8.1.1 计算机科学理论
面向非计算机专业背景数据人员的计算机科学概念科普,仅作简述,有兴趣的同学可以自行拓展学习。
8.1.1.1 核心理论
1、计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。
2、假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。
3、进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。
4、一个车间里,可以有很多工人。他们协同完成一个任务。
5、线程就好比车间里的工人。一个进程可以包括多个线程。
6、车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。
7、可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
8、一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫”互斥锁”(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。
9、还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。
10、这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做”信号量”(Semaphore),用来保证多个线程不会互相冲突。
不难看出,mutex是semaphore的一种特殊情况(n=1时)。也就是说,完全可以用后者替代前者。但是,因为mutex较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种设计。
11、操作系统的设计,因此可以归结为三点:
(1)以多进程形式,允许多个任务同时运行;
(2)以多线程形式,允许单个任务分成不同的部分运行;
(3)提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源;
12、网上有一个比喻用来比较 GPU 和 CPU ,100 个小学生(GPU)和一个大学教授(CPU)组成两队进行数学比赛,第一回合是两队分别完成 100 道四则运算题,比赛开始,第一回合教授还在写的时候,小学生们已经完成了答题,然后进行了第二回合,第二回合是两队分别完成 1 道高等数学题目,教授已经完成了答题,100 个小学生们还在苦苦冥想。
所以,什么类型的程序适合在GPU上运行?
(1)计算密集型的程序;
(2)易于并行的程序;
13、接下来是书面定义:
- 进程
进程是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间,至少有 5 种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
- 线程
线程是CPU调度和分派的基本单位,它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
- 进程和线程的关系
线程是进程的一部分。一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程
- 进程和线程的区别
理解它们的差别,从资源使用的角度来看。
(1)根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位;
(2)开销方面:每个进程都有独立的代码和数据空间(程序上下文),进程之间切换开销大;线程可以看作轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小;
(3)所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行);
(4)内存分配:系统为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源;
(5)包含关系:线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程;
8.1.1.2 数据结构
这里的数据结构指数据结构和算法,数据结构指的是一组数据的存储结构,算法指的是操作数据的一组方法。
其思维导图如下: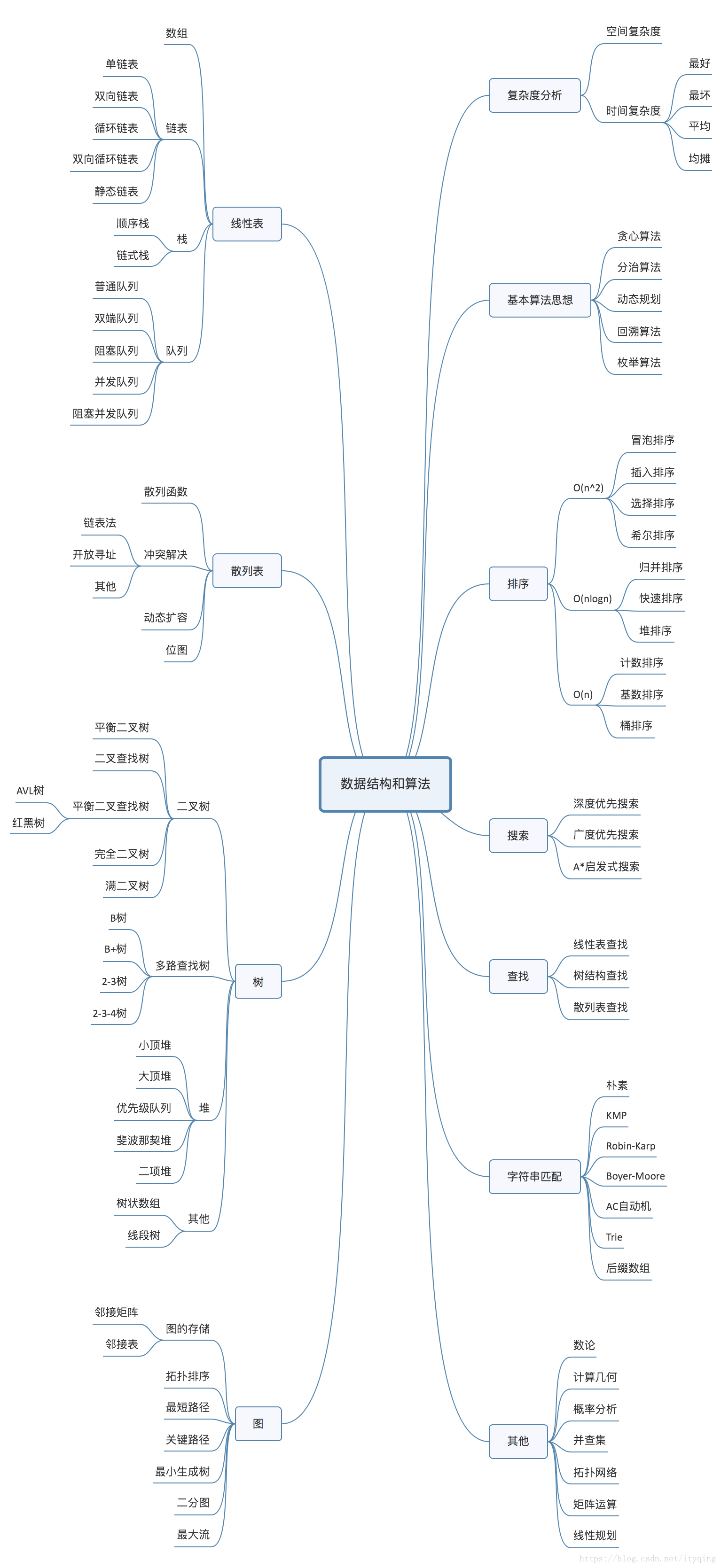
如冒泡排序:
冒泡排序/Bubble Sort,是一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。

但这也只是理论,较难理解,以下我们举些简单的应用示例,或来自思维训练,或来自生产实际。
- 示例1 分治:称金币、病毒检测
Q:有27枚金币,但有一枚质量较轻的假金币混在其中,现在想用一架没有砝码的天平称出假金币,需要几次?
A:最简单就是枚举法,一枚置天平之左,剩下26枚依次置于天平之右,那么最多26次就能称出。显然,这不是最优,至少第一次发现天平显示质量一致时,就可以换掉天平之左那枚。简单来说就是分成两堆依次称取,是一种分治思想,那么最多14次就能称出。
但,这也不是最优,我们还可以分成三堆,每堆9枚,将其中两堆分别置于天平两端,若天平平衡,则假金币即在未称取的那9枚金币里,若天平不平衡,则假金币即在比较轻的那9枚金币里;再将含有假金币的那9枚金币分成三堆,每堆3枚,类似地操作;进而再将含有假金币的那3枚金币分成三堆,每堆1枚,那么最多3次就能称出。
如果每称一次需要花费较多时间或其他代价的话,这样的优化,其收益是非常可观的。
【扩展阅读】新算法检测新冠合并样本 即可大规模筛查 英国《自然》杂志10月22日发表一项传染性疾病相关研究,科学家团队报告一种利用少量检测对大量人口进行新冠病毒感染筛查的数学方法。这种方法非常适合于大规模监测感染情况,与此同时,其有助于降低大规模检测费用,在无法负担大量检测的低收入国家可能特别有益。 …… 合并(或集中)样本一起检测,可以提高分析效率,降低成本。当某疾病在人群中的发病率较低,且大多数检测结果为阴性时,这种方法尤其有效。标准的分组检测程序是在检测前将样本合并成一定规模的小组。如果一组检测结果为阳性,则对该组中的样本逐一进行检测,以确定阳性个体。
- 示例2 排序:SAS预排序
我们知道SAS部分数据步、过程步,如涉及BY语句的MERGE、FIRST、FREQ,语句执行前需对数据集进行排序。这其实就是一种算法与数据结构思想,如MERGE本意将两个数据集进行匹配,排序后将大大省去匹配中后剩余的匹配量。只是SAS没有将这一步骤内置,并强制约定需预排序。
| 数据集1 未排序 |
数据集2 未排序 |
数据集1 排序后 |
数据集2 排序后 |
|||
|---|---|---|---|---|---|---|
| A | F | A | A | |||
| D | A | |||||
| A | C | END | ||||
| C | D | |||||
| … | … | |||||
| A | END | F |
上表就是个典型案例,未排序时哪怕在已匹配到A,但不知道数据集2还有多少个A,始终要匹配至最后一行不论数据集是100W行、1000W行,但排序后只需要
后,发现新一行的C > A,即结束匹配。
此外对于直接读取ODS进行排序,如下:
/*假设有一张含XACCOUNT的XLIST,欲与ACCT进行MERGE匹配。*//* code1 */PROC SORT DATA = XLIST;BY XACCOUNT;RUN;/* code2 */PROC SORTDATA = ODS.S_CCS_ACCTOUT = ACCT;BY XACCOUNT;RUN;/* code3 */PROC SORT DATA = ACCT;BY XACCOUNT;RUN;/* code4 */DATA TEMP;MERGE XLIST(IN=A) ACCT(IN=B);BY XACCOUNT;IF A AND B;RUN;
由于ODS数据库排序方法与SAS不一定一致,特殊时,这里代码会提示code2-SORT排序正常,且code3-已排序空处理,但code4-MERGE时仍提示需排序。
这其实也是一种算法与数据结构思想,为避免重复排序,SAS数据集设定了排序状态位0/1,当已排序数据再次被排序时,即先根据排序状态位为1知晓已排序,随即反馈提示并空处理,所以也带来了上述困扰。
- 一般建议,不直接从ODS排序。
示例3:SAS压缩
OPTIONS COMPRESS = YES;
事实上,SAS压缩也是一种重要思想,为什么一般建议YES?什么场景可以NO?
个中奥妙交由读者自行参悟。
更多详见: 《算法与数据结构之美》 https://blog.csdn.net/ityqing
8.1.1.3 云计算
Google云计算三大论文,云计算奠基工程,分别是:
- Bigtable
Bigtable_A Distributed Storage System for Structured Data.pdf
- FileSystem
- MapReduce
MapReduce_Simplified Data Processing on Large Clusters.pdf
其中,MapReduce是最经典的云计算技术,我们可以在Python中简单体验。
from functools import reducef1 = lambda x: x*xf2 = lambda x, y: x+yL0 = [1, 2, 3]L1 = list(map(f1, L0))L2 = reduce(f2, L1)print(L0, L1, L2)# [1, 2, 3] [1, 4, 9] 14
详见: 《Bigtable:A Distributed Storage System for Structured Data》 《The Google File System》 《MapReduce:Simplified Data Processing on Large Clusters》
8.1.2 版本控制
如何有效进行代码版本控制管理,也是数据分析人员的必修课,甚至可以作为一道基础面试问答题。
你是怎么对代码进行版本控制的???
8.1.2.1 副本
关于版本控制,尤其对于大型生产代码,手动备份副本,是最简单方法,也是最低要求。以抗击不可抗因素引起的各种错误,实现因放弃修改而需版本回滚、或因服务器崩溃而需重新加载。稍微自动化一点地,我们还可以通过部署自动化作业,定时扫描A文件路径,全量或增量备份至B文件路径。
但是,这种方式有以下特点:
(1)版本过多易失控
如,版本1与版本12的区别较难捉摸,就需readme文件详细说明每一版本意义。
(2)备份冗余
尤其代码量较大、修改频繁、修改极小时,如
%2F(n%2Bmk)%5C%5C%0A%E4%BE%8B%EF%BC%8C%E4%BB%A3%E7%A0%81%E9%87%8F10000%E8%A1%8C%E3%80%81%E5%90%88%E8%AE%A1%E4%BF%AE%E6%94%B9100%E6%AC%A1%E3%80%81%E6%AF%8F%E6%AC%A1%E4%BF%AE%E6%94%B9%E9%87%8F10%E8%A1%8C%5C%5C%0A%E5%A4%87%E4%BB%BD%E6%AF%94%E4%B8%BA%20(10000010010)%2F(10000%2B10010)%3D909.09%0A#card=math&code=%E4%BB%A3%E7%A0%81%E9%87%8Fn%E8%A1%8C%E3%80%81%E5%90%88%E8%AE%A1%E4%BF%AE%E6%94%B9m%E6%AC%A1%E3%80%81%E6%AF%8F%E6%AC%A1%E4%BF%AE%E6%94%B9%E9%87%8Fk%E8%A1%8C%EF%BC%8C%5C%5C%0A%E5%A4%87%E4%BB%BD%E6%AF%94%E4%B8%BA%20%28n%2Am%2Ak%29%2F%28n%2Bm%2Ak%29%5C%5C%0A%E4%BE%8B%EF%BC%8C%E4%BB%A3%E7%A0%81%E9%87%8F10000%E8%A1%8C%E3%80%81%E5%90%88%E8%AE%A1%E4%BF%AE%E6%94%B9100%E6%AC%A1%E3%80%81%E6%AF%8F%E6%AC%A1%E4%BF%AE%E6%94%B9%E9%87%8F10%E8%A1%8C%5C%5C%0A%E5%A4%87%E4%BB%BD%E6%AF%94%E4%B8%BA%20%28100000%2A100%2A10%29%2F%2810000%2B100%2A10%29%3D909.09%0A&id=fyyXg)
(3)回滚方便
当(1)问题解决时,能快速找到所需版本为版本12时,回滚等价于复制覆盖,非常方便。
8.1.2.2 Git
Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Git 与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持。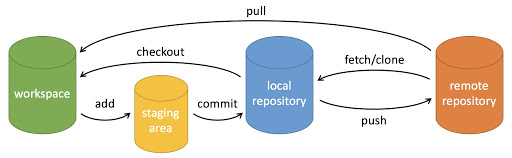
- Git常见命令
- github-git-cheat-sheet.pdf


- Git In SAS EG
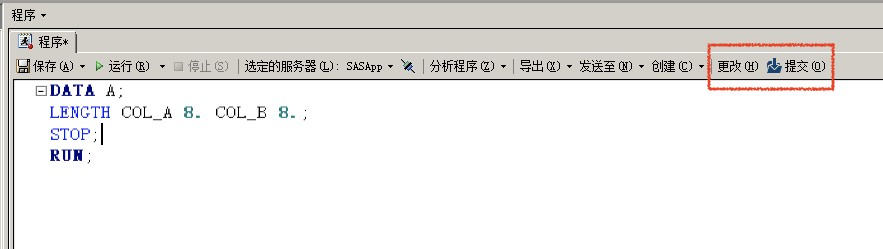
SAS EG中红框部分(若有配置)即为Git功能,编写代码后点击提交可进行代码版本Git管理。
8.1.2.3 SVN
Apache Subversion 通常被缩写成 SVN,是一个开放源代码的版本控制系统,Subversion 在 2000 年由 CollabNet Inc 开发,现在发展成为 Apache 软件基金会的一个项目,同样是一个丰富的开发者和用户社区的一部分。SVN相对于的RCS、CVS,采用了分支管理系统,它的设计目标就是取代CVS。互联网上免费的版本控制服务多基于Subversion.
- SVN 生命周期
(1)创建版本库
版本库相当于一个集中的空间,用于存放开发者所有的工作成果。版本库不仅能存放文件,还包括了每次修改的历史,即每个文件的变动历史。
Create 操作是用来创建一个新的版本库。大多数情况下这个操作只会执行一次。当你创建一个新的版本库的时候,你的版本控制系统会让你提供一些信息来标识版本库,例如创建的位置和版本库的名字。
(2)检出
Checkout 操作是用来从版本库创建一个工作副本。工作副本是开发者私人的工作空间,可以进行内容的修改,然后提交到版本库中。
(3)更新
顾名思义,update 操作是用来更新版本库的。这个操作将工作副本与版本库进行同步。由于版本库是由整个团队共用的,当其他人提交了他们的改动之后,你的工作副本就会过期。
让我们假设 Tom 和 Jerry 是一个项目的两个开发者。他们同时从版本库中检出了最新的版本并开始工作。此时,工作副本是与版本库完全同步的。然后,Jerry 很高效的完成了他的工作并提交了更改到版本库中。
此时 Tom 的工作副本就过期了。更新操作将会从版本库中拉取 Jerry 的最新改动并将 Tom 的工作副本进行更新。
(4)执行变更
当检出之后,你就可以做很多操作来执行变更。编辑是最常用的操作。你可以编辑已存在的文件,例如进行文件的添加/删除操作。
你可以添加文件/目录。但是这些添加的文件目录不会立刻成为版本库的一部分,而是被添加进待变更列表中,直到执行了 commit 操作后才会成为版本库的一部分。
同样地你可以删除文件/目录。删除操作立刻将文件从工作副本中删除掉,但该文件的实际删除只是被添加到了待变更列表中,直到执行了 commit 操作后才会真正删除。
Rename 操作可以更改文件/目录的名字。”移动”操作用来将文件/目录从一处移动到版本库中的另一处。
(5)复查变化
当你检出工作副本或者更新工作副本后,你的工作副本就跟版本库完全同步了。但是当你对工作副本进行一些修改之后,你的工作副本会比版本库要新。在 commit 操作之前复查下你的修改是一个很好的习惯。
Status 操作列出了工作副本中所进行的变动。正如我们之前提到的,你对工作副本的任何改动都会成为待变更列表的一部分。Status 操作就是用来查看这个待变更列表。
Status 操作只是提供了一个变动列表,但并不提供变动的详细信息。你可以用 diff 操作来查看这些变动的详细信息。
(6)修复错误
我们来假设你对工作副本做了许多修改,但是现在你不想要这些修改了,这时候 revert 操作将会帮助你。
Revert 操作重置了对工作副本的修改。它可以重置一个或多个文件/目录。当然它也可以重置整个工作副本。在这种情况下,revert 操作将会销毁待变更列表并将工作副本恢复到原始状态。
(7)解决冲突
合并的时候可能会发生冲突。Merge 操作会自动处理可以安全合并的东西。其它的会被当做冲突。例如,”hello.c” 文件在一个分支上被修改,在另一个分支上被删除了。这种情况就需要人为处理。Resolve 操作就是用来帮助用户找出冲突并告诉版本库如何处理这些冲突。
(8)提交更改
Commit 操作是用来将更改从工作副本到版本库。这个操作会修改版本库的内容,其它开发者可以通过更新他们的工作副本来查看这些修改。
在提交之前,你必须将文件/目录添加到待变更列表中。列表中记录了将会被提交的改动。当提交的时候,我们通常会提供一个注释来说明为什么会进行这些改动。这个注释也会成为版本库历史记录的一部分。Commit 是一个原子操作,也就是说要么完全提交成功,要么失败回滚。用户不会看到成功提交一半的情况。
8.1.2.4 Tortoise
Tortoise,图形化版本管理,这里指TortoiseSVN-https://tortoisesvn.net、TortoiseGit-[https://tortoisegit.or](https://tortoisegit.or)
这里,我们常用TortoiseSVN,且一般只在用commit、update功能。事实上,这才只是冰山一角,以下我们通过TortoiseGit示例之。
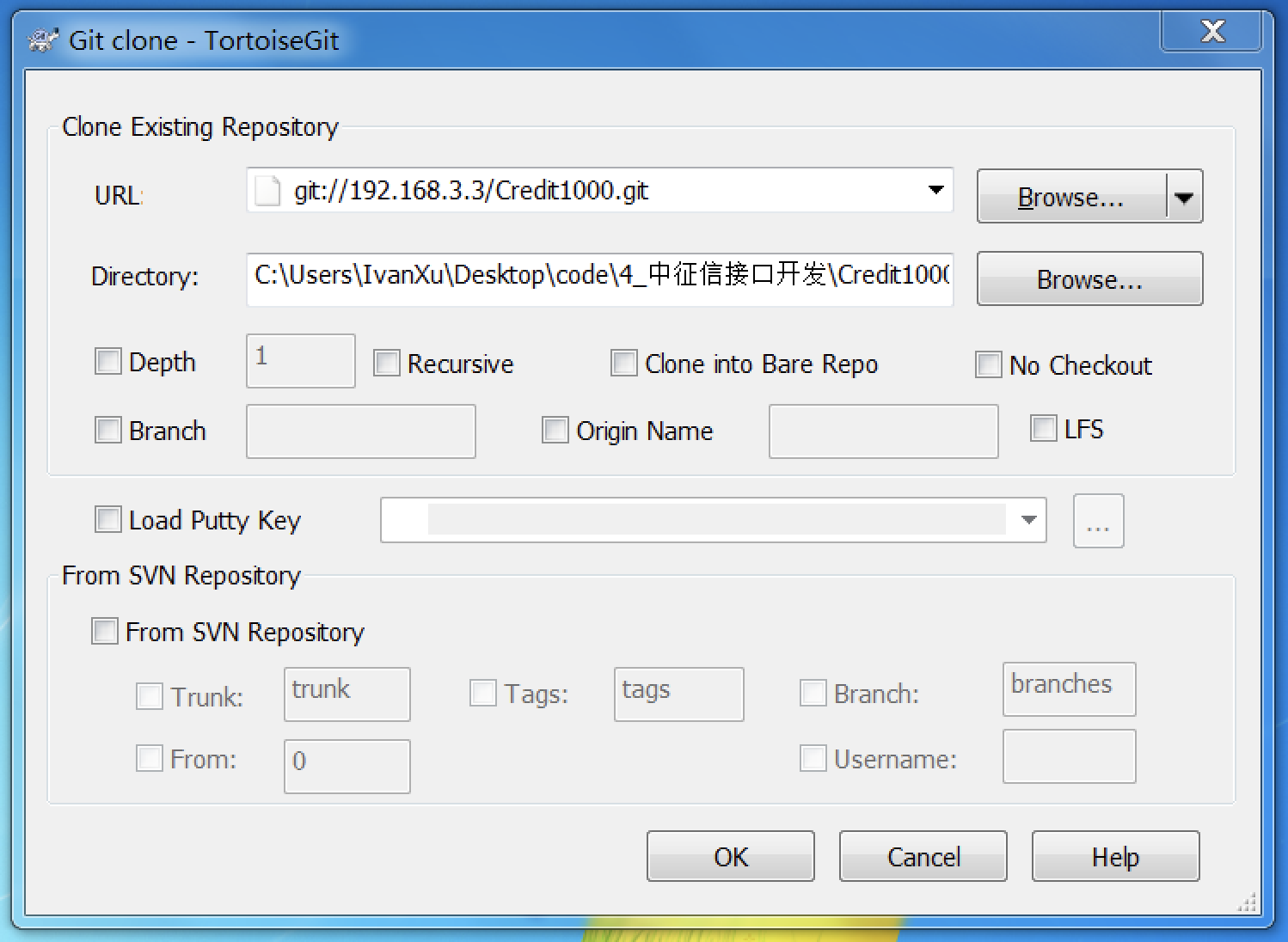
仓库拉取
TortoiseSVN称为checkout、TortoiseGit则保留Git的clone名称,即
版本提交、版本记录
即commit,但一般我们会习惯性忽略`Message`,我们输入“Ivan ADD 0.txt”作为示例。

值得注意的是,硬性要求commit需要Message时,也会规范Message内容,如下:
1、type type为必填项,用于指定commit的类型,约定了feat、fix两个主要type,以及docs、style、build、refactor、revert五个特殊type,其余type暂不使用。 feat:增加新功能 fix:修复bug docs:只改动了文档相关的内容 style:不影响代码含义的改动,例如去掉空格、改变缩进、增删分号 build:构造工具的或者外部依赖的改动,例如webpack,npm refactor:代码重构时使用 revert:执行git revert打印的message
2、scope scope也为必填项,用于描述改动的范围,格式为项目名/模块名,例如:node-pc/common rrd-h5/activity,而we-sdk不需指定模块名。如果一次commit修改多个模块,建议拆分成多次commit,以便更好追踪和维护。
3、body body填写详细描述,主要描述改动之前的情况及修改动机,对于小的修改不作要求,但是重大需求、更新等必须添加body来作说明。
4、break changes break changes指明是否产生了破坏性修改,涉及break changes的改动必须指明该项,类似版本升级、接口参数减少、接口删除、迁移等。
5、affect issues affect issues指明是否影响了某个问题。
那么,可调整为[docs]ADD, 0.txt for test BY ivan,N,N
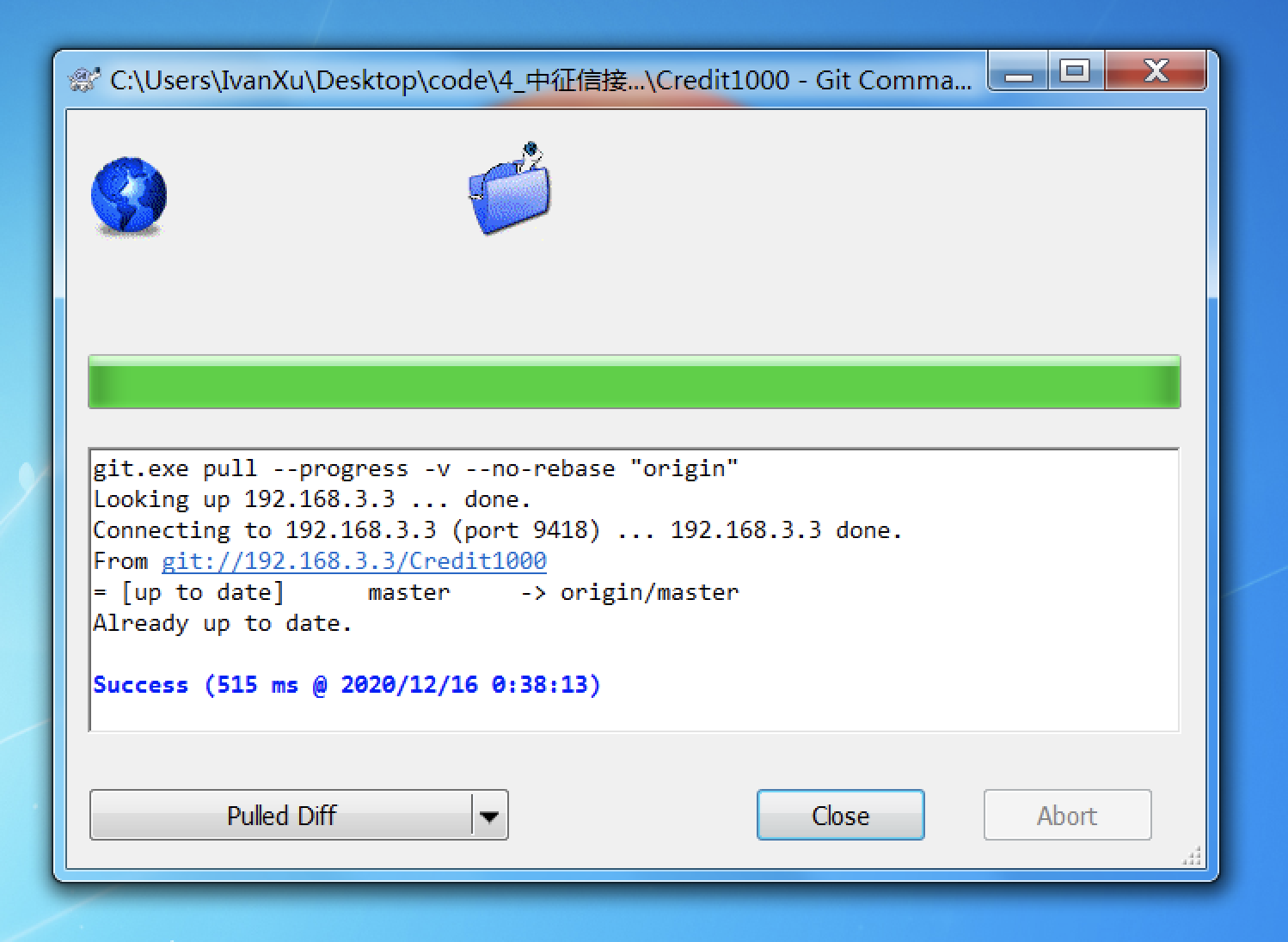
版本更新
即update,Git下需pull。
版本记录
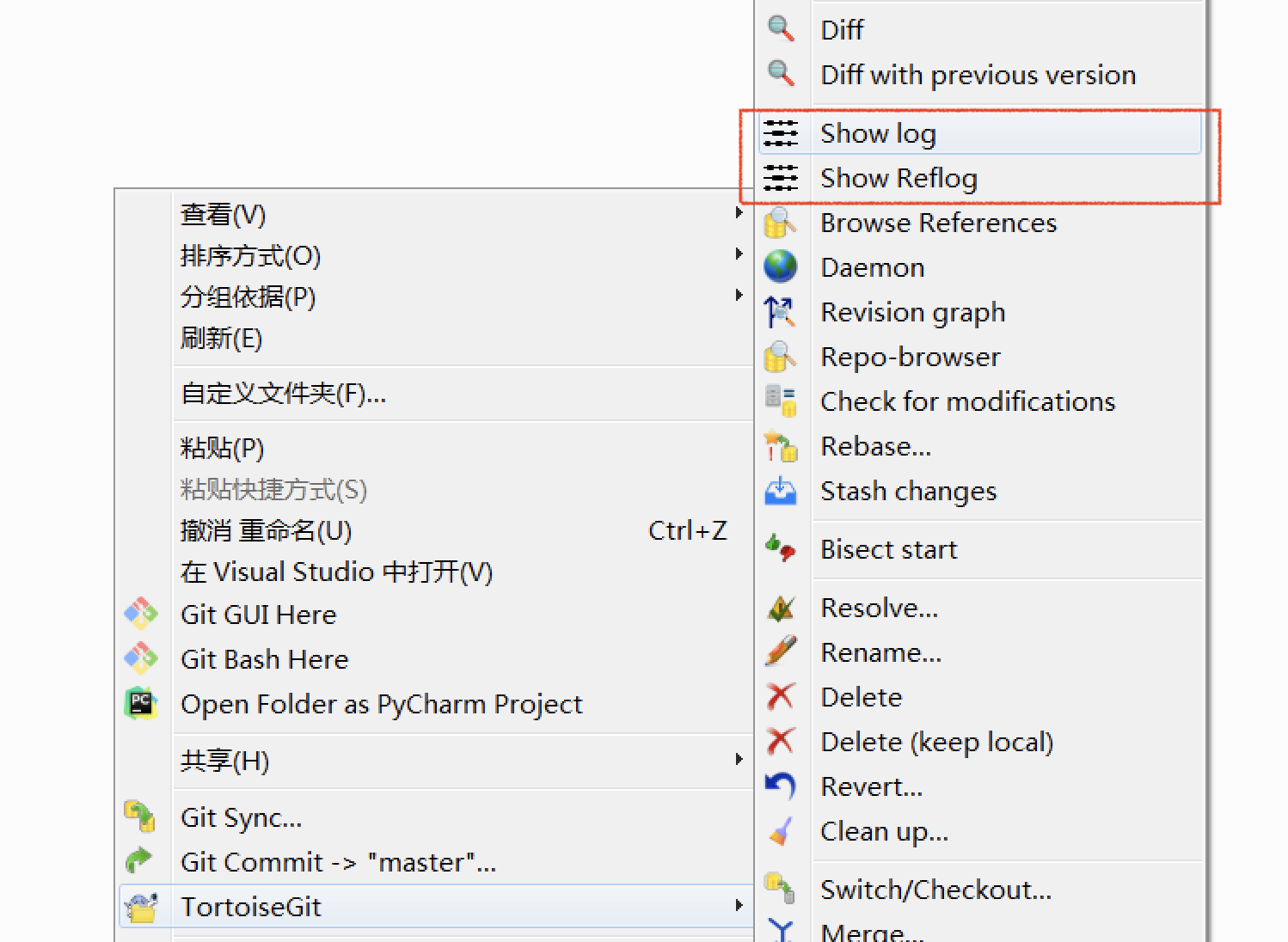
Show log,查看版本记录日志,可通过右键查看,
我们尝试找回上述提交: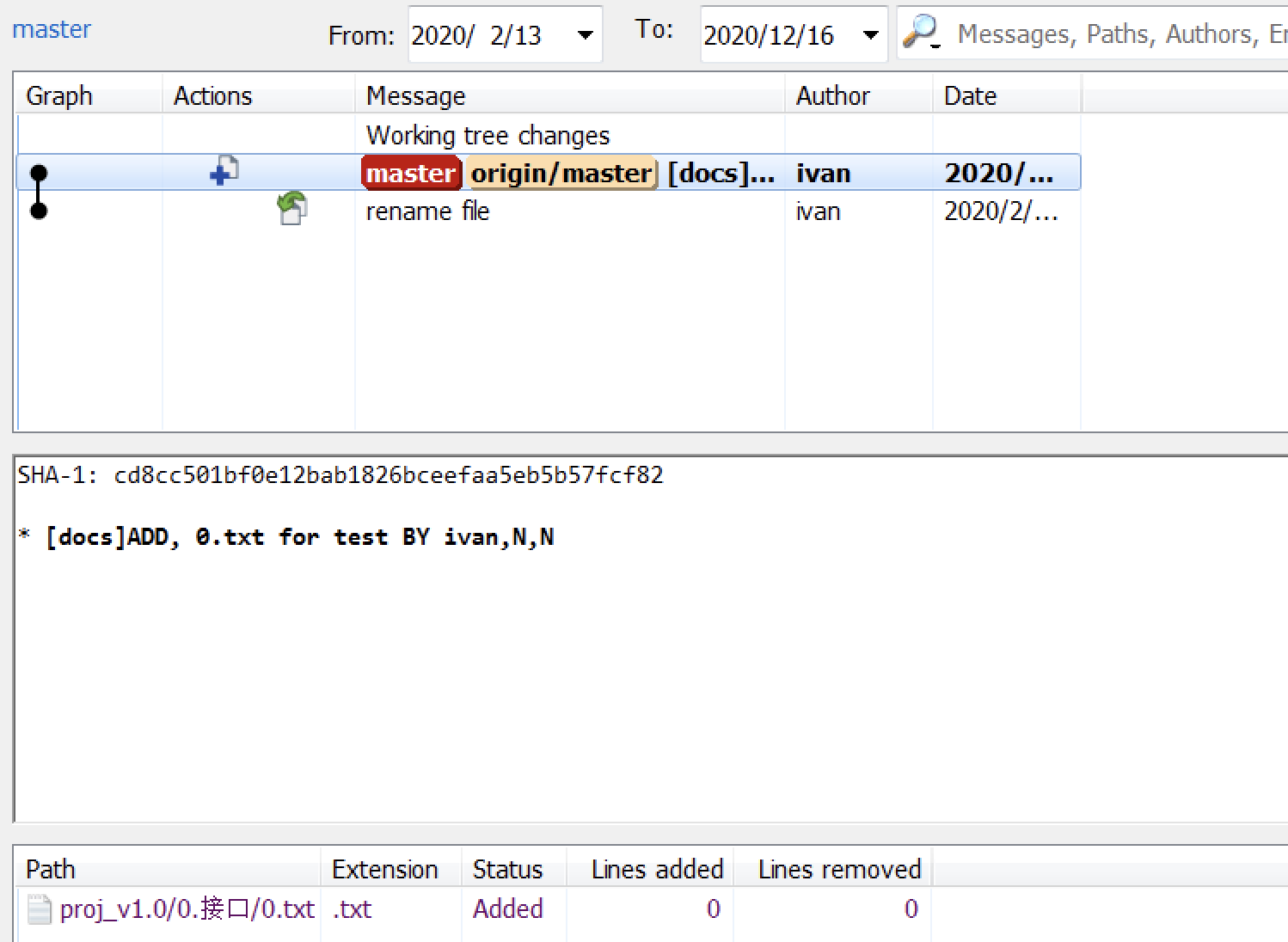
版本回滚
选择对应版本,可选择回滚或其他操作。
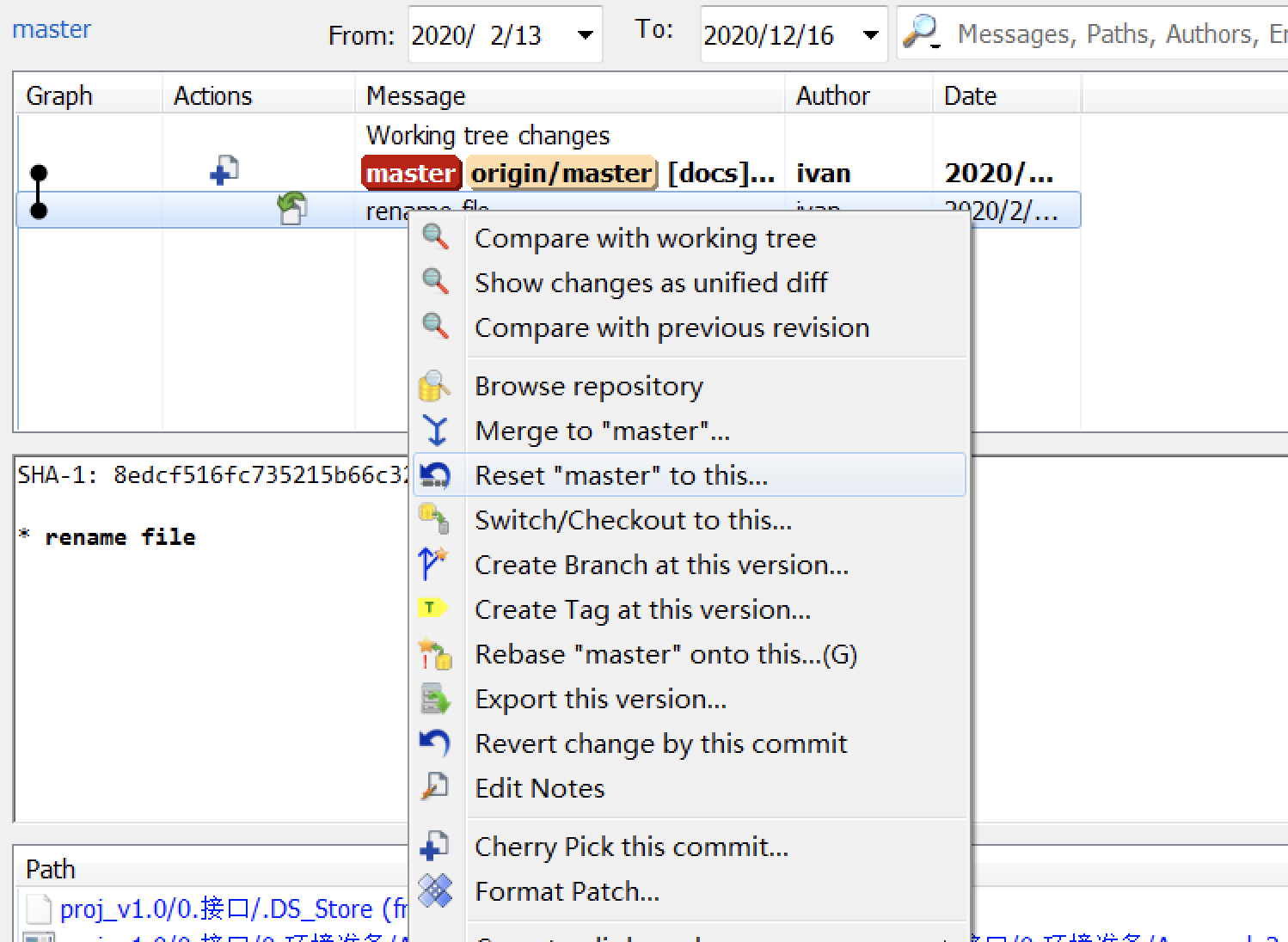
差异查看
一般,本地与远程版本一致时显示图标为绿色,有一定差异时会显示为红色,此时可通过右键Diff查看:
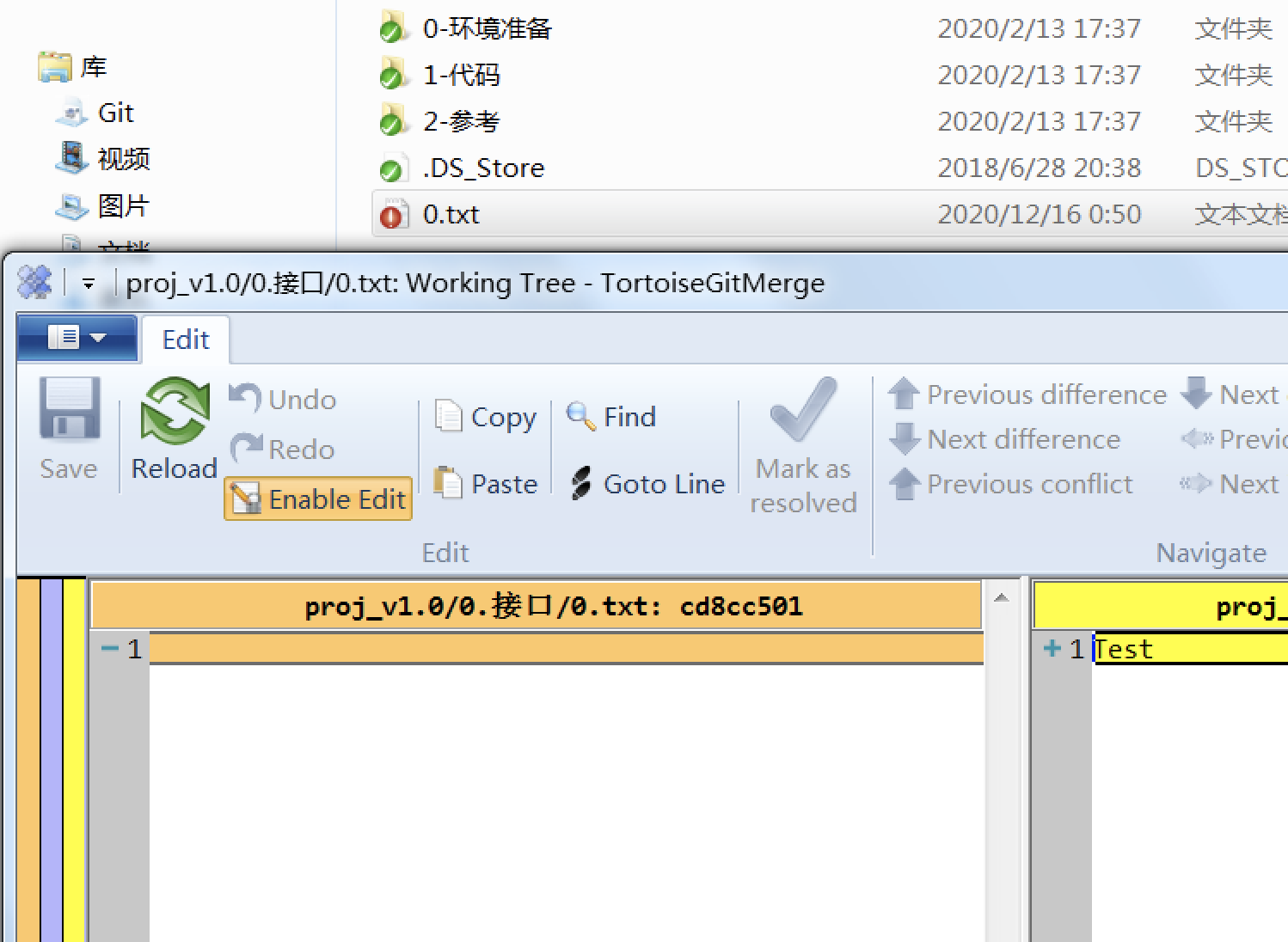
版本锁定
- …
略。
8.1.3 文件系统
8.1.3.1 文件构成
- 文件名称:XXX
- 文件类型:xml、html、txt、bat、c、ini、php、pl、js、css、fasta、fastq
- 编码格式:ANSI/ASCII、UTF-8、UTF-8(no BOM)、UTF-16、Unicode
- 换行符号:CR、LF、CR/LF
8.1.3.2 文本文件
我们这里讨论的是文本文件/text file,也就是 Windows 中为人熟知的 txt 拓展名文件。文本文件只能储存字符,也就是说文件中的信息只能是 “有几个字符” 以及 “每个字符是什么”。所以文本文件本质上不包括字体、字号、下划线等等的其他信息。一个文件是否是文本文件是由它的储存格式决定的,而不是由拓展名决定的。一些其他的文件拓展名如 html、xml、md,以及大部分编程语言的代码文件都是文本文件。
我们把所有非文本文件统称为二进制文件/binary file,因为从原理上来说任何文件都是以二进制的形式储存的。例如 Word 文档保存的 doc 或 docx 拓展名文件就是二进制文件,因为里面用其特定的格式储存了许多其他信息。又例如图片文件 jpg, png,视频文件 mp4 等也都是二进制文件。
8.1.3.3 换行符号
除了编码外,文本文件的换行符使用也有不同的规范。历史上,人们在使用机械打字机时,当一行打完,打字头停留在页面某一行的最右端。回车键(carrage return,简写为 CR)用于将打字头移动到页面的最左端,而 LF(line feed)键用于将纸张上移一行。在 ASCII 编码中,CR 和 LF 分别对应 13 和 10,Windows 系统沿用了这个传统,所以当我们在写字板程序中按下回车时,分别会在文件中插入 CR 和 LF 两个字符。Linux 系统默认使用单个 LF 换行,而 MacOS 则默认用单个 CR 换行。所以同一个文件在不同系统的默认编辑器中可能会出现全部文字排成一行的情况。一般来说,同一个文本文件应该使用同一个规范。
8.1.3.4 编码格式
最重要或者最难理解的就是编码格式,
- 计算机中存储信息的最小单元是一个字节,即8个bit,所以能表示的字符范围是0~255个;
- 人类要表示的符号太多,无法用一个字节来完全表示;
要解决这个矛盾必须要有一个新的数据结构char,从char到byte必须编码。
或者你可以理解编码就像语言翻译一样,在某些约定规则下让计算机懂得E788B1就是”爱”。
通常用16进制来表示二进制,如下表格:
| 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
| 8 | 9 | A | B | C | D | E | F |
一个字节可以用两位的十六进制表示,00FF,共256位0255。下表是二进制的位数,可以表示的字符数目。
| 2^0 | 2^1 | 2^2 | 2^3 | 2^4 | 2^5 | 2^6 | 2^7 | 2^8 | 2^9 | 2^10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 |
二进制如何表示字符,也就是编码格式标准制定的缘由。总的来讲,编码可以分为两类:
(1)Unicode,统一码、万国码、单一码,世界码,旨在全球建立统一标准;
(2)ANSI,可以理解为国标,美国的ASCII,中国的GB2312,Big5,欧洲的Latin等;
- Unicode
Unicode is a computing industry standard for the consistent encoding, representation and handling of text expressed in most of the world’s writing systems.
在表示一个Unicode的字符时,通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。Unicode的实现方式不同于编码方式。一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Transformation Format,简称为UTF)。
目前通用的实现方式是UTF-16小端序(LE)、UTF-16大端序(BE)和UTF-8。在Windows 附带的记事本(Notepad)中,“另存为”对话框可以选择的四种编码方式除去非Unicode编码的ANSI(对于英文系统即ASCII编码,中文系统则为GB2312或Big5编码) 外,其余三种为“Unicode”(对应UTF-16 LE)、“Unicode big endian”(对应UTF-16 BE)和“UTF-8”。
UTF-8是UNICODE的一种变长字符编码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码UNICODE字符。
从Unicode到UTF-8的编码方式如下:
| Unicode编码(16进制) | UTF-8 字节流(二进制) |
|---|---|
| 000000 – 00007F | 0xxxxxxx |
| 000080 – 0007FF | 110xxxxx 10xxxxxx |
| 000800 – 00FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 010000 – 10FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0×00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。UTF-8编码的最大长度是4个字节。从上表可以看出,4字节模板有21个x,即可以容纳21位二进制数字。Unicode的最大码位0x10FFFF也只有21位。
例如:“汉”字的Unicode编码是0x6C49。0x6C49在0×0800-0xFFFF之间,使用用3字节 模板了:1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是:0110 1100 0100 1001, 用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。
- ANSI
对于ANSI编码方式,存在不同的字符集(Charset), 要正确解析一个ANSI字符串,还要选择正确的字符集,每个字符集都有一个唯一的编号,称为代码页(Code Page)。简体中文(GB2312)的代码页为936,而系统默认字符集的代码页为0,它表示根据系统的语言设置来选择一个合适的字符集。
- 汉字编码
汉字编码中现在主要用到的有三类,包括GBK,GB2312和Big5。
(1)GB2312又称国标码GB2312规定“对任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。GB2312中汉字的编码范围为,第一字节0xB0-0xF7(对应十进制为176-247),第二个字节0xA0-0xFE(对应十进制为160-254)。
(2)Big5又称大五码,主要为香港与台湾使用,即是一个繁体字编码。每个汉字由两个字节构成,第一个字节的范围从0X81-0XFE(即129-255),共126种。第二个字节的范围不连续,分别为0X40-0X7E(即64-126),0XA1-0XFE(即161-254),共157种。
(3)GBK是GB2312的扩展,是向上兼容的,因此GB2312中的汉字的编码与GBK中汉字的相同。GBK中每个汉字仍然包含两个字节,第一个字节的范围是0×81-0xFE(即129-254),第二个字节的范围是0×40-0xFE(即64-254)。GBK中有码位23940个,包含汉字21003个。
R.C. GB Uni. UTF-8 R.C. GB Uni. UTF-81601 啊 B0A1 554A E5958A 1602 阿 B0A2 963F E998BF1603 埃 B0A3 57C3 E59F83 1604 挨 B0A4 6328 E68CA81605 哎 B0A5 54CE E5938E 1606 唉 B0A6 5509 E594891607 哀 B0A7 54C0 E59380 1608 皑 B0A8 7691 E79A911609 癌 B0A9 764C E7998C 1610 蔼 B0AA 853C E894BC1611 矮 B0AB 77EE E79FAE 1612 艾 B0AC 827E E889BE1613 碍 B0AD 788D E7A28D 1614 爱 B0AE 7231 E788B1
- ASCII
ASCII使用一个字节的其中7位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。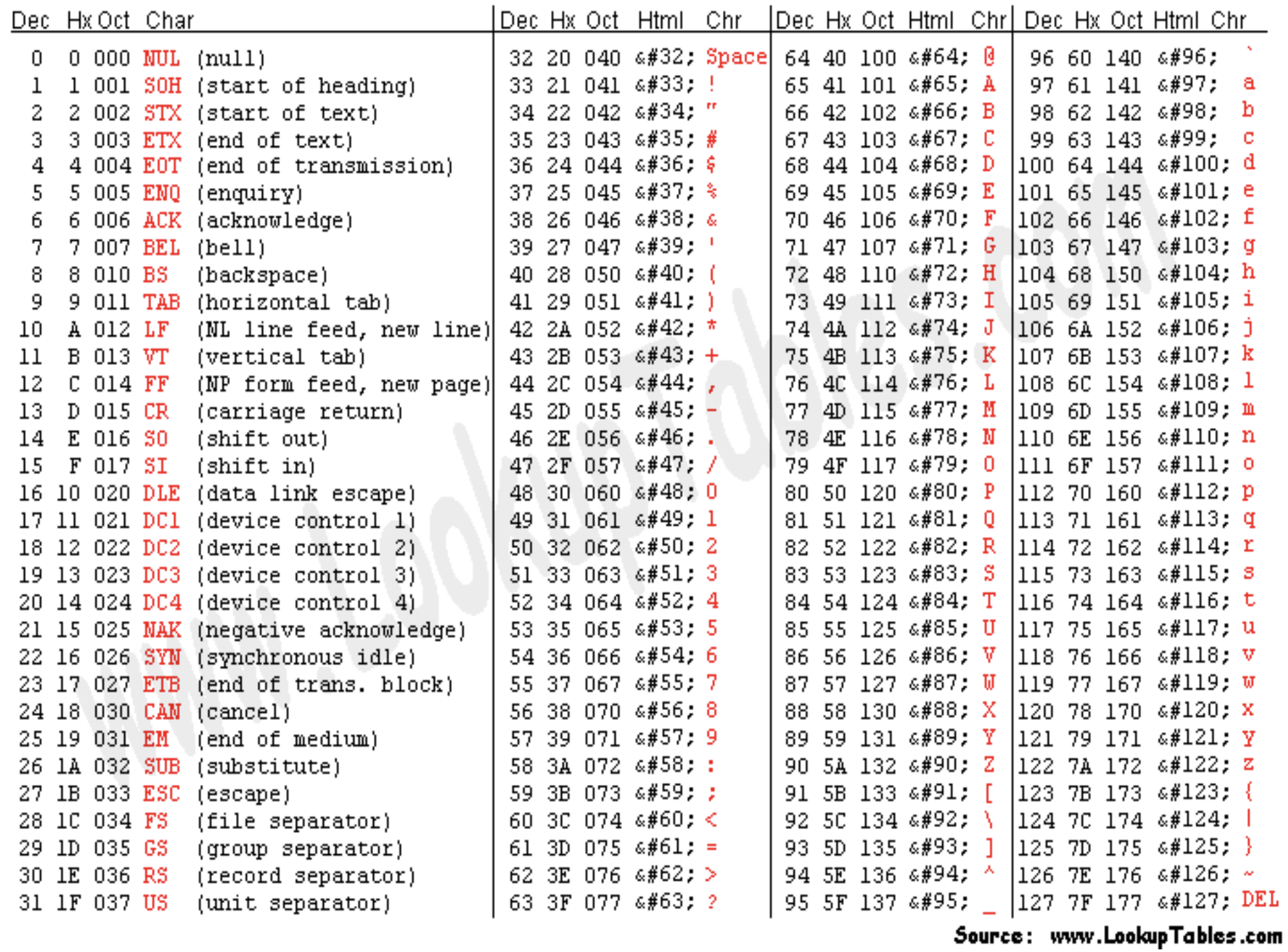
- BOM
Windows就是使用BOM来标记文本文件的编码方式的操作系统,具体如下:
在UCS 编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE”的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输 字符”ZERO WIDTH NO-BREAK SPACE”。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little- Endian的。因此字符”ZERO WIDTH NO-BREAK SPACE”又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
各种系统、工具,对于BOM处理也不一样:
(1)Notepad:可以自动识别出没有带 bom的 utf-8 编码格式文件,但不可以控制保存文件时是否添加 bom , 如果保存文件,那么会统一添加 bom ;
(2)Editplus:不能自动识别出没有 bom 的 utf-8 编码格式文件,文件保存时,选择UTF-8 格式,不会在文件头写上 BOM header;
(3)UltraEdit : 对于字符编码的功能最为强大, 可以自动识别带 bom 和不带 bom 的 utf-8 文件(可以配置) ; 保存的时候可以通过配置选择是否添加 bom;
(4)Notepad ++ :对于 utf-8 bom 支持比较好;
(5)Dreamweaver:可以配置参数,使新建文件时不写入BOM,具体如下:选择 编辑->首选参数,打开后点击左边”新建文档” 这里有个”包括Unicode 签名(BOM)” 前面的对钩去掉即可;
8.1.4 技术文档
新的空军一号飞机的操作维修手册,编写费用是8400万美元,总计超过10万页。以后如果再有人觉得写文档的成本很低,我就告诉他这个例子。
8.1.4.1 指导原则
- 多了解受众
- 强调重要性
- 使其具体化
- 加图表数据
- 使其更美观
8.1.4.2 设计原则
C.R.A.P基本设计原理——Robin Wulliams《写给大家看的设计书》
- C,Contrast/对比
- R,Repetition/重复
- A,Alignment/对齐
- P,Proximity/亲密性
让你了解怎样才能按照自己的方式设计出美观且内容丰富的产品。
我们可以在文档设计、PPT设计、产品设计中应用。
8.1.4.3 写作指南
中文技术文档写作风格指南 https://zh-style-guide.readthedocs.io/zh_CN/latest/
8.1.4.4 最佳实践
略。
8.1.5 时间计划
8.1.5.1 项目计划表
示例: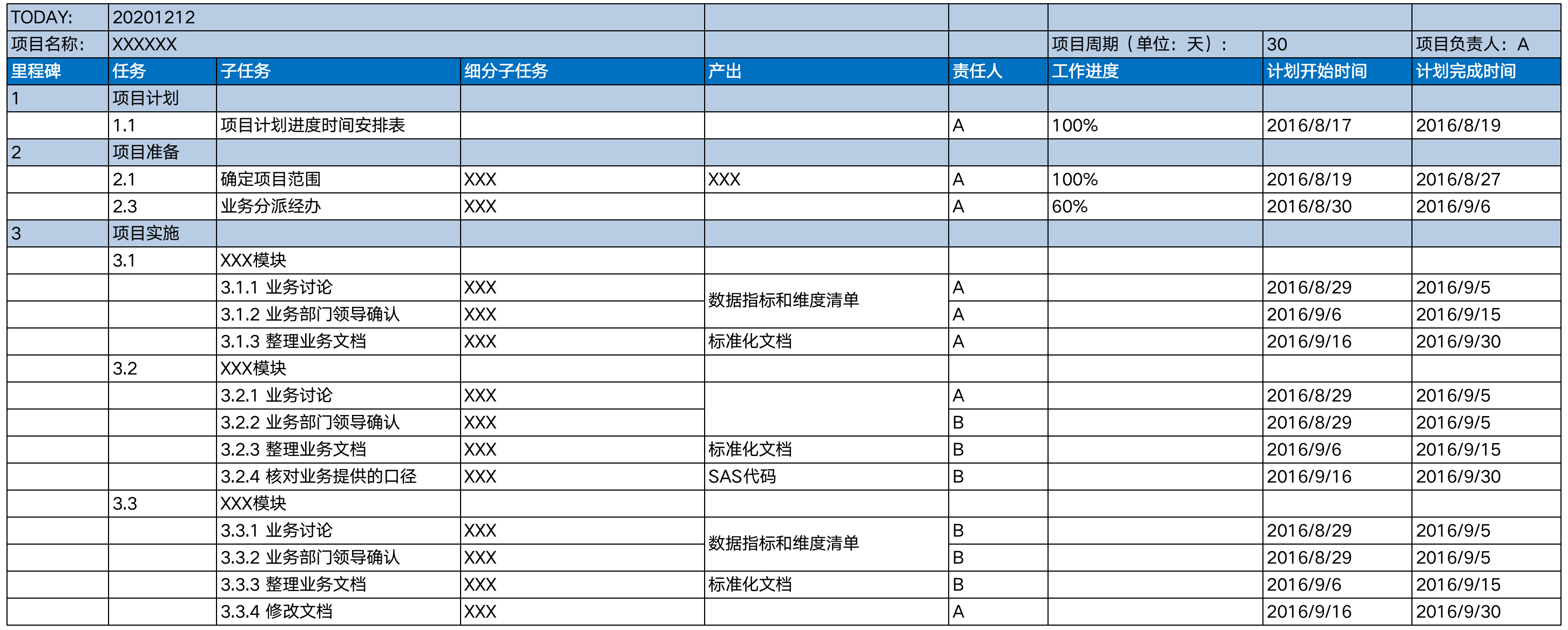
8.1.5.2 甘特图
mermaid代码:
gantttitle 项目时间计划dateFormat YYYY-MM-DD# asection 账单分期响应策略策略客服应用: active, a2, 2020-03-27, 2020-07-01策略各渠道应用 :a3, after a2, 2020-09-01挑战策略开发 :crit, active, a4, after a3, 2020-11-01挑战策略上线 :active, a5, after a4, 2021-02-01策略效果跟进 :a1, 2020-03-27, 2020-09-01
呈现效果:

若有收获,就点个赞吧
0 人点赞
