含交易金额,交易次数): 近3个月交易(金额或次数)的平均、最小、最大、总和、笔均交易金额 近6个月交易(金额或次数)的平均、最小、最大、总和、笔均交易金额 近3个月最大值出现时间距当前月份 近6个月最大值出现时间距当前月份等; 结合腾讯征信分及相关数据,针对行内网申信用卡客户进行建模,终版模型KS至55-60。
(2)京东联合建模: 2019年中原银行、2020年北京银行,与京东合作京东联名卡,提供数据如例: 可以看到,联合建模确实对模型效果有所提升。 但实际上,上述场景均存在模型
欠拟合问题。主要原因为: 以京东为例,在与京东合作前,用于联合建模的行内客户样本,需有京东行为数据,且满足一定的业务限定(如网申)、建模要求(如表现期)等条件,合适的样本量一般都不足,进而引发: A、坏样本数量不足,难以完全准确找出坏客户特征; B、样本表现期不足,表现不充分,原本坏客户被当作好客户; 这对联合建模、模型迭代均提出了挑战。
| 字段名New | 枚举值new |
|---|---|
| 收入等级 | 1:低, 2.中低, 3.中,4.中上,5,高,-9999:无法预测;N:未查得 |
| 职业预测 | 1:公务员,2:医院,3:教育,4:服务业,5:白领,6:蓝领,7:金融,-1:无数据 |
| 伪冒风险 | 1:是,0:否;N:未查得 |
| 网购网龄 | 1-4 值越大网龄越长,-1-无 |
| 网购付费意愿 | 1:是,0:否;N:未查得 |
| 有车指数 | 1:高;2:中高;3:中等;4:中低;5:低;-9999:无法预测 ;N:未查得 |
| 有房指数 | 1:高;2:中高;3:中等;4:中低;5:低;-9999:无法预测;N:未查得 |
| 有孩概率 | 1:有小孩 ;-9999:未知 ;N:未查得 |
| 综合购买力 | 1 高;2 中;3 低;-9999:无法预测 ;N:未查得 |
7.1.4.2 非结构化数据
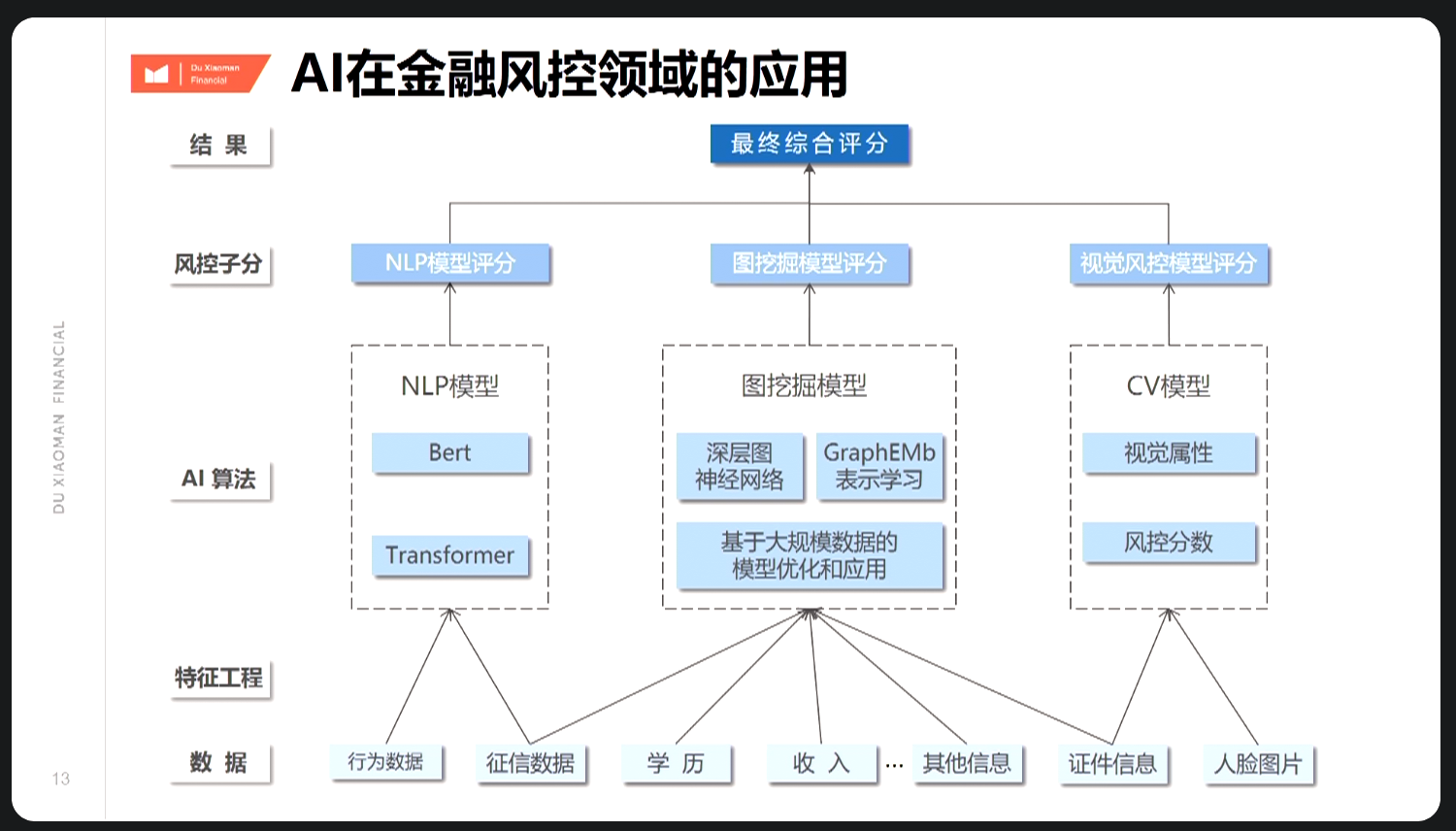
举例:文本处理上,公司名称-公司分级,传统人工标注方法不适用新公司名称,引入NLP。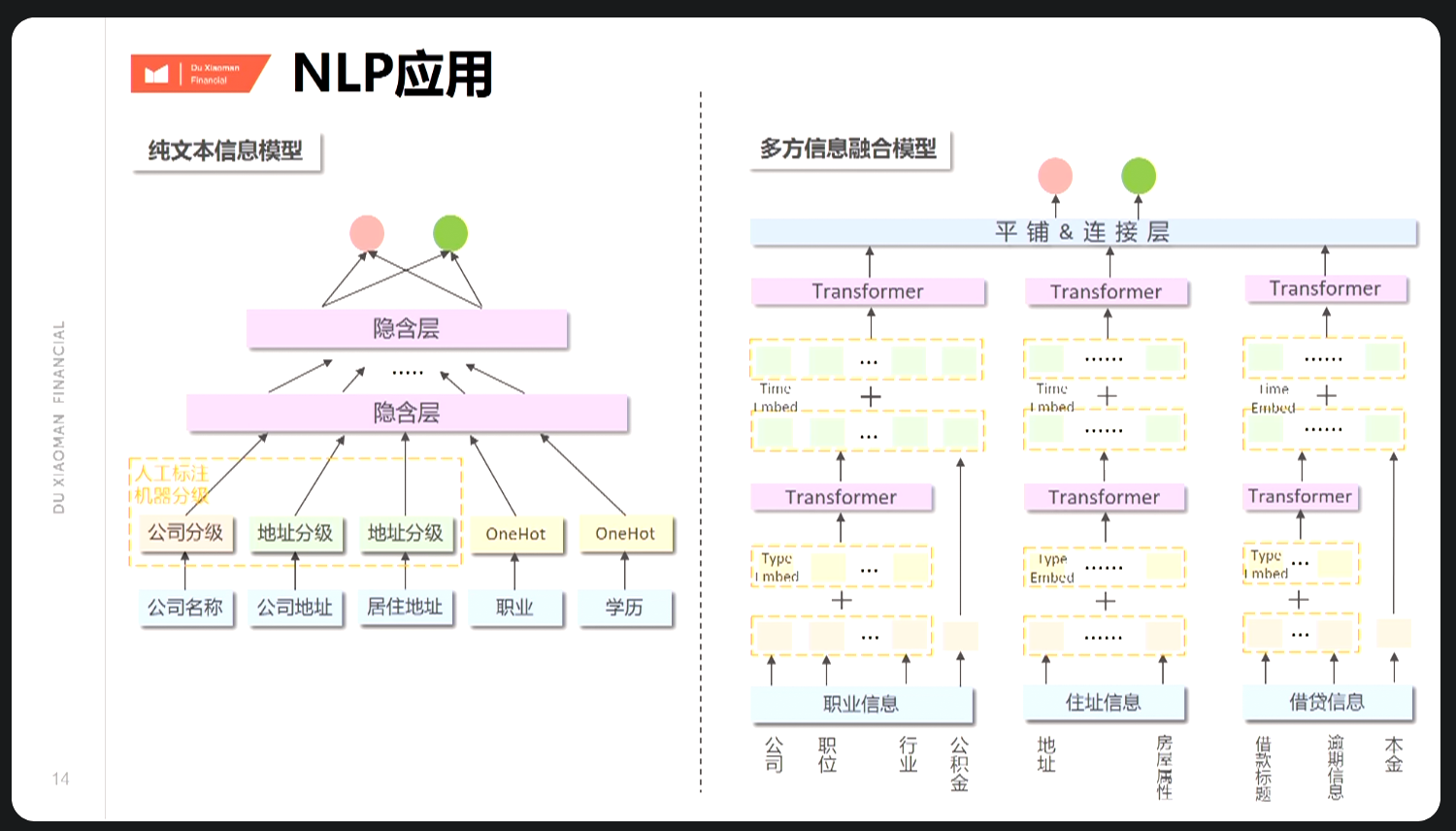
关于NLP技术应用 (1)文本处理 主要需解决: A.如示例公司名称-公司分级,主要用于贷前审批,一般通过人工标注或固定词库更新,效率和适用性较差; B.
模糊匹配问题,客户姓名、单位地址、单位名称模糊匹配; (2)其他应用 事实上,NLP技术已不仅用于文本处理,可以看到: 2020腾讯广告算法大赛,要求通过广告系统中的交互行为作为输入来预测用户的人口统计学属性。 其中冠军方案创新地引入改进BERT模型,假设每个广告为一个单词,将用户点击序列看作一句话,这样就将问题转为了NLP的文本分类问题。实打实的“他山之石,可以攻玉”,详见链接:https://github.com/guoday/Tencent2020_Rank1st
业务延伸同样地,我们可以把类似技术在交易描述上进行尝试,假设每个交易为一个单词,将客户交易行为看作一句话,定义一个与交易相关的target(如是否办理分期等),同样地把问题转化为NLP文本分类(分类器可选逻辑回归等)。 1、简单验证 取近6个月有消费、取现、还款客户,并定义6个月为观察期,预测目标为后一个月有消费。 BASE方法:构建强相关变量,观察期内消费、还款总次数;NLP模型如上,仅做简单文本预处理。 其目标皮尔逊积矩相关系数(Pearson)如下:
| 客户量 | BASE | NLP |
|---|---|---|
| 10,000 | 0.398 | 0.797 |
| 200,000 | 0.397 | 0.778 |
| 500,000 | 0.407 | 0.756 |
2、模型验证 取用SAS开发流失预警模型,NLP模型保持相同观察期、流失目标,同一数据月份,对比如下:
| 模型 | Pearson | ROC | Cutoff | F1 | Precision | Recall | ACC |
|---|---|---|---|---|---|---|---|
| SAS+NLP | 0.7518 | 0.9727 | 0.24 | 0.7444 | 0.6775 | 0.8258 | 0.9545 |
| NLP | 0.6956 | 0.9569 | 0.22 | 0.7331 | 0.6769 | 0.7996 | 0.9533 |
| SAS | 0.4843 | 0.8934 | 0.26 | 0.4772 | 0.3779 | 0.6473 | 0.8861 |
可见NLP模型较于SAS模型各评估指标较好,SAS、NLP简单融合(SAS输出概率作为NLP输入)后,效果更佳。 3、应用问题 我们猜想NLP语料更新可能会弱化模型效果,从而引发模型更新、数据采样的讨论。 数据探索:201907月交易描述合计约4400W条,交易描述词库约330W条,其匹配度约以每月3.00%下降,至201912月匹配度已下降至85.0% (1)数据采样 引入BERT的Masked LM概念,如:my dog is hairy
- 有80%的概率用“[mask]”标记来替换——my dog is [MASK]
- 有10%的概率用随机采样的单词来替换——my dog is apple
- 有10%的概率不做替换——my dog is hairy
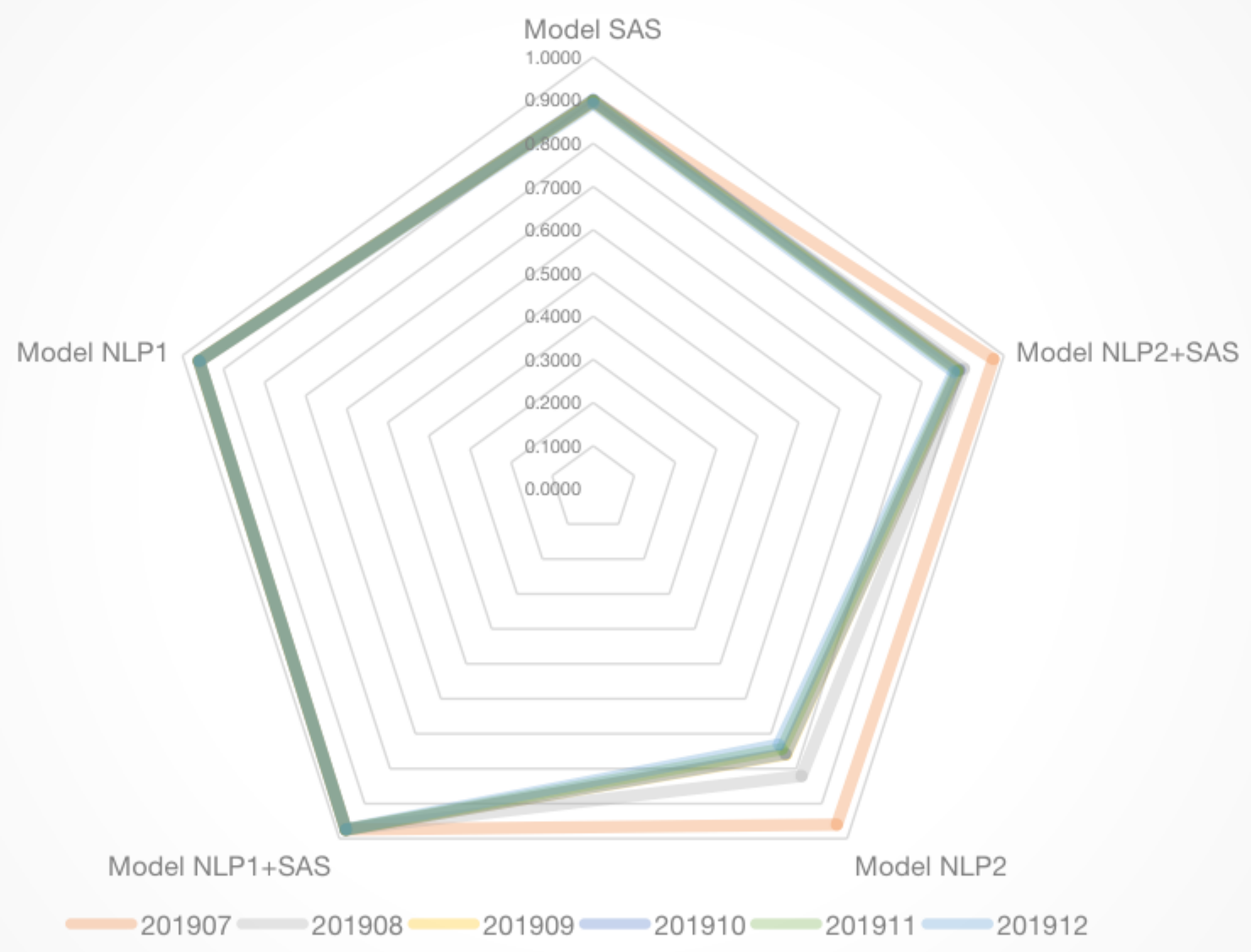
待验证(2)模型更新 定义每月重新训练NLP模型为NLP1模型、201907时点NLP模型为NLP2模型,模型评估(ROC):
| Month\Model | SAS | NLP2+SAS | NLP2 | NLP1+SAS | NLP1 |
|---|---|---|---|---|---|
| 201907 | 0.8990 | 0.9744 | 0.9599 | 0.9744 | 0.9599 |
| 201908 | 0.8974 | 0.9026 | 0.8208 | 0.9740 | 0.9608 |
| 201909 | 0.8964 | 0.8897 | 0.7590 | 0.9736 | 0.9589 |
| 201910 | 0.9011 | 0.8915 | 0.7570 | 0.9746 | 0.9594 |
| 201911 | 0.8990 | 0.8856 | 0.7435 | 0.9745 | 0.9598 |
| 201912 | 0.8925 | 0.8780 | 0.7310 | 0.9730 | 0.9585 |
可知,SAS、NLP1、NLP1+SAS模型ROC分别稳定在0.89、0.96、0.97,而NLP2模型随着时间推移ROC已不足0.75,语料更新比预想还要快,据此构建的NLP模型ROC下滑明显。但我们仍可采用如NLP1模型每月重新训练来保证模型效果。
举例:获取认证用户自上传的视频信息,通过目标检测来实现视觉风控,即如图左一、二可能优于左三、四、五。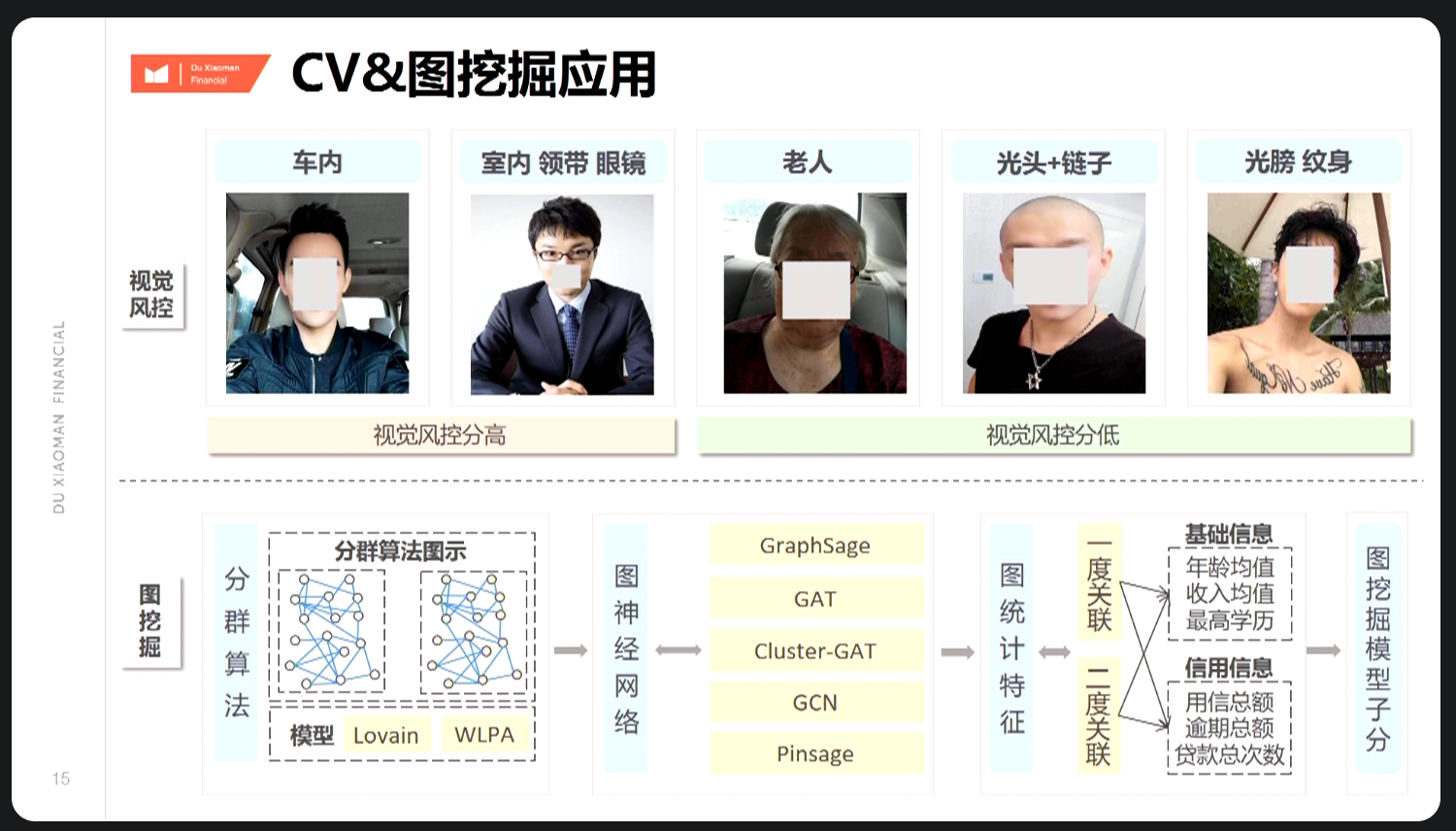
CV,计算机视觉 (1)技术分析 A、图像分类 B、人脸识别
预训练版本:基于dlib,加载预训练模型shape_predictor_5_face_landmarks、shape_predictor_68_face_landmarks; 自训练版本:基于facenet,https://github.com/davidsandberg/facenet
待分享C、目标检测Facebook开源Detectron,https://github.com/facebookresearch/Detectron 商汤科技与香港中文大学联合开源mmdetection,https://github.com/open-mmlab/mmdetection 个人比较熟悉mmdetection,也主要推荐,但需GPU资源。 常见算法:
据此框架,可自训练目标检测模型,如用于视觉风控。
待分享D、编码识别 身份信息识别、手写数字识别、验证码识别等。 E、待补充 F、其他CV技术,若暂无业务场景未罗列,如图像生成、图像分割等(2)业务分析 业务上,目前影像来源主要为:身份信息认证、网申活体检测、线下面签照片等。现传统银行图像数据应用维度仍比较单一,如身份信息认证后该图像数据基本不再应用,示例中视觉风控技术门槛较高,仅能通过调用第三方产品API获取视觉风控信息。
可接入或自研发相关图像检测产品图挖掘 (1)图神经网络 大概分类:图卷积网络(Graph Convolution Networks,GCN)、 图注意力网络(Graph Attention Networks)、图自编码器( Graph Autoencoders)、图生成网络( Graph Generative Networks) 和图时空网络(Graph Spatial-temporal Networks); 简单接触过工业级图深度学习开源框架Euler,https://github.com/alibaba/euler
待深入(2)图统计特征 引申一下关联技术,重要业务应用点:用于贷前申请反欺诈的关联网络技术。 根据复杂度拆解,业务需求有: A、复杂级别 ⭐️ 基于Python的简单关联网络,封装工具,实现一度关联和黑名单匹配。 B、复杂级别 ⭐️⭐️⭐️ 基于图数据库的复杂关联网络,用于小量级关联网络分析。 C、复杂级别 ⭐️⭐️⭐️⭐️⭐️ 完整关联网络系统,百万级+申请量,对标SAS SNA模块,可用于贷前申请反欺诈。
7.1.4.3 复杂模型
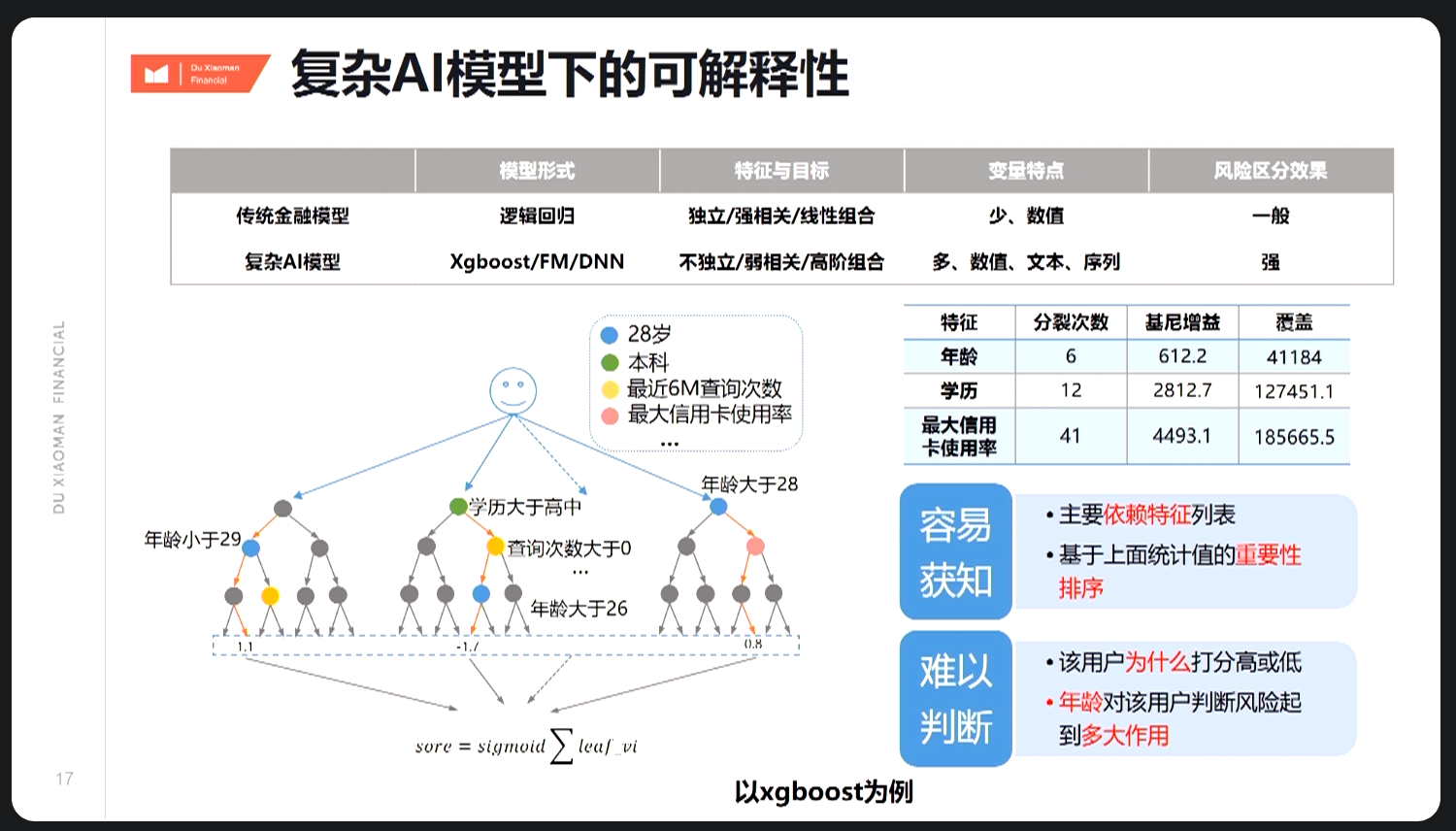
研究方向,其中方法二目前应用较广,但整体仍处于初步研究。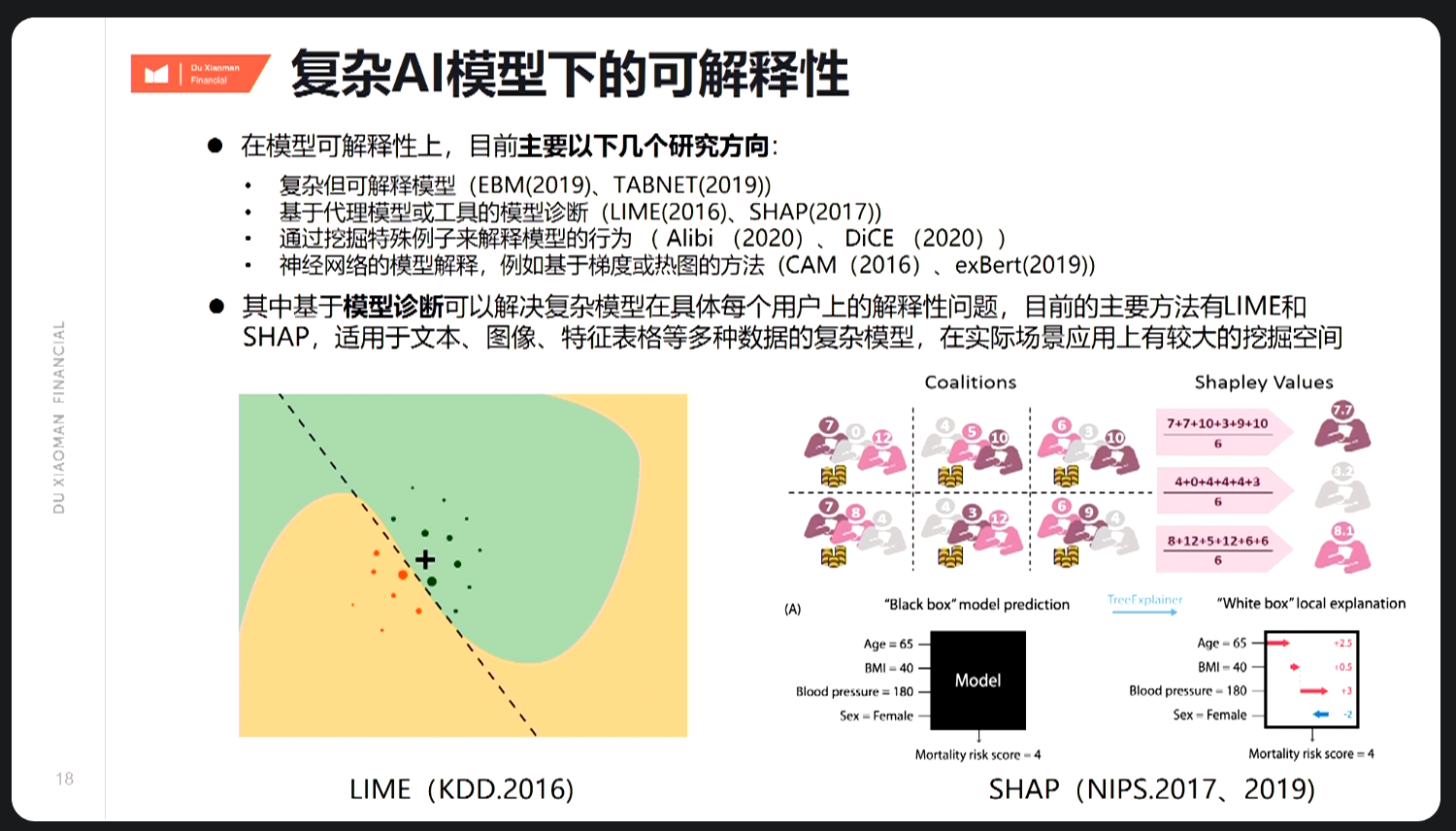
复杂模型的可解释性除了能更好地给以业务反馈,也是复杂模型能在银行这种传统甚至保守企业落地的关键。 以下引入个人探索结果:
积分梯度(Integrated Gradients)它首先在论文《Gradients of Counterfactuals》中提出,后来《Axiomatic Attribution for Deep Networks》再次介绍了它:即
是
对输出
#card=math&code=F%28x%29&id=M8JmD)的归因,通俗地说,指出x对应分量对模型决策的重要性。 然而朴素地基于梯度衡量得到分量敏感程度,因梯度饱和问题,其仍不足以作为重要性的良好度量。故通过引入基线
的概念来改进,以找到相对重要的分量,即积分梯度。
待试验

7.1.4.4 个性化建模需求
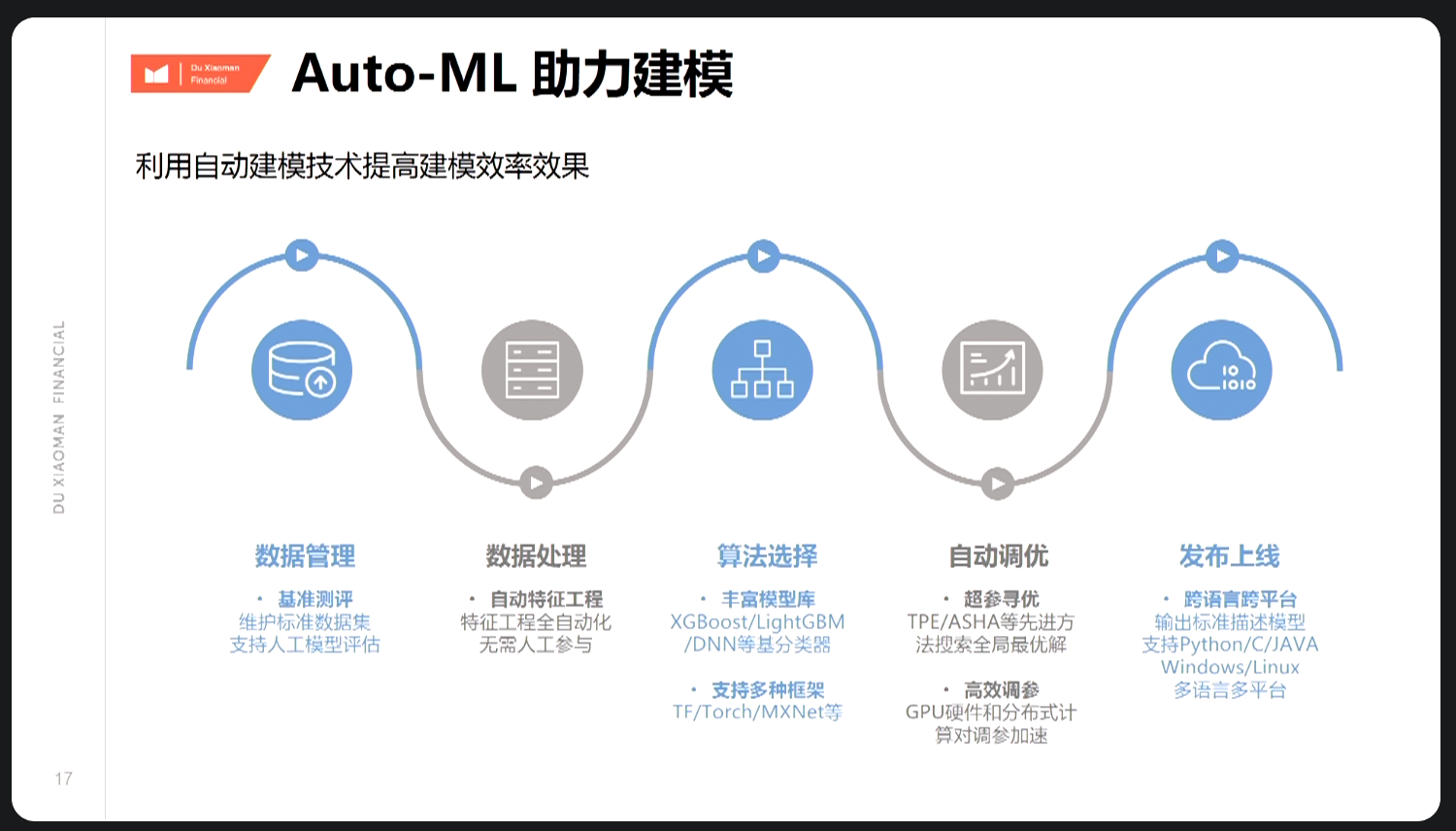
2017年广州银行为提高模型生产效率,开发过基于SAS、Python的
自动建模工具。 2018年在九江银行贷前审批系统项目中,开发过基于Python的配置化特征工程工具。 版本相对简易,但均属于Auto-ML技术探索。 总结研发经验来说,关键问题(待优化): A、变量分箱 早期方法:学习并改进了SAS随机抽样决策树分箱方法; 在与刘文穗老师多次交流py_mob项目https://github.com/statcompute/py_mob后,拟借鉴之。 B、调优效率 传统调优方法较为耗时,暂通过多线程并发、运行超时退出等方法解决; C、模型选择 如图,综合考虑KS、ACC、PRECISE、RECALL、F1、AUC,定义评估函数输出Score,并据此选择最佳模型;D、模型融合 早期框架中没有考虑模型融合,一般银行模型考虑可解释性和模型部署,也较少应用,即使SAS EM本身有模型集合功能。 为此我们将引入传统方法和集成学习(ensemble learning)概念,如下: E、模型部署 已知的区域银行模型部署,考虑到系统环境、IT配置,大多仍通过shell脚本、SAS脚本、决策引擎等部署。复杂模型发布部署也会比较复杂(如翻译成if-else规则)甚至无法实现,需轻量级的、跨语言的、跨平台的解决方案。
平均:- 简单平均法- 加权平均法投票:- 简单投票法- 加权投票法综合:- 排序融合- log融合stacking:- 构建多层模型,并利用预测结果再拟合预测。blending:- 选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测Bagging和Boosting:- Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个更加强大的分类。两种方法都是把若干个分类器整合为一个分类器的方法,只是整合的方式不一样,最终得到不一样的效果。常见的基于Bagging思想的集成模型有:随机森林;基于Boosting思想的集成模型有:Adaboost、GBDT、XgBoost、LightGBM等。
7.1.5 未提及
本篇未提及部分即笔者认为视频中未提及的人工智能技术。
仅为个人思考,以下简要罗列之:
7.1.5.1 强化学习
利用强化学习强调如何给予环境而行动,以取得最大化的预期利益,尝试将强化学习概念引进响应型营销策略,如账单分期外呼策略,为解决实验设计自动化提供新思路。
(1)背景介绍
首先简化账单分期外呼策略,假定有策略分组ABCD及其分配外呼量,如下:
| 组A | 组B | 组C | 组D | |
|---|---|---|---|---|
| 外呼分配占比 | 25% | 25% | 25% | 25% |
但实际上,
| 组A | 组B | 组C | 组D | |
|---|---|---|---|---|
| 实验组实际响应率 | 32.00% | 20.00% | 8.00% | 4.00% |
| 空白组实际响应率 | 28.00% | 10.00% | 6.00% | 3.98% |
| 提升度 | 1.143 | 2.000 | 1.333 | 1.005 |
现为提升外呼渠道效应以及全渠道响应率,需要对策略组分配占比进行调整,使外呼资源往高提升度组上倾斜。
(2)方法应用
引入强化学习,定义关键参数:
- 调整系数:即占比调整系数,假定0.01;
- 状态S:现分配系数矩阵[0.25, 0.25, 0.25, 0.25];
- 动作a:调整动作A>B,即分配占比A-0.01、B+0.01,得到[0.24, 0.26, 0.25, 0.25],共计12种;
- 奖惩:根据业务目标,可综合响应率、办理量、手续费收入的提升度;
- 回合:结合策略迭代周期,可细化到月、周、日;
7.1.5.2 对抗攻击
首先,这里的对抗指的是同对抗攻击、对抗样本相关的领域,主要关注模型在小扰动下的稳健性。
在风控模型策略中引入对抗概念,用于解决:
- 策略配置错误导致的误命中问题
- 模型特殊/边际输入值结果验证
- 专家经验评分卡有效性验证
- 欺诈识别能力检测
等。

若有收获,就点个赞吧
0 人点赞
